







KMP字符串匹配
一个字符串的子串指的是字符串某一段连续的部分,可以是其本身,判断一个字符串是否是另一个字符串的子串,可以使用 k m p kmp kmp 算法快速匹配上,假设两个子串的长度为 m 、 n m、n m、n,则暴力求解的时间复杂度为 O ( m n ) O(mn) O(mn),而 k m p kmp kmp 的时间复杂度为 O ( m + n ) O(m+n) O(m+n)。
前缀后缀最大值
一个长度为N的字符串 S S S,它有 N + 1 N+1 N+1 个前缀(包括空前缀),有 N + 1 N+1 N+1 个后缀
例如:字符串 A B C ABC ABC 有空、 A A A、 A B AB AB、 A B C ABC ABC 四个前缀,有空、 C C C、 B C BC BC、 A B C ABC ABC 四个后缀
前缀后缀最大值:对一个长度为 N N N 的字符串 S S S ,找出它的 N + 1 N+1 N+1 个后缀和前缀,按照长度划分,得到 N + 1 N+1 N+1 个对序偶<前缀、后缀>,删除前缀后缀等于字符串本身S的所有<前缀、后缀>中,前缀=后缀且长度最大的<前缀、后缀>的长度就是前缀后缀最大值。
例如:对于 S = A B A B A B A S=ABABABA S=ABABABA ,按照长度列出前缀、后缀,发现前缀后缀相等的最长前缀后缀为 A B A B A ABABA ABABA ,即前缀后缀最大值为 5 5 5 。
| 前缀 | 后缀 | 相等 |
|---|---|---|
| 空 | 空 | yes |
| A | A | yes |
| AB | BA | no |
| ABA | ABA | yes |
| ABAB | BABA | no |
| ABABA | ABABA | yes |
| ABABAB | BABABA | no |
| ABABABABA | ABABABABA | yes(除去本身) |
next数组含义
n e x t [ i ] next[i] next[i] 表示 S [ 0... i − 1 ] S[0...i-1] S[0...i−1] 这个前缀的前缀后缀最大值,注意这个不是 S [ 0... i ] S[0...i] S[0...i],准确理解 n e x t next next 的含义对理解 k m p kmp kmp 算法很重要。
例如,我们来求 S = A A A B A A A D S=AAABAAAD S=AAABAAAD 的 n e x t next next 数组,我们定义 n e x t [ 0 ] = − 1 next[0]=-1 next[0]=−1。
第一个前缀为 A A A,删除自己本身的前缀后缀是空字符串,所以前缀后缀最大值为 0 0 0, n e x t [ 1 ] = 0 next[1]=0 next[1]=0 。
第二个前缀为 A A AA AA,除去自己的前缀有空、 A A A,除去自己的后缀有空、 A A A,最大前缀后缀为 A A A, n e x t [ 2 ] = 1 next[2]=1 next[2]=1。
第三个前缀为 A A A AAA AAA,前缀有空、 A A A、 A A AA AA,后缀有空、 A A A、 A A AA AA,最大前缀后缀为 A A AA AA, n e x t [ 3 ] = 2 next[3]=2 next[3]=2。
第四个前缀为 A A A B AAAB AAAB,前缀有空、 A A A、 A A AA AA、 A A A AAA AAA,后缀有空、 B B B、 A B AB AB、 A A B AAB AAB,最大前缀后缀为空, n e x t [ 4 ] = 0 next[4]=0 next[4]=0。
我们依照上面的流程可以算出来最后的 n e x t next next 数组如下
| i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|---|
| S | A | A | A | B | A | A | A | D | |
| next | -1 | 0 | 1 | 2 | 0 | 1 | 2 | 3 | 0 |
KMP匹配算法
假设我们有两个字符串, S 1 = A A A B A A A B A A A B A A A D S1=AAABAAABAAABAAAD S1=AAABAAABAAABAAAD, S 2 = A A A B A A A D S2=AAABAAAD S2=AAABAAAD,通过一个例子来初步了解以下 K M P KMP KMP算法流程。
首先我们先计算出来
S
2
S2
S2 的
n
e
x
t
next
next 数组,我们将指针
t
1
t1
t1 指向
S
1
S1
S1 的第零个位置,指针
t
2
t2
t2 指向
S
2
S2
S2 的第零个位置,然后依次往后面匹配,如果
S
1
[
t
1
]
=
=
S
2
[
t
2
]
S1[t1]==S2[t2]
S1[t1]==S2[t2],则
t
1
+
+
,
t
2
+
+
t1++,t2++
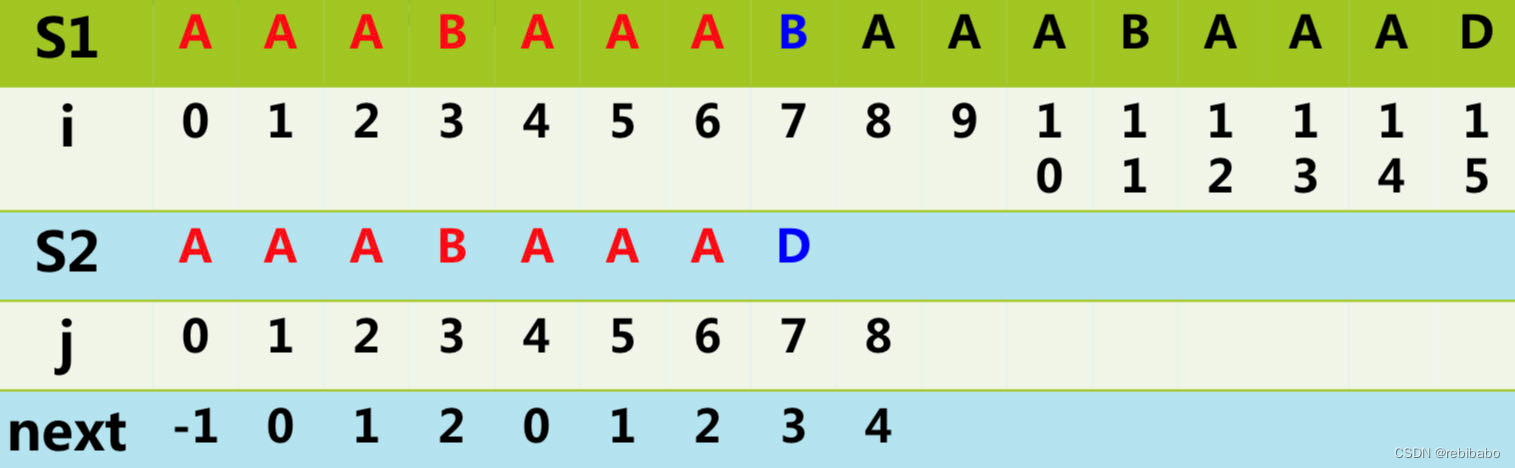
t1++,t2++,如下图所示,匹配到
t
1
=
t
2
=
7
t1=t2=7
t1=t2=7 的时候失配了,
S
1
[
7
]
≠
S
2
[
7
]
S1[7]\ne S2[7]
S1[7]=S2[7]。
对于暴力匹配算法,接下来应该是令
t
2
=
0
,
t
1
=
1
t2=0,t1=1
t2=0,t1=1,而
k
m
p
kmp
kmp 算法不是这样,因为
n
e
x
t
next
next 数组实际上存放了待匹配字符
S
2
S2
S2 的一些固定特征,可以跳过去一些重复的比较。
接下来,我们查询
7
7
7 号位置的
n
e
x
t
next
next 值,
n
e
x
t
[
7
]
=
3
next[7]=3
next[7]=3,然后令
t
2
=
n
e
x
t
[
t
2
]
=
n
e
x
t
[
7
]
=
3
t2=next[t2]=next[7]=3
t2=next[t2]=next[7]=3,相当于
S
2
S2
S2 往右移动了
∣
S
2
∣
−
n
e
x
t
[
7
]
|S2|-next[7]
∣S2∣−next[7] ,而
t
1
t1
t1 不变。

此时
t
1
=
7
,
t
2
=
3
t1=7,t2=3
t1=7,t2=3,可以发现
S
1
[
4..6
]
S1[4..6]
S1[4..6] 和
S
2
[
0..2
]
S2[0..2]
S2[0..2] 已经匹配上了,从
t
1
t1
t1 往下继续匹配即可,因为
S
2
S2
S2 的前
3
3
3 个字符和后
3
3
3 个字符相同,换句话说,我们在
S
1
[
7
]
S1[7]
S1[7] 和
S
2
[
7
]
S2[7]
S2[7] 处失配。只需要改变
t
2
t2
t2,我们查询
n
e
x
t
[
7
]
next[7]
next[7],即
S
2
[
0..6
]
S2[0..6]
S2[0..6] 的前缀后缀最大值,表示这一段前缀等于后缀,且又是长度最大的,那么移动后,失配点的前段一定还是匹配的,我们是需要再从失配点
t
1
t1
t1 继续往下匹配即可。
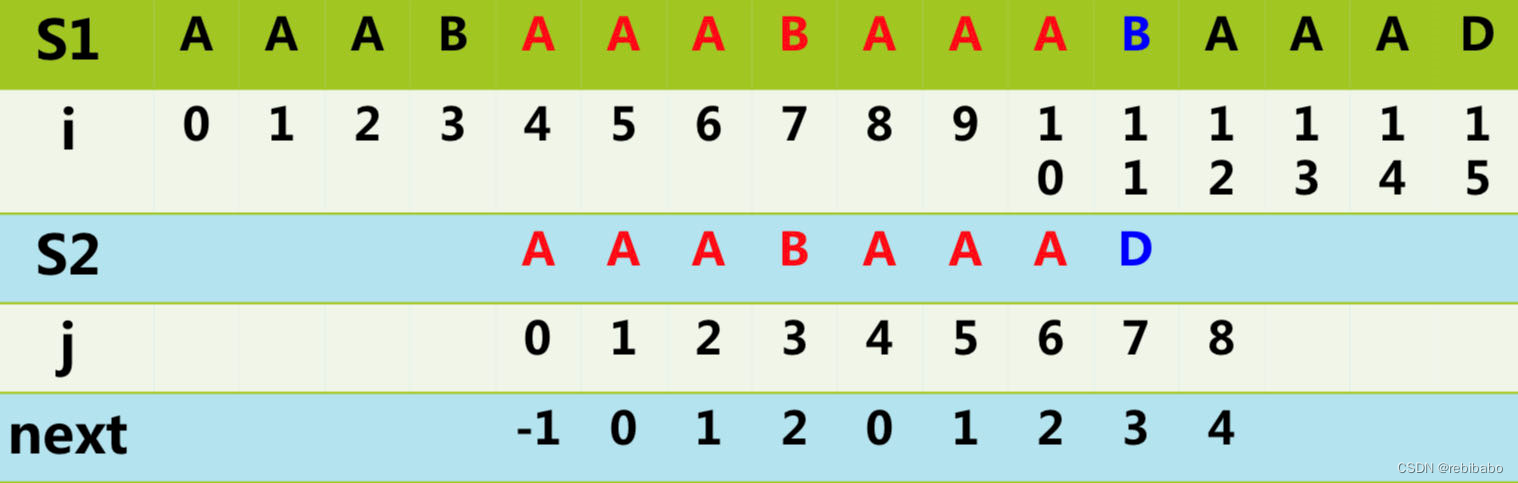
我们继续往后匹配,到了
t
1
=
11
,
t
2
=
7
t1=11,t2=7
t1=11,t2=7 时又出现了失配,还是同样的步骤,令
t
2
=
n
e
x
t
[
t
2
]
=
n
e
x
t
[
7
]
=
4
t2=next[t2]=next[7]=4
t2=next[t2]=next[7]=4。
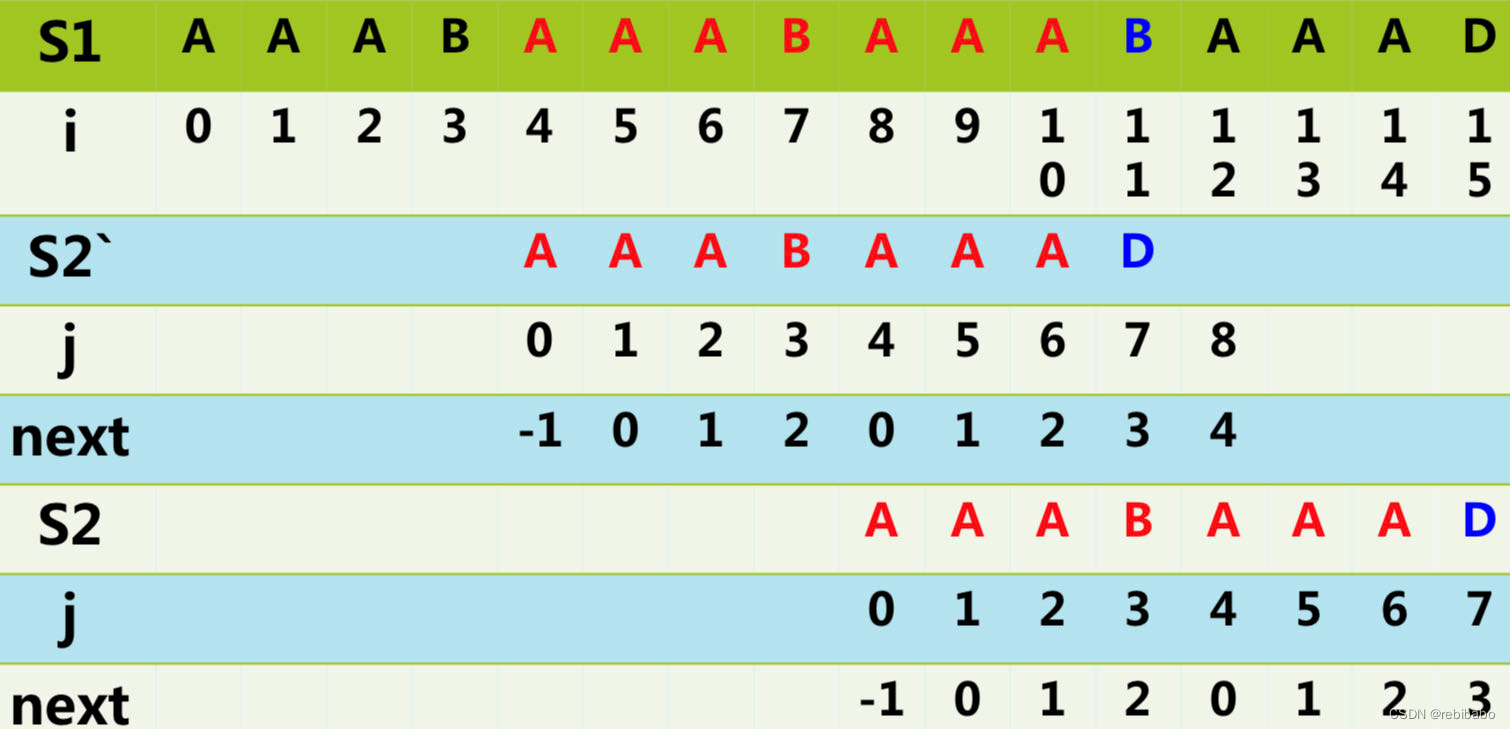
S
1
S1
S1 未动,
S
2
S2
S2 整体向右移动了
∣
S
2
∣
−
n
e
x
t
[
7
]
|S2| -next[7]
∣S2∣−next[7] 个格子。继续往下匹配,都能匹配成功,说明
S
2
S2
S2 是
S
1
S1
S1 的子串。
下面是
k
m
p
kmp
kmp 算法的代码,如果
j
=
=
−
1
j==-1
j==−1 或者
s
1
[
i
]
=
=
k
e
y
[
j
]
s1[i]==key[j]
s1[i]==key[j] ,
i
i
i 和
j
j
j 都要增一,否则
i
i
i 不变,
j
=
n
e
x
t
[
j
]
j=next[j]
j=next[j]。
bool kmp(string s1, string key){
int i = 0, j = 0;
int l1 = s1.size(), l2 = key.size();
while((i < l1) && (j < l2)){
if(j == -1 || s1[i] == key[j]){
i++;
j++;
}
else{
j = next_arr[j];
}
}
if(j >= l2) return true;
else return false;
}
如何求next数组
下面举一个例子来说明如何求
n
e
x
t
next
next 数组,我们要求
n
e
x
t
[
k
+
1
]
next[k+1]
next[k+1],其中
k
+
1
=
17
k+1=17
k+1=17,已知
n
e
x
t
[
16
]
=
8
next[16]=8
next[16]=8,则红色框内的元素是一样的,我们只需要判断
p
[
8
]
p[8]
p[8] 是否等于
p
[
16
]
p[16]
p[16],如果相等,则
n
e
x
t
[
k
+
1
]
=
8
+
1
=
9
next[k+1]=8+1=9
next[k+1]=8+1=9。
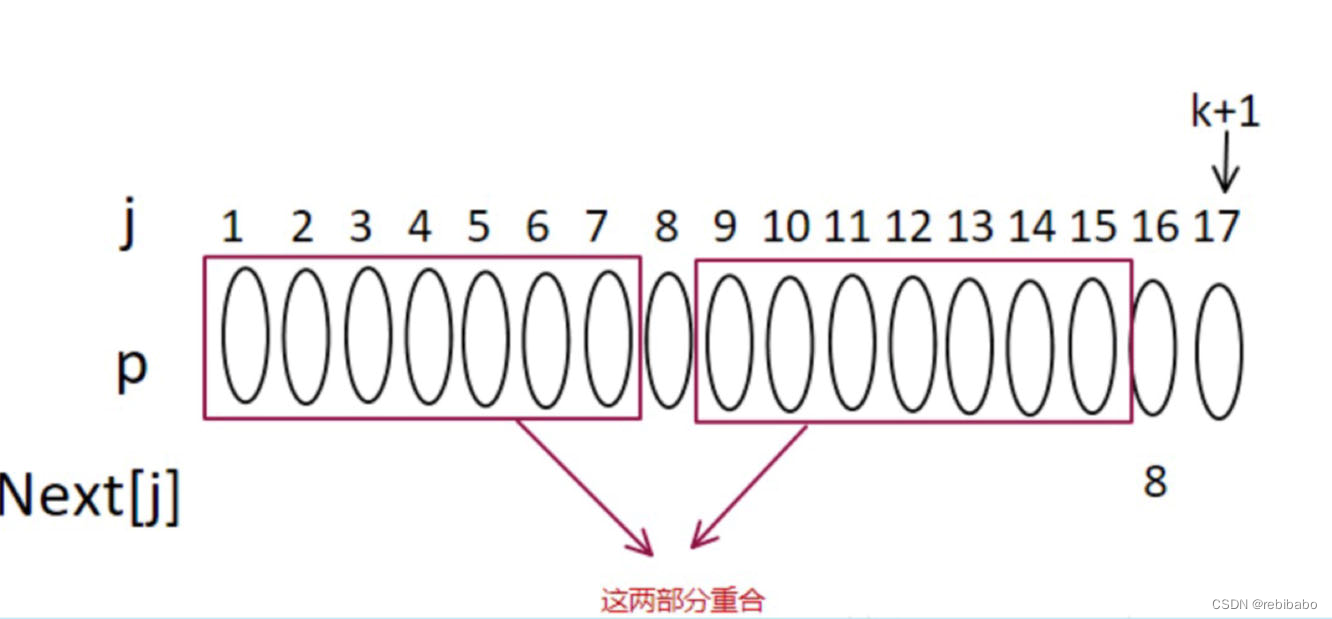
如果不相等,则看下图,假设
n
e
x
t
[
8
]
=
4
next[8]=4
next[8]=4,则蓝色框内的部分相同。
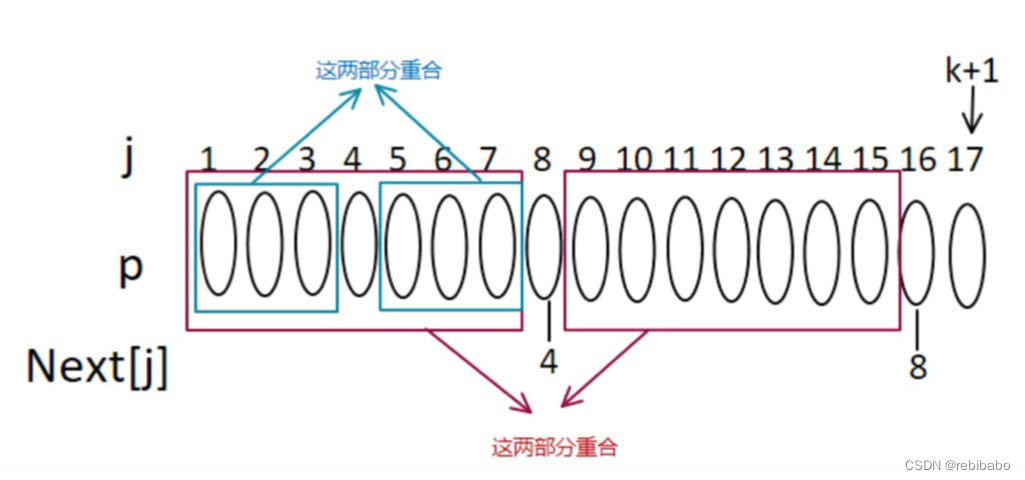
由于红色框内是对称的,所以可以得到下图中这四个蓝色框的部分相同,最左边的蓝色框和最右边蓝色框是重合的。
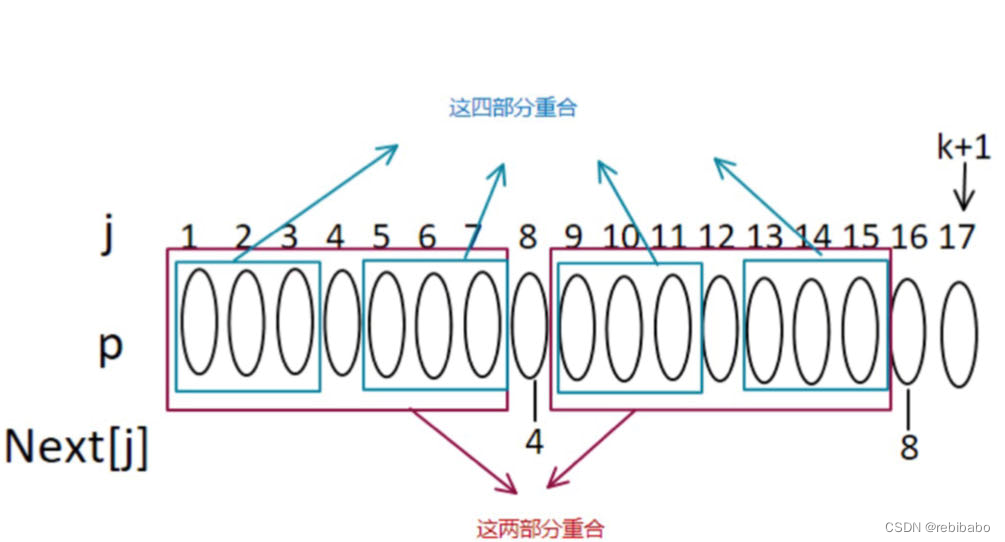
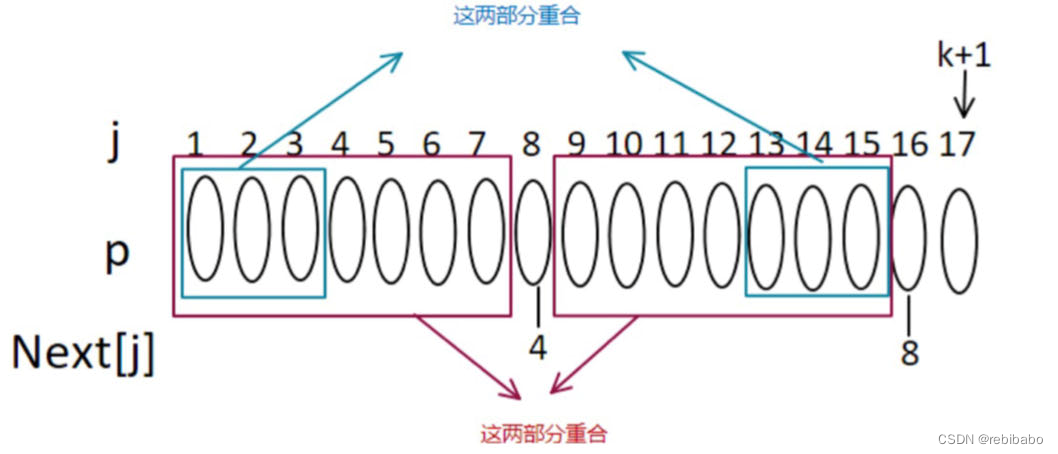
如果
p
[
4
]
=
=
p
[
16
]
p[4]==p[16]
p[4]==p[16],则
n
e
x
t
[
k
+
1
]
=
4
+
1
=
5
next[k+1]=4+1=5
next[k+1]=4+1=5,否则,继续看
n
e
x
t
[
4
]
next[4]
next[4],依此类推,直到下标变成了
0
0
0,
n
e
x
t
[
0
]
=
−
1
next[0]=-1
next[0]=−1。
下面是求 n e x t next next 数组的代码,真正要想理解就自己手动调试一遍,看看是如何求出 n e x t next next 数组的。
void getNext(string p, int *next){
int j,k;
next[0] = -1;
j = 0; //后串起始位置,一直增加
k = -1; //k==-1时,令next[1]=0,进入下一轮计算
while(j < p.size()){
if(k==-1 || p[j] == p[k]){
++j;
++k;
next[j] = k;
}
else
k = next[k];
}
}
完整代码展示
#include<iostream>
#include<string>
using namespace std;
int *next_arr;
void getNext(string p, int *next){
int j,k;
next[0] = -1;
j = 0; //后串起始位置,一直增加
k = -1; //k==-1时,令next[1]=0,进入下一轮计算
while(j < p.size()){
if(k==-1 || p[j] == p[k]){
++j;
++k;
next[j] = k;
}
else
k = next[k];
}
}
bool kmp(string s1, string key){
int i = 0, j = 0;
int l1 = s1.size(), l2 = key.size();
while((i < l1) && (j < l2)){
if(j == -1 || s1[i] == key[j]){
i++;
j++;
}
else{
j = next_arr[j];
}
}
if(j >= l2) return true;
else return false;
}
int main(void){
string s1 = "aaabaaabaaabaaad";
string s2 = "aaabaaad";
next_arr = (int*) malloc (s2.size()*4);
getNext(s2, next_arr);
cout<<kmp(s1, s2);
}















 661
661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











