










目录
2.1、Pre-trained Vision-language Models
Pre-training-then-fine-tuning paradigm
3.2 Declaration-based Prompt Tuning
Textual Adaptation via Declaration Generation
Zero-shot and few-shot learning
Generalizability over different datasets
Generalizability over different VL models
Accuracy over different question types
4.4、Zero-shot and Few-shot Results
摘要:
预训练+微调范式在跨模态任务上取得了巨大成功,例如VQA,其中视觉语言(VL)模型首先通过自监督的预训练任务目标进行优化,例如MLM和ITM,然后通过一个全新的目标函数(如答案预测)进行微调,以适应下游任务(如VQA)。然而,目标形式的不一致性不仅严重限制了预训练VL模型对下游任务的泛化,而且还需要大量标注数据进行微调。为了缓解这一问题,我们提出了一种新的VL微调范式(名为Declaration-based Prompt Tuning,称为DPT),它使用预训练的任务目标对下游VQA的模型进行微调,从而提高预训练模型对下游任务的有效适应性。具体而言,DPT通过(1)文本适应,将给定的问题转换为陈述句形式,以便prompt-tuning;(2)任务适应,以预训练阶段的方式优化VQA问题的目标函数,重新制定VQA任务(就是将VQA本来的多分类任务转换为MLM和ITM这样的预训练任务)。
一、介绍
大规模多模态预训练在许多视觉语言任务中表现出色。通常都是遵循预训练+微调范式,即模型先以自监督的方式在大规模图像文本数据集上进行预训练,然后通过引入额外参数和使用特定任务目标进行微调来适应不同的下游任务,例如VQA。
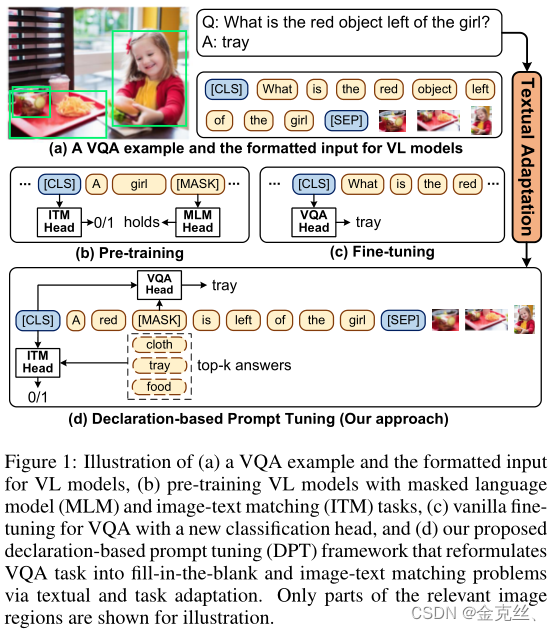
值得注意的是,预训练和微调阶段之间,客观存在着天然的gap。如图1b-c所示,大多数VL模型都是通过MLM和ITM目标进行预训练,即在跨模态上下文中恢复mask并预测图像文本对是否匹配。然而,在微调阶段,VQA问题通常使用全新的任务目标进行和优化,即将[CLS]提取出来做分类,这通常会引入额外的参数。因此,预训练和微调在任务形式上存在很大差异。这种差距限制了将预训练的VL模型推广到下游VQA任务,从而导致性能不理想,并且需要大量标注数据进行微调。
受视觉语言预训练模型(VL-PTM)和跨模态领域prompt tuning范式最新进展的启发,本文提出了Declaration-based Prompt Tuning(DPT),这是一种用于VQA问题的VL-PTM微调的新范式。我们的核心见解是将下游VQA任务的目标形式重新制定为预训练阶段的形式,最大限度地缩小两个阶段之间的gap。我们从两个方面重新制定了VQA任务(图1d):
- 将文本输入(即问题)转换为陈述句形式的文本。
- 通过从陈述句中恢复mask并选择与图像最匹配的candidate answer的任务来解决VQA问题。这样,可以模仿MLM和ITM任务在预训练阶段的行为,实现答案预测。
主要贡献如下:
- 我们引入了Declaration-based Prompt Tuning(DPT),这是一种新的微调范式,通过将下游任务转换为预训练任务的格式来解决VQA。据我们所知,这是第一次尝试使用陈述句进行视觉问答的Prompt Tuning。
- 我们提出了新的文本和任务适应方法,将VQA重新表述为MLM和ITM问题。在全数据训练和few-shot设置下,调整后的任务显著优于传统微调对应任务。
- 我们在各种VL PTM和VQA数据集上进行了综合实验,证明了DPT的有效性和通用性。
二、Related Work
2.1、Pre-trained Vision-language Models
最近,针对各种下游跨模态任务的通用模型的训练工作很多,例如VQA或image caption。常用的做法是遵循预训练+微调的范式。具体而言,在预训练阶段,首先构建了一个类似BERT的模型架构,用于通过各种自监督任务进行学习多模态表示的预训练,例如,在多模态上下文中恢复mask的MLM,或图像文本匹配(ITM)任务。接下来,在微调阶段,使用完全不同的任务特定目标(例如预测VQA任务的答案)对预训练模型进行微调,以适应下游任务。在这项工作中,我们没有在微调阶段优化全新的任务目标,而是尝试将VQA重新表述为预训练的格式,从而提高预训练VL模型对下游任务的有效泛化。
2.2、Cross-modal Prompt Tuning
最近,prompt tuning因其在保持预训练模型和下游任务的优化目标一致性方面的强大能力而日益受到关注,这使得预训练模型能够推广到下游任务,只需few/zero samples即可进行微调。例如,[Radford et al.,2021;Zhou et al.,2021]利用精心制作的模板和可学习的连续表示来重新制定下游任务的目标形式;【Cho等人,2021;Jin等人,2021;Tsinpoukelli等人,2021】考虑到利用统一的文本生成框架来统一优化自回归目标。然而,由于给定问题的语义复杂,固定模板或预定义的统一生成范式可能无法设计合适的prompt模型。为了克服这一问题,本文提出了一种创新的declaration-based prompt模型,该模型利用问题自适应陈述句作为prompt模板,使VQA任务的文本格式与预训练阶段更加一致(因为预训练通常使用的数据集是图像文本对,而文本是陈述句),缩小了预训练阶段和微调阶段之间的文本gap。
三、Methodology
在以下各节中,我们首先介绍VQA任务的问题陈述(第3.1节)。然后,我们描述了我们提出的DPT方法(第3.2节)。总体框架如图2所示。具体而言,图像和问题被转换为输入形式,并输入到预训练的VL模型中进行多模态融合,其中引入陈述句以进行prompt tuning。然后,利用模型的输出执行自适应的MLM和ITM任务,以进行模型微调和确定答案。

3.1、Preliminary
VQA任务的目的是在给定图像I和问题Q时,从候选答案集中选择正确答案a。为此,我们提出了VQA的经典范式,即预训练+微调范式。
Pre-training-then-fine-tuning paradigm
给定一个通用架构,例如Transformer,首先通过自监督任务(例如MLM和ITM)在大规模图像文本对上对模型进行预训练。为此,图像和问题
被转换为输入格式,即
,其被送到Transformer模型并融合,利用自监督目标对模型进行了进一步优化。然后,在VQA任务的微调阶段,利用输出
进行多分类,并通过交叉熵损失进行优化。这个范式引入了一个全新的微调任务,这需要大量标注数据。
3.2 Declaration-based Prompt Tuning
为了便于将预训练的VL模型推广到下游VQA任务,我们提出了一种declaration-based prompt tuning(DPT)范式,将VQA重新转换为预训练的任务格式。如图1(b-d)所示,存在两个挑战,即不同形式的文本输入(问题与陈述)和不同的任务目标(MLM和ITM与答案分类)。为了解决这些问题,我们提出了(1)文本适应模块将问题转换为相应的陈述句(2)任务适应模块将答案预测转换为MLM和ITM任务。将这两个经过调整的任务结合起来,以确定最终答案。
Textual Adaptation via Declaration Generation
文本适应旨在将文本输入(即问题)转换为预训练时文本的形式(即陈述句),例如“女孩左边的红色物体是什么?”的陈述句为“一个红色的[mask]在女孩的左边”。为此,我们引入了陈述生成,将此过程描述为一个翻译问题,其中源文本和目标文本分别是问题和陈述句。在形式上,我们首先使用GQA数据集中的注释构建一个陈述数据集,其中“fullAnswer”被视为陈述,“fullAnswer”中的简短答案词\短语被替换为[MASK]标记。然后,在此数据集上训练编码器网络(T5【Raffel et al.,2020】)。最后,该模型可用于将问题转换为各种VQA数据集的陈述句,例如GQA和VQA v2。更多详情见第4.1节和附录。
Task Adaptation
有了陈述句,VQA可以转换为预训练任务格式,即MLM和ITM。改动主要涉及两个方面:文本输入格式和任务目标。具体来说,MLM在文本输入中保留一个[mask]标记,并通过多分类预测答案。ITM将[mask]替换为MLM预测的top-k候选答案,并使用二分类预测匹配分数,即图文匹配。
Adaptation to MLM task
为了将VQA重新表述为MLM任务,将问题和陈述句连接起来,形成文本输入:
![]()
其中,表示将问题
转换为输入格式的转换函数,D表示陈述句。在等式(1)中,我们将问题
保留在文本输入中,因为我们发现,由于缺乏推理上下文,仅陈述句的性能就会下降(详情请参阅附录)。值得注意的是,
保留了一个[mask]标记,例如,一个红色的[mask]在女孩的左边。这样,模型将被提示决定要填充mask,该mask准确地指示着摇预测的答案。
在自适应文本输入的基础上,利用预训练的VL模型融合文本和图像特征,生成一组隐藏表示。将来自[CLS]和[mask](即h[CLS]和h[M ASK])的输出串联起来,以预测答案:

其中表示答案集
上的分数,使用交叉熵损失优化模型,定义如下:
![]()
其中是真值答案,
表示VQA数据集。
Adaptation to ITM task
为了将VQA转换为ITM任务,陈述句D中的[mask]标记用公式2输出的top-k个答案替换,会生成K个候选陈述句:
![]()
根据候选陈述句,文本输入可以通过问题和陈述句的串联形成,定义如下:
![]()
其中表示转换函数,
表示陈述句,[mask]被第k个候选答案
取代,例如,一个红色的 tray/food/cloth 在女孩的左边。
这样,预训练的VL模型会被提示确定图像文本是否匹配。为了实现这一点,图像和文本输入被输入到VL模型,来自[CLS]和answer token(即和
)的输出被串联起来以预测匹配分数:

其中表示图像和第k个候选答案的匹配分数。直观地说,具有真值答案的图像-文本对应该具有更高的匹配分数,因此,使用二元交叉熵损失对模型进行优化,定义如下:

Training and inference
在任务适应的基础上,VQA被重新表述为MLM和ITM问题。在训练过程中,我们将等式(4)和(9)中的损失进行聚合,以微调VL模型,DPT的总损失定义为:
![]()
在推理过程中,通过简单求和将MLM和ITM预测的归一化得分进行组合,选择得分最高的答案作为最终预测结果,定义如下:
![]()
Zero-shot and few-shot learning
搭建好DPT后,只有将方程(2)和(7)重新转换为与预训练阶段中的方程相同的形式,并用预训练权重初始化,才能将先前预训练的VL模型转换为zero\few-shot learning的VQA任务:

其中表示使用预训练权重初始化的MLP层,由于答案的数量少于词汇表的数量,因此仅取与答案单词对应的权重来初始化
。
四、Experiments
4.1、Implementation Details
Datasets
GQA和VQA v2用于构建陈述生成数据集,并评估我们针对VQA任务提出的方法。更多详情见附录。
Model training
T5 small被用作陈述生成,至于VQA,VinVL被选为我们的基本架构。我们提出的DPT通过文本和任务自适应应用于VinVL。该模型使用经过调整的任务目标进行了微调,从而产生了关于培训任务的两种变体,即DPT(传销)和DPT(传销和ITM)。ITM 候选答案数量K为8。
4.2、Experimental Results

对于GQA数据集的在线评估,我们将我们的方法与最先进的模型进行比较,包括非预训练模型,即MMN、NSM和预训练VL模型,即LXMERT、VILLA、OSCAR、VinVL、MDETR、VL-T5,结果见表1。当仅利用平衡分割数据集进行训练时,我们的方法在test-dev和test-std上分别达到63.55%和63.57%的总体准确性,优于最先进的非预训练和预训练模型。具体而言,我们的方法(DPTbal)在test-dev上比微调对应方法(VinVLbal)高出2.68个百分点。当使用所有分割数据集来训练我们的模型时,我们的方法(DPT)在总体精度方面仍然排名第一,在test-std上比对应方法(VinVL)高出0.27%,MMN和NSM即使没有进行预训练,也能取得有竞争力的结果,这要归功于使用故意生成的场景图或监督执行程序。
4.3、Ablation Study
为了更深入地了解DPT,我们进一步对GQA和VQA v2的局部数据集进行了消融研究,GQA上的textdev和VQA v2.0上的val。
Different prompts
为了说明陈述句在提示调整方面的有效性,表2中提出了几个陈述句变体进行比较,定义如下:
- Baseline:没有提示的微调VinVL。
- Mask: “Answer: [MASK]”。
- Dynamic: “Answer: [V1] [V2] ... [V16] [MASK]”。
- Declaration (Ours): “Answer: D”。

其中,“[V1]”-“[V16]”表示微调期间联合训练的可学习token。如表2所示,在GQA数据集上,我们提出的DPT比手动设计的模板(即mask和Dynamic)更有效。例如,具有MLM任务的DPT(第5行)分别以1.83%和0.62%的准确率超过了Mask和Dynamic。配备了MLM和ITM任务,我们的模型(第6排)比基线高出2.87%。
Generalizability over different datasets
表2显示了VQA v2的消融结果,与GQA上的结果一致,我们提出的DPT优于使用固定模板(即mask和Dynamic)的微调。具体而言,我们的DPT模型的性能比基线好0.45%。GQA和VQA的准确率差异(2.87%对0.45%)主要是由于问题的复杂性和生成的陈述句的质量(详情请参阅附录)。
Generalizability over different VL models

为了说明我们提出的方法在不同预训练VL模型上的通用性,我们将我们的DPT应用于最近提出的VL模型,这些模型已经通过MLM和ITM任务进行了预训练,例如UNITER和ViLT。如表3所示,对于采用我们的DPT方法的所有三条基线,可以观察到一致的性能改善(平均0.64%)。例如,ViLT+DPT和UNITER+DPT与Finetunning对等相比,实现了0.46%和1.01%的绝对性能增益。
Accuracy over different question types

图3显示了不同问题语义类型的准确性细分。可以观察到,与基线相比,经过调整的MLM任务在属性问题上取得了很大的准确性提高(70.46%对64.87%),这显示了DPT在捕获对象属性方面的优势。此外,调整后的ITM任务在全局问题上的成绩有了更大的提高(59.24%比56.69%),表明其在理解全局语义方面的优越能力。
4.4、Zero-shot and Few-shot Results
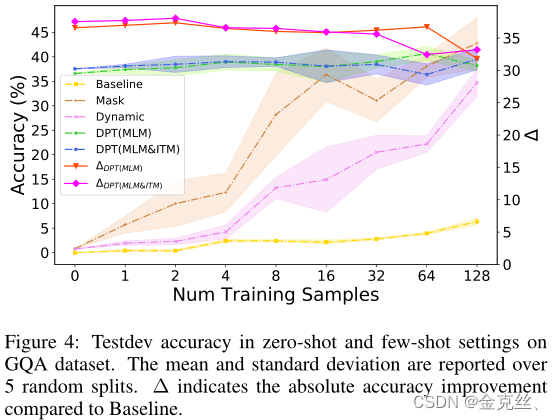
图4显示了GQA数据集上zero\few-shot的精度。我们提前删除了数据集中的是/否问题,因为大部分是/否问题(yes\no问题没必要做zero\few-shot)将导致较大的差异(∼8%)进行基线评估。如图4所示,DPT比普通微调对应项和其他提示(即mask和Dynamic)的性能要好得多。例如,在没有样本进行训练的情况下,我们的DPT实现了36.6%的高准确率,而微调后的DPT由于随机猜测而无法预测正确答案。提供时1∼128个样本,我们的DPT方法达到31.8%与基线相比,绝对准确度提高37.4%。
4.5、Case study

在图5中,我们展示了我们提出的DPT方法的两个成功案例。关于第一种情况,基线产生成的“左”和“右”概率几乎相同,表明其在解决此类方向相关问题方面的弱点。相比之下,我们的DPT具备MLM的能力,可以自信地预测正确答案“正确”。对于第二种情况,基线模型和DPTMLM都错误地预测了答案“child”,主要归因于“child”是列车集中出现的更频繁的对象。此外,“child”是“girl”和“boy”的缩写,是许多问题的通用答案。相反,DPT和适应性ITM任务考虑了答案的语义,并且给了答案“女孩”更高的分数,从而得出正确的答案。
五、Conclusion
我们建议将VQA任务转换为MLM和ITM任务,最大限度地减少视觉语言(VL)预训练和微调阶段之间的差距。为了实现这一点,我们首先将问题转换为带有保留[mask]或候选答案的陈述句,以缓解文本输入方面的差异。然后,通过任务自适应将VQA问题转化为预训练的格式,以MLM和ITM任务的方式解决VQA问题。在两个基准上进行的大量实验验证了我们提出的DPT范式在全数据训练和zero\few shot下对不同预训练VL模型的有效性和通用性。















 737
737











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









