







第一章 Flink简介
1.1 初识 Flink


- Flink项目的理念 是 Apache Flink 是为分布式、高性能、随时可用以及准确的流处理应用程序打造的开源流处理框架 ”。
- Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。 Flink 被设计 在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。
1.2 Flink 的重要特点
事件驱动型 Event driven)
- 事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。比较典型的就是以 kafka 为代表的消息队列几乎都是事件驱动型应用。
- 与之不同的就是SparkStreaming 微批次,如图:

- 事件驱动型:

流与批的世界观
- 批处理的特点是有界、持久、大量, 非常适合需要访问全套记录才能完成的计算工作 ,一般用于离线统计 。
- 流处理的特点是无界、实时 , 无需针对整个数据集执行操作,而是对通过系统传输的每个数据项执行操作,一般用于实时统计。
- 在spark 的世界观中 ,一切都是由批次组成的,离线数据是一个大批次,而实时数据是由一个一个无限的小批次组成的。
- 而在flink 的世界观中 ,一切都是由流组成的,离线数据是有界限的流,实时数据是一个没有界限的流,这就是所谓的有界流和无界流。
- 无界数据流: 无界数据流有一个开始但是没有结束 ,它们不会在生成时终止并提供数据,必须连续处理无界流,也就是说必须在获取后立即 处理 event 。对于无界数据流我们无法等待所有数据都到达,因为输入是无界的,并且在任何时间点都不会完成。处理无界数据通常要求以特定顺序(例如事件发生的顺序)获取 event ,以便能够推断结果完整性。
- 有界数据流: 有界数据流有明确定义的开始和结束 ,可以在执行任何计算之前通过获取所有数据来处理有界流,处理有界流不需要有序获取,因为可以始终对有界数据集进行排序,有界流的处理也称为批处理。
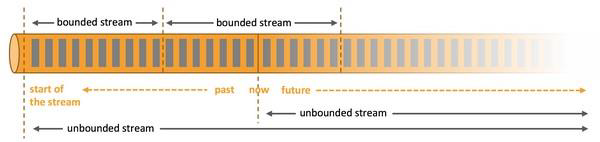
这种以流为世界观的架构,获得的最大好处就是具有极低的延迟。
分层 api
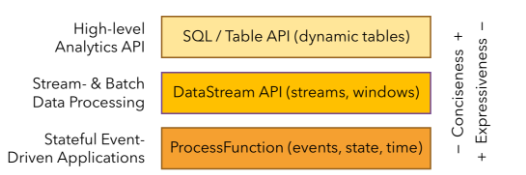
- 最底层级的抽象仅仅提供了有状态流,它将通过过程函数(Process Function)被嵌入到 DataStream API 中。底层过程函数(Process Function) 与 (DataStream API)相集成,使其可以对某些特定的操作进行底层的抽象,它允许用户可以自由地处理来自一个或多个数据流的事件,并使用一致的容错的状态。除此之外,用户可以注册事件时间并处理时间回调,从而使程序可以处理复杂的计算。
第二章 快速上手
2.1 搭建 maven 工程 FlinkTutorial
pom文件

2.2 批处理 wordcount
2.3 流处理 wordcount
第三章 Flink部署
3.1 Standalone 模式
3.2 Yarn 模式
3.3 3.3 Kubernetes部署
第四章 Flink运行架构
4.1 Flink 运行时的组件
- Flink运行时架构主要包括四个不同的组件,它们会在运行流处理应用程序时协同工作:作业管理器( JobManager )、资源管理器 ResourceManager )、任务管理器 TaskManager以及分发器( Dispatcher )。因为 Flink 是用 Java 和 Scala 实现的,所以所有组件都会运行在Java 虚拟机上。每个组件的职责如下:
- 作业管理器( JobManager)
控制一个应用程序执行的主进程,也就是说,每个应用程序都会被一个不同的JobManager 所控制执行。 JobManager 会先接收到要执行的应用程序, 这个应用程序会包括:作业图( JobGraph )、逻辑数据流图 logical dataflow graph )和打包了所有的类、库和其它资源的 JAR 包。 JobManager 会把 JobGraph 转换成一个物理层面的数据流图,这个图被叫做“执行图 ExecutionGraph ),包含了所有可以并发执行的任务。 JobManager 会向资源管理器( ResourceManager )请求执行任务必要的资源,也就是任务管理器 TaskManager )上的插槽( slot )。一旦它获取到了足够的资源,就会将执行图分发到真正运行它们的TaskManager 上。而在运行过程中, JobManager 会负责所有需要中央协调的操作,比如说检查点( checkpoints )的协调。 - 资源管理器( ResourceManager)
主要负责管理任务管理器(TaskManager )的插槽 slot TaskManger 插槽是 Flink 中定义的处理资源单元。 Flink 为不同的环境和资源管理工具提供了不同资源管理器,比如YARN 、 Mesos 、 K8s ,以及 standalone 部署。当 JobManager 申请插槽资源时, ResourceManager会将有空闲插槽的 TaskManager 分配给 JobManager 。如果 ResourceManager 没有足够的插槽来满足 JobManager 的请求,它还可以向资源提供平台发起会话,以提供启动 TaskManager进程的容器。另外, ResourceManager 还负责终止空闲的 TaskManager ,释放计算资源。 - 任务管理器( TaskManager)
Flink中的工作进程。通常在 Flink 中会有多个 TaskManager 运行,每一个 TaskManager都包含了一定数量的插槽(
slots )。插槽的数量限制了 TaskManager 能够执行的任务数量。启动之后, TaskManager 会向资源管理器注册它的插槽;收到资源管理器的指令后,TaskManager 就会将一个或者多个插槽提供给 JobManager 调用。 JobManager 就可以向插槽分配任务( tasks )来执行了。在执行过程中,一个 TaskManager 可以跟其它运行同一应 用程序的 TaskManager 交换数据。 - 分发器( Dispatcher)
可以跨作业运行,它为应用提交提供了REST 接口。当一个应用被提交执行时,分发器就会启动并将应用移交给一个 JobManager 。由于是 REST 接口,所以 Dispatcher 可以作为集群的一个 HTTP 接入点,这样就能够不受防火墙阻挡。 Dispatcher 也会启动一个 Web UI ,用来方便地展示和监控作业执行的信息。 Dispatcher 在架构中可能并不是必需的,这取决于应用提交运行的方式。
- 作业管理器( JobManager)
4.2 任务提交流程
我们来看看当一个应用提交执行时, Flink 的各个组件是如何交互协作的:

- 上图是从一个较为高层级的视角,来看应用中各组件的交互协作。如果部署的集群环境不同(例如 YARN Mesos Kubernetes standalone 等),其中一些步骤可以被省略,或是有些组件会运行在同一个 JVM 进程中。
- 具体地,如果我们将Flink 集群部署到 YARN 上,那么就会有如下的提交流程:

- Flink任务提交后, Client 向 HDFS 上传 Flink 的 Jar 包和配置,之后向 Yarn ResourceManager 提交任务, ResourceManager 分配 Container 资源并通知对应的NodeManager 启动 ApplicationMaster ApplicationMaster 启动后加载 Flink 的 Jar 包
和配置构建环境,然后启动 JobManager ,之后 ApplicationMaster 向 ResourceManager申请资源启动 TaskManager ResourceManager 分配 Container 资源后,由ApplicationMaster 通知资源所在节点的 NodeManag er 启动 TaskManagerNodeManager 加载 Flink 的 Jar 包和配置构建环境并启动 TaskManager TaskManager启动后向 JobManager 发送心跳包,并等待 JobManager 向其分配任务。
4.3 任务调度原理

- 客户端不是运行时和程序执行的一部分,但它用于准备并发送dataflow(JobGraph) 给 Master(JobManager) JobManager),然后,客户端断开连接或者维持连接以等待接收计算结果。
- 当Flink 集群启动后,首先会启动一个 JobManger 和一个或多个的TaskManager 。由 Client 提交任务给 JobManager JobManager 再调度任务到各个TaskManager 去执行,然后 TaskManager 将心跳和统计信息汇报给 JobManager 。TaskManager 之间以流的形式进行数据的 传输。上述三者均为独立的 JVM 进程。
- Client为提交 Job 的客户端,可以是运行在任何机器上(与 JobManager 环境连通即可)。提交 Job 后, Client 可以结束进程( Streaming 的任务),也可以不结束并等待结果返回。
- JobManager主要负责调度 Job 并协调 Task 做 checkpoint ,职责上很像Storm 的 Nimbus 。从 Client 处接收到 Job 和 JAR 包等资源后,会生成优化后的执行计划,并以 Task 的单元调度到各个 TaskMa nager 去执行。
- TaskManager在启动的时候就设置好了槽位数( Slot ),每个 slot 能启动一个Task Task 为线程。从 JobManager 处接收需要部署的 Task ,部署启动后,与自己的上游建立 Netty 连接,接收数据并处理。
TaskManger 与 Slots
- Flink中 每一个 worker(TaskManager) 都 是一个 JVM 进程 ,它可能会在 独立的线程 上执行一个或多个 subtask 。为了控制一个 worker 能接收多少个 task worker 通过 task slot 来进行控制(一个 worker 至少有一个 task slot )。
- 每个task slot 表示 TaskManager 拥有资源的 一个固定大小的子集 。假如一个TaskManager 有三个 slot ,那么它会将其管理的内存分成三份给各个 slot 。资源 slot化意味着一个 subtask 将不需要跟来自其他 job 的 subtask 竞争被管理的内存,取而
代之的是它将拥有一定数量的内存储备。需要注意的是,这里不会涉及到 CPU 的隔离, slot 目前仅仅用来隔离 task 的受管理的内存。 - 通过调整task slot 的数量,允许用户定 义 subtask 之间如何互相隔离。如果一个TaskManager 一个 slot ,那将意味着每个 task group 运行在独立的 JVM 中(该 JVM可能是通过一个特定的容器启动的),而一个 TaskManager 多个 slot 意味着更多的subtask 可以共享同一个 JVM 。而在同一个 JVM 进程中的 task 将共享 TCP 连接(基于多路复用)和心跳消息。它们也可能共享数据集和数据结构,因此这减少了每个task 的负载。
- 默认情况下,Flink 允许子任务共享 slot ,即使它们是不同任务的子任务 (前提是它们来自同一个 job 。 这样的结果是,一个 slot 可以保存作业的整个管道。
- Task Slot是静态的概念,是指 TaskManager 具有的并发执行能力 ,可以通过参数 taskmanager.numberOfTaskSlots 进行配置; 而 并行度 parallelism 是动态概念,即 TaskManager 运行程序时实际使用的并发能力 ,可以通过参数 parallelism.default
进行配置。 - 也就是说,假设一共有3 个 TaskManager ,每一个 TaskManager 中的分配 3 个TaskSlot ,也就是每个 TaskManager 可以接收 3 个 task ,一共 9 个 TaskSlot ,如果我们设置 parallelism.default=1 ,即运行程序默认的并行度为19个TaskSlot 只用了 1个,有 8个空闲,因此,设置合适的并行度才能提高效率。


程序与数据流( DataFlow)

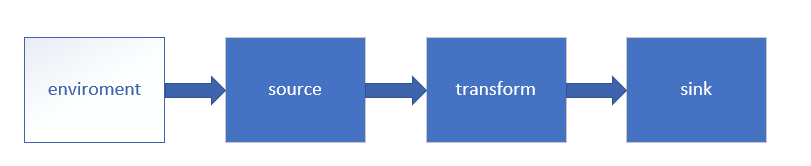
- 所有的Flink 程序都是由三部分组成的: Source 、 Trans formation 和 Sink 。
- Source负责读取数据源, Transformation 利用各种算子进行处理加工, Sink 负责输出。
- 在运行时,Flink 上运行的程序会被映射成 “逻辑数据流 dataflows )),它包含了这三部分。 每一个 dataflow 以一个或多个 sources 开始以一个或多个 sinks 结束 。 dataflow 类似于任意的有向无环图( DAG )。在大部分情况下,程序中的 转换
运算( transformations 跟 dataflow 中的 算子( operator 是一一对应的关系,但有时候,一个 tra nsformation 可能对应多个 operator 。

第五章 Flink 流处理API
5.1 Environment
getExecutionEnvironment
- 创建一个执行环境,表示当前执行程序的上下文。如果程序是独立调用的,则此方法返回本地执行环境;如果从命令行客户端调用程序以提交到集群,则此方法返回此集群的执行环境 ,也就是说 getExecutionEnvironment 会根据查询运行的方式决定返回什么样的运行环境,是最常用的一种创建执行环境的方式。

- 如果没有设置并行度,会以flink conf.yaml 中的配置为准,默认是1 。

createLocalEnvironment
返回本地执行环境,需要在调用时指定默认的并行度。
LocalStreamEnvironment env = StreamExecutionEnvironment.createLocalEnvironment(1);
createRemoteEnvironment
返回集群执行环境,将Jar 提交到远程服务器。需要在调用时指定 JobManager的 IP 和端口号,并指定要在集群中运行的 Jar 包。
StreamExecutionEnvironment env =
StreamExecutionEnvironment.createRemoteEnvironment("jobmanage-hostname", 6123,
"YOURPATH//WordCount.jar");
5.2 Source
从集合读取数据

从文件读取数据
DataStream<String> dataStream = env.readTextFile("YOUR_FILE_PATH ");
以 kafka 消息队列的数据作为来源
需要引入kafka 连接器的依赖:

具体代码如下:

自定义 Source
除了以上的source 数据来源,我们还可以自定义 source 。需要做的,只是传入一个 SourceFunction 就可以。具体调用如下:
DataStream<SensorReading> dataStream = env.addSource( new MySensor());
我们希望可以随机生成传感器数据,MySensorSource 具体的 代码 实现如下:

5.3 Transform
转换算子
map


flatMap

Filter


KeyBy

DataStream 👉 KeyedStream :逻辑地将一个流拆分成不相交的分区,每个分区包含具有相同 key 的元素,在内部以 hash 的形式实现的。
滚动聚合算子( Rolling Aggregation)
这些算子可以针对 KeyedStream 的每一个支流做聚合。
- sum()
- min()
- max()
- minBy()
- maxBy()
Reduce
KeyedStream 👉 DataStream :一个分组数据流的聚合操作,合并当前的元素和上次聚合的结果,产生一个新的值,返回的流中包含每一次聚合的结果,而不是只返回最后一次聚合的最终结果。

Split 和 Select
Split

DataStream 👉 SplitStream :根据某些特征把一个 DataStream 拆分成两个或者多个 DataStream 。
Select

SplitStream 👉 DataStream :从一个 SplitStream 中获取一个或者多个DataStream 。
需求:传感器数据按照温度高低(以 30 度为界),拆分 成两个流 。

Connect 和 CoMap

DataStream,DataStream 👉 ConnectedStreams :连接两个保持他们类型的数据流,两个数据流被 Connect 之后,只是被放在了一个同一个流中,内部依然保持各自的数据和形式不发生任何变化,两个流相互独立。
CoMap,CoFlatMap

ConnectedStreams 👉 DataStream:作用于 ConnectedStreams 上,功能与 map和 flatMap 一样,对 ConnectedSt reams 中的每一个 Stream 分别进行 map 和 flatMap处理。

Union

DataStream 👉 DataStream :对两个或者两个以上的 DataStream 进行 union 操作,产生一个包含所有 DataStream 元素的新 DataStream 。
DataStream<SensorReading> unionStream = highTempStream.union(lowTempStream);
Connect与 Union 区别:
- Union 之前两个流的类型必须是一样, Connect 可以不一样,在之后的 coMap中再去调整成为一样的。
- Connect 只能操作两个流, Union 可以操作多个 。
5.4 支持的数据类型
- Flink流应用程序处理 的是 以数据对象表示的事件流。 所以 在 Flink 内部, 我们需要能够 处理这些对象。它们需要被序列化和反序列化,以便通过网络传送它们;或者 从状态后端、检查 点和保存点读取它们。为了有效地做到这一点, Flink 需要明确知道 应用程序 所 处理的数据类型。 Flink 使用类 型信息的概念来表示数据类型,并为每个数据类型生成特定的序列化器、反序列化器 和比较器。
- Flink还具有一个类型提取系统,该系统 分析函数的输入和返回类型,以自动获取类型信息,从而获得序列化器和反序列化器。但是,在某些情况下,例如 lambda函数或泛型类型,需要显式地提供类型信息 ,才能使应用程序 正常 工作或提高其性
能。 - Flink支持 Java 和 Scala 中 所有常见数据类型。使用最广泛的类型有以下几种。
基础数据类型
- Flink支持所有的 Java 和 Scala 基础数据类型, Int, Double, Long, String, …
DataStream<Integer> numberStream = env.fromElements(1, 2, 3, 4);
numberStream.map(data -> data * 2);
- Java 和 Scala 元组(Tuples)
DataStream<Tuple2<String, Integer>> personStream = env.fromElements(
new Tuple2("Adam", 17),
new Tuple2("Sarah", 23) );
personStream.filter(p -> p.f1 > 18);
- Scala样例类(case classes)
case class Person name String age Int
val persons DataStream Person env fromElements
Person ((" 17),
Person ((" 23)
persons.filter(p => p.age > 18)
- Java简单对象( POJOs)
- 其它( Arrays, Lists, Maps , Enums, 等等)
5.5 实现 UDF 函数 更细粒度的控制流
函数类( Function Classes)
- Flink暴露了 所有 udf 函数的接口 实现方式为接口或者抽象类 。例如MapFunction, FilterFunction, ProcessFunction 等等。
- 下面例子实现了 FilterFunction 接口

还可以将函数实现成匿名类
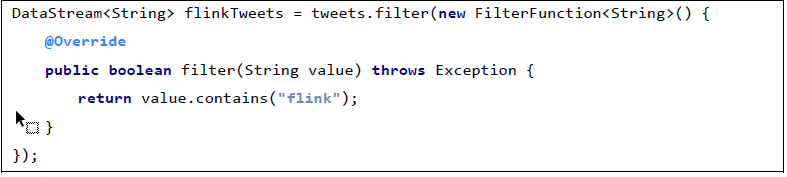
我们filter 的字符串 " 还可以当作参数传进去。

匿名函数( Lambda Functions)

富函数( Rich Functions)
“富函数”是DataStream API 提供的 一个 函数 类 的接口 所有 Flink 函数类都有其 Rich 版本。 它与常规函数的不同 在于,可以获取运行环境的上下文,并拥有一些生命周期方法,所以可以实现更复杂的功能。
- RichMapFunction
- RichFlatMapFunction
- RichFilterFunction
Rich Function有一个生命周期的概念 。 典型的生命周期方法有 - open() 方法是 rich function 的初始化方法,当一个算子例如 map 或者 filter被调用之前 open() 会被调用。
- close() 方法是生命周期中的最后一个调用的方法,做一些清理工作。
- getRuntimeContext() 方法 提供了函数的 RuntimeContext 的一些信息,例如函数执行的并行度,任务的名字,以及 state 状态

5.6 Sink
Flink没有类似于 s park 中 f oreach 方法,让用户进行迭代的操作。虽有对外的输出操作都要利用 Sink 完成。最后通过类似如下方式完成整个任务最终输出操作。
stream.addSink(new My Sink(xxxx))
官方提供了一部分的框架的sink 。除此以外,需要用户自定义实现 sink 。
Kafka
Redis
Elasticsearch
JDBC 自定义 sink
第六章 Flink中的Window
6.1 Window
Window 概述
- streaming流式计算是一种被设计用于处理无限数据集的数据处理引擎,而无限数据集是指一种不断增长的本质上无限的数据集,而 window 是一种切割无限数据为有限块进行处理 的手段。
- Window是无限数据流处理的核心, Window 将一个无限的 stream 拆分成有限大小的” buckets ”桶,我们可以在这些桶上做计算操作。
Window 类型
- Window 可以分成两类:
- CountWindow :按照指定的数据条数生成一个 Window ,与时间无关。
- TimeWindow :按照时间生成 Window 。
- 对于Time Window ,可以根据窗口实现原理的不同分成三类:滚动窗口 Tumbling Window )、滑动窗口 Sliding Window )和会话窗口 Session Window )。
- 滚动窗口(Tumbling Windows)
- 将数据依据固定的窗口长度对数据进行切片。
- 特点:时间对齐,窗口长度固定,没有重叠。
- 滚动窗口分配器将每个元素分配到一个指定窗口大小的窗口中,滚动窗口有一个固定的大小,并且不会出现重叠。例如:如果你指定了一个 5 分钟大小的滚动窗口,窗口的创建如下图所示:

- 适用场景:适合做BI 统计 等(做每个时间段的聚合计算)。
- 滑动窗口(Sliding Windows)
- 滑动窗口是固定窗口的更广义的一种形式,滑动窗口由固定的窗口长度和滑动间隔组成。
- 特点:时间对齐,窗口长度固定,可以有重叠。
- 滑动窗口分配器将元素分配到固定长度的窗口中,与滚动窗口类似,窗口的大小由窗口大小参数来配置,另一个窗口滑动参数控制滑动窗口开始的频率。因此,滑动窗口如果滑动参数小于窗口大小的话,窗口是可以重叠的,在这种情况下元素会被分配到多个窗口中。
- 例如,你有10 分钟的窗口和 5 分钟的滑动,那么每个窗口中 5 分钟的窗口里包含着上 个 10 分钟产生的数据,如下图所示:

- 适用场景:对最近一个时间段内的统计(求某接口最近5min 的失败率来决定是否要报警)。
- 会话窗口(Session Windows)
- 由一系列事件组合一个指定时间长度的timeout 间隙组成,类似于 web 应用的session ,也就是一段时间没有接收到新数据就会生成新的窗口。
- 特点:时间无对齐。
- session窗口分配器通过 session 活动来对元素进行分组, session 窗口跟滚动窗口和滑动窗口相比,不会有重叠和固定的开始时间和结束时间的情况,相反,当它在一个固定的时间周期内不再收到元素,即非活动间隔产生,那个这个窗口就会关闭。一个 session 窗口通过一个 session 间隔来配置,这个 session 间隔定义了非活跃周期的长度,当 这个非活跃周期产生,那么当前的 session 将关闭并且后续的元素将被分配到新的 session 窗口中去。

- 滚动窗口(Tumbling Windows)















 445
445











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









