







实时数据管道:现代数据处理的核心
在当今快速变化的数字世界中,实时数据处理已成为许多企业和应用程序的关键需求。无论是金融交易、物联网设备监控,还是用户行为分析,能够快速高效地处理和分析流式数据都变得至关重要。本文将深入探讨如何使用Python构建强大的实时数据管道,特别关注Quix Streams库在简化这一过程中的重要作用。
实时数据管道的重要性
实时数据管道允许组织即时捕获、处理和分析数据流,从而能够做出快速决策和响应。这种能力在诸如金融交易、欺诈检测、个性化推荐等场景中尤为重要。与传统的批处理系统相比,实时数据管道提供了更高的时效性和灵活性。
Python在实时数据处理中的角色
Python因其简洁的语法、丰富的库生态系统和强大的数据处理能力,已成为构建数据管道的首选语言之一。特别是在与Apache Kafka等消息中间件结合使用时,Python可以轻松处理大规模的实时数据流。
构建实时数据管道:以加密货币交易为例
为了更好地理解实时数据管道的构建过程,让我们以一个加密货币交易机器人为例。这个例子不仅具有实际意义,还能很好地展示实时数据处理的各个环节。
数据管道的基本架构
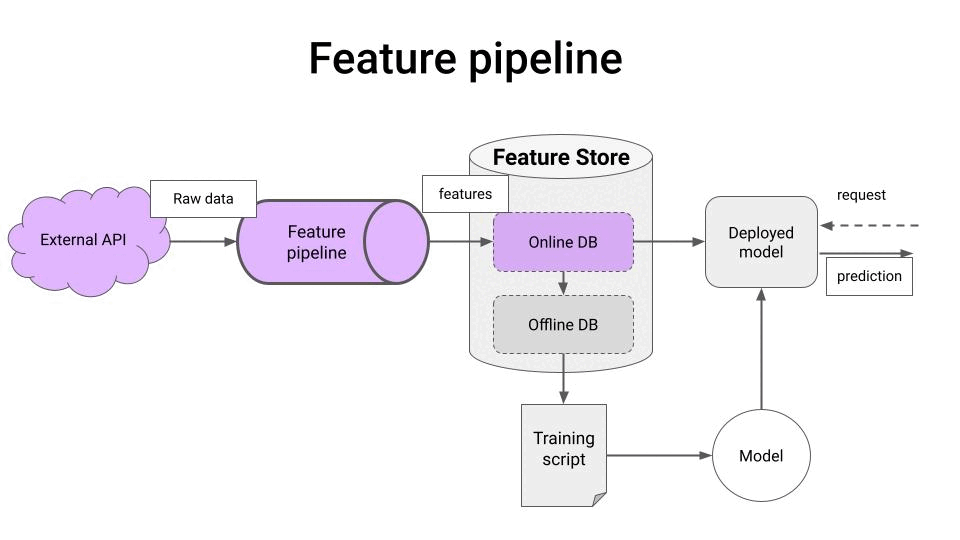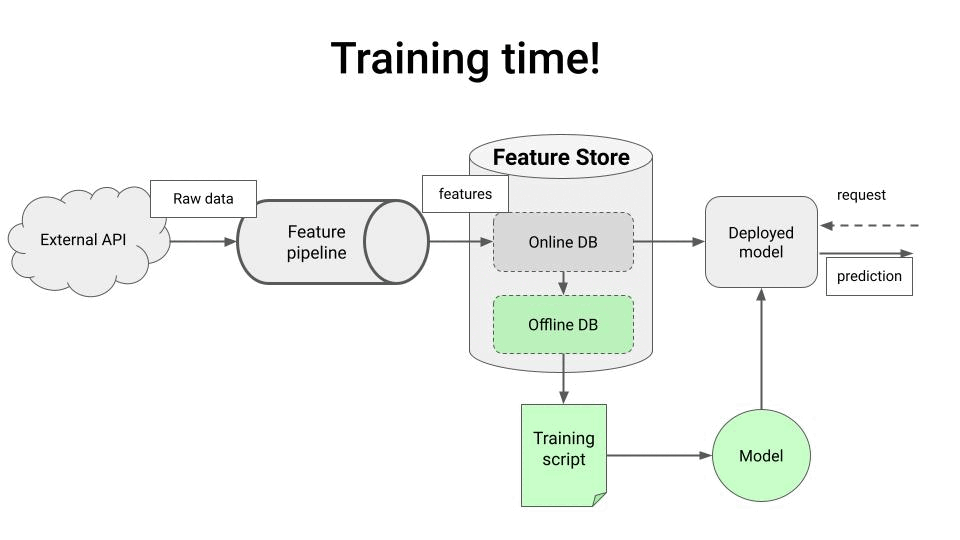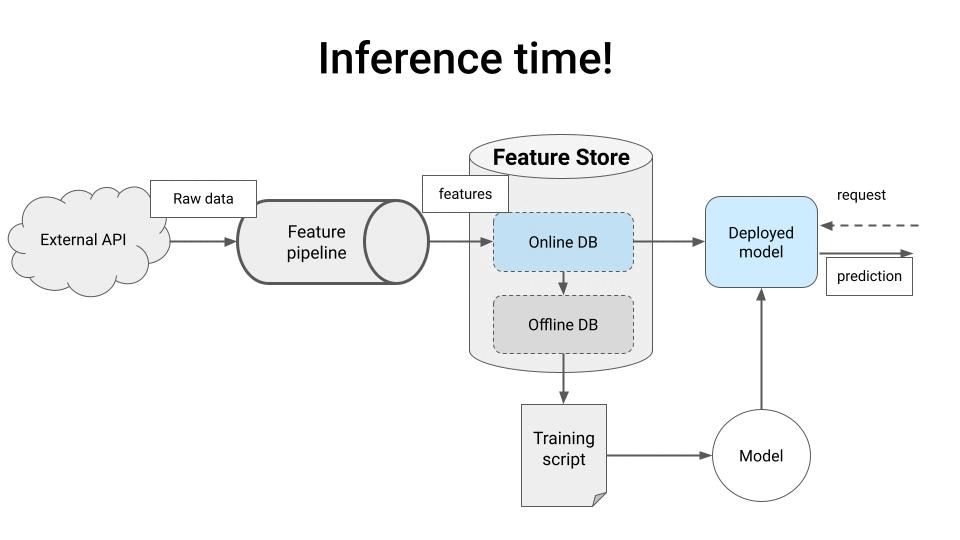
一个典型的实时数据管道通常包含以下三个主要步骤:
- 数据采集:从外部服务(如Kraken WebSocket API)实时获取原始交易数据。
- 数据转换:将原始交易数据转换为机器学习模型所需的特征,例如基于1分钟OHLC(开高低收)蜡烛图的交易指标。
- 数据存储:将处理后的特征数据保存到特征存储中,以便机器学习模型在训练和实时预测时使用。
在实际应用中,这三个步骤通常被实现为独立的服务,它们之间通过Kafka等消息中间件进行通信。这种设计使得系统具有良好的可扩展性和弹性。
使用Quix Streams简化开发
Quix Streams 是一个专为处理Kafka中的数据而设计的云原生Python库。它结合了Apache Kafka的低级可扩展性和弹性,以及Python简单易用的接口,使得数据科学家和机器学习工程师能够轻松构建生产级的实时数据管道。
使用Quix Streams,我们可以轻松实现上述三个步骤:
- trade_producer:从Kraken WebSocket API读取交易数据,并将其保存到Kafka主题中。
- trade_to_ohlc:从Kafka主题读取交易数据,使用状态窗口操作符计算OHLC蜡烛图,并将结果保存到另一个Kafka主题。
- ohlc_to_feature_store:将最终的特征数据保存到外部特征存储中。
实现细节
让我们深入了解每个步骤的实现细节:
1. 数据采集(trade_producer)
import quixstreams as qx
from kraken_wsclient_py import kraken_wsclient_py as kraken_client
def on_message(ws, message):
# 处理从Kraken WebSocket接收到的消息
# 使用Quix Streams将数据写入Kafka主题
topic_producer.produce(message)
# 初始化Quix Streams客户端和生产者
client = qx.QuixStreamingClient()
topic_producer = client.get_topic_producer("raw_trades")
# 连接到Kraken WebSocket
ws = kraken_client.WssClient()
ws.subscribe_public(pairs=["XBT/USD"], subscription={'name': 'trade'})
这段代码展示了如何使用Kraken的WebSocket客户端接收实时交易数据,并使用Quix Streams将数据写入Kafka主题。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1207
1207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









