







1. 数据库设计概述
数据库设计的目标是为用户和各种应用系统提供一个信息基础设施和高效率的运行环境
1.1 数据库设计的特点:结构和行为分离的设计
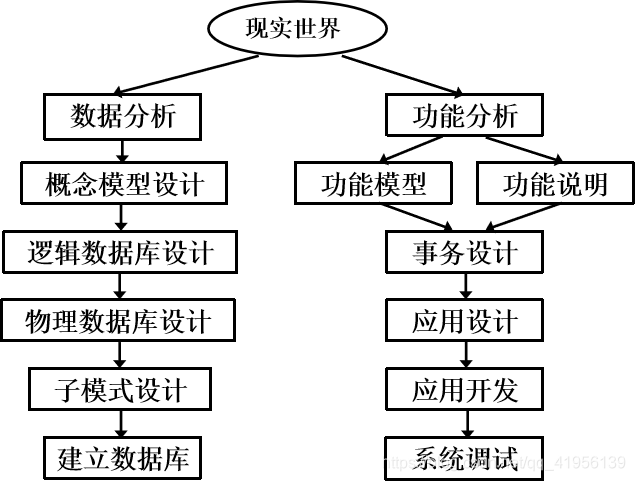
1.2 数据库设计方法
典型方法
新奥尔良(New Orleans)方法
基于E-R模型的数据库设计方法
3NF(第三范式)的设计方法
面向对象的数据库设计方法
统一建模语言(UML)方法
1.3 数据库设计的基本步骤
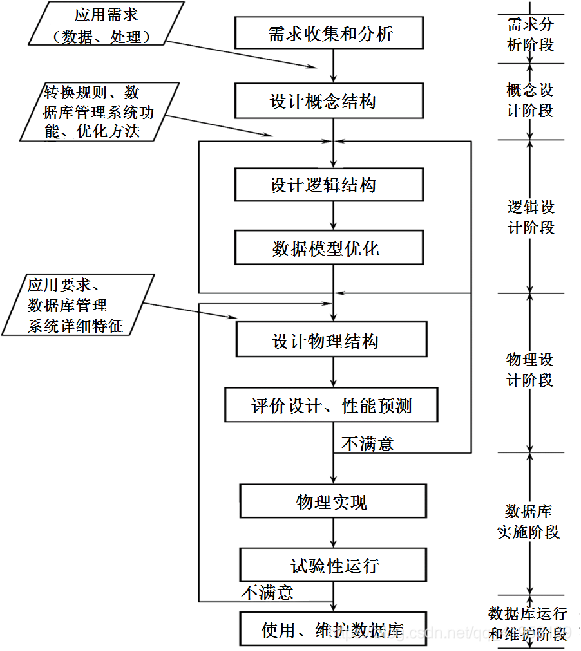
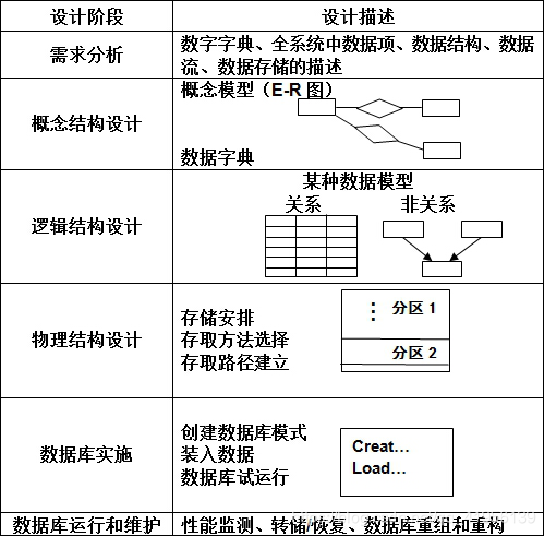
1.4 数据库设计过程中的各级模式
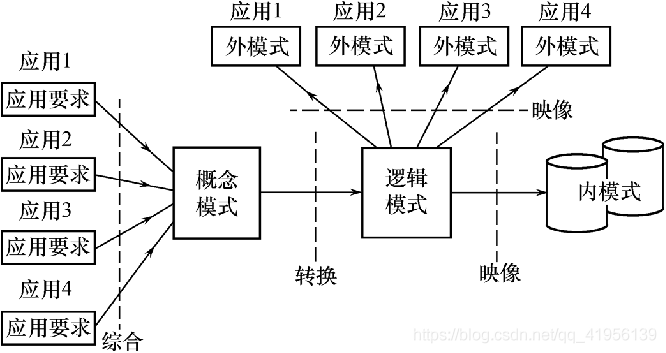
2. 需求分析
2.1 需求分析的任务
1、新系统必须充分考虑今后可能的扩充和改变
2、获得用户对数据库的要求
(1)信息要求
用户需要从数据库中获得信息的内容与性质
由信息要求可以导出数据要求,即在数据库中需要存储哪些数据
(2)处理要求
用户要完成的处理功能
对处理性能的要求
(3)安全性与完整性要求
2.2 需求分析的方法
结构化分析方法(Structured Analysis,简称SA方法)
SA方法从最上层的系统组织机构入手,采用自顶向下、逐层分解的方式分析系统
需求分析过程:
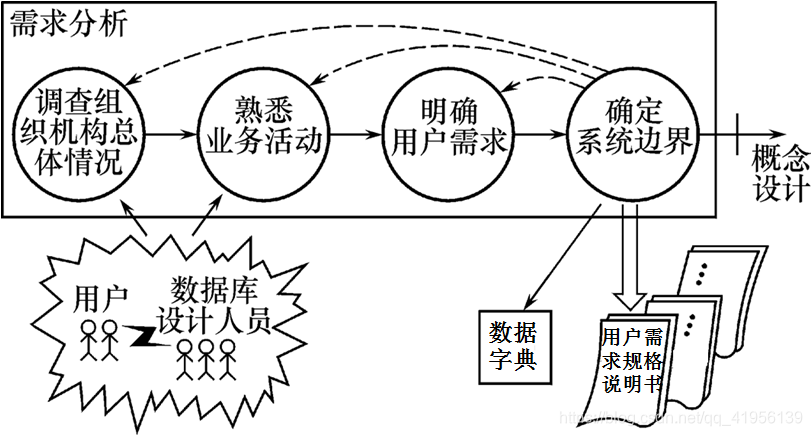
2.3 数据字典
1、数据字典是关于数据库中数据的描述,即元数据(不是数据本身),注意和关系数据库管理系统中数据字典的区别和联系(关系数据库中的数据字典是数据库的定义)
2、数据字典的内容
- 数据项:是数据的最小组成单位
- 数据结构:反映了数据之间的组合关系(一个数据结构可以由若干个数据项组成,也可以由若干个数据结构组成,或由若干个数据项和数据结构混合组成)
- 数据流:数据结构在系统内传输的路径
- 数据存储:是数据结构停留或保存的地方,也是数据流的来源和去向之一
- 处理过程:处理逻辑一般用判定表或判定树来描述
3、数据项描述={数据项名,数据项含义说明,别名,数据类型,长度,取值范围,取值含义,与其他数据项的逻辑关系, 数据项之间的联系}
4、数据结构描述={数据结构名,含义说明,组成:{数据项或数据结构}}
5、数据流描述={数据流名,说明,数据流来源,数据流去向,组成:{数据结构},平均流量,高峰期流量}
6、数据存储描述={数据存储名,说明,编号,输入的数据流 ,输出的数据流, 组成:{数据结构},数据量,存取频度,存取方式}
7、处理过程描述={处理过程名,说明,输入:{数据流}, 输出:{数据流},处理:{简要说明}}
3. 概念结构设计(概念模式,E-R图)
概念结构设计:将用户需求抽象为信息结构
3.1 概念模型
3.2 E-R模型
1、实体之间的联系
(1)两个实体型之间的联系:
①一对一联系(1∶1)
②一对多联系(1∶n)
③多对多联系(m∶n)
(2)两个以上的实体型之间的联系
一般地,两个以上的实体型之间也存在着一对一、一对多、多对多联系
(3)单个实体型内的联系
同一个实体集内的各实体之间也可以存在一对一、一对多、多对多的联系
2、E-R 图
E-R图提供了表示实体型、属性和联系的方法
实体型:矩形
属性:椭圆
联系:菱形(联系可以具有属性)
实例:某个工厂物资管理的概念模型
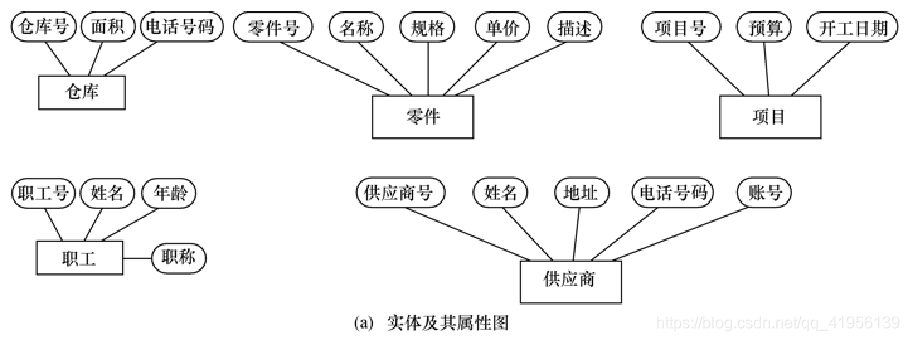
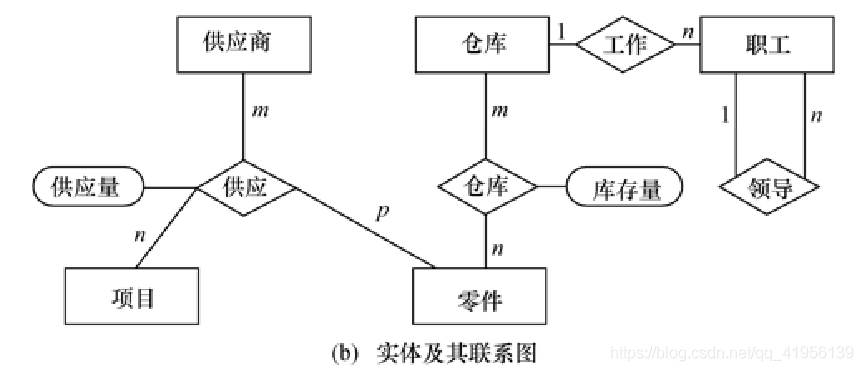
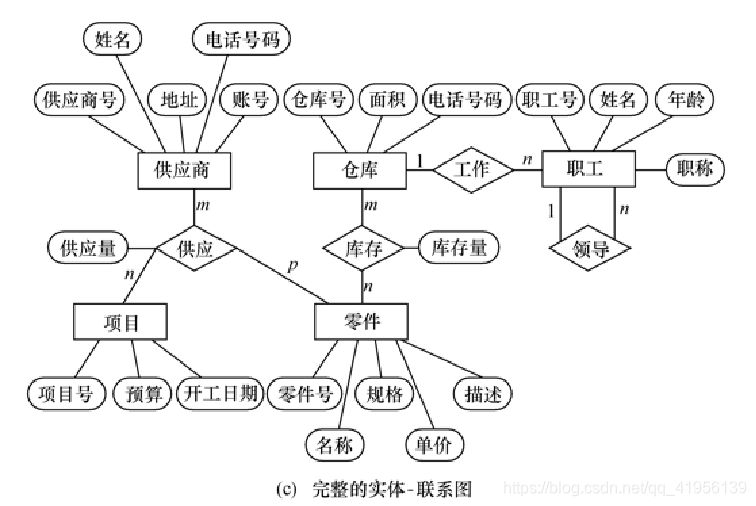
3、实体与属性的划分原则
为了简化E-R图的处置,现实世界的事物能作为属性对待的,尽量作为属性对待
两条准则:
(1)作为属性,不能再具有需要描述的性质。属性必须是不可分的数据项,不能包含其他属性
(2)属性不能与其他实体具有联系,即E-R图中所表示的联系是实体之间的联系
实例分析:
- 职称如果没有与工资、福利挂钩,根据准则(1)可以作为职工实体的属性;
- 如果不同的职称有不同的工资、住房标准和不同的附加福利,则职称作为一个实体更恰当
4、E-R 图的集成
1、两步:合并 --> 修改和重构
2、合并时主要有三类冲突:①属性冲突 ②命名冲突 ③结构冲突
属性冲突:属性域冲突,即属性值的类型、取值范围或取值集合不同;属性取值单位冲突
命名冲突:同名异义;异名同义;命名冲突
结构冲突:同一对象在不同应用中具有不同的抽象(如在A处为实体,在B处为属性);同一实体在不同子系统的E-R图中所包含的属性个数和属性排列次序不完全相同;实体间的联系在不同的E-R图中为不同的类型(如在A处为一对多联系,在B处为多对多联系)
3、合并时消除冗余的方法
①以数据字典和数据流图为依据,根据数据字典中关于数据项之间逻辑关系的说明来消除冗余
②用规范化理论来消除冗余
确定分E-R图实体之间的数据依赖FL;然后求FL的最小覆盖GL,差集为 D=FL-GL,逐一考察D中的函数依赖,确定是否是冗余的联系,若是,就把它去掉
4. 逻辑结构设计(逻辑模式、外模式)
把基本E-R图转换为与选用数据库管理系统产品所支持的数据模型相符合的逻辑结构
4.1 E-R图向关系模型的转换
关系模型的逻辑结构是一组关系模式的集合
将E-R图转换为关系模型:将实体型、实体的属性和实体型之间的联系转化为关系模式
1、转换原则
(1)一个实体型转换为一个关系模式
关系的属性:实体的属性
关系的码:实体的码
(2)实体型间的联系有以下不同情况
- 一个1:1联系可以转换为一个独立的关系模式,也可以与任意一端对应的关系模式合并
① 转换为一个独立的关系模式
关系的属性:与该联系相连的各实体的码以及联系本身的属性
关系的候选码:每个实体的码均是该关系的候选码
②与某一端实体对应的关系模式合并
合并后关系的属性:加入对应关系的码和联系本身的属性
合并后关系的码:不变 - 一个1:n联系可以转换为一个独立的关系模式,也可以与n端对应的关系模式合并
①转换为一个独立的关系模式
关系的属性:与该联系相连的各实体的码以及联系本身的属性
关系的码:n端实体的码
②与n端对应的关系模式合并
合并后关系的属性:在n端关系中加入1端关系的码和联系本身的属性
合并后关系的码:不变
可以减少系统中的关系个数,一般情况下更倾向于采用这种方法 - 一个m:n联系转换为一个关系模式
关系的属性:与该联系相连的各实体的码以及联系本身的属性
关系的码:各实体码的组合 - 三个或三个以上实体间的一个多元联系转换为一个关系模式
关系的属性:与该多元联系相连的各实体的码以及联系本身的属性
关系的码:各实体码的组合 - 具有相同码的关系模式可合并
目的:减少系统中的关系个数
合并方法:
将其中一个关系模式的全部属性加入到另一个关系模式中;
然后去掉其中的同义属性(可能同名也可能不同名);
适当调整属性的次序
4.2 数据模型的优化
得到初步数据模型后,还应该适当地修改、调整数据模型的结构,以进一步提高数据库应用系统的性能,这就是数据模型的优化
优化数据模型的方法:
(1)确定数据依赖
(2)对于各个关系模式之间的数据依赖进行极小化处理,消除冗余的联系
(3)按照数据依赖的理论对关系模式进行分析,考察是否存在部分函数依赖、传递函数依赖、多值依赖等,确定各关系模式分别属于第几范式
(4)按照需求分析阶段得到的各种应用对数据处理的要求,分析对于这样的应用环境这些模式是否合适,确定是否要对它们进行合并或分解(并不是规范化程度越高的关系就越优)
(5)对关系模式进行必要分解,提高数据操作效率和存储空间的利用率。常用分解方法:水平分解(把(基本)关系的元组分为若干子集合,定义每个子集合为一个子关系),垂直分解(把关系模式R的属性分解为若干子集合,形成若干子关系模式)
补充: 函数依赖和范式
一、函数依赖
1、部分函数依赖:设X,Y是关系R的两个属性集合,存在X→Y,若X’是X的真子集,存在X’→Y,则称Y部分函数依赖于X。
举个例子:学生基本信息表R中(学号,身份证号,姓名)当然学号属性取值是唯一的,在R关系中,(学号,身份证号)->(姓名),(学号)->(姓名),(身份证号)->(姓名);所以姓名部分函数依赖与(学号,身份证号);
2、完全函数依赖:设X,Y是关系R的两个属性集合,X’是X的真子集,存在X→Y,但对每一个X’都有X’!→Y,则称Y完全函数依赖于X。
例子:学生基本信息表R(学号,班级,姓名)假设不同的班级学号有相同的,班级内学号不能相同,在R关系中,(学号,班级)->(姓名),但是(学号)->(姓名)不成立,(班级)->(姓名)不成立,所以姓名完全函数依赖与(学号,班级);
3、传递函数依赖:设X,Y,Z是关系R中互不相同的属性集合,存在X→Y(Y !→X),Y→Z,则称Z传递函数依赖于X。
例子:在关系R(学号 ,宿舍, 费用)中,(学号)->(宿舍),宿舍!=学号,(宿舍)->(费用),费用!=宿舍,所以符合传递函数的要求。
4、平凡函数依赖:存在X→Y,且Y含于X,则称X→Y是平凡的函数依赖(对于任一关系模式,平凡函数依赖都是必然成立的,它不反映新的语义)
例子:(学号,课程号)→学号
5、非平凡函数依赖:存在X→Y,但Y不含于X,则称X→Y是非平凡的函数依赖
例子:(学号,课程号)→成绩
6、多值依赖:设R(U)是一个属性集合U上的一个关系模式,X, Y, 和Z是U的子集,并且Z=U-X-Y,多值依赖X→→Y成立当且仅当对R的任一个关系r,r在(X,Z)上的每个值对应一组Y的值,这组值仅仅决定于X值而与Z值无关。
若X→→Y,而Z=空集,则称X→→Y为平凡的多值依赖。否则,称X→→Y为非平凡的多值依赖。
(定义很绕~~脑阔疼)
举个例子,通俗理解一下:一个关系(课程C,教师T,参考书B),其中,课程确定教师且与参考书无关(即对于C的每一个值,T有 一组 值与之对应,而不论B取何值)
教师T多值依赖于课程C
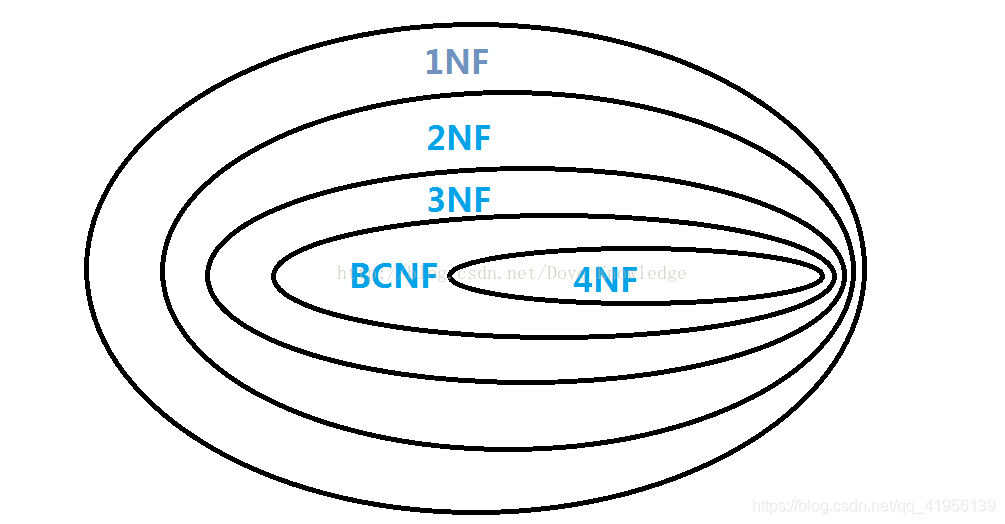
二、范式 1 、第一范式(1NF) 在任何一个关系数据库中,第一范式(1NF)是对关系模式的基本要求,不满足第一范式(1NF)的数据库就不是关系数据库。 所谓第一范式(1NF)是指数据库**表的每一列(即每个属性)都是不可分割的基本数据项**,同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性。简而言之,第一范式就是无重复的列。 2、 第二范式(2NF) 第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。第二范式(2NF)要求数据库**表中的每个实例或行必须可以被唯一地区分**。为实现区分通常需要为表加上一个列,以存储各个实例的唯一标识。员工信息表中加上了员工编号(emp_id)列,因为每个员工的员工编号是唯一的,因此每个员工可以被唯一区分。这个**唯一属性列被称为主关键字或主键、主码**。 **第二范式(2NF)要求实体的属性完全依赖于主关键字**。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性,如果存在,那么这个属性和主关键字的这一部分应该分离出来形成一个新的实体,新实体与原实体之间是一对多的关系。为实现区分通常需要为表加上一个列,以存储各个实例的唯一标识。简而言之,第二范式就是非主属性完全依赖于码。 3 、第三范式(3NF) 满足第三范式(3NF)必须先满足第二范式(2NF)。在满足第二范式的基础上,且**不存在传递函数依赖**,那么就是第三范式。简而言之,每一个非主属性既不部分依赖于码也不传递依赖于码。 4、BC范式(BCNF) BCNF 在第三范式的基础上,数据库表中如果不存在任何字段对任一候选关键字段的传递函数依赖则符合第三范式。
* 所有非主属性对每一个码都是完全函数依赖;
* 所有的主属性对于每一个不包含它的码,也是完全函数依赖;
* 没有任何属性完全函数依赖于非码的任何一组属性
>5、第四范式(4NF)
设R是一个关系模型,D是R上的多值依赖集合。如果D中存在凡多值依>赖X->Y时,X必是R的超键,那么称R是第四范式的模式。
最后简单的总结一下:
1、第一范式(1NF):一个关系模式R的所有属性都是不可分的基本数据项
2、第二范式(2NF):关系模式R属于第一范式,且每个非主属性都完全函数依赖于键码(简单说 建立在第一范式基础上,消除部分依赖)
3、第三范式(3NF):关系模式R属于第一范式,且每个非主属性都不传递依赖于键码(简单说 建立在第二范式基础上,消除传递依赖)
4、 BC范式(BCNF):关系模式R属于第一范式,且每个属性都不传递依赖于R的候选键
4.3 设计用户子模式
定义用户外模式时应该更注重考虑用户的习惯与方便。包括三个方面:
(1)使用更符合用户习惯的别名
(2)针对不同级别的用户定义不同的视图,以保证系统的安全性
(3)简化用户对系统的使用
5. 物理结构设计(内模式)
为一个给定的逻辑数据模型选取一个最适合应用要求的物理结构的过程,就是数据库的物理设计。
数据库物理设计的步骤:
(1)确定数据库的物理结构:在关系数据库中主要指存取方法和存储结构
(2)对物理结构进行评价:评价的重点是时间和空间效率
5.2 关系模式存取方法选择
1、数据库管理系统常用存取方法
(1)B+树索引存取方法
(2)Hash索引存取方法
(3)聚簇存取方法
2、选择索引存取方法的主要内容
(1)对哪些属性列建立索引
(2)对哪些属性列建立组合索引
(3)对哪些索引要设计为唯一索引
3、选择索引存取方法的一般规则
(1)一个(或一组)属性经常在查询条件中出现
(2)一个属性经常作为最大值和最小值等聚集函数的参数
(3)一个(或一组)属性经常在连接操作的连接条件中出现
4、选择Hash存取方法的规则
如果一个关系的属性主要出现在等值连接条件中或主要出现在等值比较选择条件中,而且满足下列两个条件之一
(1)该关系的大小可预知,而且不变
(2)该关系的大小动态改变,但所选用的数据库管理系统提供了动态Hash存取方法
5、聚簇存取
为了提高某个属性(或属性组)的查询速度,把这个或这些属性(称为聚簇码)上具有相同值的元组集中存放在连续的物理块中称为聚簇。该属性(或属性组)称为聚簇码
(1)聚簇索引
建立聚簇索引后,基表中数据也需要按指定的聚簇属性值的升序或降序存放,在一个基本表上最多只能建立一个聚簇索引
(2)聚簇存取方法
- 设计候选聚簇:场景——经常进行连接操作的关系、经常作为相等比较条件的属性组、属性或属性组中值重复率较高
- 检查候选聚簇中的关系,取消其中不必要的关系:删除经常进行全表扫描的关系、删除更新操作远多于连接操作的关系、删除重复出现的关系
5.3 确定数据库的存储结构
确定数据库物理结构主要指确定数据的存放位置和存储结构
基本原则:根据应用情况,将易变部分与稳定部分分开存放,将经常存取部分与存取频率较低部分分开存放
例如:可以将比较大的表分别放在两个磁盘上,以加快存取速度,这在多用户环境下特别有效;可以将日志文件与数据库对象(表、索引等)放在不同的磁盘以改进系统的性能
5.4 评价物理结构
对数据库物理设计过程中产生的多种方案进行评价,从中选择一个较优的方案作为数据库的物理结构
评价方法:定量估算各种方案的存储空间、存取时间、维护代价















 1754
1754











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









