







AI视野·今日CS.CV 计算机视觉论文速览
Tue, 29 Jun 2021 (showing first 100 of 120 entries)
Totally 100 papers
👉上期速览✈更多精彩请移步主页

Interesting:
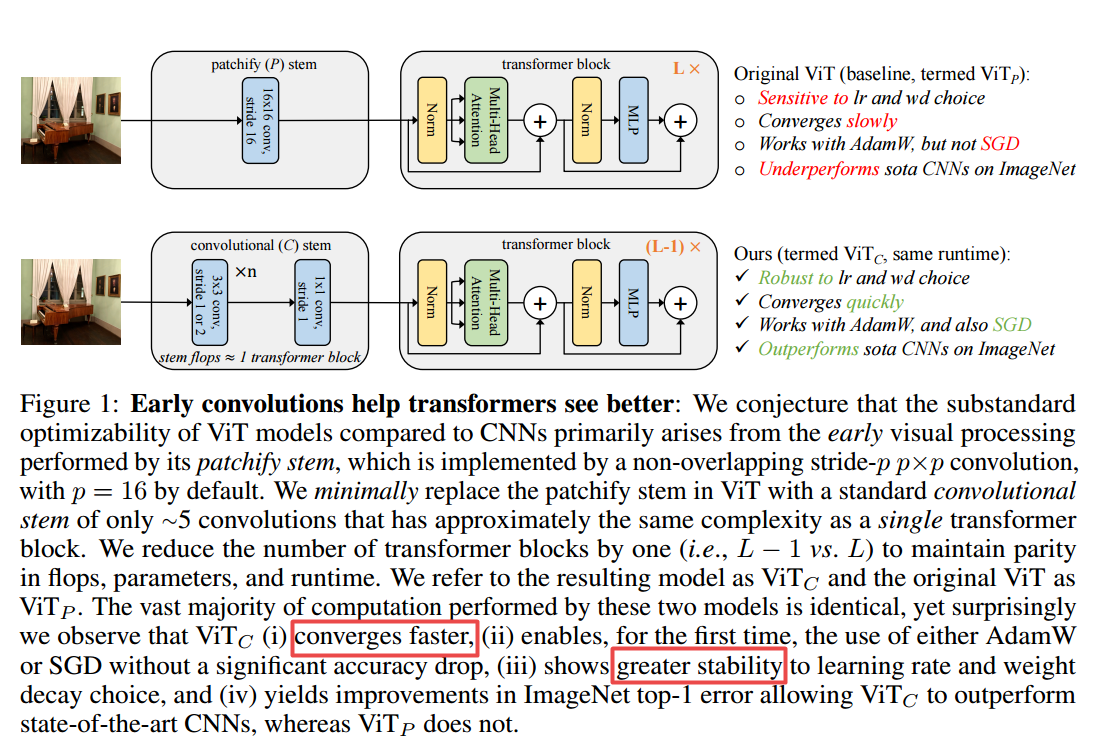
📚*****提升Transformer训练稳定性与性能的早期卷积层, (from FAIR)
📚***CCS基于循环行列式的MLP视觉主干网络, (from 百度认知实验室)
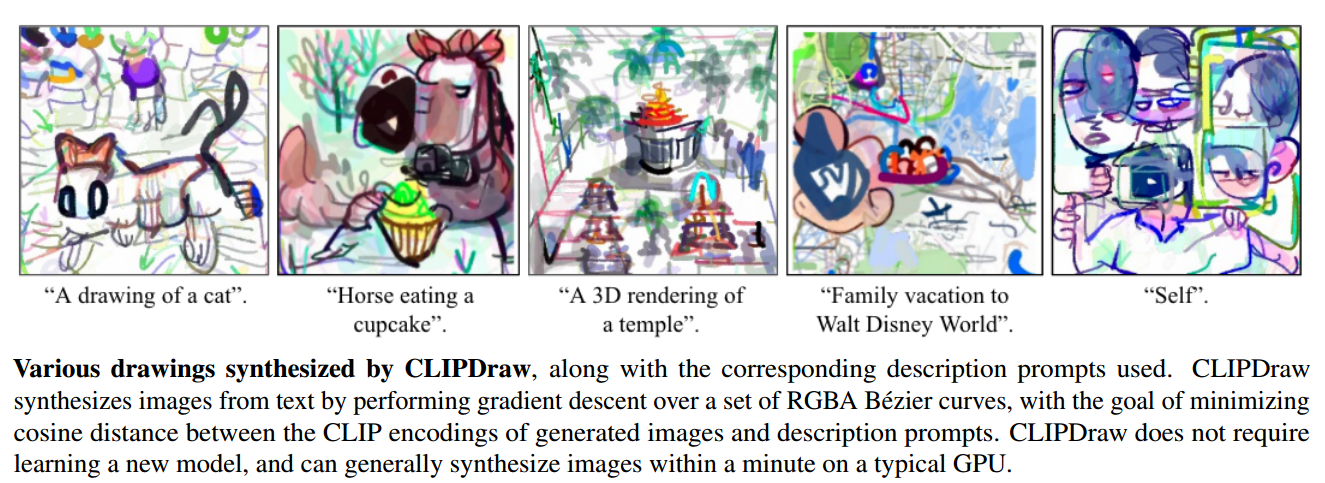
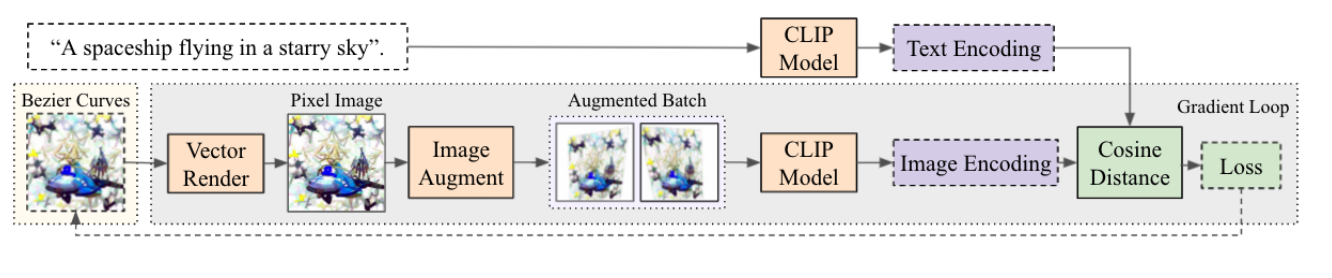
📚****CLIPDraw文本到绘图的合成,语言图像编码器, (from Cross Labs JP MIT)

code:https://colab.research.google.com/github/kvfrans/clipdraw/blob/main/clipdraw.ipynb
cross compass:https://github.com/xc-jp https://www.cross-compass.com/
Contrastive Language-Image Pre-training: CLIP
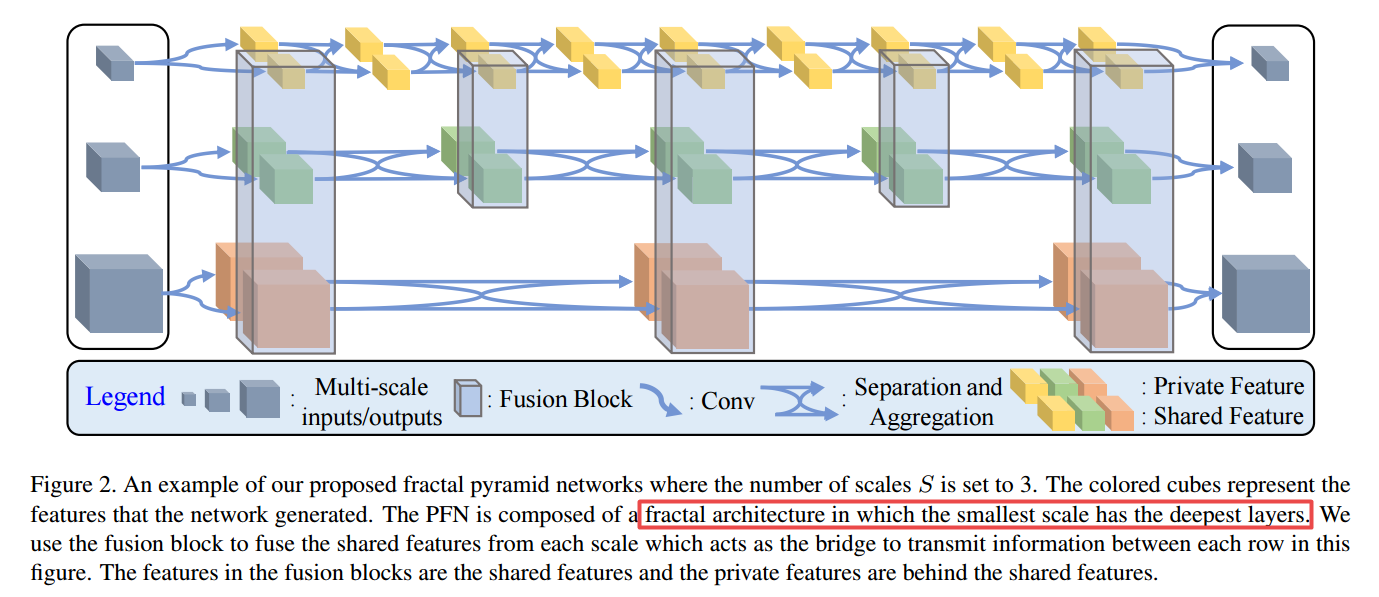
📚***Fractal Pyramid Networks, 多个信息处理通道和特征抽取分支的分数架构。(from 浙大)
📚VAT-MART, 预测人工物体的操作轨迹。(from 北大)
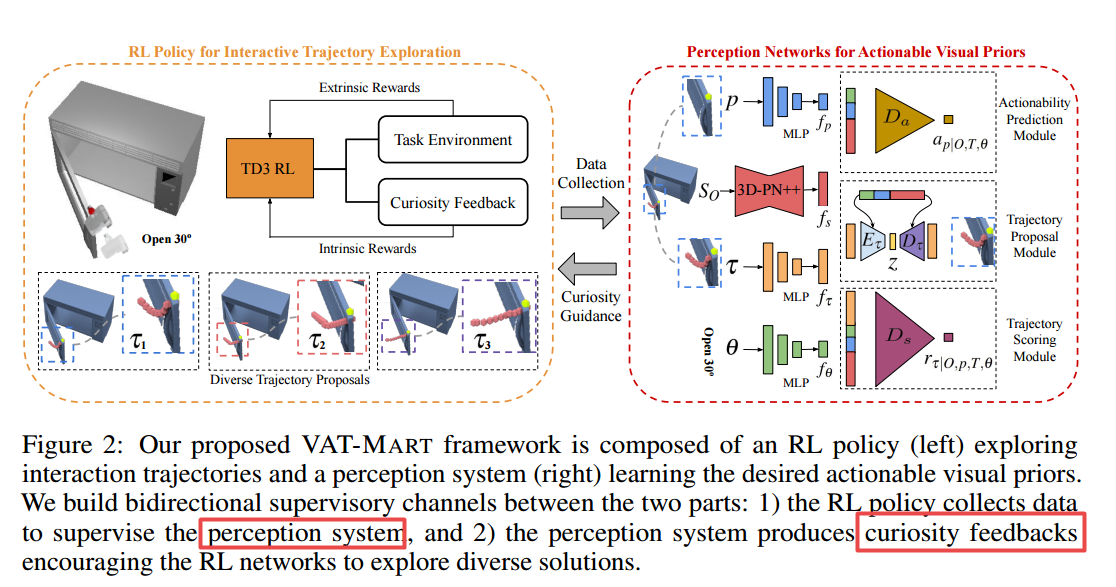
web:https://hyperplane-lab.github.io/vat-mart
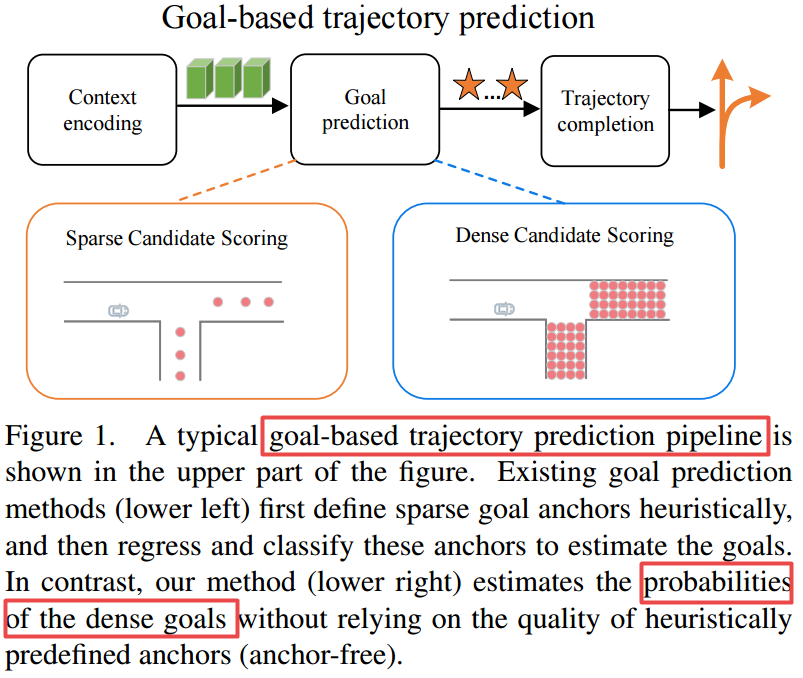
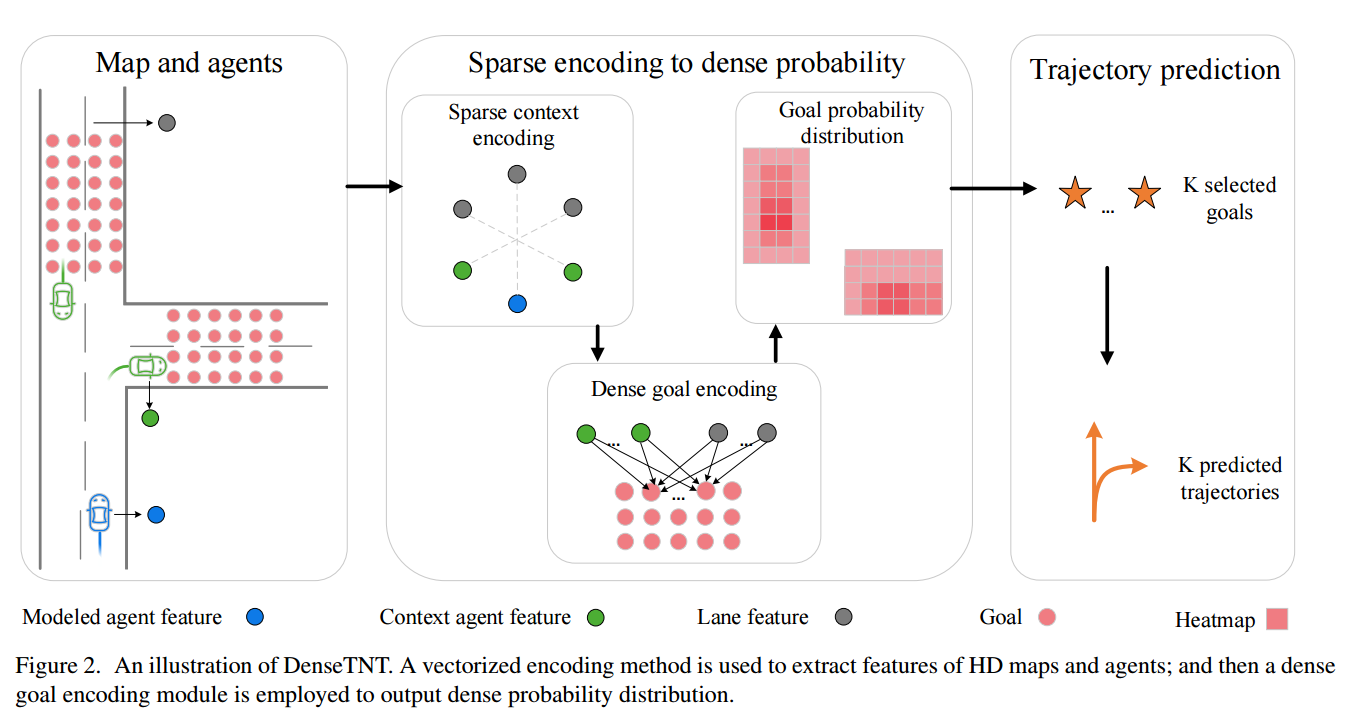
📚DenseTNT, 自动驾驶中的运动预测问题(from 清华 )
code:https://waymo.com/open/challenges
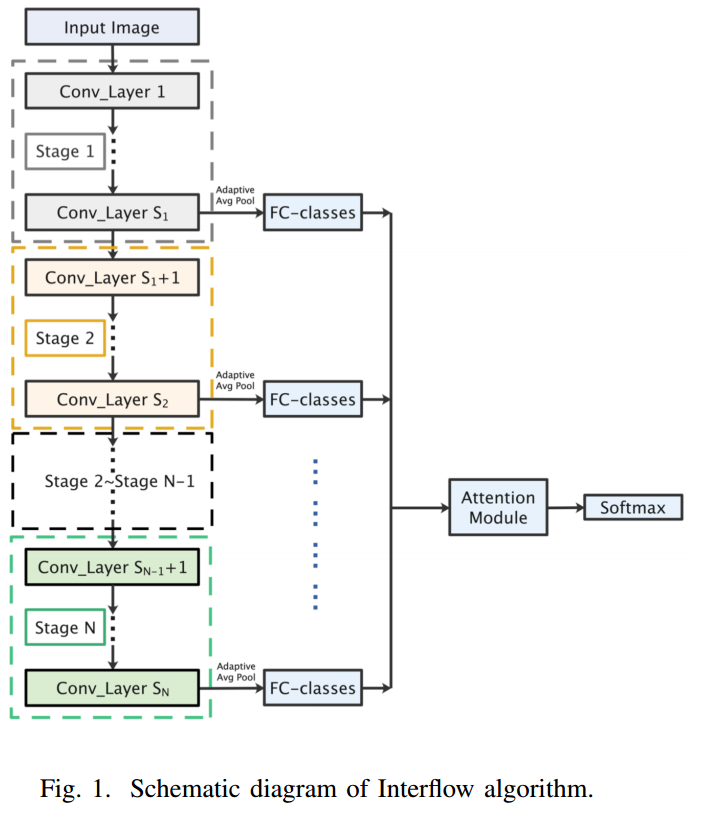
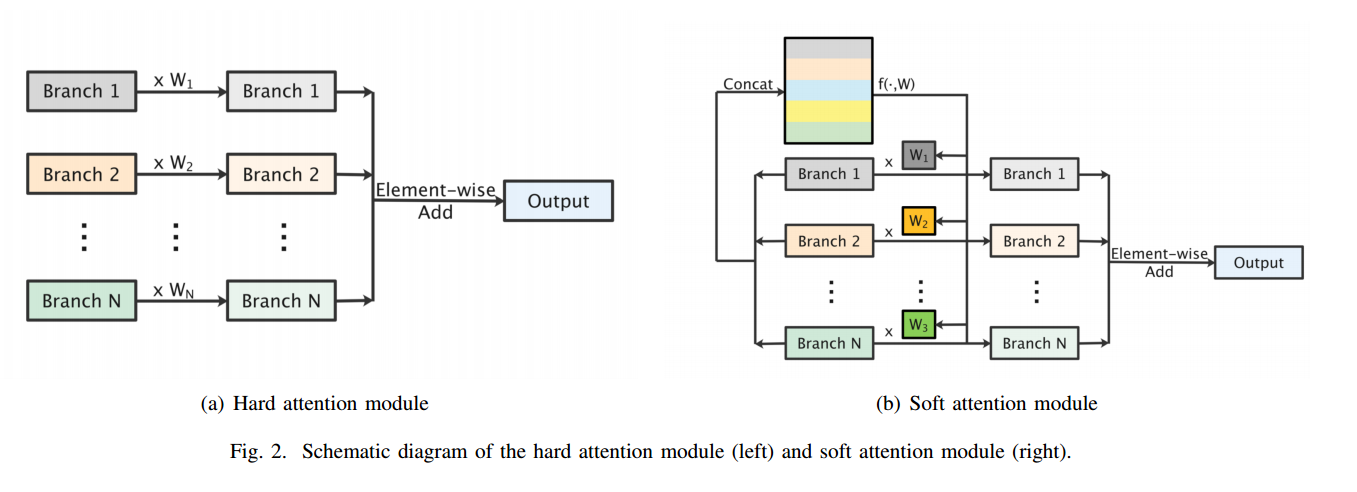
📚***Interflow,基于注意力机制的多层特征映射机制与聚合,用于注意力学习来聚合特征。(from 南京大学)
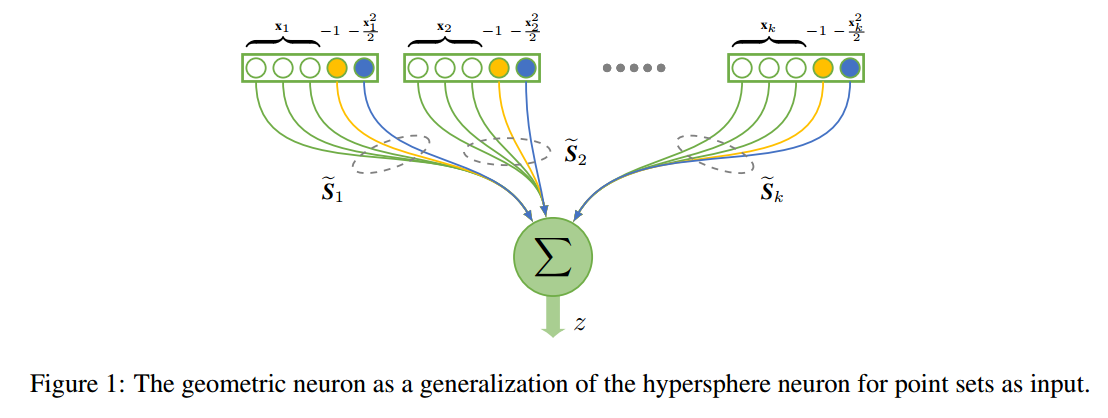
📚***3D Spherical Neurons用于点云学习的球神经元。(from 林雪平大学)
Daily Computer Vision Papers
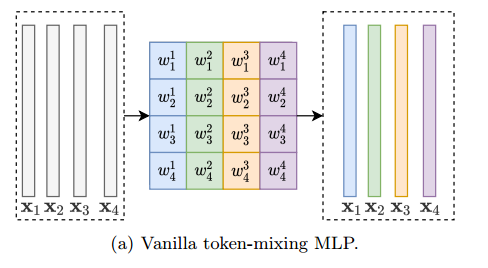
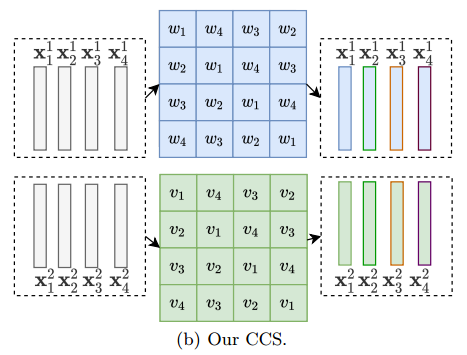
| Rethinking Token-Mixing MLP for MLP-based Vision Backbone Authors Tan Yu, Xu Li, Yunfeng Cai, Mingming Sun, Ping Li 在过去的十年中,我们在机器视觉骨干中迅速进展。通过从图像处理中引入电感偏差,卷积神经网络CNN在许多计算机视觉任务中取得了优异的性能,并且已经建立为Emph de骨干。近年来,通过变压器在NLP任务中取得的巨大成功的启发,视觉变压器模型出现。与CNN对应物相比,使用较少的归纳偏差,在计算机视觉任务中取得了有希望的表现。最近,研究人员使用纯MLP架构调查,以建立视觉骨干,以进一步降低电感偏差,实现良好的性能。纯MLP骨架基于频道混合MLPS,以使通道和令牌混合MLP熔合在贴片之间的通信。在本文中,我们认为令牌混合MLP的设计。我们发现现有的MLP骨干中的令牌混合MLP是空间特异性的,因此它对空间翻译敏感。同时,现有令牌混合MLP的通道不可知性质将其能力限制在混合令牌中。为了克服这些限制,我们提出了一种称为循环通道特异性CCS令牌混合MLP的改进结构,其是空间不变和特定的通道。它需要更少的参数,但在ImageNet1k基准上实现了更高的分类准确性。 |
| Early Convolutions Help Transformers See Better Authors Tete Xiao, Mannat Singh, Eric Mintun, Trevor Darrell, Piotr Doll r, Ross Girshick 视觉变压器Vit模型具有不合格的优化性。特别是,它们对优化器Adamw与SGD,优化器超参数和培训计划长度的选择敏感。相比之下,现代卷积神经网络更容易优化。为什么如此在这项工作中,我们猜测该问题借助于vit模型的打包杆,其默认应用于输入图像的默认情况下由步幅P PXP卷积P 16实现。这个大核加上大步卷积与神经网络中的卷积层的典型设计选择进行计数器。为了测试这个非典型设计选择是否导致问题,我们将vit模型的优化行为与原来的涂装茎相比,通过少数堆叠的卷曲,我们通过少量堆叠的步伐更换vit阀门。虽然两种Vit设计中的绝大多数计算是相同的,但我们发现早期视觉处理的这种小变化导致对优化设置的敏感性以及最终模型精度的敏感性明显不同。在VIT中使用卷积杆显着提高优化稳定性,并且在Imagenet 1K上通过12前1个精度提高了峰值性能,同时保持拖鞋和运行时。可以在从1G到36G拖伏的宽范围的模型复杂性横跨从Imagenet 1K到Imagenet 21k的数据集尺度观察到改进。这些调查结果引导我们建议使用标准的轻质卷积阀,用于与原始Vit模型设计相比更强大的建筑选择。 |
| HDMapGen: A Hierarchical Graph Generative Model of High Definition Maps Authors Lu Mi, Hang Zhao, Charlie Nash, Xiaohan Jin, Jiyang Gao, Chen Sun, Cordelia Schmid, Nir Shavit, Yuning Chai, Dragomir Anguelov 高定义高清地图是具有精确定义的地图,具有丰富的交通规则的语义。它们对于自主驾驶系统中的几个关键阶段至关重要,包括运动预测和规划。然而,只有少量的现实世界道路拓扑和几何形状,这显着限制了我们测试自动驾驶堆的能力,以概括到新的看不见的场景。要解决此问题,我们介绍了一个新的具有挑战性的任务来生成高清地图。在这项工作中,我们使用不同的数据表示来探索几种自回归模型,包括序列,纯图和分层图。我们提出了HDMAPGEN,一种能够通过粗糙的方法产生高质量和多样化高清地图的等级图形生成模型。在协会数据集和房屋数据集中的实验表明,HDMAPGEN明显优于基线方法。此外,我们证明HDMAPGEN实现了高可扩展性和效率。 |
| Explicit Clothing Modeling for an Animatable Full-Body Avatar Authors Donglai Xiang, Fabian Andres Prada, Timur Bagautdinov, Weipeng Xu, Yuan Dong, He Wen, Jessica Hodgins, Chenglei Wu 最近的工作在建设质地的动画全身编解码器头像中表现出巨大的进步,但这些化身仍然面临困难,在发电的衣服的高保真动画方面仍然面临困难。为了解决困难,我们提出了一种制造一个动画披身身体头像的方法,从多视图捕获的视频中的上半身上的衣服显式表示。我们使用两层网格表示来单独注册3D扫描的模板。为了改善不同帧的光度对应,然后通过逆转录的衣服几何形状和由变形自动码器预测的纹理来执行纹理对准。然后,我们用上衣和内部主体层的单独建模训练新的两层编解码器头像。为了了解身体动态和服装状态之间的互动,我们使用时间卷积网络基于一系列输入骨架姿势来预测服装潜像。我们为三个不同的演员表示光致动画输出,并展示穿着身体头像在上一个工作中的单层化身上的优势。我们还展示了一种明确服装模型的好处,它可以在动画输出中编辑服装纹理。 |
| K-Net: Towards Unified Image Segmentation Authors Wenwei Zhang, Jiangmiao Pang, Kai Chen, Chen Change Loy 尽管有不同的相关框架,已经通过不同的和专门的框架解决了语义,实例和Panoptic分段。本文为这些基本相似的任务提供了一个统一,简单,有效的框架。该框架,名为K NET,段落的一组被学习内核的实例和语义类别,其中每个内核负责为潜在实例或填充类生成掩码。为了解决区分各种实例的困难,我们提出了一个内核更新策略,它使每个内核动态和条件在输入图像中的其有意义的组上。 K NET可以在结束时培训,以与二分匹配为止,其培训和推论自然是免费的,盒子免费。如果没有钟声和口哨,K网超越了先前的所有先前状态的艺术单一模型,分别在ADE20K上与52.1 PQ和54.3 miou的ADE20K上的COCO和语义分段上的PANoptic Semonation结果。其实例分段性能也与级联掩模R CNNON MS COCO相同,具有60 90升的推理速度。代码和模型将被释放 |
| Iris Presentation Attack Detection by Attention-based and Deep Pixel-wise Binary Supervision Network Authors Meiling Fang, Naser Damer, Fadi Boutros, Florian Kirchbuchner, Arjan Kuijper 虹膜呈现攻击检测垫在虹膜识别系统中起着重要作用。基于CNN的最现有的CNN IRIS PAD解决方案1仅在CNNS培训期间执行二进制标签监控,服务全球信息学习但削弱局部鉴别特征的捕获,2更喜欢堆叠更深层次的卷曲或专家设计的网络,提高了过度装备的风险,3保险丝多垫系统或各种类型的功能,越来越难以在移动设备上部署。因此,我们提出了一种基于深度的深度引起的深映射二进制监控PBS方法。像素明智的监督首先能够捕获细粒度像素补丁级别提示。然后,注意机制指导网络自动找到最多有助于准确的焊盘决定的区域。在Livdet Iris 2017和其他三个公开数据库上进行了广泛的实验,以显示提出的PBS方法的有效性和稳健性。例如,PBS模型在IITD WVU数据库上实现了6.50的HTER,现有技术的表现优势。 |
| CLIPDraw: Exploring Text-to-Drawing Synthesis through Language-Image Encoders Authors Kevin Frans, L.B. Soros, Olaf Witkowski 这项工作提出了ClipDraw,这是一种算法,其基于自然语言输入综合新颖绘图。 ClipDraw不需要任何培训,而是将预先训练的剪辑语言图像编码器用作度量标准,以便最大化给定描述和生成的图形之间的相似性。 Clipeally,ClipDraw在向量中进行操作,而不是像素图像,这是一个对更简单的人类可识别形状偏置图的约束。结果通过优化方法突出ClipDraw和其他综合,以及突出ClipDraw的各种有趣行为,例如以多种方式满足模糊文本,可靠地在不同的艺术风格中制作图纸,并且从简单到复杂的视觉表示,作为笔划计数增加。有关该方法的试验代码可供选择 |
| Dataset Bias Mitigation Through Analysis of CNN Training Scores Authors Ekberjan Derman 训练数据集对于基于卷积神经网络的算法至关重要,直接影响其整体性能。因此,始终需要使用具有最小偏差水平的井结构数据集。在本文中,我们提出了一种新颖的域独立方法,称为基于分数的重采样SBR,以基于使用该训练集获得的模型预测分数来定位原始训练数据集的表示样本。在我们的方法中,一旦接受培训,我们使用相同的CNN模型来推断自己的训练样本,获得预测分数,并基于预测和地面真理之间的距离,我们识别远离地面真相并增加它们的样本在原始培训集中。 S形函数的温度术语降低以更好地区分得分。对于实验评估,我们为性别分类选择了一个摇臂数据集。我们首先使用基于CNN的分类器,具有相对标准的结构,在训练图像上培训,并在原始数据集的提供的验证样本上进行评估。然后,我们在完全新的测试数据集中评估它,包括轻型男性,轻的女性,黑雄性和黑色女性团体。获得的精度变化,揭示了对原始数据集中的某些组的分类偏差的存在。随后,根据我们提出的方法,我们在重新采样后培训了模型。我们将我们的方法与先前提出的变分性AutoEncoder VAE算法进行了比较。所获得的结果证实了我们建议的方法对原始数据集之间代表样本的识别识别的有效性,以减少分类某些组的分类偏差。虽然测试了性别分类,但是所提出的算法可用于调查基于CNN的任意CNN的数据集结构。 |
| Hyperspectral Remote Sensing Image Classification Based on Multi-scale Cross Graphic Convolution Authors Yunsong Zhao, Yin Li, Zhihan Chen, Tianchong Qiu, Guojin Liu 特征的挖掘和利用直接影响了对高光谱遥感图像分类和识别的模型的分类性能。传统模型通常从单一的角度进行特征开采,其中特征在于被挖掘有限,并且它们之间的内部关系被忽略。因此,有用的特征丢失,分类结果不满意。为了完全挖掘并利用图像特征,提出了一种新的多尺度特征挖掘学习算法MGRNet。该模型使用主成分分析来降低原始高光谱图像HSI的维度,以保留其语义信息的99.99并提取维度减少特征。使用多尺度卷积算法,开采输入维数减少特征,以获得浅的特征,然后送入多尺度图卷积算法的输入,以构造不同尺度的特征值之间的内部关系。然后,我们在通过图表卷积获得的多尺度信息的交叉融合,在输入为深度特征挖掘的残余网络算法中获得的新信息之前。最后,使用灵活的最大传输函数分类器来预测最终特征并完成分类。三个常见的高光谱数据集的实验显示了本文提出的MGRNET算法,以识别准确性优于传统方法。 |
| A Theory-Driven Self-Labeling Refinement Method for Contrastive Representation Learning Authors Pan Zhou, Caiming Xiong, Xiao Tong Yuan, Steven Hoi 对于图像查询,无监督的对比学习标签与阳性相同图像的作物,以及其他图像作物作为否定。虽然直观,但原生标签分配策略不能揭示查询及其阳性和否定之间的潜在语义相似性,并且损害性能,因为一些否定是语义上类似于查询甚至与查询共享相同的语义类。在这项工作中,我们首先证明,对于对比学习,不准确的标签分配严重损害其对语义实例歧视的泛化,而准确的标签则有利于其泛化。受到这个理论的启发,我们提出了一种新颖的自我标签对比学习的细化方法。它通过两个互补模块改善了标签质量,即可自行标记炼油厂SLR,以产生准确的标签和II动量混合MM,以增强查询与其正的相似性。 SLR使用阳性查询来估计查询和积极和否定之间的语义相似性,并将估计的相似性与Vanilla标签分配相结合,以便迭代地生成更准确和信息丰富的软标签。理论上我们显示我们的SLR可以完全恢复标签损坏数据的真正语义标签,并监督网络以实现分类任务的零预测错误。 MM随机结合查询和阳性,以增加所生成的虚拟查询和它们的阳性之间的语义相似性,以提高标签精度。 CIFAR10,Imagenet,VOC和Coco的实验结果表明了我们方法的有效性。 Pytorch码和模型将在线发布。 |
| One-Shot Affordance Detection Authors Hongchen Luo 1 , Wei Zhai 1 and 3 , Jing Zhang 2 , Yang Cao 1 , Dacheng Tao 3 1 University of Science and Technology of China, China, 2 The University of Sydney, Australia, 3 JD Explore Academy, JD.com, China 可用性检测是指识别图像中对象的潜在动作可能性,这是机器人感知和操纵的重要能力。为了使机器人能够在看不见的情景中具有这种能力,我们考虑了本文的挑战,即,给定描述动作目的的支持图像,应检测到具有共同带来的场景中的所有对象。为此,我们设计了一个拍摄的一拍了一拍了OS广告网络,首先估计目的,然后将其传送以帮助检测所有候选图像的共同承受。通过协作学习,OS AD可以捕获具有相同潜在可供性的对象之间的共同特征,并学习良好的适应能力,以感知看不见的能力。此外,我们通过从31带31次提供和标记4K图像和72个对象类别来构建一个目的驱动的无力数据集垫。实验结果表明,在客观指标和视觉质量方面,我们对以前代表性的模型的优越性。基准套件是ProjectPage。 |
| Real-Time Human Pose Estimation on a Smart Walker using Convolutional Neural Networks Authors Manuel Palermo, Sara Moccia, Lucia Migliorelli, Emanuele Frontoni, Cristina P. Santos 康复对于改善流动性障碍的生活质量是重要的。智能步行者是一个常用的解决方案,应该嵌入自动和客观工具,用于循环控制和监控中的数据驱动的人。但是,目前的解决方案专注于从专用传感器中提取少量特定指标,没有统一的全身方法。我们调查一般,实时,全身姿势估计框架,基于两个RGB D相机流,其安装在康复中使用的智能助行器设备上。使用两个阶段神经网络框架执行人的关键点估计。 2D阶段实现检测模块,该检测模块在2D图像帧中定位身体键点。 3D阶段实现了一个回归模块,其升级并将两个相机中的检测到的关键点相对于助行器涉及到3D空间。模型预测低通滤波以提高时间一致性。使用自定义采集方法来获取数据集,其中具有14个健康的科目,用于培训和评估拟议的框架离线,然后部署在真实的助行器设备上。报告了2D级的3.73像素的总体关键点检测误差和3D阶段44.05mm,推测时间为26.6ms,当时在步行者的受限硬件上部署。我们在智能步行者背景下提出了一种新的患者监测和数据驱动人员的方法。它能够实时提取完整和紧凑的身体表示以及从廉价的传感器中提取完整和紧凑的体表示,作为下游度量提取解决方案和人体机器人交互应用的公共基础。尽管结果有前途,但应对具有损伤的用户收集更多数据,以评估其作为现实世界情景中的康复工具的性能。 |
| Unsupervised Discovery of Actions in Instructional Videos Authors AJ Piergiovanni, Anelia Angelova, Michael S. Ryoo, Irfan Essa 在本文中,我们解决了从教学视频中自动发现无人监督的原子行为的问题。教学视频包含复杂的活动,是智能代理的丰富信息来源,例如,自主机器人或虚拟助手,例如,可以从教学视频中自动读取步骤并执行它们。但是,视频很少有原子活动,界限或持续时间注释。我们提出了一种无人监督的方法来从各种教学视频中学习结构化人类任务的原子行动。我们提出了一种序贯的随机自回归模型,用于视频的时间分割,从而了解任务的不同原子动作之间的顺序关系,并为视频提供自动和无监督的自我标记。我们的方法优于艺术艺术的状态无监督的方法。我们将开源代码。 |
| Real-Time Multi-View 3D Human Pose Estimation using Semantic Feedback to Smart Edge Sensors Authors Simon Bultmann, Sven Behnke 我们介绍了一种从多相机设置估计3D人类姿势的新方法,采用分布式智能边缘传感器,通过语义反馈回路与后端耦合。每个摄像机视图的2D接头检测在专用嵌入式推断处理器上本地执行。在网络上仅传输语义骨架表示,并在传感器板上保持原始图像。 3D姿势从中央后端的2D关节恢复,基于三角测量和一个人的模型,该模型包括人体骨架的先验知识。从后端到各个传感器的反馈通道在语义级别实现。将Allocentric 3D姿势倒置到传感器视图中,在那里它与2D联合检测融合。因此可以通过结合全局上下文信息来提高每个传感器上的局部语义模型。整个管道能够实时运行。我们在三个公共数据集中评估我们的方法,在那里我们实现了最先进的结果,并显示了我们的反馈架构的好处,以及我们自己的多人实验设置。使用反馈信号改善了2D联合检测,并且又估计的3D姿势。 |
| Motion Projection Consistency Based 3D Human Pose Estimation with Virtual Bones from Monocular Videos Authors Guangming Wang, Honghao Zeng, Ziliang Wang, Zhe Liu, Hesheng Wang 实时3D人类姿态估计对于人机互动至关重要。它是便宜且实用的是仅从单眼视频估计3D人类姿势。然而,近期基于骨剪接的3D人姿势估计方法带来了累积误差的问题。在本文中, |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









