






本文作者
王加龙,阿里云高级算法专家
往期文章推荐
时序预测双飞轮,全面超越Transformer,纯MLP模型实现性能效能齐飞
前言
ChatGPT发布后,AI相关话题被推向了前所未有的热度,科学家、工程师、艺术家、政府人员、商人以及广大群众都在讨论AI话题。于是,不管是专业人士还是吃瓜群众,难免会心生一个问题:AI是否超越了人类?
类不相同,何以对比?诚然如此。但人们在探索AI的过程中,一直试图从各个维度模仿着人类智能;所以,这种对比是存在意义的。
此次对比,将回避对数据、算法、算力、系统等专业知识的探讨,从自然语言任务、图像处理任务、语音生成、视频生成、代码能力、AI 推理等六大方面,详细介绍AI的能力表现及效果。
本文首先向大家展示AI在自然语言任务、图像处理任务、语音生成3方面的表现及效果。
业界近况
首先,快速地回顾一下AI行业的“近况”。
所谓“文无第一、武无第二”,在AI技术日新月异的当今,过多回顾历史版本的技术能力无助于探讨本文的主旨话题。所以,仅从2023年以来发布的基础模型中挑选一些较为关键的模型,以作管中窥豹。如下图所示,沿着时间脉络列举了近二十款重要模型,涉及文本、图像、语音等多种模态。
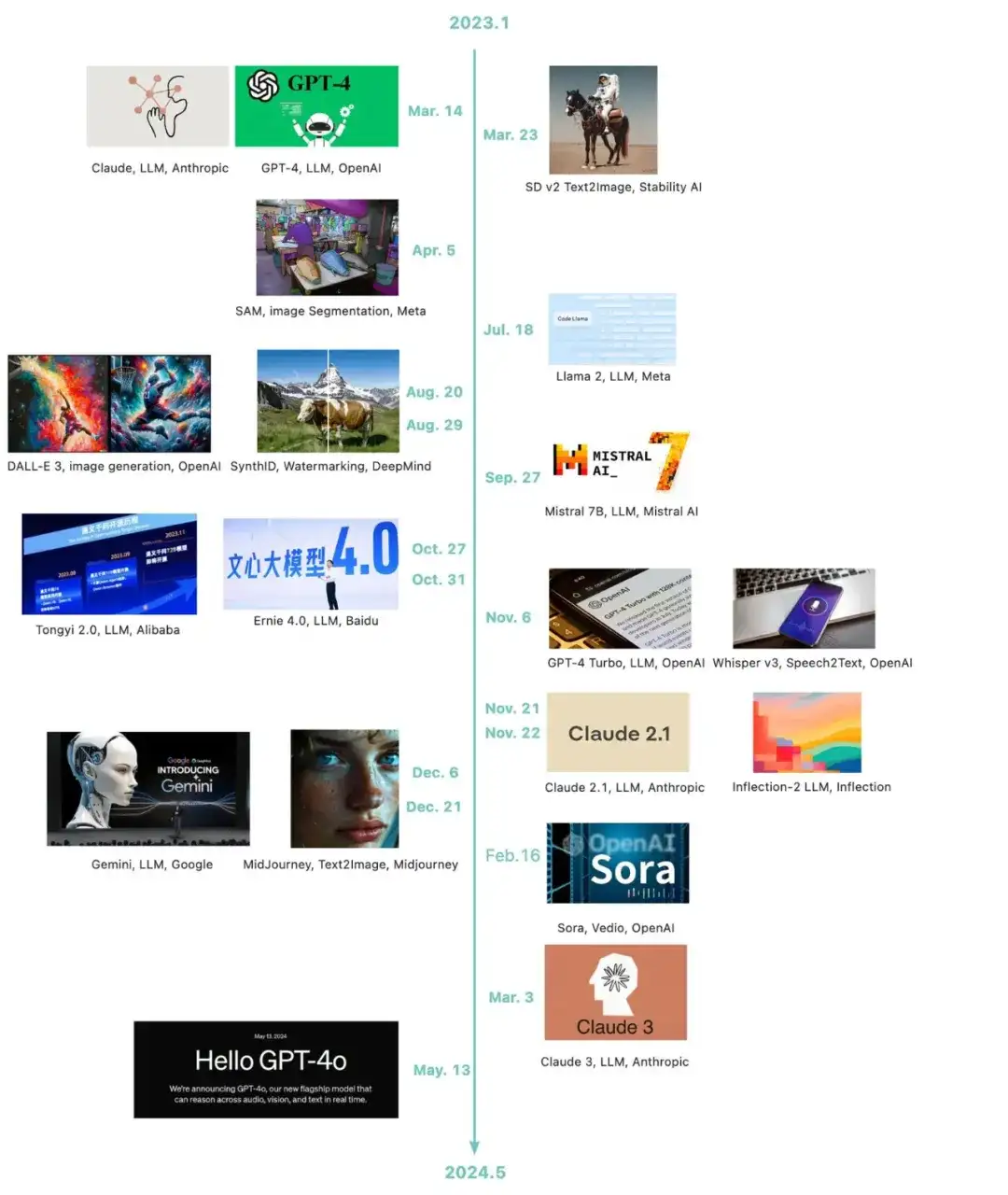
从模型多样性、性能炸裂程度来看,当前AI领域的“卷王”是OpenAI
对比测评
为了衡量AI的能力,历史上有许多人提过很多有意思的测试方法,学术界也有各种各样的定量研究方法。
关于测试方法,其中很有名的一个是“图灵测试”,它是为了探究机器智能是否具备与人类相似或无法区分的能力;关于定量研究,普遍的做法是定义某种任务的测评数据集,对 AI 进行测评打分,然后对比 AI 与 Human 的得分高低。
2.1 基于图灵测试
图灵在1950年的论文中预测,“大约50年后,人们将有可能对存储容量达到109左右的计算机进行编程,使其在模仿游戏中表现出色,以至于一般提问者经过 5分钟提问后做出准确判断的几率不超过 70%”。即,AI系统的通过率达到30%(目前不清楚图灵为何选定这个值)。时至今日已过去了 70 多年,图灵的预测到底达到了没有?针对大模型的图灵测试,UCSD专门有人在研究。他们在 2023 年 10 月[论文]、2024 年 5 月[论文]先后共发表了 2 篇论文,以分享他们最新的研究进展和结论。

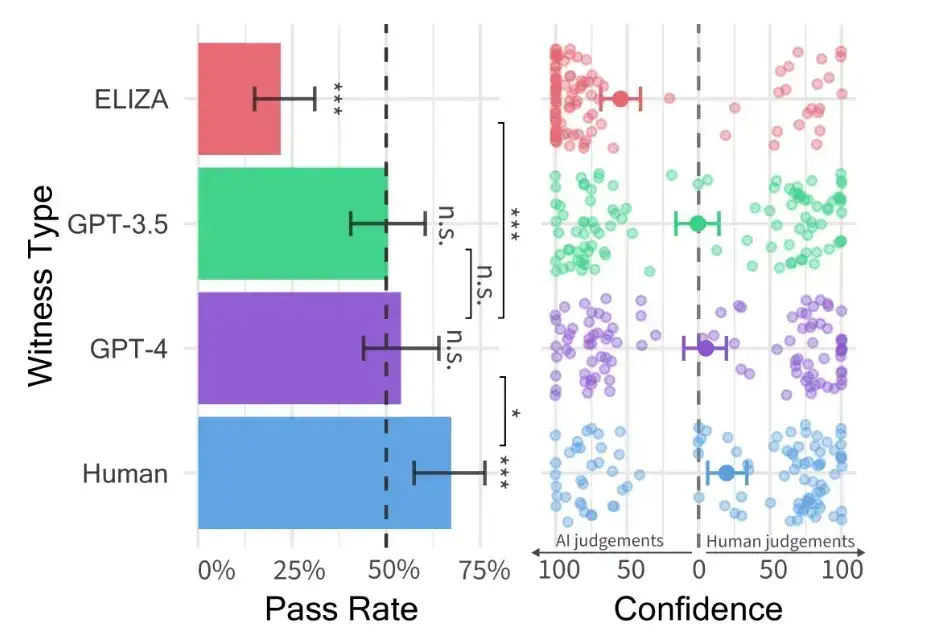
根据其2024年5月的最新研究论文,在图灵测试中,GPT-4有54%的情况下被判定为人类。这个值意味着什么呢?它意味着GPT-4的通过率超出了图灵当年提到的30%这个值,还意味着GPT-4被判定为人类的概率超过了五五开。
从这个意义上讲,GPT-4已经通过了图灵测试。此外,在该测试中,人类被判定为人类人概率为67%,也就是说人的表现还是更像人。
2.2 基于基准测评
用特定任务下的基准数据集做测试,在某些任务上大模型开始超越人类。比如,图像分类(2015)、基础阅读理解(2017)、视觉推理(2020)、自然语言推理(2021)、多任务语言理解任务(2024.1, Gemini Ultra)。但是,在复杂认知的任务上,AI仍然不及人类,比如视觉常识推理、竞赛级的数学问题。如下图所示,虚线是人类的水准,其它实线是AI在不同任务下的得分。
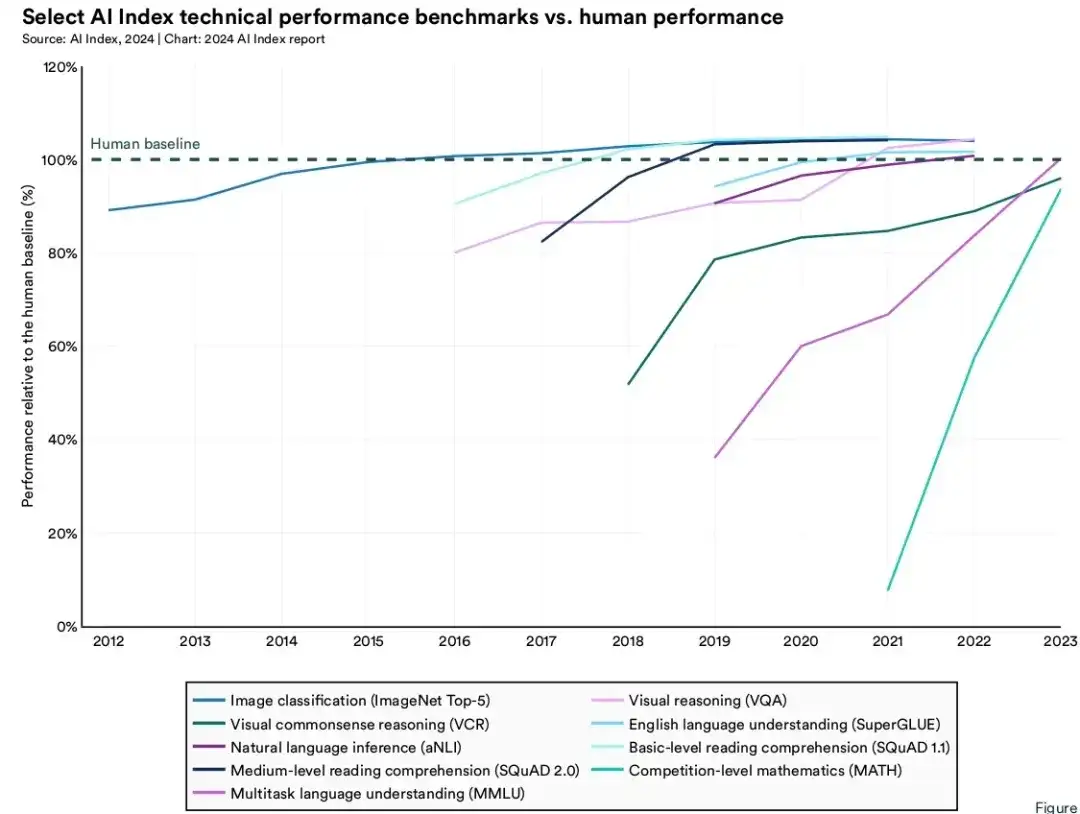
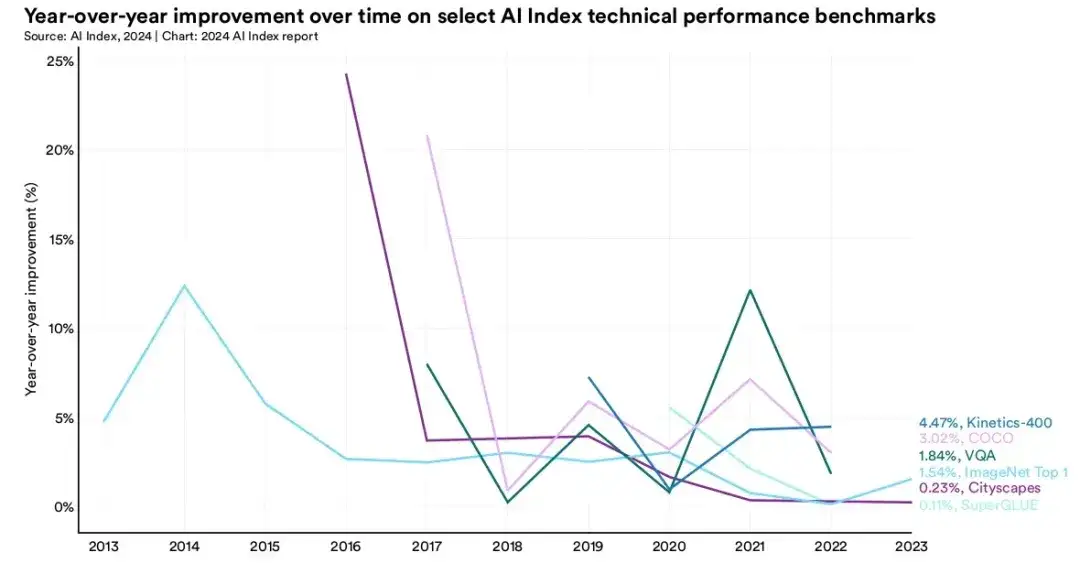
随着算法模型的迭代,某些经典测试基准的准确率已经很高,模型的性能也趋于饱和。所以,新的、更难的基准数据集也在被推出。因此,AI是否超越人类与具体的任务和测试集有关。通俗地说法是,张三、李四都得了100分,指的是他们在试卷上的表现,换张试卷可能结果会有不同。
分领域详情
尽管第二节的内容能够从总体上反映出AI的能力现状,但仍然难让人“深有感触”。所以,要想更具体的感受到AI当前在各种不同任务场景下的能力,还得看得更细一点。本节将从自然语言任务、图像处理任务、语音生成、等方面,详细介绍AI的能力表现及效果。
3.1 自然语言任务
目前AI在自然语言理解方面的具体能力如何?本节将基于常见任务的测评基准,分别展开介绍。从我平时关注的、行业较为流行的 5 个测评基准来看,AI 的得分均已经超过了人类水平。
3.1.1 溯因自然语言推理(aNLI)
https://openreview.net/attachment?id=Byg1v1HKDB&name=original_pdf
如下图所示,该类任务基于给定的若干“观察”(O1、O2,通常不完备),选择出最可能的“推测”(H1、H2、H3中最可能的一个)。
比如:当你下班回家,看到房里乱糟糟的,你会作何猜测?你首先会回忆,早上好像窗户没关紧;然后,你会推测,是不是风吹的、或者是小动物捣乱、或者是有贼人到访?这是一个很有意思的测评方式,因为人们日常生活中充满了这类场景。
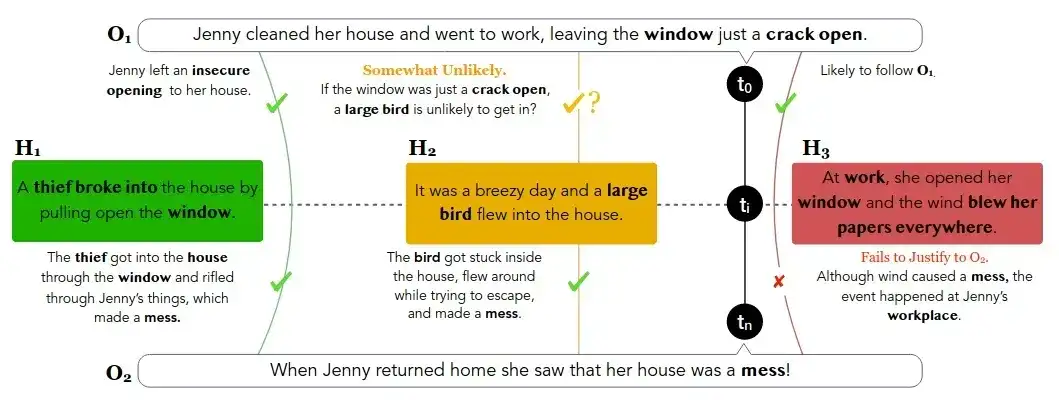
在这种场景下,AI表现如何?aNLI数据集给出了近17万对训练样本、1532对测试样本,目前SOTA算法准确率达到93.7%左右(2022/5/12),超出人类水准的92.9%。
样本一:
Obs1: It was a gorgeous day outside.
Obs2: She asked her neighbor for a jump-start.
Hyp1: Mary decided to drive to the beach, but her car would not start due to a dead battery.
Hyp2: It made a weird sound upon starting.
样本二:
Obs1: Jenny was addicted to sending text messages.
Obs2: Jenny narrowly avoided a car accident.
Hyp1: Since her friend's texting and driving car accident, Jenny keeps her phone off while driving.
Hyp2: Jenny was looking at her phone while driving so she wasn't paying attention.3.1.2 基础阅读理解(SQuAD1.1)
Stanford Question Answering Dataset(SQuAD)是由 Rajpurkar等人提出的一个抽取式QA数据集(闭集),v1.1版本在2016年EMNLP的论文中提出。
SQuAD的答案是text span,就是以文章原文中的某小一段文字来作为问题的答案。简单地说,就是从段落里“找现成答案”。该数据集包含 10万多个(问题、原文、答案)三元组,原文来自于 536 篇维基百科文章。
SQuAD是行业公认的机器阅读理解顶级水平测试,是机器阅读理解领域的"ImageNet",同样是一个数据集、搭配一个竞争激烈的竞赛。
下面给出了样本,大家可以感受一下。目前,该数据集榜单上最高准确率达到了90.6%(EM,2021),远远超越了人类的准确率82.3%。

3.1.3 中级阅读理解(SQuAD2.0)
- 榜单:https://rajpurkar.github.io/SQuAD-explorer/
- 论文:http://arxiv.org/abs/1806.03822
- 官网:https://worksheets.codalab.org/worksheets/0x9a15a170809f4e2cb7940e1f256dee55/
SQuAD 2.0在2018年ACL的论文中被提出,该论文是当年的最佳短论文。在SQuAD1.1中,段落中一定会有答案,只是在哪个具体位置的问题。
SQuAD2.0在SQuAD1.1的10万多个QA基础上,又针对相同段落混入了5万多个没答案的问题。这些新增的问题由人工刻意编写,使其看起来与相应段落相关、且看似存在合理的答案,十分具有迷惑性,因此难度更高。
要在SQuAD2.0上做得好,系统不仅要在可回答的情况下回答问题,还必须确定该段落何时不能支持回答该问题。下面给出了样本示例,大家可以感受下。
目前,该数据集上的最高准确率达到90.94%(EM,2021),同样显著超越了人类的准确率86.8%。

3.1.4 英语理解(SuperGlue)
- 榜单:https://super.gluebenchmark.com/leaderboard
- 论文:https://w4ngatang.github.io/static/papers/superglue.pdf
- 官网:https://super.gluebenchmark.com/
SuperGLUE(General Language Understanding Evaluation)是一个广泛用于测试自然语言理解模型性能的基准测试集合,由纽约大学发布(2020.2.13)。包含8个任务,涵盖了自然语言推理、问答、文本蕴含等多个领域,是自然语言理解领域最具挑战性的测试集之一,旨在推动自然语言处理技术的发展。该基准设置了一个总体评估指标:SuperGLUE 分数,即在所有任务上所得分数的平均。目前,榜单上最强模型的得分为91.3(2022),已经超越了人类的89.8分。每个任务都有许多样例,以下是几个任务的样例。
任务1样例:判断给定问题的答案是否为“是”或“否”。
Question:
Has any candidate ever run for president more than once?
Passage:
Multiple candidates have run for president more than once. However, only one candidate has been elected to the office of President of the United States for two non-consecutive terms. Franklin Delano Roosevelt won both the 1932 and 1936 elections, and then won two more terms in 1940 and 1944.
Answer:
yes
任务2样例:给定一个段落和一组问题,要求从段落中标记出能够回答问题的部分。
Passage:
Vladimir Putin was born in Leningrad, now known as St. Petersburg, on October 7, 1952. After graduating from Leningrad State University in 1975, Putin joined the KGB, the security agency of the Soviet Union. Putin served as an officer in the KGB for 16 years, rising to the rank of lieutenant colonel. Following the collapse of the Soviet Union in 1991, Putin entered politics and eventually became president of Russia in 2000.
Questions:
What was Putin's job before entering politics?
When did Putin become president of Russia?
Answer:
Putin worked as an officer in the KGB for 16 years.
Putin became president of Russia in 2000.
任务5样例:给定一个句子和两个名词短语,判断哪个名词短语更符合句子中的指代关系。
Sentence:
The trophy wouldn't fit in the brown suitcase because it was too big.
Option 1:
trophy Option 2: suitcase
Answer:
Option 2
任务8样例:给定一个段落和一组问题,要求回答每个问题,同时提供支持答案的句子。
Passage:
John is trying to decide where to go on vacation. He wants to go somewhere warm and sunny, but he also wants to see some interesting sights. He is considering Hawaii, Florida, and California. Hawaii is known for its beautiful beaches and warm weather. Florida has many theme parks and attractions, as well as beaches. California is home to Hollywood and many famous landmarks, such as the Golden Gate Bridge.
Questions:
What is John trying to do?
What are the three places John is considering?
What is Hawaii known for?
What does Florida have besides beaches?
What is California home to?
Answer:
John is trying to decide where to go on vacation.
John is considering Hawaii, Florida, and California.
Hawaii is known for its beautiful beaches and warm weather.
Florida has many theme parks and attractions, as well as beaches.
California is home to Hollywood and many famous landmarks, such as the Golden Gate Bridge.3.1.5 多任务语言理解(MMLU)
- 榜单:https://paperswithcode.com/sota/multi-task-language-understanding-on-mmlu
- 论文:http://arxiv.org/pdf/2009.03300v3
- 官网:https://paperswithcode.com/dataset/mmlu
多任务语言理解(MMLU)由UC Berkeley大学的研究人员在2020年9月7日提出,用于衡量文本模型的多任务准确性。涵盖了57个任务,包括基本数学、美国历史、计算机科学、法律等多个领域。为了在这个测试中获得高准确性,模型必须具备广泛的世界知识和问题解决能力。从下面的样例可以看出,虽然都是选择题,但因为领域很多,要都回答正确的话其难度也不小。目前,榜单上最强模型的准确率达到了90%(Gemini Ultra, 1760B, 2024.1),正式超越了人类专家的准确率89.9%、也超越了GPT-4的准确率86.4%。
(微观经济学)政府反对和监管垄断的原因之一是
(A)生产者剩余减少,消费者剩余增加。
(B)垄断价格确保生产效率,但对社会的资源配置效率造成损失。
(C)垄断企业不进行重要的研究和开发。
(D)高价格和较低产量导致消费者剩余减少。正解
(概念物理)当你从静止状态抛出一个球时,它以9.8米/秒²的加速度向下加速。如果你假设没有空气阻力向下抛出它,它离开你的手后立即的加速度是
(A)9.8 米/秒²
(B)大于9.8 米/秒²
(C)小于9.8 米/秒²
(D)除非给出抛出速度,否则无法确定。
(学院数学)在复数平面z平面上,满足方程z² = |z|²的点集是
(A)一对点
(B)圆
(C)半直线
(D)直线
(专业医学)一位33岁的男子因甲状腺癌接受激素治疗。手术期间,左侧颈部出现中度出血,需要结扎几条血管。术后血液检查显示血钙浓度为7.5 mg/dL,白蛋白浓度为4 g/dL,甲状旁腺激素浓度为200 pg/mL。造成患者这些发现的是下列哪一条血管?
(A)肋颈干的分支
(B)外颈动脉的分支
(C)颈甲状干的分支 正确
(D)颈内静脉的支流3.2 图像处理任务
目前AI在图像处理方面的具体能力如何?本节将基于常见任务的测评基准,分别展开介绍。
3.2.1 图像分类(ImageNet)
- 榜单:https://paperswithcode.com/sota/image-classification-on-imagenet
- 论文:https://ieeexplore.ieee.org/document/5206848
- 官网:https://www.image-net.org/
ImageNet是一个“古老”的数据集,由李飞飞团队创建(2009年IEEE论文)。其数据结构按照WordNet层次结构组织,每个节点包含成百上千个图像。其主要特征:
- 规模庞大:总量超过1400万张图片、2万多分类,是当前最大的公开图像数据库之一。
- 多样性:包含了各种物体和场景,图像涵盖了动物、植物、日常生活物品等等。
- 高质量标注:图像经过了精确的人工标注,每个图像都有对应的物体类别和位置标签。
- 挑战性:其中的一些类别具有很高的相似性,使得图像分类任务具有挑战性。
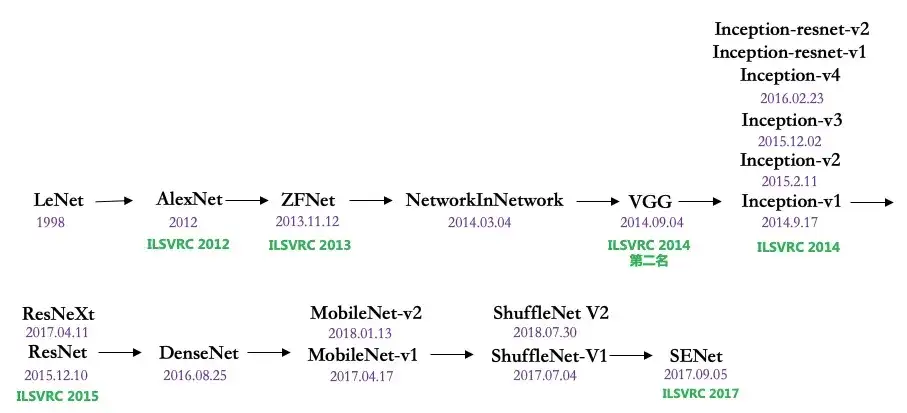
自2010年以来,每年都会举办ILSVRC(ImageNet Large-Scale Visual Recognition Challenge)图像识别大赛,该赛事基于ImageNet子集(128、5、10万张、1000类)。竞赛和刷榜的历史见证了很多知名神经网络模型的诞生,比如AlexNet、VGG、GoogLeNet、ResNet、Inception、DenseNet等模型。各类模型基于ImageNet持续创新迭代,准确率从从最初的71.8%持续提升,并超越了人类的识别率94.9%,所以该竞赛自2017年起不再举办(但仍可刷榜)。有人就会问,不就是一个看图识物么,难在哪里?以看图识狗为例,其在ILSVRC竞赛中的类别达到120种。由于数据太难、模型普遍不给力,所以当时的评估用采用Top5准确率(让你答5次,有1次对得上就算准确)。在2017年ImageNet竞赛中,最强模型的top-5准确率达到了98%,而人眼辨识的Top5错误率大概为5.1%(乐观估计则为2.4%)。但当时最高的top-1准确率只有82%。
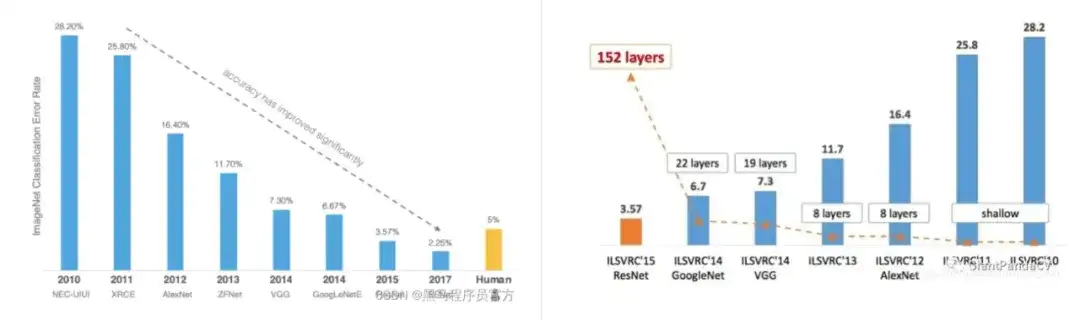
目前,Top5已经成为过去式,最强模型的Top1准确率都已经达到了92.4%(OmniVec ViT, 2023.11)。我暂未找到人类top-1准确率的报道(如有人发现,敬请补充)。
3.2.2 图像生成(HEIM)
图像生成包含了多种场景,比如文生图、图生图、图像编辑、3D重建等等。
- 文生图:通过文本提示词生成图片
目前,文生图比较著名的模型有DALL-E(OpenAI)、MidJourney、StableDiffusion。

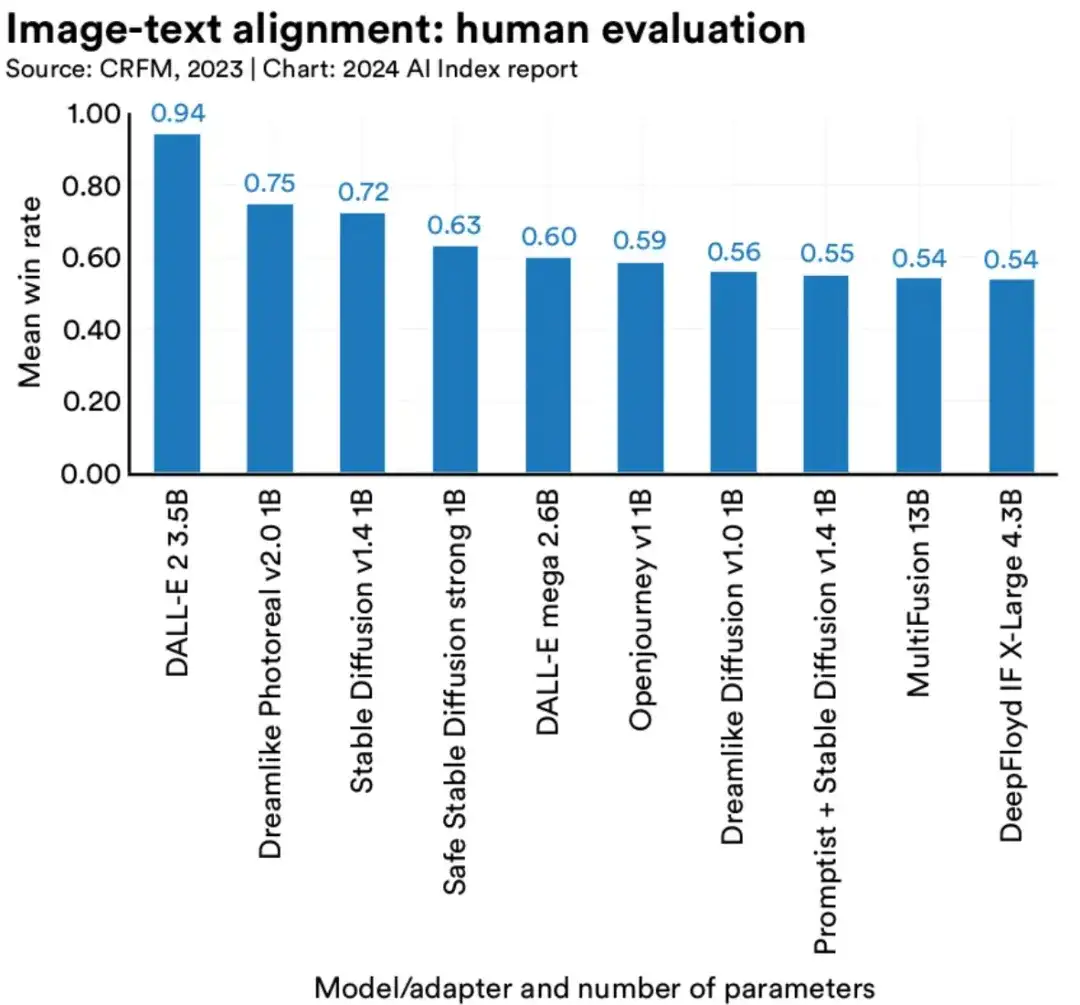
一种评估文生图的方法,是2023年Stanford研究人员提出的Holistic Evaluation of Text2Image Models (HEIM)基准,它从12个方面全面评估生成器的能力,比如文图一致性、图片质量、美学。目前DALL-E2 3.5B在文图一致性方面显著领先,但尚未有模型能在所有维度全面领先。
- 文生图:通过文本编辑图片
通过文本提示词输入,实现对图片的编辑。这种情况下如何评价模型生成的好坏,是存在难度的。目前,EditVal是最近新出的测评基准,用于文本引导图片编辑场景,该基准包含了13种编辑类型(比如调尺寸、加东西、改位置、目标替换,等等)、涉及19类目标。目前,各类模型的准确率普遍不高。下图是该测评基准中的样例。

- 文生图:辅助图片引导的图片生成
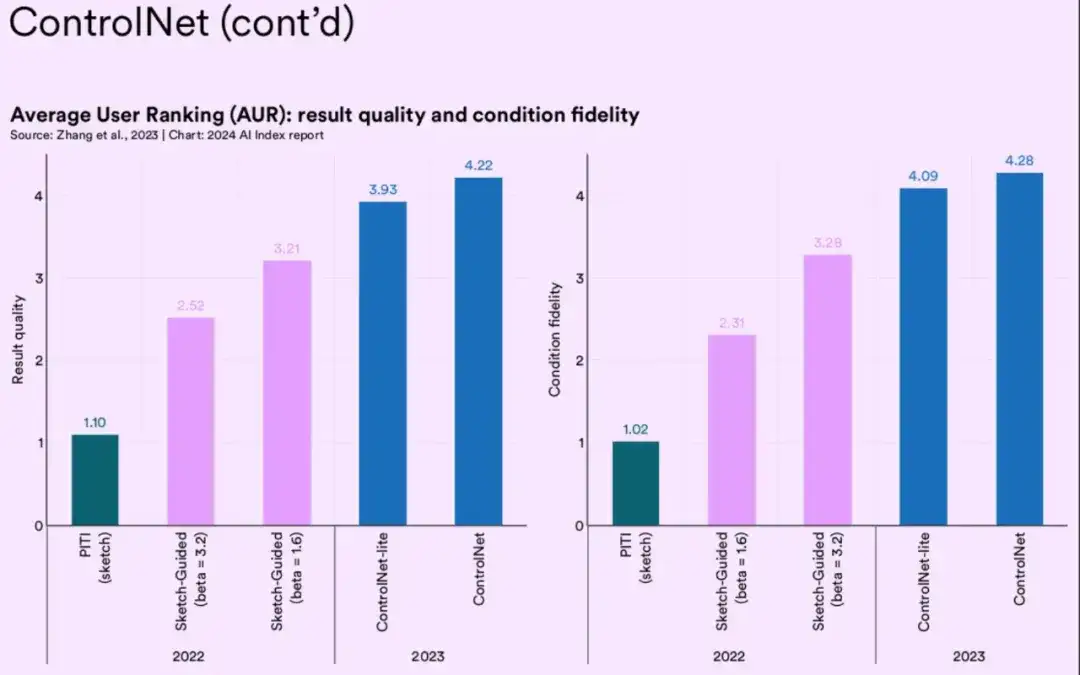
通过文本来生成图片的一个问题是,难以精准控制图片内容的空间构成,比如复杂的布局、特定的姿势、不同的形状。理论上可以针对特定的场景进行模型的Fine-Tuning来实现,但实际样本的有限性、场景多样性,使得这种方式的训练并不好做。2023年,斯坦福大学推出了一种新的模型:ControlNet。这个模型对于提升文生图的精准度具有非常重大意义。

- 文生图:text-to-3D geometries
论文:https://arxiv.org/html/2308.16512v4基于文本输入,生成一组3D多视角的图片。典型代表是MVDream(ByteDance&UCSD,生成256*256的图片),它是一个从文本到多视角图像的生成模型,同时从2D和3D的数据中学习,达到在2D下的泛化性以及3D渲染的一致性。


- 文生图:3D图片编辑
Berkeley的研究人员开发了一个模型(Instruct-NeRF2NeRF),能基于文本指令来对3D图片进行编辑。

- 文生图:3D重建
所谓3D重建,是指基于2D图片来生成3D几何体。这有啥用呢?比如,医疗图像、机器人、虚拟现实。2023年发布的Skoltech3D数据集,用于多视角3D表面重建。该数据集包含了140万张图片,来自100种不同视角、14种不同光照条件的107个场景。
- 图像处理:图生3D
2023年,牛津大学研究人员提出的RealFusion,可以基于单张图片生成完整的3D模型,从而实现3D重建。它先是基于2D的图像生成器生成物体的多视角图,然后将它们组合成360度的模型。

3.2.3 语义分割
语义分割就是将图片中的各种目标进行像素级的分割,是图像处理领域非常重要的一个分支问题。通常,语义分割模型基于特定数据的训练后,只负责从图像中分割出特定类别的目标。
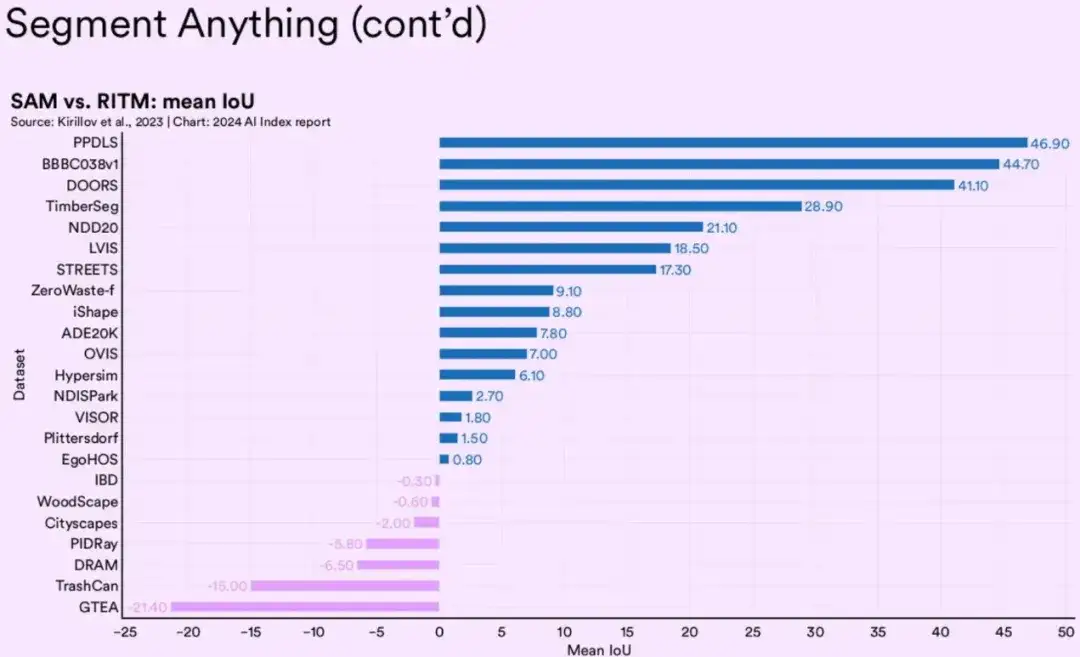
2023年Meta发布的模型Segment Anything(SAM),则实现了通用分割能力,能将一张图像中所有目标都分割出来,为该技术领域开辟了新的方向。
为了实现同一张图上的多类目标、或非特定目标的分割,学术界曾提出了交互式图像分割方法,其中代表者是RITM(三星电子的三星研究院Samsung Labs);而 SAM在23个语义分割任务测评中,有16个领先RITM模型,成为领域内最强模型。
AM是一种可提示的分割系统,对不熟悉的对象和图像进行零样本泛化,无需额外训练;根据点或框等输入提示生成高质量的对象遮罩,可用于为图像中的所有对象生成掩膜。

官网Demo地址:https://segment-anything.com/demo
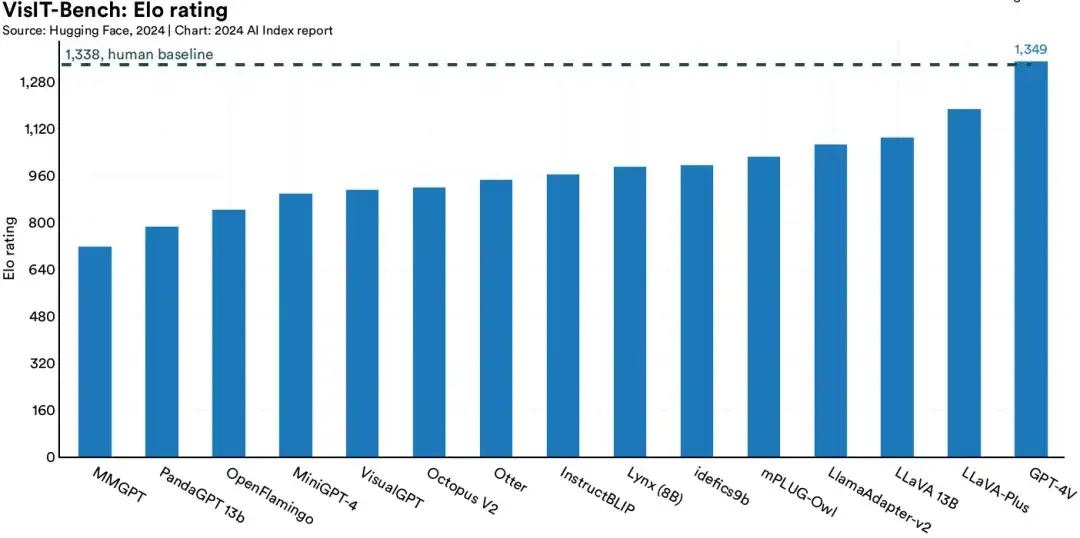
3.2.4 图像理解(VisIT-Bench)
VisIT-Bench是一个用于评估“指令遵循视觉语言模型”(Instruction-following vision-language models)的新基准,针对的是真实世界的使用情况。包含70个“指令类型”、592个测试用例,包括图像、指令、人工描述和验证后的生成结果,涵盖从识别到推理等各种技能。A sample VisIT-Bench instruction set

An example of a multi-image instruction task from VisIT-Bench

截至到2024年1月,GPT-4V(GPT-4 Turbo的视觉版)是该基准上表现最好的模型。其得分达到了1349,超越了人类水平参考分。
3.3 语音生成
2023年可以说得上是音频生成领域重大突破之年,涉及的音频合成既有人声演讲、也有音乐生成。一些重要的音频生成器,比如UniAudio、MusicGen、MusicLM,等等。这些模型的能力到底达到了什么程度?
3.3.1 音频生成
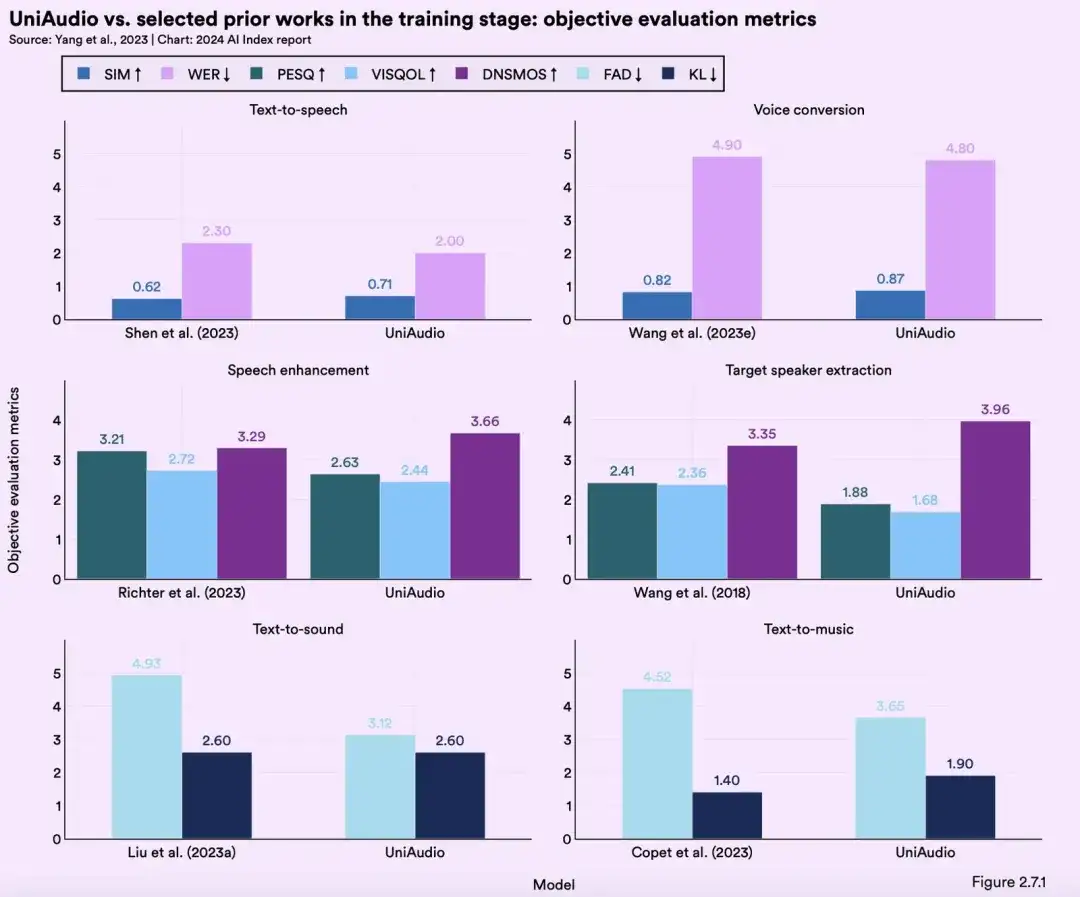
UniAudio是一种基于语言模型(多尺度Transformer模型)的用于音频内容生成的技术,于2023年10月9日发布(港中文、CMU、微软亚洲研究院、ZJU等),拥有1B参数。经过16.5万小时的音频上进行了训练,支持11种不同的音频生成任务(超过了音频研究领域的所有其他模型)。与当前LLMs一样,它统一化地对所有音频类型进行分词,采用逐词预测的方式来生成高质量的音频,能够生成高质量的语音、声音和音乐。UniAudio在11种任务中表现出来竞争力、并在若干任务中超越了其它先进方法,比如Text2Speech、语音增强以及语音转换等任务。
3.3.3 语音处理
- 论文:https://arxiv.org/pdf/2212.04356
- 官网:https://dataconomy.com/2023/11/07/openai-whisper-v3-speech-recognition/
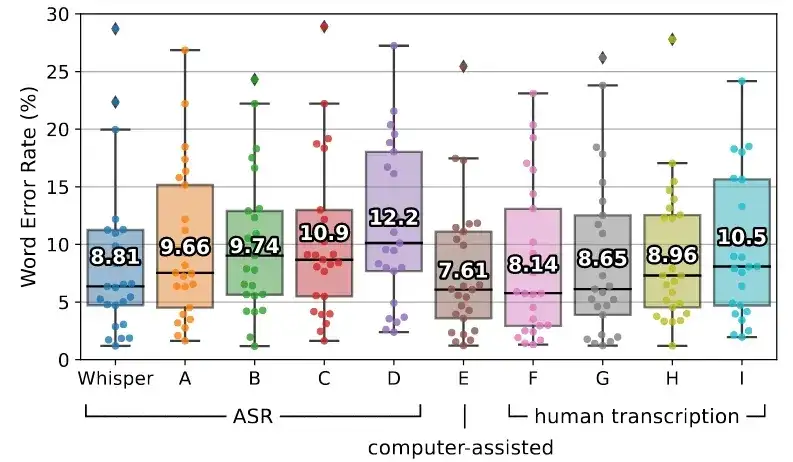
Whisper V3是OpenAI在2023年11月推出的语音模型,用于语音识别、语种辨识、语音翻译。该模型在68万小时的多种语言、多种任务的数据下进行了训练;不同于Wav2Vec等使用无监督方法训练的预训练语音大模型,Whisper使用弱监督训练的方法,可以直接进行多任务的学习,而不需要针对特定任务做finetune。其准确度、可靠性都接近与人类水平。
官方样例:https://openai.com/index/whisper/
3.3.2 音乐生成
- Github:https://github.com/facebookresearch/audiocraft
- 官网:https://about.fb.com/news/2023/08/audiocraft-generative-ai-for-music-and-audio/
Meta的MusicGen是一种新的音频生成模型,也是利用语言模型中常见的transformer架构来生成音频。MusicGen可以基于简单的文本描述来创建高质量、免版税的音乐,并直接在项目中使用。
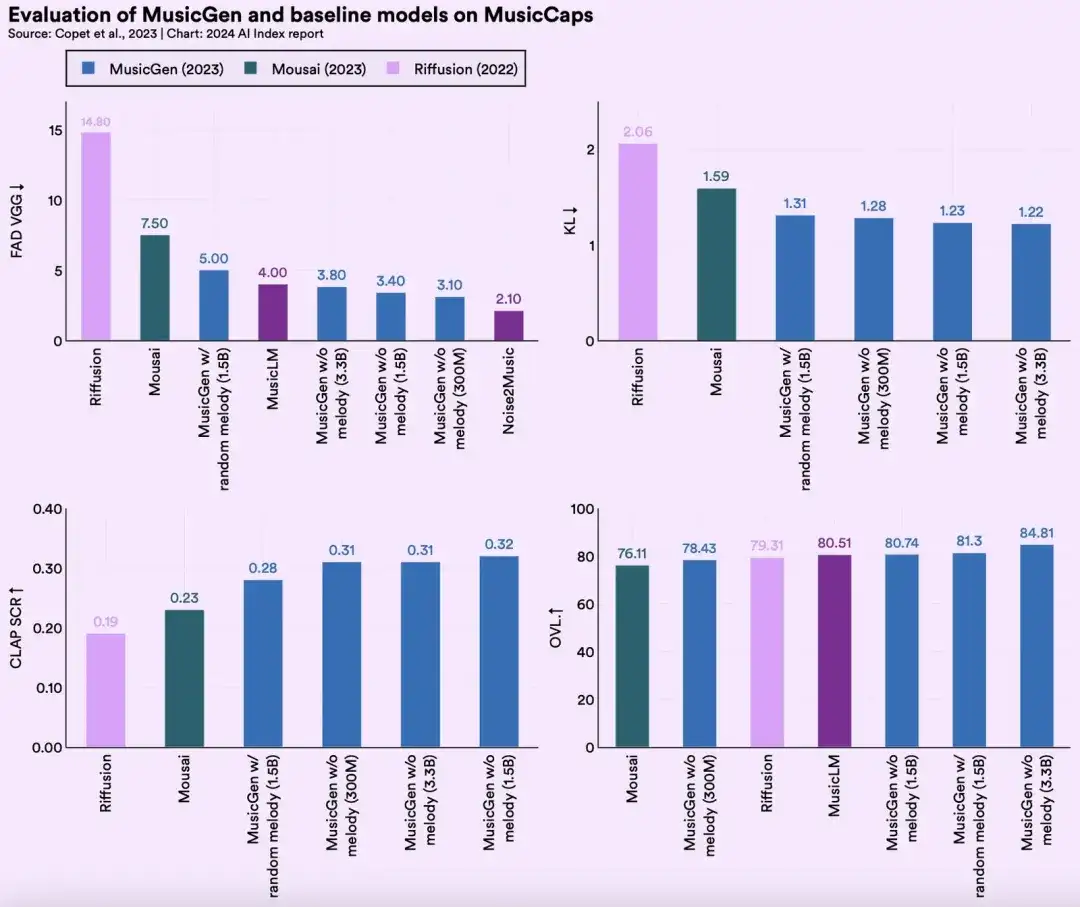
该模型使用了1万小时的“高质量”授权歌曲和39万首器乐曲目进行训练(与版权持有人签订了法律协议)。测评研究显示,MusicGen在各种生成音乐评估指标上超过了其他流行的文本到音乐模型,如Riffusion、Moûsai和MusicLM。
特点:
- 更低的FAD分数,意味着更可靠的音乐生成;
- 更低的KL得分,意味着与参考音乐有更好的一致性;
- 更高的CLAP得分,说明能更好地依循参考音乐的文本描述来进行创作。
- 此外,因其整体更好的质量,使得人类评估者对其更加青睐。
尽管MusicGen优于同年早先发布的一些Text2Music模型,但MusicLM值得一提;因为与其一起发布的还有MusicCaps数据集,是一个包含5500个“音乐-文本”对的SOTA数据集。
MusicGen的研究者用该数据集对他们的系列模型进行了基准测评。MusicsGen模型以及MusicCaps数据集基准的出现,意味着生成式人工智能已经不再局限于语言和图像,而是拓展到了更多样的模态比如音频生成。
官方样例:https://about.fb.com/news/2023/08/audiocraft-generative-ai-for-music-and-audio/
写在最后
本文基于常见任务的测评基准,从自然语言理解,图像处理,语音生成三大方面对AI进行实测。因此,我们可以更加清晰了解到哪些能力是AI具备的、哪些是不具备的。在下期文章中,我会向大家展示AI在视频生成、代码能力、AI 推理等方面的能力表现及效果。
篇幅较长、又限于个人水平和视野,故难免存在不准确之处,敬请批评指正。欢迎探讨和交流。
“可信 AI 进展 “ 公众号致力于最新可信人工智能技术的传播和开源技术的培育,覆盖大规模图学习,因果推理,知识图谱,大模型等技术领域,欢迎扫码关注,解锁更多 AI 资讯~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









