







前言
在这个网络发展快速的时代,我想问为什么你选择做程序员?有人说因为不善交际,也有人说最火的行业互联网,最好的职业程序员。确实在这个繁荣的行业,只要你自己不下船技术不水,就可以衣食无忧,努力努力说不定还能加薪升职,成为别人眼中的佼佼者,没多少行业如同程序员起薪高,也没有多少行业如同程序员涨薪快,没多少行业和程序员这个行业一样处处聚集高智力人群,身边都是工作上脑子转的飞快的人群。职场不讲政治只讲方案,对一些不善交际的人来说确实是一种轻松的活法。
为别人做事,那一份稳定的工资,对很多人来说不是很难接受的事情,怕就怕在当你人到了中年,发现自己被绑定在了这个行业绑定在了公司,一身专业技能到了出了公司根本用不到,甚至生活中的菜米油盐都和这个没有半毛钱关系,很久之前流行这么一句话‘世界那么大,我想去看看’这是某位任性的教师离职时的辞职信,很多人当年很佩服这位老师的潇洒,那是因为有选择自由的选择,而我们一离开程序员这个圈子,你会发现很多那些原本因为不善言辞而选择这个行业的人因为时间久了变成了生活中的巨婴,不善与人打交道,别人怪我们情商太低不会做事?这些算是程序员的悲哀吗,还算是市场圈子的潜移默化的影响?我曾遇到过一个人,本来因为不善言辞而选择的这个行业,后来因为这个圈子的氛围影响,回到家更不善和自己的爱人沟通,最后导致了婚姻的不幸。着实令人惋惜!
面试题
一般Android面试分为两部分:Java部分和Android部分,下面说一下自己面试过程遇到的一些具体题目和一些相关知识点。
一 JAVA相关
1)JAVA基础
1.java基本数据类型有哪些,int, long占几个字节
2.== 和 equals有什么区别
3.hashcode 和 equals作用
4.new String创建了几个对象
5.位运算符的一些计算
6.java的拆装箱
7.compareable 和 compartor的区别
下面列一两个遇到的题吧
2)数据结构和算法
常见的数据结构就是:数组,栈,队列,集合,映射,链表,堆,二分搜索树,红黑树。当然还有其他的一些,比如AVL平衡树等一些数据结构。
我们要做的就是了解它们的实现原理和各自的优缺点。
数据结构部分面试遇到最多的就是:
1.ArrayList和LinkedList的区别,优缺点
2.hashmap实现,扩容是怎么做的,怎么处理hash冲突,hashcode算法等
3.链表需要知道。LinkedHashMap一般再问LRU的时候会问到
4.二分搜索树的特性和原理。前中后序遍历写出其中一种,当问到二分搜索树的缺点的时候,你需要提出基于二分搜索树的红黑树,说出他的特性。
5.堆的实现,最大堆,最小堆,优先队列原理。
算法
算法其实就是我们平时常见的一些排序:选择排序,插入排序,冒泡排序,希尔排序,归并排序,快速排序。以及和数据结构相关联的解决部分问题的一些计算方法。
算法面试遇到的一些题:
1.手写快速排序,插入排序,冒泡排序
2.翻转一个数字
3.翻转一个链表
4.O(n)复杂度找出数组中和是9的两个数的索引
5.写出二分搜索树前中后序遍历中的其中一个
6.实现一个队列,并能记录队列中最大的数。
算法这一块是需要练习的推荐去Leetcode上面刷刷题,开拓一下思维。算法也并不一定要求你能写出来,主要考察你的思路,已经如何优化你的算法。
3)JVM虚拟机
JVM虚拟机我们需要知道他们内部组成:堆,虚拟机栈,本地方法栈,方法区,计数器。每一块都存放什么东西,以及垃圾回收的时候主要回收哪些块的东西。GC-ROOT链是从哪些地方开始的,垃圾回收集算法(很少遇到问的)。
类加载ClassLoader已经双亲委派机制,类加载的过程,类加载的信息对应在JVM的哪些块中。
4)线程安全
当多个线程访问一个对象的时候,如果不用考虑这些线程在运行时环境下的调度和交替执行,也不需要进行额外的同步,或者在调用方进行任何其他的协调操作,调用这个对象的行为都可以获取正确的结果,我们就认为这个对象时线程安全的。
线程安全就是一些多线程下载,同步,锁,死锁,线程池。volatile关键字的特性,变量的原子性。以及java.util.concurrent包下的类,也需要了解一下。
一般会问的是手写单例,以及双重锁式单例的优点。还有就是让你自己实现一个多线程下载,看你怎么设计。
5)编程思想
封装,继承,多态,抽象,反射,注解,设计模式,设计模式的原则。
面试中一般会问下:
1.抽象和接口有什么不一样
2.工作中常用的设计模式,一些源码中的设计模式
3.具体给你一个设计模式让你说说你对他的了解,比如观察者,工厂。
以上这些东西主要考察你的代码设计能力。
6)网络协议
1.互联网的实现主要分为几层,http、ftp、tcp、ip分别位于哪一层。
2.http和https的区别
3.为什么tcp要经过三次握手,四次挥手
4.socket了解过吗?
一般http和https问的比较多,对称加密和非对称加密也会问。tcp和socket偶尔遇见问的。
关于面试的充分准备
一些基础知识和理论肯定是要背的,要理解的背,用自己的语言总结一下背下来。
虽然 Android 没有前几年火热了,已经过去了会四大组件就能找到高薪职位的时代了。这只能说明 Android 中级以下的岗位饱和了,现在高级工程师还是比较缺少的,我能明显感觉到国庆后多了很多高级职位,所以努力让自己成为高级工程师才是最重要的。
好了,希望对大家有所帮助。
接下来是整理的一些Android学习资料,有兴趣的朋友们可以关注下我免费领取方式。
①Android开发核心知识点笔记
②对标“阿里 P7” 40W+年薪企业资深架构师成长学习路线图
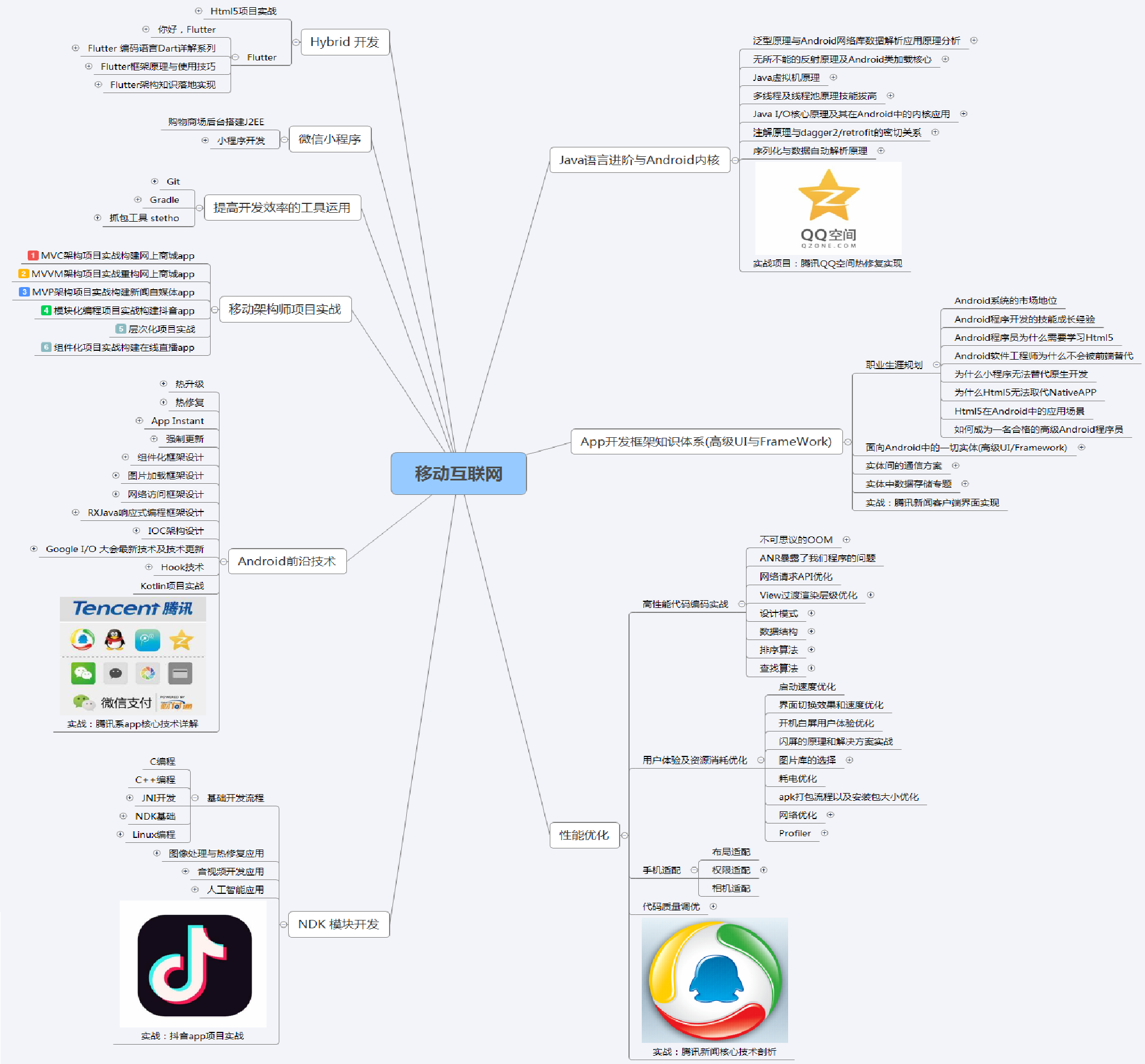
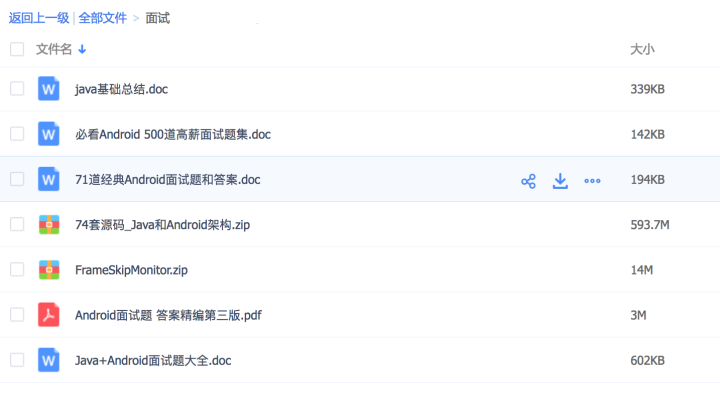
③面试精品集锦汇总
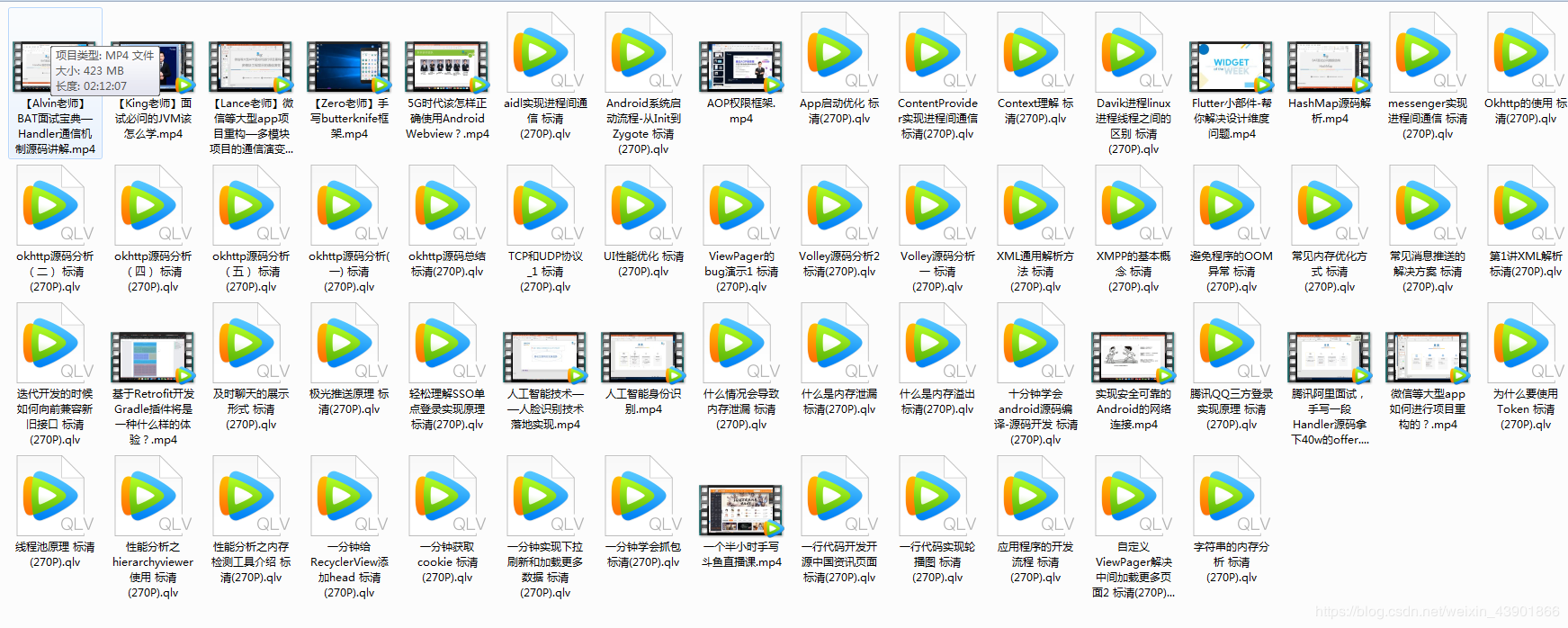
④全套体系化高级架构视频
**Android精讲视频领取学习后更加是如虎添翼!**进军BATJ大厂等(备战)!现在都说互联网寒冬,其实无非就是你上错了车,且穿的少(技能),要是你上对车,自身技术能力够强,公司换掉的代价大,怎么可能会被裁掉,都是淘汰末端的业务Curd而已!现如今市场上初级程序员泛滥,这套教程针对Android开发工程师1-6年的人员、正处于瓶颈期,想要年后突破自己涨薪的,进阶Android中高级、架构师对你更是如鱼得水,赶快领取吧!
获取方式:【Android架构视频+BAT面试专题PDF+学习笔记】
C%9A%E8%BF%99%E4%BA%9B%EF%BC%9F%E5%A6%82%E4%BD%95%E9%9D%A2%E8%AF%95%E6%8B%BF%E9%AB%98%E8%96%AA%EF%BC%81.md)】**















 1113
1113











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









