






一、check_data 检测数据集都包含哪些类别以及各个类别的信息
import os
import shutil
import numpy as np
import pandas as pd
from tqdm import tqdm
import matplotlib.pyplot as plt
from collections import defaultdict
import xml.etree.ElementTree as ET
def check(year='VOC2007', show=False):
"""
输入数据文件名,返回有图没标注文件和有标注文件没图的数据路径
"""
######################################################################################################
##########################本节代码检查只有图或只有标注文件的情况##########################################
#######################################################################################################
data_path = os.path.join("VOCdevkit", year)
imgs_path = os.path.join(data_path, 'JPEGImages')
anns_path = os.path.join(data_path, 'Annotations')
# 获取图片文件
img_names = set([os.path.splitext(i)[0] for i in os.listdir(imgs_path)])
ann_names = set([os.path.splitext(i)[0] for i in os.listdir(anns_path)])
print(
"########################################################################################数据集{}检验结果如下:######################################################################################################".format(
year))
if not len(img_names):
print(' 该数据集没有图片')
return
img_ann = img_names - ann_names # 有图没标注文件
ann_img = ann_names - img_names # 有标注文件没有图
if len(img_ann):
print(" 有图片没标注文件的图片是:{} 等(只列前50个) 注意检查这些图片是否是背景图片".format({v for k, v in enumerate(img_ann) if k < 50}))
else:
print(" 所有图片都有对应标注文件")
if len(ann_img):
print(" 有标注文件没有图片的标注文件是:{}(只列前50个)".format({v for k, v in enumerate(ann_img) if k < 50}))
else:
print(" 所有标注文件都有对应图片")
#####################################################################################################
#######本节代码对于上节检查结果有问题的图片和标注文件统一移动到结果文件夹中进行下一步查看 ##################
#####################################################################################################
result_path = os.path.join(data_path, year + '_result')
if os.path.exists(result_path):
print(' 结果文件{}已经存在,请检查'.format(result_path))
else:
os.makedirs(result_path)
if len(ann_img) + len(img_ann):
# 把只有图或只有标注文件的数据集全部移出来
if (not os.path.exists(result_path)):
os.makedirs(result_path)
else:
print(' 存在有图无标注或有标注无图的文件,另结果文件{}已经存在,请检查'.format(result_path))
# return
img_anns = [os.path.join(imgs_path, i + '.jpg') for i in img_ann]
ann_imgs = [os.path.join(anns_path, i + '.xml') for i in ann_img]
if len(img_anns):
for img in img_anns:
shutil.move(img, result_path)
print(' 移动只有图无标注文件完成')
if len(ann_img):
for ann in ann_imgs:
shutil.move(ann, result_path)
print(' 移动只有标注文件无图完成')
###################################################################################################
##########本节内容提取分类文件夹标注文件夹中所有的分类类别,这个部分由于数据可能是#######################
##########多个人标的,所在对于使用数据的人还是要看一下分类的,很有必要 #######################
ann_names_new = [os.path.join(anns_path, i) for i in os.listdir(anns_path)] # 得新获取经过检查处理的标注文件
total_images_num = len(ann_names_new)
classes = list() # 用来存放所有的标注框的分类名称
img_boxes = list() # 用来存放单张图片的框的个数
hw_percents = list() # 用来存放图像的高宽比,因为图像是要进行resize的,所以可能会有resize和scaled resize区分
num_imgs = defaultdict(int) # 存放每个分类有多少张图片出现
num_boxes = dict() # 存放每个分类有多少个框出现
h_imgs = list() # 存放每张图的高
w_imgs = list() # 存放每张图的宽
area_imgs = list() # 存放每张图的面积
h_boxes = defaultdict(list) # 存放每个分类框的高
w_boxes = defaultdict(list) # 存放每个分类框的宽
area_boxes = defaultdict(list) # 存放每个分类框的面积
area_percents = defaultdict(list) # 存放每个分类框与图像面积的百分比
for ann in tqdm(ann_names_new):
try:
in_file = open(ann, encoding='utf-8')
tree = ET.parse(in_file)
except:
print(f"打开标注文件{ann}失败,文件将被处理")
shutil.move(ann, result_path)
im_path = os.path.join(ann.split(os.sep)[0], ann.split(os.sep)[1], 'JPEGImages',
os.path.splitext(ann)[0].split(os.sep)[-1] + '.jpg')
shutil.move(im_path, result_path)
continue
root = tree.getroot()
try:
size = root.find('size')
# print image_id
w = int(size.find('width').text)
h = int(size.find('height').text)
except:
print(f"取标注尺寸错误,标注文件{ann}将被处理")
shutil.move(ann, result_path)
im_path = os.path.join(ann.split(os.sep)[0], ann.split(os.sep)[1], 'JPEGImages',
os.path.splitext(ann)[0].split(os.sep)[-1] + '.jpg')
shutil.move(im_path, result_path)
continue
img_area = w * h
if img_area < 100:
print(f"有标注文件{ann}无图片尺寸,将被处理")
shutil.move(ann, result_path)
im_path = os.path.join(ann.split(os.sep)[0], ann.split(os.sep)[1], 'JPEGImages',
os.path.splitext(ann)[0].split(os.sep)[-1] + '.jpg')
shutil.move(im_path, result_path)
continue
img_boxes.append(len(root.findall('object')))
if not len(root.findall('object')):
print(f"有标注文件{ann}但没有标注物体,将被处理")
shutil.move(ann, result_path)
i_path = os.path.join(ann.split(os.sep)[0], ann.split(os.sep)[1], 'JPEGImages',
os.path.splitext(ann)[0].split(os.sep)[-1] + '.jpg')
shutil.move(i_path, result_path)
continue
img_classes = []
ok_flag = True
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls_name = obj.find('name').text
if isinstance(cls_name, type(None)):
print(f"标注框类名有问题,标注文件将被处理,类名:{cls_name},标注文件:{ann}")
shutil.move(ann, result_path)
ok_flag = False
continue
elif isinstance(cls_name, str) and len(cls_name) < 2:
ok_flag = False
print(f"标注框类名有问题,标注文件将被处理,类名:{cls_name},标注文件:{ann}")
shutil.move(ann, result_path)
continue
else:
pass
# if int(difficult) == 1:
# continue
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text)) # 左,右,上,下
if int(b[1] - b[0]) == 0 or int(b[3] - b[2]) == 0:
ok_flag = False
print(f"有零存在,框为点或直线,将被处理,边框:{b},标注文件:{ann},类名称:{cls_name},标注文件:{ann}")
shutil.move(ann, result_path)
box_area = (b[1] - b[0]) * (b[3] - b[2])
area_percent = round(np.sqrt(box_area / float(img_area)), 3) * 100
hw_percents.append(float(h / w))
if not (cls_name in classes):
classes.append(cls_name)
img_classes.append(cls_name)
num_boxes[cls_name] = num_boxes.get(cls_name, 0) + 1
h_boxes[cls_name].append(int(b[3] - b[2]))
w_boxes[cls_name].append(int(b[1] - b[0]))
area_boxes[cls_name].append(int(box_area))
area_percents[cls_name].append(area_percent)
if ok_flag:
h_imgs.append(h)
w_imgs.append(w)
area_imgs.append(img_area)
for img_cls_name in set(img_classes):
num_imgs[img_cls_name] = num_imgs.get(img_cls_name, 0) + 1
classes = sorted(classes)
print(
f"数据集{year}一共有{total_images_num}张合格的标注图片,{sum(img_boxes)}个标注框,平均每张图有{round(sum(img_boxes) / total_images_num, 2)}个标注框;一共有{len(classes)}个分类,分别是{classes};图片中标注框个数最少是{min(img_boxes)},\
最多是{max(img_boxes)}.图片高度最小值是{min(h_imgs)},最大值是{max(h_imgs)};图片宽度最小值是{min(w_imgs)},最大值是{max(w_imgs)};\
图片面积最小值是{min(area_imgs)},最大值是{max(area_imgs)} ;图片高宽比最小值是{round(min(hw_percents), 2)},图片高宽比最大值是{round(max(hw_percents), 2)}")
num_imgs_class = [num_imgs[class_name] for class_name in classes]
num_boxes_class = [num_boxes[class_name] for class_name in classes] # 各分类的标注框个数
min_h_boxes = [min(h_boxes[class_name]) for class_name in classes] # 各分类标注框高度最小值
max_h_boxes = [max(h_boxes[class_name]) for class_name in classes] # 各分类标注框高度最大值
min_w_boxes = [min(w_boxes[class_name]) for class_name in classes] # 各分类标注框宽度最小值
max_w_boxes = [max(w_boxes[class_name]) for class_name in classes] # 各分类标注框宽度最大值
min_area_boxes = [min(area_boxes[class_name]) for class_name in classes] # 各分类标注框面积最小值
max_area_boxes = [max(area_boxes[class_name]) for class_name in classes] # 各分类标注框面积最大值
min_area_percents = [min(area_percents[class_name]) for class_name in classes] # 各分类标注框面积与图像面积比最小值
max_area_percents = [max(area_percents[class_name]) for class_name in classes] # 各分类标注框面积与图像面积比最大值
result = {'cls_names': classes, 'images': num_imgs_class, 'objects': num_boxes_class, 'min_h_bbox': min_h_boxes,
'max_h_bbox': max_h_boxes, 'min_w_bbox': min_w_boxes,
'max_w_bbox': max_w_boxes, 'min_area_bbox': min_area_boxes, 'max_area_bbox': max_area_boxes,
'min_area_box/img': min_area_percents, 'max_area_box/img': max_area_percents}
# 显示所有列(参数设置为None代表显示所有行,也可以自行设置数字)
pd.set_option('display.max_columns', None)
# 显示所有行
pd.set_option('display.max_rows', None)
# 设置数据的显示长度,默认为50
pd.set_option('max_colwidth', 50)
# 禁止自动换行(设置为Flase不自动换行,True反之)
pd.set_option('expand_frame_repr', False)
result_df = pd.DataFrame(result)
print(result_df)
# plt.figure(figsize=(10.8,6.4))
# result_df.iloc[:,1:3].plot(kind='bar',)
if show:
##############################################画各个类别图片数与框数的直方图############################################################
plt.figure(figsize=(15, 6.4))
x1 = [i + 4 * i for i in range(len(classes))]
x2 = [i + 2 for i in x1]
y1 = [int(num_boxes[cl]) for cl in classes]
y2 = [int(num_imgs[cl]) for cl in classes]
lb1 = ["" for i in x1]
lb2 = classes
plt.bar(x1, y1, alpha=0.7, width=2, color='b', label='objects', tick_label=lb1)
plt.bar(x2, y2, alpha=0.7, width=2, color='r', label='images', tick_label=lb2)
plt.xticks(rotation=45)
# plt.axis('off')
plt.legend()
# plt.savefig
##############################################画单张图标注框数量的直方图################################################################
# 接着用直方图把这些结果画出来
plt.figure(figsize=(15, 6.4))
# 定义组数,默认60
# 定义一个间隔大小
a = 1
# 得出组数
group_num = int((max(img_boxes) - min(img_boxes)) / a)
n, bins, patches = plt.hist(x=img_boxes, bins=group_num, color='c', edgecolor='red', density=False, rwidth=0.8)
for k in range(len(n)):
plt.text(bins[k], n[k] * 1.02, int(n[k]), fontsize=12,
horizontalalignment="center") # 打标签,在合适的位置标注每个直方图上面样本数
# 组距
distance = int((max(img_boxes) - min(img_boxes)) / group_num)
if distance < 1:
distance = 1
plt.xticks(range(min(img_boxes), max(img_boxes) + 2, distance), fontsize=8)
# 辅助显示设置
plt.xlabel('number of bbox in each image')
plt.ylabel('image numbers')
plt.xticks(rotation=45)
plt.title(
f"The number of bbox min:{round(np.min(img_boxes), 2)},max:{round(np.max(img_boxes), 2)} \n mean:{round(np.mean(img_boxes), 2)} std:{round(np.std(img_boxes), 2)}")
plt.grid(True)
plt.tight_layout()
##############################################画单张图高宽比的直方图################################################################
plt.figure(figsize=(15, 6.4))
# 定义组数,默认60
a = 0.1
# 得出组数
group_num = int((max(hw_percents) - min(hw_percents)) / a)
n, bins, patches = plt.hist(x=hw_percents, bins=group_num, color='c', edgecolor='red', density=False,
rwidth=0.8)
for k in range(len(n)):
plt.text(bins[k], n[k] * 1.02, int(n[k]), fontsize=12,
horizontalalignment="center") # 打标签,在合适的位置标注每个直方图上面样本数
# 组距
distance = int((max(hw_percents) - min(hw_percents)) / group_num)
if distance < 1:
distance = 1
plt.xticks(range(int(min(hw_percents)), int(max(hw_percents)) + 2, distance), fontsize=8)
# 辅助显示设置
plt.xlabel('image height/width in each image')
plt.ylabel('image numbers')
plt.xticks(rotation=45)
plt.title(
f"image height/width min:{round(np.min(hw_percents))},max:{round(np.max(hw_percents), 2)} \n mean:{round(np.mean(hw_percents), 2)} std:{round(np.std(hw_percents), 2)}")
plt.grid(True)
plt.tight_layout()
##############################################画各个分类框图面积比直方图################################################################
plt.figure(figsize=(8 * 3, 8 * round(len(classes) / 3)))
for i, name in enumerate(classes):
plt.subplot(int(np.ceil(len(classes) / 3)), 3, i + 1)
# 定义组数,默认60
a = 5
# 得出组数
group_num = int((max(area_percents[name]) - min(area_percents[name])) / a)
n, bins, patches = plt.hist(x=area_percents[name], bins=group_num, color='c', edgecolor='red',
density=False, rwidth=0.8)
for k in range(len(n)):
plt.text(bins[k], n[k] * 1.02, int(n[k]), fontsize=12,
horizontalalignment="center") # 打标签,在合适的位置标注每个直方图上面样本数
# 组距
distance = int((max(area_percents[name]) - min(area_percents[name])) / group_num)
if distance < 1:
distance = 1
plt.xticks(range(int(min(area_percents[name])), int(max(area_percents[name])) + 2, distance), fontsize=8)
# 辅助显示设置
plt.xlabel('area percent bbox/img')
plt.ylabel('boxes numbers')
plt.xticks(rotation=45)
plt.title(
f"id {i + 1} class {name} area percent min:{round(np.min(area_percents[name]), 2)},max:{round(np.max(area_percents[name]), 2)} \n mean:{round(np.mean(area_percents[name]), 2)} std:{round(np.std(area_percents[name]), 2)}")
plt.grid(True)
plt.tight_layout()
check('VOC2007')
# 把数据集按照VOC的格式整理好放在根目录下,在代码末尾加上check('VOC2007'),然后直接运行代码就行了。
# 无对应图片以及xml文件也会输出检测结果。
#VOCdevkit/VOC2007
#├── Annotations
#├── ImageSets
#├── JPEGImages
运行结果示例如下
二、remove_some_class,移除数据集中的部分类别(原数据集会改变,移除的类别的图片和xml文件都会放在result_path文件夹下)
import os
import shutil
from tqdm import tqdm
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from collections import defaultdict
import xml.etree.ElementTree as ET
def remove_classes(year='VOC2007', classes=None):
"""
输入数据文件名,将指定分类数据移出
classes:如果是None,那么保持原数据集不变,否则是个列表,列出要移动的分类即可
"""
######################################################################################################
##########################本节代码检查只有图或只有标注文件的情况##########################################
#######################################################################################################
data_path = os.path.join("VOCdevkit", year)
imgs_path = os.path.join(data_path, 'JPEGImages')
anns_path = os.path.join(data_path, 'Annotations')
if not len(os.listdir(imgs_path)):
print(' 该数据集没有图片')
return
#####################################################################################################
###############################################################保存结果文件 ##########################
#####################################################################################################
result_path = os.path.join(data_path, year + '_result')
if os.path.exists(result_path):
print(' 结果文件{}已经存在,请检查'.format(result_path))
else:
os.makedirs(result_path)
if classes is not None:
source_anns = os.listdir(anns_path)
for source_ann in tqdm(source_anns):
tree = ET.parse(os.path.join(anns_path, source_ann))
root = tree.getroot()
result = root.findall("object")
for obj in result:
if obj.find("name").text in classes:
shutil.move(os.path.join(anns_path, source_ann), result_path)
img_path = os.path.join(data_path, 'JPEGImages', os.path.splitext(source_ann)[0]) + '.jpg'
shutil.move(img_path, result_path)
break
else:
pass
# 下面classes包含几类就会移除几类,数据集格式还是按照前面的VOC格式继续运行就可以
remove_classes(year='VOC2007',classes=['LabelQiPao'])
三、提取数据集中的一些类别(原数据集不变,提取出的类别的图片和xml文件都会放在result_path文件夹下)
import os
import xml.etree.ElementTree as ET
import shutil
from tqdm import tqdm
def get_needed_classes(source_dataset="VOCdevkit/VOC2007", dest_dataset="VOCdevkit/VOC2007_dest", classes=None):
"""
source_dataset:提取数据集位置
dest_daaset:提取后数据集存放位置
classes:列表,指定要提取的分类,所有出现在该参数中的类都会被提取,如果是None则复制整个数据集
"""
if os.path.exists(dest_dataset):
shutil.rmtree(dest_dataset)
os.mkdir(dest_dataset)
else:
os.mkdir(dest_dataset)
if classes is not None:
img_filepath = os.path.join(source_dataset, 'JPEGImages')
ann_filepath = os.path.join(source_dataset, 'Annotations')
img_savepath = os.path.join(dest_dataset, 'JPEGImages')
ann_savepath = os.path.join(dest_dataset, 'Annotations')
main_path = os.path.join(dest_dataset, "ImageSets/Main")
if not os.path.exists(img_savepath):
os.makedirs(img_savepath)
if not os.path.exists(ann_savepath):
os.makedirs(ann_savepath)
if not os.path.exists(main_path):
os.makedirs(main_path)
source_anns = os.listdir(ann_filepath)
for source_ann in tqdm(source_anns):
tree = ET.parse(os.path.join(ann_filepath, source_ann))
root = tree.getroot()
result = root.findall("object")
bool_num = 0
for obj in result:
if obj.find("name").text not in classes:
root.remove(obj)
else:
bool_num = 1
if bool_num:
tree.write(os.path.join(ann_savepath, source_ann))
name_img = os.path.splitext(source_ann)[0] + '.jpg'
shutil.copy(os.path.join(img_filepath, name_img), os.path.join(img_savepath, name_img))
else:
shutil.copytree(source_dataset, dest_dataset)
#把想要提取的类放在classes里面,其它不做改动,数据集格式还是上面VOC格式
get_needed_classes(classes=['Hook'])
四、对提取出来的部分类别修改其名称(需要先运行上面的提取代码,把需要修改的类别提取到VOC2007_dest文件夹下,然后在运行下面这段代码,注意只需修改classes和new_classes,运行完之后修改后的名称已经保存在VOC2007_dest文件中,将其xml标签文件复制回原文件即可)
import os
import xml.etree.ElementTree as ET
import shutil
from tqdm import tqdm
def get_needed_classes_change_name(source_dataset="VOCdevkit/VOC2007", dest_dataset="VOCdevkit/VOC2007_dest",
classes=None, new_classes=None):
"""
source_dataset:提取数据集位置
dest_daaset:提取后数据集存放位置
classes:指定要提取的分类,所有出现在该参数中的类都会被提取,如果是None则复制整个数据集
new_classes: 在classes 提取的分类中选取部分或全部进行修改,如果是None则不需要进行修改这个是默认的
"""
if os.path.exists(dest_dataset):
shutil.rmtree(dest_dataset)
os.mkdir(dest_dataset)
else:
os.mkdir(dest_dataset)
if classes is not None:
img_filepath = os.path.join(source_dataset, 'JPEGImages')
ann_filepath = os.path.join(source_dataset, 'Annotations')
img_savepath = os.path.join(dest_dataset, 'JPEGImages')
ann_savepath = os.path.join(dest_dataset, 'Annotations')
main_path = os.path.join(dest_dataset, "ImageSets/Main")
if not os.path.exists(img_savepath):
os.makedirs(img_savepath)
if not os.path.exists(ann_savepath):
os.makedirs(ann_savepath)
if not os.path.exists(main_path):
os.makedirs(main_path)
change = False
if new_classes:
change = True
for name in new_classes.keys():
if not name in classes:
print("要改的名称必须要在所提取的类别中")
return
source_anns = os.listdir(ann_filepath)
for source_ann in tqdm(source_anns):
tree = ET.parse(os.path.join(ann_filepath, source_ann))
root = tree.getroot()
result = root.findall("object")
bool_num = 0
for obj in result:
if obj.find("name").text not in classes:
root.remove(obj)
else:
if change and obj.find("name").text in new_classes.keys():
obj.find("name").text = new_classes[obj.find("name").text]
bool_num = 1
if bool_num:
tree.write(os.path.join(ann_savepath, source_ann), encoding='utf-8') # 写进原始的xml文件中,防止中文乱码
name_img = os.path.splitext(source_ann)[0] + '.jpg'
shutil.copy(os.path.join(img_filepath, name_img), os.path.join(img_savepath, name_img))
else:
shutil.copytree(source_dataset, dest_dataset)
get_needed_classes_change_name(source_dataset="VOCdevkit/VOC2007",dest_dataset="VOCdevkit/VOC2007_dest",classes=['Staight Sucker'],new_classes={"Staight Sucker":"Straight Sucker"})
示例:
get_needed_classes_change_name(source_dataset="VOCdevkit/VOC2007",dest_dataset="VOCdevkit/VOC2007_dest",classes=['Staight Sucker'],new_classes={"Staight Sucker":"Straight Sucker"})get_needed_classes_change_name(source_dataset="VOCdevkit/VOC2007",dest_dataset="VOCdevkit/VOC2007_dest",classes=['Biopolar'],new_classes={"Biopolar":"Bipolar"})五、视频切分为图片
import cv2
vc = cv2.VideoCapture(r'H:/cholec80_sub_tool_locations/video/video15.mp4') # 读入视频文件,命名cv,这里是要读入视频的位置
n = 0 # 计数
if vc.isOpened(): # 判断是否正常打开
rval, frame = vc.read()
else:
rval = False
timeF = 25 # 视频帧计数间隔频率
i = 0
while rval: # 循环读取视频帧
rval, frame = vc.read()
if (n % timeF == 0): # 每隔timeF帧进行存储操作
i += 1
print(i)
cv2.imwrite(r'H:/cholec80_sub_tool_locations/video_15/{}_{}_{}.jpg'.format('video15',i,n), frame) # video是图片名字,可以更换,i为第几张图片,n为第多少帧,
n = n + 1
cv2.waitKey(1)
vc.release()六、图片批量重命名
import os
class BatchRename():
'''
批量重命名文件夹中的图片文件
'''
def __init__(self):
self.path = 'C:/Users/YDD/Desktop/a' #表示需要命名处理的文件夹
self.new_path='C:/Users/YDD/Desktop/c' #表示重命名之后的新文件夹
def rename(self):
filelist = os.listdir(self.path) #获取文件路径
total_num = len(filelist) #获取文件长度(个数)
i = 1 #表示文件的命名是从1开始的
for item in filelist:
if item.endswith('.png'): #初始的图片的格式为jpg格式的(或者源文件是png格式及其他格式,后面的转换格式就可以调整为自己需要的格式即可)
src = os.path.join(os.path.abspath(self.path), item)
dst = os.path.join(os.path.abspath(self.new_path), 'video01' + '_' + str(i) + '.jpg')#处理后的格式也为jpg格式的,当然这里可以改成png格式
#dst = os.path.join(os.path.abspath(self.path), '0000' + format(str(i), '0>3s') + '.jpg') 这种情况下的命名格式为0000000.jpg形式,可以自主定义想要的格式
try:
os.rename(src, dst)
print ('converting %s to %s ...' % (src, dst))
i = i + 1
except:
continue
print ('total %d to rename & converted %d jpgs' % (total_num, i))
if __name__ == '__main__':
demo = BatchRename()
demo.rename()
# 直接改七八行的输入输出地址就可以了
# jpg和png可以随意改变,即可以把jpg格式变为png,也可以把png格式变为jpg
# 想要什么格式的名字可以在16行随意调整
# 还要注意运行完程序之后原理文件夹里的原图片就不复存在了,所以记得备份
七、xml转为txt
1、把split.py和voc_label.py两个文件放在yolov5根目录下
split.py
# split.py
# coding:utf-8
import os
import random
import argparse
parser = argparse.ArgumentParser()
path=''
#xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='datasets/mydata/images/', type=str, help='input xml label path')
#数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='datasets/mydata/', type=str, help='output txt label path')
opt = parser.parse_args()
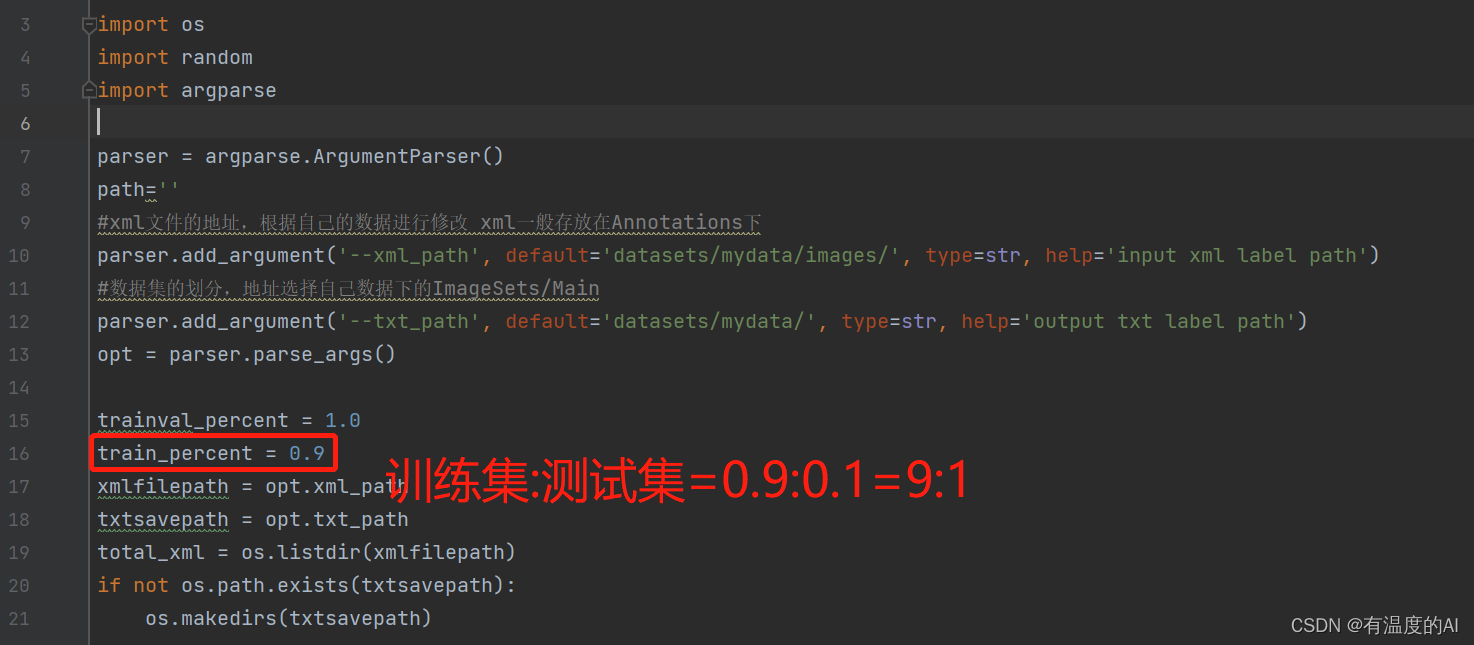
trainval_percent = 1.0
train_percent = 0.9
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
#file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in train:
file_train.write(path+name)
else:
file_val.write(path+name)
file_train.close()
file_val.close()
file_test.close()voc_label.py
# voc_label.py
import xml.etree.ElementTree as ET
import pickle
import os
import os.path
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test','val']
classes = ['Bipolar', 'Cottle Elevator', 'Dissector', 'Knife', 'Drill', 'Ring', 'Straight Sucker',
'Tumor Pliers', 'Up Scissors', 'Needle Monopolar']
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
if os.path.isfile('datasets/mydata/Annotations/%s.xml' % (image_id)):
in_file = open('datasets/mydata/Annotations/%s.xml' % (image_id))
out_file = open('datasets/mydata/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
print(wd)
for image_set in sets:
if not os.path.exists('datasets/mydata/labels/'):
os.makedirs('datasets/mydata/labels/')
image_ids = open('datasets/mydata/%s.txt' % (image_set)).read().strip().split()
list_file = open('datasets/mydata/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write('datasets/mydata/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()2、数据集摆放格式
#datasets/mydata
#├── Annotations
#├── Image
3、运行split.py
运行后

4、运行voc_label.py
classes修改为对应的类别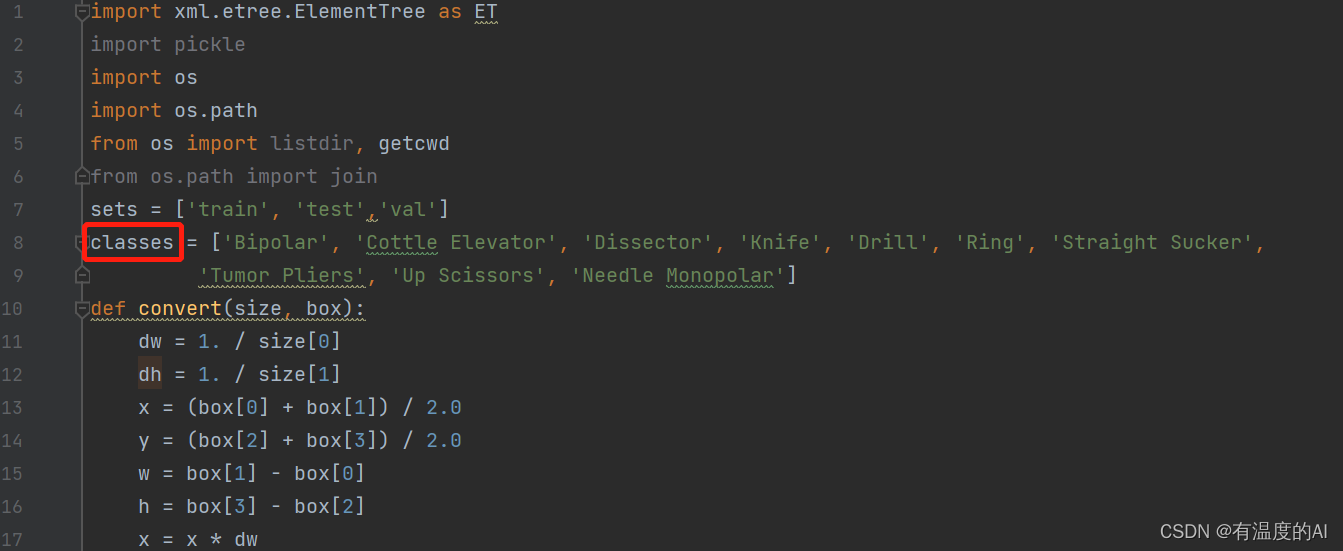
运行后















 6184
6184











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









