







概念结构设计
主要内容:[1]E-R图中如何确定实体与属性[2]集成E-R图时如何解决冲突
1 实体与属性的划分原则
[1]具体的应用环境常常对实体和属性已经作了自然的划分。
[2]为了简化E-R图的处置,现实世界的事物能作为属性对待的尽量作为属性对待。
[3]可以作为属性对待的事物应满足两条准则:
A 作为属性,不能再具有需要描述的性质
B 属性不能与其他实体具有联系
2 E-R图的集成
在开发一个在型信息系统时,最常采用的策略是自顶向下地进行需求分析,然后自底向上地设计概念结构。
即在设计E-R图时,首先设计各子系统的分E-R图,然后将它们集成起来,得到全局E-R图。
E-R图的集成一般需要分两步走:
•合并。
•修改和重构
(1)合并E-R图,生成初步E-R图
[1]冲突产生的原因。各个局部应用所面向的问题不同,且通常是由不同的设计人员进行局部设计,这就导致各个子系统的E-R图之间必定会存在许多不一致的地方,称之为冲突。合并E-R图必须着力消除冲突。
[2]冲突的种类。属性冲突、命名冲突和结构冲突。

(2)消除不必要的冗余,设计基本E-R图
在初步E-R图中,可能存在一些冗余的数据和实体间冗余的联系。
冗余数据是指可由基本数据导出的数据;
冗余联系是指可由其他联系导出的联系。
冗余数据和冗余联系容易破坏数据库的完整性,并且给数据库维护增加困难。
消除冗余的方法:
1)主要采用分析方法来消除冗余。
即以数据字典和数据流图为依据,根据数据字典中关于数据项之间逻辑关系的说明来消除冗余:
*消除能计算出的属性
*消除能够导出的联系
2)用规范化理论来消除冗余(教材了解)。
逻辑结构设计
逻辑结构设计的任务:
把概念结构设计阶段设计好的基本E-R图转换为与选用DBMS产品所支持的数据模型相符合的逻辑结构。这里只讨论向关系模型的转换。
设计逻辑结构的步骤:
[1]概念结构转换为数据模型(关系模型)
[2]对数据模型进行优化(满足第三范式即可)
[3]设计用户子模式
E-R图向关系模型转换
E-R图向关系模型的转换要解决的问题:
如何将实体型和实体间的联系转换为关系模式;
如何确定这些关系模式的属性和码。
转换方法(掌握,实际应用中重要):
E-R图由实体型、实体的属性和实体型之间的关系3个要素组成。
E-R图转换为关系模式,就是把这3要素转换为关系模式,具体方法:
1 一个实体型转换成一个关系模式,实体的属性即为关系的属性,实体的码就是关系的码。
2 对于实体型间的联系则有以下不同情况:
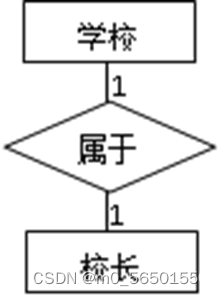
(1)一个1:1联系可以转换为一个独立的关系模式(各实体的码、联系本身的属性均转换为关系模式的属性,每个实体的码均可作为候选码),也可以与任意一端对应的关系模式合并(需要加入另一关系模式的码和联系本身的属性,码不变),推荐使用合并。
例:
实体型的转换:
学校(学校编号,学校名称,地址)
校长(校长ID,姓名,性别,出生日期)
实体间联系的转换:
方案一,独立的关系模式:学校责任人(学校编号,校长ID)
方案二,合并关系模式:学校(学校编号,学校名称,地址,校长ID)
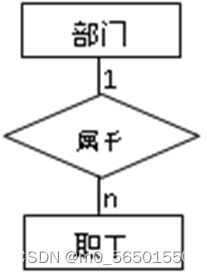
(2)一个1:n联系可以转换为一个独立的关系模式(各实体的码、联系本身的属性均转换为关系模式的属性,关系的码为n端的码),也可以与n端对应的关系模式合并(需要加入1端关系模式的码和联系本身的属性,码不变),推荐。
实体型的转换:
部门(部门号,部门名)
职工(职工号,职工名,职务)
实体间联系的转换:
方案一,部门职工(部门号,职工号),职工号为码(n端)
方案二,职工(职工号,职工名,职务,部门号)(只能于n端合并)
(3)一个m:n联系转换为关系模式(只能转换成独立的关系模式)。与该联系的各实体的码以及联系本身的属性均转换为关系的属性,各实体的码组成关系的码或关系码的一部分。
例:
学生选课。
实体型的转换:
实体之间联系的转换:
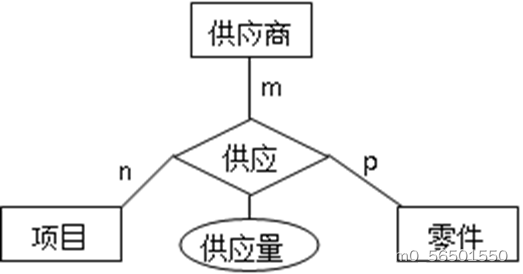
(4)三个或三个以上实体间的一个多元联系转换为一个关系模式。与该多元联系相连的各实体的码以及联系本身的属性均转换为关系的属性,各实体的码组成关系的码或关系码的一部分。
实体型的转换:
供应商(供应商号,供应商名, …… )
项目(项目号,项目名, …… )
零件(零件号,零件名, …… )
实体型:供应商,项目,零件
这些实体型间的关系,独立的转换成一个供应这个关系模式,椭圆代表实体型中的属性
实体之间联系的转换:
供应(供应商号,项目号,零件号,供应量,……)
(5)具有相同码的关系模式可以合并。
数据模型的优化
优化目的:提高数据库应用系统的性能。
优化指导:规范化理论。
优化方法(5点)
1)确定数据依赖(根据需求分析所得到的语义,写出每个关系模式内部各属性之间的数据依赖以及不同关系模式属性之间数据依赖。)。
2)对于各个关系模式之间的数据依赖进行极小化处理,消除冗余的联系。
3)按照数据依赖的理论对关系模式逐一进行分析,考查是否存在部分函数依赖、传递函数依赖、多值依赖等,确定各关系模式分别属于第几范式。
4)按照需求分析阶段得到的各种应用对数据处理的要求,分析对于这样的应用环境,这些模式是否合适,确定是否要对它们进行合并或分解。
并不是规范化程度越高的关系就越优。为了提高效率,要减少联接运算,一般需要符合3NF。
5)对关系模式进行必要的分解或合并,以提高数据操作的效率和存储空间的利用率。常用的两种分解方法是水平分解和垂直分解。
设计用户子模式
将概念模型转换为全局逻辑模型后,还应根据局部应用需求,设计用户外模式。视图是定义用户外模式的一个好工具。
定义数据库模式主要是从系统的时间效率、空间效率、易维护等角度出发。定义用户外模式时应该更注重考虑用户的习惯与方便。包括三个方面:
1)使用更符合用户习惯的别名。
2)可以对不同级别的用户定义不同的视图,以保证系统的安全性。
3)简化用户对系统的使用。(将复杂的查询定义为视图)
物理结构设计
数据库在物理设备上的存储结构与存取方法称为数据库的物理结构,它依赖于选定的数据库管理系统。
为一个给定的逻辑数据模型选取一个最适合应用要求的物理结构的过程,就是数据库的物理设计。
数据库物理设计步骤:
[1]确定数据库的物理结构。在关系数据库中主要指存取方法和存储结构;
[2]对物理结构进行评价,评价的重点是时间和空间效率。
数据库物理设计的内容和方法
没有通用的物理设计方法可遵循。(不同的数据库产品所提供的物理环境、存取方法和存储结构有很大差别)
(学生自学)
关系数据库物理设计的内容:
关系模式存取方法选择
存取方法是快速存取数据库中数据的技术。数据库管理系统一般都提供多种存取方法。常用的存取方法有三类:
1)索引方法,目前主要是B+树索引方法。
B+树索引法是数据库中经典的存取方法,使用最普遍。
2)聚簇(Cluster)方法
3)HASH方法
1 索引存取方法的选择
所谓选择索引存取方法实际上就是根据应用要求:确定对关系的哪些属性列建立索引,建立什么样的索引。规则:
1)如果一个(或一组)属性经常在查询条件中出现,则考虑在这个(或这组)属性上建立索引(或组合索引)。
2)如果一个属性经常作为最大值和最小值等聚集函数的参数,则考虑在这个属性上建立索引。
3)如果一个(或一组)属性经常在连接操作的连接条件中出现,则考虑在这个(或这组)属性上建立索引。
另外,关系上定义的索引并不是越多越好,系统为维护索引要付出代价,查找索引也要付出代价。更新频率很高的关系,不适合建立索引。
2 聚簇存取方法的选择
什么是聚簇?
为了提高某个属性(或属性组)的查询速度,把这个或这些属性(称为聚簇码)上具有相同值的元组集中存放在连续的物理块称为聚簇。
聚簇存取方法可以大大提高按聚簇码进行查询的效率,也可以大大提高按聚簇码进行连接操作的效率。
一个关系只能加入一个聚簇。
设计候选聚簇规则:
1)对经常在一起进行连接操作的关系可以建立聚簇;
2)如果一个关系的一组属性经常出现在相等比较条件中,则该单个关系可建立聚簇;
3)如果一个关系的一个(或一组)属性上的值重复率很高,则此单个关系可建立聚簇。即对应每个聚簇码值的平均元组数不太少。太少了,聚簇的效果不明显。
3 HASH存取方法的选择
有些数据库管理系统提供了HASH的存取方法,选择HASH存取方法的规则:
该关系的属性主要出现在等值连接条件中或主要出现在相等比较选择条件中,而且满足下列两个条件之一,则此关系可以选择HASH存取方法:
确定数据库的存储结构
确定数据库物理结构主要指确定数据的存放位置和存储结构。包括:确定关系、索引、聚簇、日志、备份等的存储安排和存储结构,确定系统配置等。
确定数据的存放位置和存储结构要综合考虑存取时间、存储空间利用率和维护代价3个方面的因素。
1 确定数据的存放位置。为了提高系统性能,应该根据应用情况将数据的易变部分与稳定部分、经常存取部分和存取频率较低部分分开存放。
2 确定系统配置。数据库管理系统一般都提供了一些系统配置变量和存储分配参数,应合理的进行配置。
评价物理结构
数据库物理设计过程中需要对时间效率、空间效率、维护代价和各种用户要求进行权衡,其结果可以产生多种方案。数据库设计人员必须对这些方案进行细致的评价,从中选择一个较优的方案作为数据库的物理结构。
课后自己掌握:
数据库编程:
存储函数、用户自定义函数、触发器

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









