







AudioLM-PyTorch:开启音频生成的新纪元
在人工智能和深度学习领域,音频生成一直是一个充满挑战的任务。然而,随着AudioLM的出现,这一领域迎来了突破性的进展。AudioLM是由谷歌研究院开发的一种基于语言模型的音频生成方法,它在音频合成方面展现出了惊人的能力。而AudioLM-PyTorch则是这一创新模型在PyTorch框架下的实现,为研究人员和开发者提供了一个强大而灵活的工具。
AudioLM的核心理念
AudioLM的核心思想是将音频生成问题转化为一个语言建模任务。这种方法的独特之处在于,它不是直接在波形或频谱图上进行操作,而是将音频编码为一系列离散的标记。这些标记可以被视为"音频语言"中的单词或字符。通过在这些标记序列上训练大规模的Transformer模型,AudioLM学会了捕捉音频中的长期依赖关系和复杂结构。
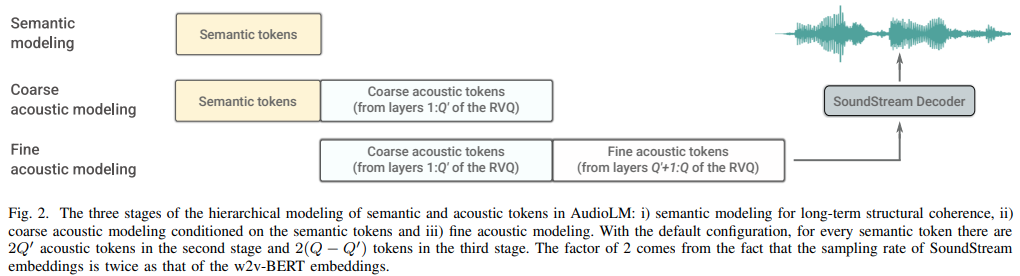
AudioLM-PyTorch的主要组件
AudioLM-PyTorch的实现包含了几个关键组件:
-
SoundStream编解码器: 这是一个神经音频编解码器,负责将原始音频波形压缩成离散的标记序列,以及将这些标记序列重建回连续的音频信号。
-
语义Transformer: 这个模型负责捕捉音频的高级语义结构,例如语音中的语言内容或音乐中的旋律和和声进展。
-
粗粒度Transformer: 它处理中等尺度的音频特征,如音色和节奏。
-
细粒度Transformer: 这个模型关注最细微的音频细节,确保生成的音频具有高保真度和自然
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









