






并发处理、数据库操作、缓存使用、消息队列、分布式服务框架
企业在招聘时不仅考量技术能力和相关经验,还注重候选人的学历背景和个人素质,并通过多轮面试来综合评估其技术广度、深度及是否符合公司文化。求职者需提升自身技术水平以满足现代企业的多元化需求。
redis的话,你能不能讲讲它的一个核心的一个原理呢?它的这个线程模型是什么,对不对?然后你能不能讲一下,如果说我把它给部署成一个集群,那么这个redis它的这个集群架构的一个原理是什么?然后要保证这个redis可以抗高并是为什么要让这个redis整个集群可以呈现一个高可用的这样的一个架构,那么应该怎么来实现?这个redis里面把这个数据落地磁盘的时候,它的这个策略是怎么来做的
MQ,你们平时是怎么做技术选型的?然后你怎么来你怎么能够保证这个MQ是高可用的?你怎么能保证我写的MQ里的消息它是不会丢的呢?你怎么来保证我写到MQ里的消息它是有顺序的呢?如果说整个MQ里面出现了大量消息的一个积压,然后这个时候的话,你应该怎么来处理呢?那如果让你自己来写个MQ,你应该怎么来实现,对不对?
公司在招聘这个候选人的时候,非常重要的一点考量。也就是说根据自己的这个项目的一个技术体系去反推一套知识体系,拿这套知识体系的话去考察候选人,希望候选人能满足这套知识体系。然后进来了以后快上手就直接可以开始干活了。
其实几轮面试就是想找一个从技术到学历、到履历、到经验,到人的这个性格,然后到价值观,各方面的这个东西都跟自己相对来说比较匹配。进来以后他上手就可以开始干活了。
==和equals比较
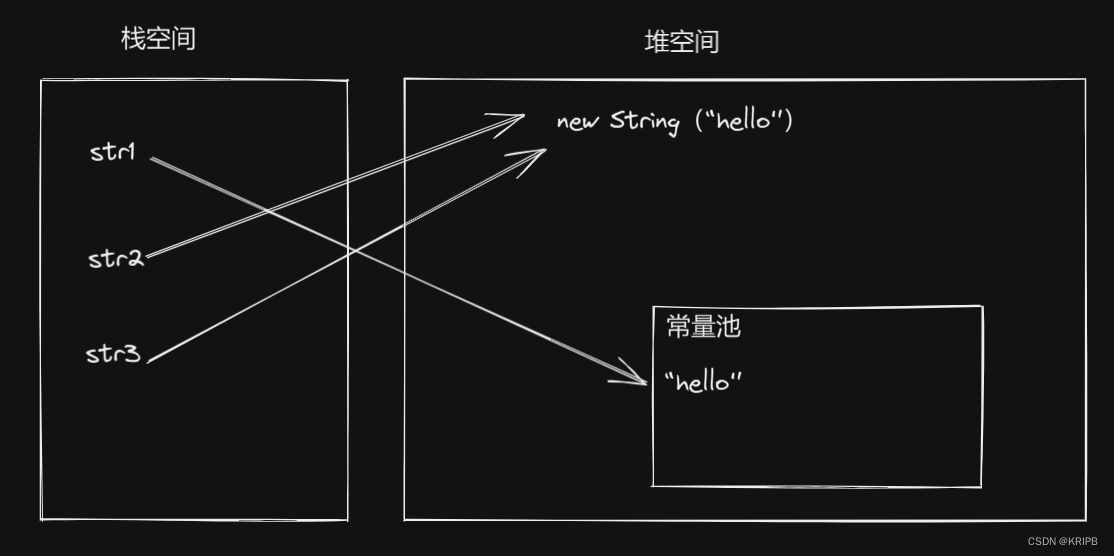
==对比的是栈中的值,如果是基本数据类型则对比的是变量值,如果是引用类型则对比的是堆中内存对象的地址
equals:objecte中默认也是采用==比较,但是通常会重写(这个时候对比的内容是字符串里的内容,因此后三个比较的结果都是true)
默认情况下,Java 中的 Object 类的 equals 方法实现是使用 == 操作符比较两个对象的引用是否相同,它比较的是两个对象的内存地址是否一致。这意味着如果两个对象不是同一个实例(即它们在内存中的位置不同),即使它们的内容相同,equals 方法也会返回 false。然而,通常我们会重写 Object 类的 equals 方法,以便根据对象的内容来比较它们的等价性。重写 equals 方法时,我们通常会比较对象的属性值是否相等。例如,如果有两个 String 对象,即使它们不是同一个实例,但它们包含的文本内容相同,也认为它们是等价的。

ArrayList和LinkedList的区别
ArrayList:基于动态数组,连续内存存储,适合下标访问(随机访问),扩容机制:因为数组长度固定,超出长度存数据时需要新建数组,然后将老数组的数据拷贝到新数组,如果不是尾部插入数据还会涉及到元素的移动(往后复制一份,插入新元素),使用尾插法并指定初始容量可以极大提升性能、甚至超过linkedList(需要创建大量的node对象)
LinkedList:基于链表,可以存储在分散的内存中,适合做数据插入及删除操作,不适合查询:需要逐一遍历。遍历LinkedList必须使用iterator(迭代器),不能使用for循环,因为每次for循环体内通过get(i)取得某一元素时都需要对list重新进行遍历,性能消耗极大(for循环的这个数据结构,它是用这种链表去存储的)。另外不要试图使用indexOf等返回元素索引,并利用其进行遍历,使用indexOf对list进行了遍历,当结果为空时会遍历整个列表。LinkedList里边维护了一个node的一个内部类。它每一个节点每插入一个元素,哪怕你是插入个123这个数字,它都会创建一个node对象。所以说这个LinkedList它如果是大量数据去进行插入的话,那么需要创建大量的node对象,需要创建大量的节点。创建对象的消耗是比较大的。
LinkedList虽然在插入操作上有劣势,但在大规模数据插入时,通过精确使用ArrayList(就是空间大小分配好后并且使用尾插插入数据),其实现性能可能会超越LinkedList
因为每一个元素在这个数组中占的这个内存长度它是一样的,它又是一个连续的。所以用下标去做访问的时候它会非常的快。
ArrayList和LinkedList有哪些区别
1.首先,他们的底层数据结构不同,ArrayList底层是基于数组实现的,LinkedList底层是基于链表实现的
2.由于底层数据结构不同,他们所适用的场景也不同,ArrayList更适合随机查找,LinkedList更适合删除和添加,查询、添加、删除的时间复杂度不同
3.另外ArrayList和LinkedList都实现了List接口,但是LinkedList还额外实现了Deque接口,所以LinkedList还可以当做队列来使用
ConcurrentHashMap的扩容机制
1.7版本
1.1.7版本的ConcurrentHashMap是基于Segment分段实现的
2.每个Segment相对于一个小型的HashMap
3.每个Segment内部会进行扩容,和HashMap的扩容逻辑类似
4.先生成新的数组,然后转移元素到新数组中
5.扩容的判断也是每个Segment内部单独判断的,判断是否超过阈值
1.8版本
1.1.8版本的ConcurrentHashMap不再基于Segment实现
2.当某个线程进行put时,如果发现ConcurrentHashMap正在进行扩容那么该线程一起进行扩容
3.如果某个线程put时,发现没有正在进行扩容,则将key-value添加到ConcurrentHashMap中,然后判断是否超过阀值,超过了则进行扩容
4.ConcurrentHashMap是支持多个线程同时扩容的
5.扩容之前也先生成一个新的数组
6.在转移元素时,先将原数组分组,将每组分给不同的线程来进行元素的转移,每个线程负责一组或多组的元素转移工作
java并发
ConcurrentHashMap实现线程安全的底层原理到底是什么?
synchronized关键字的底层原理以及跟Lock锁之间的区别?
你对JDK中的AQS理解吗?AQS的实现原理是什么?
线程池的底层工作原理可以吗?
线程池的核心配置参数都是干什么的?平时我们应该怎么用?
如果线程池的队列满了之后,会发生什么事情吗?
如果线上机器突然宕机,线程池的阻塞队列中的请求怎么办?
如果在线程中使用无界阻塞队列会发生什么问题?
你对CAS的理解以及其底层实现原理可以吗?
你对Java内有模型的理解可以吗?
Java内存模型中的原子性、有序性、可见性是什么吗?
指令重排、内存栅栏以及happens-before这些是什么吗?
能从Java底层角度聊聊volatile关键字的原理吗?
能说说ThreadLocal的底层实现原理吗?
spring
spring的AOP和IOC机制都是如何实现的?循环依赖应该如何处理呢?
了解过cglib动态代理吗?他限jdk动态代理的区别是什么?
spring的事务实现原理是什么?能聊聊你对事务传播机制的理解吗?
从源码实现角度谈谈,Spring中用了哪些的设计模式?
tomcat
你知道为什么面试官要考察Tomcat底层知识吗?
你能聊聊Tomcat的核心架构原理吗?
你知道Tomcat的线程模型是什么样的吗?默认Tomcat有多少工作线程?
平时你们生产环境中是如何配置Tomcat的JVM的?如何对Tomcat进行性能优化?
说说你对负载均衡算法的理解,以及Nginx的负载均衡原理?
jvm
为什么互联网公司的面试官会极为重视IVM的考察?
JVM中有哪几块内存区域?Java8之后对内存分代做了什么改进?
你知道JVM是如何运行起来的吗?如何创建对象以及何时触发垃圾回收?
说说你对JVM的垃圾回收算法以及垃圾回收器的理解?
你们生产环境中是如何设置VM的内存参数以及垃圾回收参数的?
JVM可能会发生哪几种OOM?如何排查和处理线上系统的OOM问题?
你在实际项目中是否做过JIVMGC优化,怎么做的?
聊聊VM类加载器体系?为什么要使用双亲委派?如何自定义类加载?
网络
为什么Java工程师的面试中要考察网络的基础知识?
说说你对TCP/IP四层模型的理解?
说说HTTP协议的工作原理,还有HTTP1.0、1.1以及2.0的区别是什么?
你现场画一下HTTPS协议的原理,如何使用HTTPS协议?
你知道什么是网络抓包的问题吗?能说说怎么解决这个问题吗?
谈谈你对TCP三次握手和四次握手的理解,以及为什么要这么做?
当你用浏览器打开一个链接的时候,计算机做了哪些工作步骤。
Linux
为什么Java工程师的面试中要考察Linux的基础知识?
在Linux中你都关注过哪些关键的内核参数,有没有做过优化?
Linux有哪几种IO模型?你知道epoll和poll有什么区别吗?
说说你对Linux操作系统中线程切换过程的理解?
MySQL
如果Java工程师只会写SQL,能hold住互联网公司的线上系统吗?
MySQL的myisam和innodb两种存储引擎的区别是什么?底层文件结构是什么?
对MySQL的索引原理了解吗?素引的数据结构是什么?B+树和B树有什么区别?
生产实践
系统启动10分钟后机器就会CPU负载100%,重启之后依然如此,怎么排查?
如果线上系统的内存使用率一直不停上涨,重启之后依然如此,怎么排查?
如果线上系统突然假死,无法访问了,此时如何排查?
如果线上系统出现线程死锁或者MySQL死锁问题,应该如何排查?
平时你们对线上系统是如何进行监控的?cpu、内存、磁盘、io和jvm都监控什么?
hashmap
哈希表的内在数据结构及其运作方式。
尽管外观上类似于关联数组或映射表,但实际上哈希表是基于数组构建的数据结构。
通过哈希函数将键映射至数组特定位置的过程,以及面对键值冲突时的解决策略。
强调即便同一键值被多次修改,最终仅保留最新一次插入的值这一特性。
哈希表利用哈希值对数组长度取模以确定索引的方法,有效支持数据的快速查找和插入。Java中对于哈希表的实现虽增加了一些复杂性,但核心机制保持一致,均依托于此基础架构来提高数据处理效率。
hash底层是数组,通过key值把数据填到对应位置















 12万+
12万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









