







Abstract
识别像眼睛和喙这样的区分细节对于区分细粒度类很重要,因为它们有相似的整体外观。 在这方面,我们引入了任务差异最大化(TDM),这是一个用于细粒度少镜头分类的简单模块。 我们的目标是通过突出显示编码类别不同信息的通道来定位类别区分区域。 具体来说,TDM基于支持关注模块(SAM)和查询关注模块(QAM)两个新的组件来学习特定于任务的信道权重。 SAM产生支持权重来表示每个类的信道区分能力。 然而,由于SAM基本上只基于标记的支持集,它可能容易偏向于这种支持集。 因此,我们提出了QAM,它通过产生一个查询权重来补充SAM,该权重为给定查询图像的对象相关通道赋予更多的权重。 通过组合这两个权重,定义了一个基于类的特定于任务的通道权重。 然后将权值应用于任务自适应特征映射,更侧重于区分细节。 我们的实验验证了TDM在细粒度少镜头分类中的有效性及其与现有方法的互补优势。
总结:提出一种模块(TDM)来提高细粒度识别的准确度。
Introduction
少镜头分类的必要性
基于度量的学习流是少镜头分类的一个很有前途的方向。
应对少镜头分类的现有的策略。
现有的策略不适用于细粒度的分类。
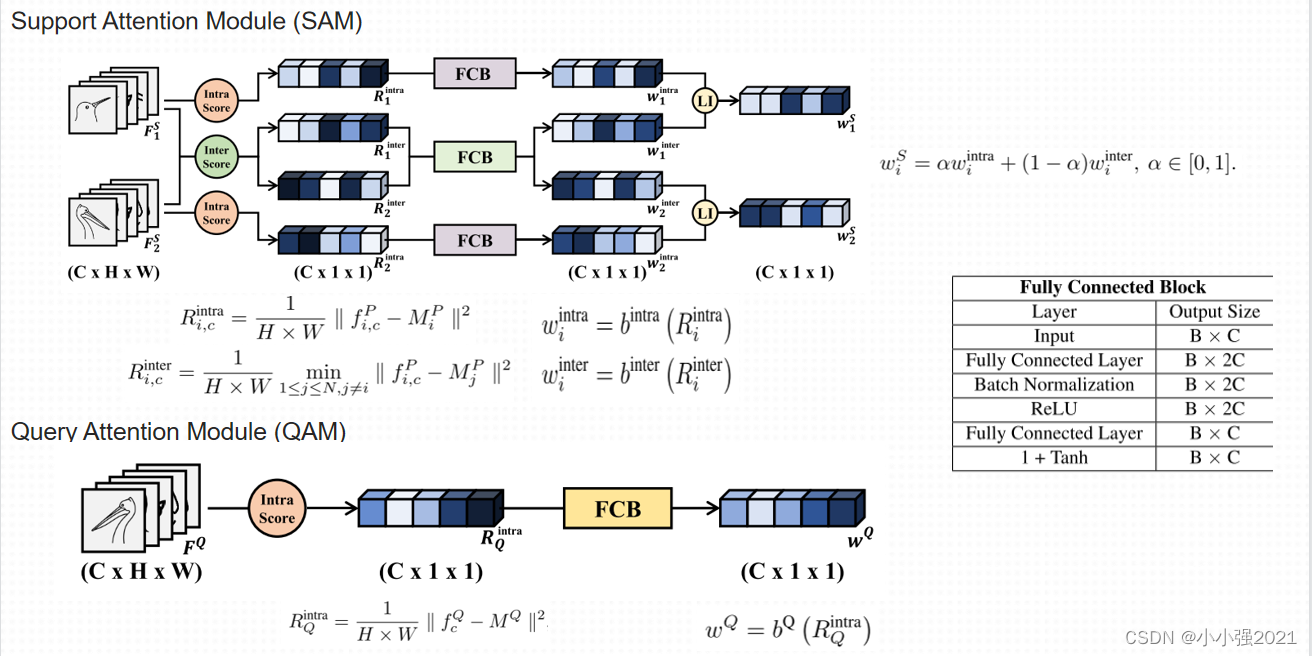
TDM,一种通过加权每个类别的通道来定位鉴别区域的模块。 TDM突出了代表区分区域的信道,并基于信道的分类权值抑制了其它信道的贡献。 具体来说,TDM由支持关注模块(SAM)和查询关注模块(QAM)两部分组成。 给定支持集,SAM输出每个类的支持权重,该权重在鉴别信道上呈现高激活度。 另一方面,向QAM提供查询集以产生每个实例的查询权重。 查询权重是突出显示与对象相关的通道。 为了推断这些权重,考虑了每个特征映射与平均信道集合特征之间的关系。 注意,信道池平均特征图具有如图中描述的对象的空间信息。因此,当通道与空间平均特征映射相似时,通道极有可能表示对象。 通过组合两个权重,最终定义了一个特定于任务的权重。并用该权重产生任务自适应的特征映射。

Related Works
Few-Shot Classification
少镜头分类的方法可分为两大主流:基于优化的方法和基于度量的方法。
基于度量的方法通过使用预定义的或在线训练的度量来学习深度表示。
基于度量的方法通常学习减少类中实例之间的距离,我们有同样的目标,因为TDM是它们的一个模块。 然而,TDM技术通过动态地识别有区别的信道,使得基于自适应信道权值的距离计算成为可能,而现有技术对所有信道都是一视同仁的。
Feature Alignment
特征对齐分为空间对齐和通道对齐,不同于考虑支持图像和查询图像之间成对关系的现有方法不同,TDM考虑整个任务来处理特征对齐。
Method
给定由支持和查询实例组成的事件,特征提取器首先计算特征映射。 然而,由于特征提取器被训练为寻找用于分类基类的鉴别特征,因此特征映射并不是对每一集都是最优的,TDM通过利用表示特定任务的信道区分能力的特定任务权值来转换特征映射。 因此,我们的目标是通过将原始特征映射细化为任务自适应特征映射来聚焦于可区分的细节。

图3。方法概述。 TDM由两个子模块组成。 每个子模块获取特征映射F并生成信道权重W。 支持关注模块利用支持实例的特征映射作为输入,并为每个类找到鉴别通道。 然后,它为第i个类别生成支持权重Wsi,其中权重在这些通道中具有较高的值。 另一方面,查询关注模块获得查询实例,并发现查询的对象相关通道。 然后,来自查询关注模块的查询权重WQ强调具有关于该查询的对象信息的特定通道。 这些来自两个子模块的权重通过线性组合被集成,以定义每个第i个类别的任务权重WT i。 最后,将任务权重与原始特征映射相乘,得到集中在识别区域上的任务自适应特征映射。
设置两个数据集,元训练数据集Dbase和元测试数据集Dnovel,Cbase和Cnovel分别代表基类和novel类。训练集和测试集是由episodes组成,而每一个episode由随机抽样的n类组成,且每一类中包含k个标记图像(这就是超参数中 n way k shot 的由来)。标记图像组成支持集,未标记图像组成查询集(训练集和测试集)————应用了元学习的策略。
Experiments……
略















 6773
6773











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











