








目录
三、Linguistically Routing Capsule Network
3.1. Linguistic layout generation
3.2. Word-level multimodal embedding
4.3. Comparison with state-of-the-art methods
4.4. Visualization of routing results
摘要:
对分布不同的测试数据的泛化是视觉问答中一个重要但尚未充分探讨的主题,当前最先进的VQA模型经常利用数据和标签之间的有偏差的相关性,当测试和训练数据具有不同的分布时,这会导致很大的性能下降。人类可以通过组合已有的概念来识别新的概念,胶囊网络具有表示部分-整体层次结构的能力,受此启发,作者提出使用胶囊来表示部分,并引入“语言路由”来建模部分到整体的层次结构。具体来说,作者首先将视觉特征与单个问题词作为原子部分进行融合,然后我们引入了“语言路由”来重加权两层胶囊之间的连接,这样:1)较低的层胶囊可以转移他们的输出到最兼容的更高层的胶囊,2)两个胶囊可以合并,如果与之相应的单词在问题解析树出现合并。路由过程将上述的一元和二元势在多层之间最大化,最终在胶囊网络内部雕刻出一个树形结构。我们在CLEVR、VQA-CP v2数据集和VQA v2数据集上评估了我们提出的路由方法。
一、介绍
视觉问答(VQA)的任务是正确地回答有关图像的问题。目前最先进的VQA模型专注于增加模型的容量,但往往只是捕捉了问题和答案之间的表面关联,由于这种相关性只在训练分布上成立,因此在不同分布的测试集上会导致模型精度的急剧下降,还有的工作探索了用结构化模型来表示原子元素(例如:对象大小、颜色或关系),然后整合元素来推断最终结果。这些方法具有较好的可解释性和泛化能力,但对于一般和不受约束的测试数据,其性能不如现有的神经网络。
人类可以通过结合学习过的概念来识别新的概念,这种组合泛化能力允许人们使用有限的一组基本技能来解决大量的问题,这也是人类智能和当前深度神经网络之间的主要区别之一。同时,胶囊网络具有将端到端神经网络与基于部分的模型连接起来的潜力,可以表示部分-整体层次结构的关系。每个胶囊可以用来表示特定的部件,路由过程可以用来建模层次结构,虽然胶囊网络在一些小实验中展示了有趣的分组特性,但在大规模的图像数据集上,由于没有适当的引导,无法通过黑盒方式学习分组权值来获取不同的视觉成分,因此其结果仍然不理想。

因此,作者建议将人类组合概念的能力注入胶囊网络中,以提高神经网络的组合泛化能力,同时保持其在非相同分布数据集的性能,如图1所示,在问题解析树的指导下,提出了“语言路由”方法,在胶囊网络内部生成自适应推理例程,我们首先将每个视觉胶囊与单个问题词融合,得到图像和问题片段的多模态表示。在每一层,语言路由对每个胶囊生成[0,1]的权重向量,这样:1)只有最兼容的高层胶囊会被激活,同时接收每个低层胶囊的输出,2)两个胶囊应该合并,如果相应问题解析树的片段出现了合并。为了满足上述两个要求,作者提出的语言路由学习预测一元势,为每个特定样本选择最具代表性的胶囊;并生成表示两个胶囊是否应该合并的二元势。语言路由最大限度地利用条件随机场(CRF)的一元和二元势。经过各层转发后,在网络内部刻划出一个与解析树同构的构成结构,由下至上的胶囊可以对问题词、短语、子句,最后对句子进行编码。
作者的贡献如下:1)提出了一种端到端可训练的路由方法,可以将外部结构信息纳入胶囊网络。2)提出利用语言解析树来引导路由,并将其调整到视觉问答任务中。3)进行了大量的实验,表明所提出的语言路由胶囊网络在保证性能的前提下,能够获得良好的泛化能力。
二、相关工作
Visual question answering VQA任务需要对图像和文本进行协同推理,以推断出正确的答案。早期的研究采用基于cnn-lstm的体系结构和注意机制端到端训练神经网络,后来,大量的研究集中在图像与问题的联合嵌入上,最近,最先进的方法利用基于Transformer的结构同时嵌入问题和图像区域。然而,有人认为这些黑盒模型可能会利用数据集偏差,而不是真正的理解了问题和图像。这种争论激发了无偏数据集和OOD(非相同分布)数据集的提出。最近的一些OOD VQA方法训练了一个仅问题模型来预测答案,并将训练后的模型作为正则化器来减少数据集偏差,提高OOD测试数据的性能。
Structured and interpretable model 除了端到端神经网络,其他方法也尝试加入额外的结构化信息来提高复合推理和泛化能力。神经模块网络利用神经模块解决特定的子任务,并按照结构化布局将它们组装起来,以预测最终答案。还有将场景图作为附加信息,然后应用GRU或图卷积网络来获得特定于问题的图表示。PTGRN在依赖解析树的指导下执行可解释的推理过程。
Capsule network 胶囊网络内容比较多,可以直接百度学习胶囊网络的原理。
三、Linguistically Routing Capsule Network

给定问题q,图像I,我们提出的语言路由是将胶囊网络的路由权重与问题解析树对齐,以预测答案。如图2所示,我们首先解析一个问题并将其转换为语言布局g,然后,将图像特征与问题中的每个词融合,我们将每个生成的特征胶囊表示为,并使用向量
![]() 来表示第i个胶囊编码的单词,其中nq是问题的最大长度,所有的胶囊被连接成网络的输入
来表示第i个胶囊编码的单词,其中nq是问题的最大长度,所有的胶囊被连接成网络的输入。
在每一层l中,有个胶囊
![]() ,它们的词编码
,它们的词编码![]() ,以及语言布局
,以及语言布局。语言路由进程旨在对每一对胶囊
和
生成权重向量
![]() ,这样每个低级胶囊
,这样每个低级胶囊激活一个合适的高层胶囊
,如果有两个词在解析树里出现了合并,则这两个词对应的低级胶囊也会合并到相同的高层胶囊。
所有层前向传播后,在胶囊网络内部生成一个树形结构的路由路径,最后一层对整个问题图像嵌入进行编码,再进行全局平均池化和线性变换,预测最终答案。
3.1. Linguistic layout generation
我们首先生成给定输入问题q的语言布局,通过使用现成的通用Stanford Parser解析问题来获得依赖解析树,然后,根据它们是否在解析树中被合并对单词进行分组。
具体来说,我们用节点与最远叶节点之间的距离来表示节点的层级,考虑一个以节点i为根的层级l的子树,我们将这个子树中的单词分组成一个集合,并用表示它,所有处于同一级别的组构成一个列表
。例如,层级0和层级1的分组g0= {{are},{there},{more},…,{tiny},{cylinders}}和g1 ={{are},{there},{more},…,{than, tiny, cylinders}},如图2所示。生成的布局G={g0, g1,…, gH}用于指导不同层次的路由过程,其中H为解析树的最大高度。
3.2. Word-level multimodal embedding
我们将提取的图像特征v与编码的单词特征wi做低秩双线性池化融合,得到第0层的多模态表示。具体来说,我们将单词和图像特征投影到多维空间,然后进行逐元素乘法,得到:
![]()
每个多模态表示包含图像和单个词的信息,因此是一个one-hot编码,其中
= 1,表示有没有这个词,
是网络的输入。
3.3. Linguistically Routing

给定胶囊层、词编码
和问题引导布局
,路由过程生成路由权重
![]() ,以激活几个更高级别的胶囊,并用语言引导组合更低级别的胶囊。我们用一元势
,以激活几个更高级别的胶囊,并用语言引导组合更低级别的胶囊。我们用一元势表示每个高级胶囊被激活的概率,用二元势
![]() 表示胶囊i和胶囊i'在解析树中合并时选择相同的高层胶囊。我们通过一个全连接的CRF来最大化这两个势,CRF的推理结果是路由权重
表示胶囊i和胶囊i'在解析树中合并时选择相同的高层胶囊。我们通过一个全连接的CRF来最大化这两个势,CRF的推理结果是路由权重,如图3所示。
Unary potential 一元势表示哪一个更高层次的胶囊应被激活以表示胶囊i,我们将其全局最大池化映射到具有两个全连接层的nc维向量上,其中nc是胶囊的数量,应用softmax对结果向量进行归一化,使每个元素都在[0,1]之间。
Binary potential 二元势![]() 表示胶囊i和i'在解析树中合并时选择相同的高层胶囊j。
表示胶囊i和i'在解析树中合并时选择相同的高层胶囊j。
但是,集合操作是不可微分的,因此使得整个模型无法端到端训练。我们有nq维的向量,其条目表示第i个胶囊编码每个问题单词的数量,例如,在第0层输入处,胶囊i将图像与问题中的第一个单词进行融合,
为一个独热向量,其中
= 1,那么,如果softmax归一化路由权值
![]() ,则第i个词对胶囊j和k的编码度分别为0.9和0.05,给定路由权重
,则第i个词对胶囊j和k的编码度分别为0.9和0.05,给定路由权重,我们可以更新
,得到:
![]()
为了得到二元势,我们首先将布局g变换为nq*nq的相关矩阵g',表示两个词i和i'是否合并:
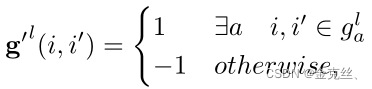
其中g是3.1节中描述的语言布局。![]() 表示两个词i和i'在同一个组中,例如,{than, tiny, cylinders}。否则,我们设置
表示两个词i和i'在同一个组中,例如,{than, tiny, cylinders}。否则,我们设置![]() ,以防止两个单词过早合并,直观地看,当胶囊中包含更多的兼容词时,二元势ϕi,i '应该较高。因此我们有:
,以防止两个单词过早合并,直观地看,当胶囊中包含更多的兼容词时,二元势ϕi,i '应该较高。因此我们有:![]() ,对于层级l上的所有胶囊对,我们将上面的方程改写为矩阵形式,有:
,对于层级l上的所有胶囊对,我们将上面的方程改写为矩阵形式,有:
![]()
然后,我们将每个二元势ϕi,i '展开成一个对角nc∗nc矩阵,使它们在选择不同的高级胶囊时的位置为0。最后,利用该二元势和一元势构建CRF,得到各层胶囊的路由权重。
CRF inference 路由权重应该在全局范围内最大化一元势和二元势,我们构造了一个条件随机场(CRF),并利用(Loopy Belief Propagation)来寻找最优的路由权值。具体来说,我们构造了一个CRF,其中每个节点代表一个胶囊,节点i是与路由权重相关的nc维随机变量{zi}。我们初始化了![]() 均匀分布,并将消息更新为:
均匀分布,并将消息更新为:

其中![]() 是除节点i '外的节点i的邻居,T次迭代后,我们收集所有节点和变量的消息,得到边缘概率:
是除节点i '外的节点i的邻居,T次迭代后,我们收集所有节点和变量的消息,得到边缘概率:
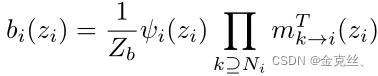
其中Zb是标准化因子,得到的边缘概率为相应的路由权![]()
![]() 。我们实现上述(Loopy Belief Propagation)过程作为一个非参数层,这样它可以反向传播梯度。
。我们实现上述(Loopy Belief Propagation)过程作为一个非参数层,这样它可以反向传播梯度。
3.4. Capsule layer
在一般的神经网络中,正向传播为![]() ,其中xi和xj为神经元,σ为激活函数。将一组神经元按按照胶囊分组后,将语言路由权值
,其中xi和xj为神经元,σ为激活函数。将一组神经元按按照胶囊分组后,将语言路由权值![]() 应用于从胶囊i到胶囊j的线性变换的再加权:
应用于从胶囊i到胶囊j的线性变换的再加权:
![]()
对于卷积层,在空间维度上进行相同的卷积运算,并在特征通道上应用路由权值:
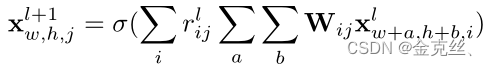
w和h是特征图中的空间位置。以上所有运算都是可微的,因此,提出的语言路由可以与其他网络参数一起端到端训练,在训练过程中,我们只使用答案标签作为监督信号,对整个胶囊网络进行端到端训练。
四、实验
4.1. Datasets
CLEVR-CoGenT、VQA v2、VQA-CP va数据集。
4.2. Implementation details
为了验证我们提出的语言路由的有效性,我们使用了两种最先进的方法,即FiLM和MCAN作为骨干结构,并分别用胶囊层替换了它们的卷积层和全连接层。
对于CLEVR-CoGenT数据集,我们采用FiLM进行图像特征提取和词嵌入。我们调整图像大小224×224,从ResNet-101的conv4block提取14×14×1024特征图,这是在ImageNet上预训练的。1024维的特征图投影到128维的空间,通过GRU得到问题的词嵌入向量,得到一个512维的词向量,然后,我们对图像特征进行词级多模态嵌入,得到的多模态表示![]() 是神经网络的最低层特征图,其中nq= 46是CLEVR-CoGenT数据集中问题的最大长度。每个胶囊
是神经网络的最低层特征图,其中nq= 46是CLEVR-CoGenT数据集中问题的最大长度。每个胶囊![]() 是14×14×128 特征图,它的编码词编码
是14×14×128 特征图,它的编码词编码![]() 是一个独热向量。因为解析树中层级1的节点的最大数量是9,所以我们将胶囊数量设置为9,每个胶囊有16个通道。在CLEVR-CoGenT中,解析树的高度大多小于4,因此,我们设置解析树为4层,并将卷积胶囊层的数量设置为4层。在语言路由过程中,每个14×14×16的胶囊被送入一个全局最大池化层,这是两个全连接层,输出大小为512和9,其中9是下一层胶囊的数量。给定二元势和9维一元势,我们执行Loopy Belief Propagation 2次迭代以获得路由权重。每个胶囊层有3×3×144卷积核,最后,分类器卷积144维特征映射到512维,并将结果送到两个全连接层,输出大小为1024和29,其中29是候选答案的数量。
是一个独热向量。因为解析树中层级1的节点的最大数量是9,所以我们将胶囊数量设置为9,每个胶囊有16个通道。在CLEVR-CoGenT中,解析树的高度大多小于4,因此,我们设置解析树为4层,并将卷积胶囊层的数量设置为4层。在语言路由过程中,每个14×14×16的胶囊被送入一个全局最大池化层,这是两个全连接层,输出大小为512和9,其中9是下一层胶囊的数量。给定二元势和9维一元势,我们执行Loopy Belief Propagation 2次迭代以获得路由权重。每个胶囊层有3×3×144卷积核,最后,分类器卷积144维特征映射到512维,并将结果送到两个全连接层,输出大小为1024和29,其中29是候选答案的数量。
对于VQA-CP v2和VQA v2数据集,我们修改了MCAN,并在引导注意块中引入了语言路由,与MCAN类似,通过LSTM和6个自注意块嵌入单词,得到512维的单词嵌入向量。采用BUTD提取图像特征,每幅图像有36个对象,具有2048维特征向量,我们将每个对象特征分成16个胶囊维度,然后将单词的嵌入投影到32维向量上,并将其与32维视觉特征进行融合。因此,胶囊数量为16个,每个胶囊包含32个神经元,图像首先通过3个引导注意力块,然后我们只将最后3个引导注意块中的前馈层替换为语言路由胶囊层,我们分别为每个对象执行语言路由,对于每个物体,他们的32维胶囊被送入两个全连接层,输出尺寸分别为32和16,以预测一元势,经过2次Loopy Belief Propagation迭代来获得路由权重。该分类器与MCAN的相同,它对问题词和36个图像对象进行关注,得到1024维向量,分类器将1024维向量投影到3129维,其中候选答案的数量为3129。
4.3. Comparison with state-of-the-art methods
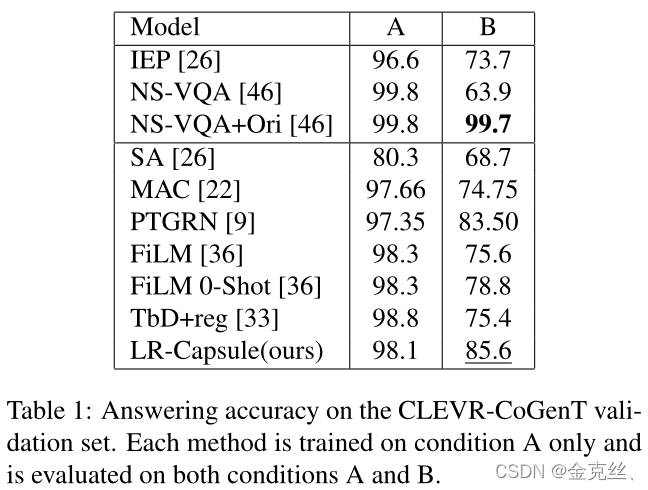
我们在表1中报告了不同模型在CLEVR-cogent上的回答准确度。

我们在表2中报告了标准的VQA-CP v2评估度量。
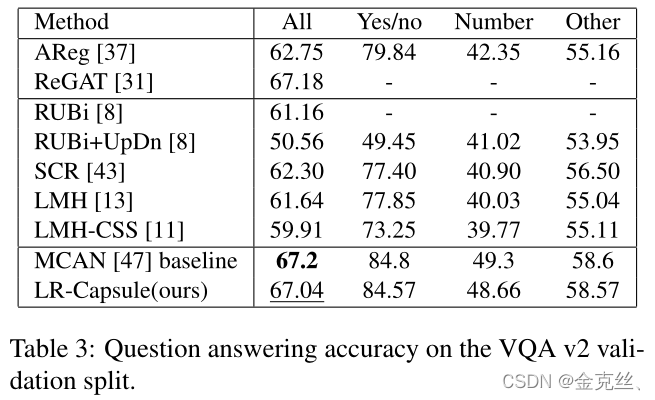
表3给出了VQA v2验证集上的结果。
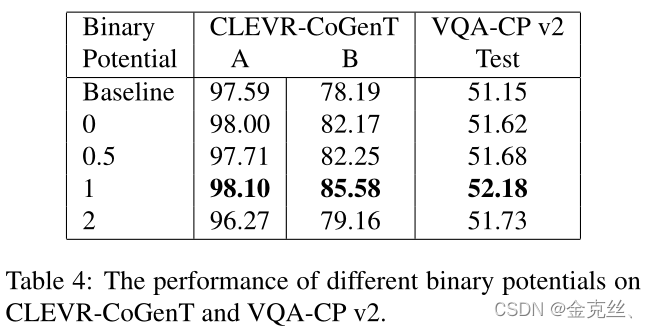

4.4. Visualization of routing results

我们将路由结果可视化在图4中。
五、结论
我们提出了一种端到端融合语言信息的语言路由方法,以提高胶囊网络对面向对象数据的泛化能力。我们对每个胶囊使用一元势激活一个适当的高级胶囊,并使用二元势的胶囊对合并语言结构。当我们将最低的视觉特征绑定到一个单词时,自底向上的语言引导的合并过程可以将单词组合成短语、子句,最后是一个句子。各层前向传播后,解析树被刻入网络内部,与视觉模态纠缠在一起。














 855
855











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









