







目录
一、方法引用
方法引用概述
class Task implements Runnable {
@Override
public void run() {
System.out.println("自定义类线程任务");
}
}
public void m1() {
Task task = new Task();
new Thread(task).start();
//匿名内部类
new Thread(new Runnable() {
//重写run方法
@Override
public void run() {
System.out.println("匿名内部类线程任务");
}
}).start();
//使用Lambda表达式,可以代替匿名内部类 (限制:针对函数式接口)
new Thread(() -> {
System.out.println("Lambda线程任务");
}).start();
}当使用Lambda实现一个逻辑时,如果这个逻辑已经在某个类中存在相同逻辑的方法,可直接引用而不需要写Lambda。
结论:Lambda用来简化匿名内部类,方法引用是用来简化Lambda。符号是双冒号 ::。
| 种类 | 语法格式 |
|---|---|
| 静态方法引用 | 类名::静态方法名 |
| 构造器引用 | 类名 :: new |
| 类的任意对象的实例方法引用 | 类名::实例方法名 |
| 特定对象的实例方法引用 | 对象:: 实例方法名 |
方法引用的分类:(在方法引用时使用双冒号做为引用符号 )
-
引用静态方法 ==> 类名::静态方法名
-
引用构造方法 ==> 类名::new
-
引用类的任意对象方法 ==> 类名::实例方法名
-
引用特定对象的方法 ==> 对象::实例方法名
1. 静态方法的引用(类名::静态方法名)
//1.匿名内部类
MathTool max1 = new MathTool() {
@Override
public int max(int a, int b) {
return Math.max(a,b);
}
};
//2.Lambda
MathTool max2 = (a,b)->Math.max(a,b);
//3.方法引用
MathTool max3 = Math::max;2.构造器引用(类名::new)
在Stream流中,将流中字符串转换为一个奥特曼类型的对象 //map()方法,Ultramannn::new会自动指向带有字符串参数的构造方法。
List<String> aoTu = new ArrayList<>();
Collections.addAll(aoTu, "迪迦", "杰克", "赛文");
//1.匿名内部类
aoTu.stream().map(new Function<String, Ultramannn>() {
@Override
public Ultramannn apply(String name) {
return new Ultramannn(name);
}
}).forEach(System.out::println);
//2.Lambda
aoTu.stream().map((name)->new Ultramannn(name)).forEach(System.out::println);
//3.方法引用
aoTu.stream().map(Ultramannn::new).forEach(System.out::println);3.类任意对象的实例方法引用(类名::方法名)
List<String> aoTu = new ArrayList<>();
Collections.addAll(aoTu, "迪迦", "杰克", "赛文");
//方法引用
aoTu.stream().map(Ultramannn::new).forEach(Ultramannn::fly);
//迪迦在飞...
//杰克在飞...
//赛文在飞...4.特定对象的实例方法引用(对象::方法)
List<String> aoTu = new ArrayList<>();
Collections.addAll(aoTu, "迪迦", "杰克", "赛文");
//方法引用
aoTu.stream().map(Ultramannn::new).forEach(System.out::println);方法引用的作用:可以替换Lambda表达式的书写(简化书写)
二、Base64
1.Basic编码:
输出被映射到一组字符A-Za-z0-9+/,编码不添加任何行标,输出的解码仅支持A-Za-z0-9+/
String msg = "我是迪迦!!";
//编码器:Base64.getEncoder(),调用encodeToString编码
String baseMsg = Base64.getEncoder().encodeToString(msg.getBytes());
System.out.println("编码后的数据 = " + baseMsg);
//获取解码器:Base64.getDecoder(),decode解码
byte[] bytes = Base64.getDecoder().decode(baseMsg);
System.out.println("解码后的数据 = " + new String(bytes));2. URL编码:
输出映射到一组字符A-Za-z0-9-_,输出是URL和文件
String url = "www.dijia.com";
//URL编码器:Base64.getUrlEncoder(),调用encodeToString编码
String base64Url = Base64.getUrlEncoder().encodeToString(url.getBytes());
System.out.println("编码后的数据 = " + base64Url);
//URL解码Base64.getUrlDecoder(),调用decode解码
byte[] decode = Base64.getUrlDecoder().decode(base64Url);
System.out.println("解码后的数据:" + new String(decode));3.MIME编码:
使用基本的字母数字产生Base64输出,而且对MIME格式友好:每一行输出不超过76个字符,而且每行以“\r\n”符结束。
文件的MIMEBase64编解码:
public void m8() {
//将file/img/迪迦.jpg 编码成为Base64文件 用file/img/迪迦Base64.jpg保存
String src1 = "F:\\files\\img/迪迦.jpg";
String dest1 = "F:\\files\\img/迪迦Base64.jpg";
//编码成为Base64文件
encodeFile(src1, dest1, Base64.getMimeEncoder());
//解码Base64的图片
decodeFile(dest1,"F:\\files\\img/迪迦2.jpg",Base64.getMimeDecoder());
}
/**
* 实现对文件进行Base64编码得到新文件
*/
public void encodeFile(String src, String dest, Base64.Encoder encoder) {
try (FileInputStream fis = new FileInputStream(src);//按照正常的方式读取字节数据
//创建一个字节输出流,然后包装为能够编码Base64数据的输出流
OutputStream fos = encoder.wrap(new FileOutputStream(dest));) {
byte[] bytes = new byte[1024];
int len;
while ((len = fis.read(bytes)) != -1) {//读取原始的文件数据
fos.write(bytes, 0, len);//写出去的是Base64数据
}
} catch (IOException e) {
}
}
/**
* 实现对Base64编码文件解码得到源文件
*/
public void decodeFile(String src, String dest, Base64.Decoder decoder) {
try (InputStream fis = decoder.wrap(new FileInputStream(src));
//将普通的字节输入流,包装成为一个能够解码Base64数据的输入流
OutputStream fos = new FileOutputStream(dest);) {
byte[] bytes = new byte[1024];
int len;
while ((len = fis.read(bytes)) != -1) {//按照Base64的解码方案进行读取
fos.write(bytes, 0, len);//将正常的数据写到文件中
}
} catch (IOException e) {
}
}三、XML
-
XML全称:EXtensible Markup Language(可扩展的标记语言)。是由各种标记(标签、元素)组成
-
可扩展:所有的标签都是自定义的,可以随意扩展的。如:<abc/>,<姓名>
-
标记语言:整个文档由各种标签组成
-
-
XML设计的初衷是用来传输和存储数据
1.数据传输的应用:(基本不用)
数据交换:不同的计算机语言之间,不同的操作系统之间,不同的数据库之间,进行数据交换。
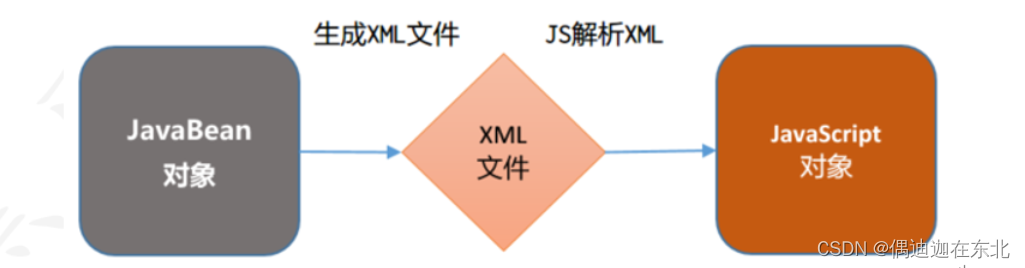
2.存储数据的应用:配置文件
XML文档组成
-
声明
-
元素(标签)
-
属性
-
注释
-
转义字符【实体字符】
-
CDATA (字符区)
1.文档声明:(固定的格式)
<?xml version="1.0" encoding="utf-8" ?>
-
文档声明必须为
<?xml开头,以?>结束 -
文档声明必须从文档的1行1列位置开始,==必须在xml文档中的首行首列==
-
文档声明中常见的两个属性:
-
version:指定XML文档版本。必须属性,这里一般选择1.0
-
encoding:指定当前文档的编码,可选属性,默认值是utf-8
-
2.元素:也称为标签
格式1: 有标签体的标签
<person> 内容(元素体) </person>
格式2: 没有标签体的标签
<person/> 1.元素是XML文档中最重要的组成部分
2.普通元素的结构由开始标签、元素体、结束标签组成
3.元素体:元素体可以是元素,也可以是文本
<person>
<name>张三</name>
</person>4.空元素:空元素只有标签,而没有结束标签,但元素必须自己闭合
<sex/>5.元素命名
-
区分大小写
-
不能使用空格,不能使用冒号
-
不建议以XML、xml、Xml开头
结论:除了不能使用美元符号外,可以保持与Java命名标识符一样的规则
6.有且仅有一个根元素
3.属性
<person id="110" myid="111">-
属性是元素的一部分,必须出现在元素的开始标签中
-
属性的定义格式:
属性名=“属性值”,其中属性值必须使用单引或双引号括起来 -
一个元素可以有0~N个属性,但一个元素中不能出现同名属性
-
属性名定义规则可以和标签名一样
<person id="123">
<name>张三</name>
</person>
<sex value="男"/>4.注释
<!-- 注释内容 -->5.转义字符(实体字符)
因为很多符号已经被xml文档结构所使用,所以在元素体或属性值中想使用这些符号就必须使用实体字符
转义字符应用示例:
在 XML文档中放置了一个类似 "<" 字符,那么这个文档会产生一个错误,因为解析器会把它解释为新元素的开始。
<!-- 小于号 < -->
<message>if salary < 1000 then</message>| 字符 | 预定义的转义字符 | 说明 |
|---|---|---|
| < | < | 小于(less than) |
| > | > | 大于(greater than) |
| " | " | 双引号(quotation) |
| ' | ' | 单引号(apostrophe) |
| & | & | 和号(ampersand ) |
6.CDATA(字符区)
当大量的转义字符出现在xml文档中时,会使XML文档的可读性大幅度降低。这时可以使用CDATA字符区。CDATA (Character Data)字符数据区,格式如下:
<![CDATA[
文本数据 < > & ; " "
]]>-
CDATA 指的是不应由 XML 解析器进行解析的文本数据(Unparsed Character Data)
-
CDATA 部分由
<![CDATA[开始,由]]>结束; -
CDATA 部分不能包含字符串 "]]>"。也不允许嵌套的 CDATA 部分
-
标记 CDATA 部分结尾的 "]]>" 不能包含空格或折行
XML约束 :DTD
在XML技术里,可以编写一个文档来约束一个XML文档的书写规范,这称之为XML约束。
-
XML文档通常书写的都是用户自定义的标签,若出现小小的错误,软件程序将不能正确地获取文件中的内容而报错
常见的xml约束:DTD、Schema
DTD约束
DTD(Document Type Definition),文档类型定义,用来约束XML文档
DTD可以规定XML文档中元素的名称,子元素的名称及顺序,元素的属性等
DTD语法:
<!-- 在DTD中,使用ELEMENT来对XML文档中的元素进行声明 -->
<!ELEMENT 元素名称 使用规则>DTD示例
DTD:
<!ELEMENT 书架 (书+)> <!--表示至少出现一次-->
<!ELEMENT 书 (书名,作者,售价)> <!--约束元素书的子元素必须为书名、作者、售价-->
<!ELEMENT 书名 (#PCDATA)>
<!ELEMENT 作者 (#PCDATA)>
<!ELEMENT 售价 (#PCDATA)>
XML:
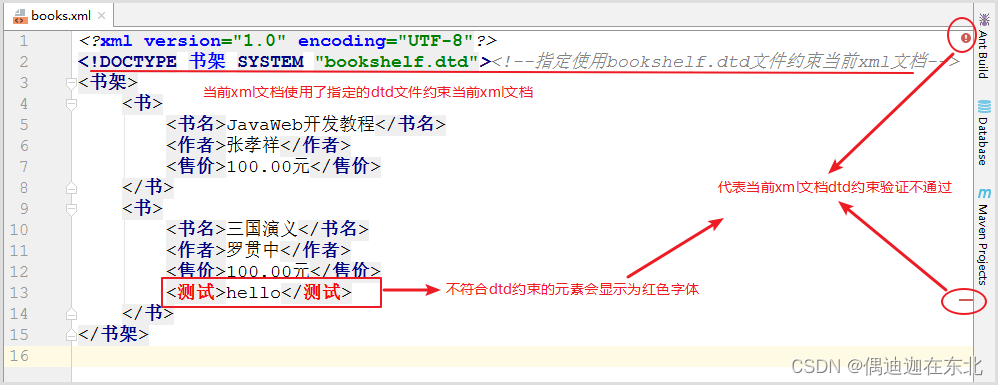
<!-- 引入外部的DTD约束 --> <!--<!DOCTYPE 根元素 SYSTEM "dtd约束文件的路径">-->
<!DOCTYPE 书架 SYSTEM "bookshelf.dtd"> <!--指定使用bookshelf.dtd文件约束当前xml文档-->
<书架>
<书>
<!--顺序及子标签类型必须按照dtd中定义-->
<书名></书名>
<作者></作者>
<售价></售价>
<!-- <售></售>--><!--不符合DTD定义的子标签会报错-->
</书>
</书架>| 规则 | 描述 |
|---|---|
| (子元素) | 指示元素中包含的子元素 |
| (#PCDATA) | 指示元素的主体内容只能是普通的文本 |
| ANY | 指示元素的主体内容为任意类型 |
| EMPTY | 用于指示元素的主体为空 |
定义子元素:
-
如果子元素用逗号分开,说明必须按照声明顺序去编写XML文档
<!ELEMENT file (name,size,date)-
如果子元素用"|"分开,说明任选其
<!ELEMENT file (title|name)-
在定义子元素时可以使用:
+、*、?来表示元素出现的次数:-
如果元素后面没有
+、*、?: 表示必须且只能出现一次 -
+:表示至少出现一次(一次或多次) -
*:表示可有可无(零次或多次) -
?:表示可有可无 (零次或一次)【有的话只能有一次】
-
<!ELEMENT 书架 (书+)><!--表示书子标签至少出现一次-->
<!ELEMENT 书 (书名,作者,售价)><!--约束元素书的子元素必须为书名、作者、售价,限制顺序-->
<!ELEMENT 书名 (#PCDATA)>
<!ELEMENT 作者 (#PCDATA)>
<!ELEMENT 售价 (#PCDATA)>XML约束:Schema约束
Schema 语言也叫做 XSD(XML Schema Definition)。
其本身也是XML格式文档,但Schema文档扩展名为xsd,而不是xml。
Schema 功能更强大,数据类型约束更完善。 比DTD强大,是DTD代替者
DTD约束无法对具体数据类型进行约束,所以开发工具没有任何错误提示,而Schema约束可以对XML文件中的元素体数据类型进行约束。
Schema冲突:
一个XML文档最多可以使用一个DTD文件,但一个XML文档中使用多个Schema文件,若这些Schema文件中定义了相同名称的元素时,使用的时候就会出现名字冲突。
结论:在XML文档中通过名称空间(namespace)来解决自定义的元素名称或自定义的属性名称冲突
名称空间就是在根元素后面的内容 , 使用xmlns引入
当一个XML文档中需要使用多个Schema文件的时候 , 有且仅有一个使用缺省的 , 其他的名称空间都需要起别名
xmlns="http://www.dijia.cn"
<!-- 缺省的名称空间.使用此约束中的元素的时候只需要写元素名即可 例如:<书></书> -->
xmlns:aa="http://java.dijia2.com"
<!-- aa就是此约束的别名,使用此约束中的元素的时候就需要加上别名 例如:<aa:书></aa:书> --><根元素>
<别名:姓名> </别名:姓名>
<数据>
<姓名></姓名>
</数据>
</根元素>














 3895
3895











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









