







LaTeX-OCR:让数学公式图像转代码变得简单
在数学、物理等领域的学术研究和教学工作中,LaTeX作为一种强大的排版系统被广泛使用。然而,将已有的数学公式图像转换为LaTeX代码一直是一个耗时且容易出错的过程。为了解决这个问题,GitHub上的开源项目LaTeX-OCR应运而生,它利用计算机视觉和深度学习技术,实现了数学公式图像到LaTeX代码的自动转换。
项目概述
LaTeX-OCR项目由Lukas Blecher开发并维护,其核心目标是创建一个基于学习的系统,能够接收数学公式的图像输入,并输出相应的LaTeX代码。该项目在GitHub上获得了超过11,700颗星,显示出其在学术和开发社区中的广泛关注度。
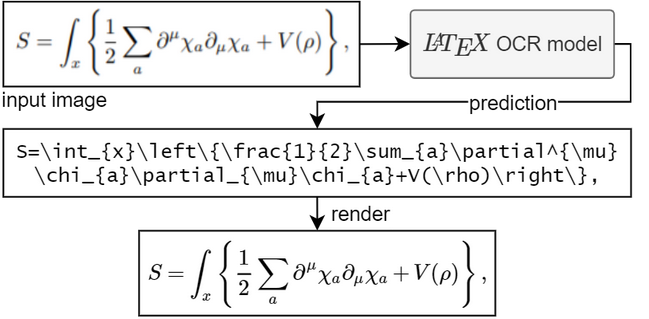
技术原理
LaTeX-OCR采用了先进的深度学习架构,主要包括:
- 编码器:使用Vision Transformer (ViT)结构,配合ResNet骨干网络,用于提取图像特征。
- 解码器:采用Transformer架构,将编码器提取的特征转换为LaTeX代码序列。
这种编码器-解码器结构能够有效地捕捉数学公式图像中的复杂结构和语义信息,从而生成准确的LaTeX代码。
使用方法
LaTeX-OCR提供了多种使用方式,以适应不同用户的需求:
-
命令行工具:通过
pix2tex命令可以直接处理本地图像或剪贴板中的图像。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1706
1706

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









