






vits2_pytorch项目简介
vits2_pytorch是VITS2论文的非官方PyTorch实现,VITS2是一个高质量高效率的单阶段文本转语音(TTS)模型。该项目由GitHub用户p0p4k开发,旨在改进原始VITS模型,提高合成语音的自然度和计算效率。
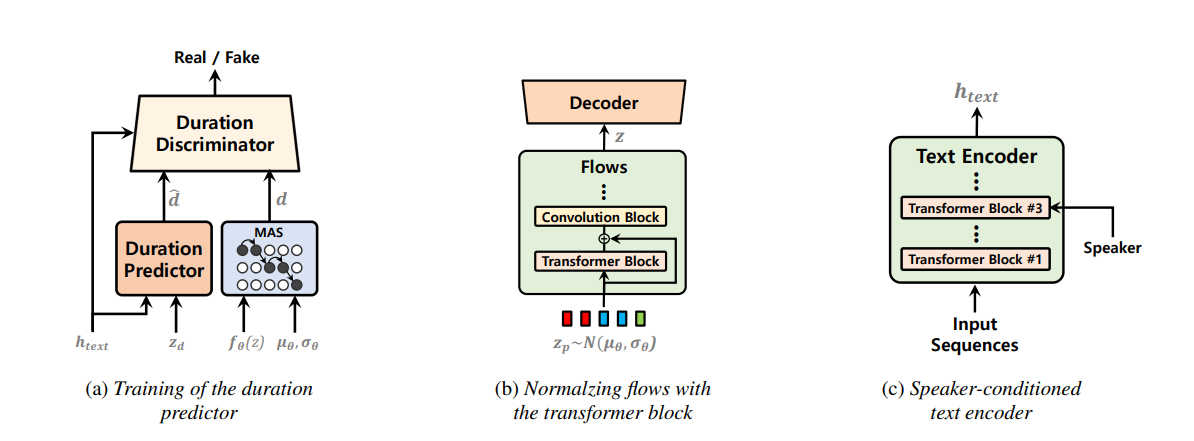
主要特性
- 改进了持续时间预测器,添加了LSTM判别器
- 在归一化流中加入了Transformer块
- 引入了说话人条件文本编码器
- 使用梅尔频谱图后验编码器
- 支持单说话人和多说话人训练
- 提供ONNX导出和Gradio演示界面
预训练模型
- LJSpeech无SDP模型 - 64k步训练,可作为迁移学习的起点
音频样本
使用教程
环境配置
- Python >= 3.10
- PyTorch 1.13.1
- 安装依赖:
pip install -r requirements.txt - 可能需要安装espeak:
apt-get install espeak
数据准备
- 下载LJSpeech数据集,链接到
DUMMY1 - 多说话人设置:下载VCTK数据集,降采样到22050Hz,链接到
DUMMY2
训练示例
# LJSpeech
python train.py -c configs/vits2_ljs_nosdp.json -m ljs_base
# VCTK
python train_ms.py -c configs/vits2_vctk_base.json -m vctk_base
ONNX导出
python export_onnx.py --model-path="G_64000.pth" --config-path="config.json" --output="vits2.onnx"
贡献者
项目得到了多位贡献者的支持,包括@erogol、@lexkoro、@athenasaurav等。
vits2_pytorch为研究人员和开发者提供了一个强大的TTS模型实现,欢迎大家使用和贡献该项目!
文章链接:www.dongaigc.com/a/vits2-pytorch-text-to-speech-resources
https://www.dongaigc.com/a/vits2-pytorch-text-to-speech-resources















 830
830

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









