







摘要
近年来,预训练然后微调的范式在广泛的跨模态任务中取得了巨大的成功,如视觉问答,其中一个视觉-语言模型首先通过自监督任务目标优化,如掩码语言建模(MLM)和图像-文本匹配(ITM),然后通过一个全新的目标函数微调以适应下游任务,如答案预测。然而,目标形式的不一致性不仅严重限制预训练好的VL模型对下游任务的泛化,也需要大量的标签数据用于微调。为减轻这一问题,我们提出一种创新的VL微调范式(称为基于声明的促进微调,缩写为DPT),利用预训练目标对下游VQA的模型进行微调,提高了预训练好的模型对下游任务的有效适应。具体地,DPT通过以下两点来重新制定VQA任务:(1)文本适应,将给定的问题转换为陈述性句子形式用于促进微调;(2)任务适应,以预训练阶段的方式优化VQA问题的目标函数。在GQA数据集上的实验结果表明,DPT在全监督和零样本/少样本设置下的准确性都大大优于微调后的对手。
一、介绍
视觉语言任务的一种常用做法是遵循预训练然后微调的范式,其中有一个通用的Transformer在大规模的数据集上以自监督的方式进行预训练,然后通过引入额外的参数和使用特定于任务的目标进行微调来适应不同的下游任务,如在视觉问答中使用答案分类的辅助全连接层。这一范式极大地推动了VQA任务的最先进水平。
尽管取得了良好的性能,但值得注意的是,在预训练阶段和微调阶段之间,在目标形式上存在着自然的差距。如图1(b-c),大多VL模型都是通过掩码语言建模和图像-文本匹配目标进行预训练的,即在跨模态上下文上恢复掩码标记,并预测图像-文本对的匹配分数。然而,在微调阶段,VQA问题通常使用一个全新的任务目标进行执行和优化,即将[CLS]标记分类为语义标签(即答案),其中会引入其他参数。结果,在任务形式中,预训练和微调之间存在着较大的差异。这一差距阻碍了预训练好的VL模型泛化到下游VQA任务,导致性能欠优,需要大量的有标签数据进行微调。
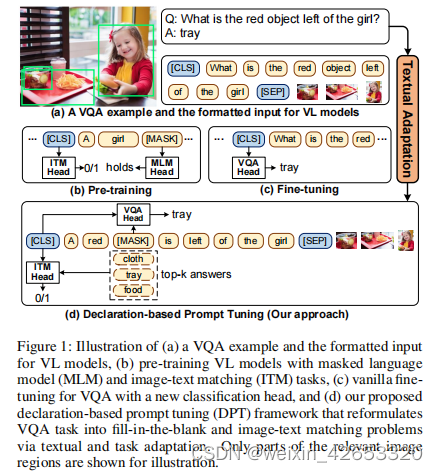
受视觉-语言预训练模型最新进展(VL-PTM)和跨模态领域的促进微调范式的启发,本文,我们提出基于声明的促进微调(DPT),一种针对VQA问题的微调VL-PTM的新范式。我们的核心见解是将下游VQA任务的目标形式重新制定为预训练阶段的形式,最大限度地减轻两个阶段之间的差距。为实现这一目标,我们从两个方面重新制定了VQA任务(图1(d)):(1)文本适应,将文本输入(问题)转换为陈述句子形式,(2)任务适应,通过从陈述句子中恢复掩码标记,并选择最匹配图像的标记来解决VQA。这样,答案预测就可以通过密集填充和图像-文本匹配来实现,模拟MLM和ITM任务在预训练阶段的行为。
通过减轻预训练和微调之间的差距,DPT使得在全监督和零/少样本设置下的各种VL模型和VQA数据集上都具有强大的性能。例如,在精度方面,我们的方法在全监督设置中实现了2.68%的绝对改进,而在GQA评估中的零/少样本设置中实现了31.8%∼37.4%的绝对改进。此外,在配备最近提出的VL模型的VQAv2.0上进行的泛化实验表明,与普通的微调方法相比,0.45%∼1.01%的绝对改进。
综上,主要贡献如下:(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 329
329











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









