











当下云计算、大数据盛行的背景下,大并发和大吞吐量的需求已经是摆在企业面前的问题了,其中网络的性能要求尤为关键,除了软件本身需要考虑到性能方面的要求,一些硬件上面的优化也是必不可少的。
作为一名测试工作者,对于性能测试的问题肯定不会陌生,但是测试不仅仅是执行和收集数据,更多的应该是分析问题、找到性能瓶颈以及一些优化工作。
毕竟在客户现场测试性能的时候,能够通过一些系统层面的调优,提升软件的性能,那对项目无疑是一件锦上添花的事。
指标
不管你做何种性能测试,指标是绕不过去的事,指标是量化性能测试的重要依据。衡量某个性能的指标有很多,比如衡量数据库性能通常用TPS、QPS和延时,衡量io性能通常用iops、吞吐量和延时,衡量网络的性能指标也有很多,在业界有一个RFC2544的标准,参考链接:https://www.rfc-editor.org/rfc/rfc2544。
这里稍微解释一下几个指标:
-
背靠背测试:在一段时间内,以合法的最小帧间隔在传输介质上连续发送固定长度的包而不引起丢包时的数据量。
-
丢包率测试:在路由器稳定负载状态下,由于缺乏资源而不能被转发的帧占所有该被转发的帧的百分比。
-
时延测试:输入帧的最后一位到达输入端口到输出帧的第一位出现在输出端看的时间间隔。
-
吞吐量测试:没有丢包情况下能够转发的最大速率。
通常客户对于吞吐量和时延的指标是比较关心的,吞吐量反应了系统的并发的处理能力,时延反应了整体业务的响应时间。
测试准备
本文以网卡中的战斗机intel X710为测试对象,进行小包的吞吐量测试。
Tips:通常大包的测试可以达到线速,小包则很难线速,相同mtu下,包越小单位时间内cpu处理的包数越多,cpu的压力越大。
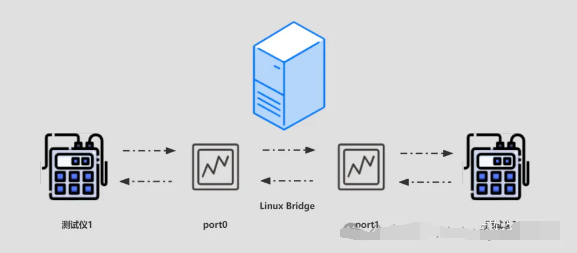
1 测试拓扑
在被测设备上插入X710网卡,使用网卡的2个网口建立linux bridge,通过测试仪发送接收数据包:
[root@localhost ~]
# brctl addbr test
[root@localhost ~]
# brctl addif test enp11s0f2 enp11s0f3
[root@localhost ~]
# ip link set test up
[root@localhost ~]
# brctl show
bridge name bridge id STP enabled interfaces
test
8000.6
cb311618c3
0
no
enp11s0f2
enp11s0f3
virbr
0
8000.5254004
c4831 yes virbr
0
-nic2 硬件信息
有个伟人曾说过,“如果性能测试不谈硬件,那么就和恋爱不谈结婚一个道理,都是耍流氓”。
鲁迅:"我没说过!"
题外话,这里先简单说一下数据包进入网卡后的流程:数据包进入到网卡后,将数据缓存到服务器内存后通知内核进行处理,接着协议栈进行处理,通常netfilter也是在协议栈去处理,最后应用程序从socker buff读取数据。
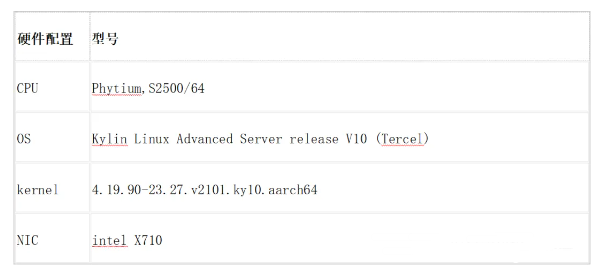
言归真正,本文测试采用的是国产之光飞腾S2500服务器。
测试调优
针对以上拓扑,发送128字节万兆双向流量,用RFC2544标准进行测试。

RFC2544的标准是0丢包测试吞吐量,结果是818Mbps。
以上都是前菜,接下来是本文的重头戏,根据已有资源做一些优化,提升“测试”性能,让客户满意。
1 调整队列数
调整网卡的队列数,利用网卡的多队列特性,不同的队列通过中断绑定到不同的cpu,提升cpu处理性能,提升网络带宽。
调整队列数,这里也不是越大越好,因为服务器的cpu个数是有上限的,队列多的话会出现多个中断绑定在同一个cpu上,这里我服务器单个numa有8个cpu,修改队列数为8:
[root@localhost
~]# ethtool -l enp11s0f2
Channel
parameters for enp11s0f2:
Pre-set
maximums:
RX:
0
TX:
0
Other:
1
Combined:
128
Current
hardware settings:
RX:
0
TX:
0
Other:
1
Combined:
8因为数据包会根据hash来进入到多个收包队列,因此发送数据包的时候,可以选择源ip变化的流来确保使用了网卡的多队列,可以查看网卡的队列计数。
[root@localhost ~]#
ethtool
-S
enp11s0f3
NIC
statistics
:
rx_packets
: 4111490
tx_packets
: 4111490
rx_bytes
: 509824504
tx_bytes
: 509824504
rx_errors
: 0
tx_errors
: 0
rx_dropped
: 0
tx_dropped
: 0
collisions
: 0
rx_length_errors
: 0
rx_crc_errors
: 0
rx_unicast
: 4111486
tx_unicast
: 4111486
...
rx-2
.rx_bytes: 63718020
tx-3
.tx_packets: 513838
tx-3
.tx_bytes: 63715912
rx-3
.rx_packets: 514847
rx-3
.rx_bytes: 63841028
tx-4
.tx_packets: 1027488
tx-4
.tx_bytes: 127408512
rx-4
.rx_packets: 513648
rx-4
.rx_bytes: 63692352
tx-5
.tx_packets: 52670
tx-5
.tx_bytes: 6530824
rx-5
.rx_packets: 514388
rx-5
.rx_bytes: 63784112
tx-6
.tx_packets: 1029202
tx-6
.tx_bytes: 127621048
rx-6
.rx_packets: 514742
rx-6
.rx_bytes: 63828008
tx-7
.tx_packets: 460901
tx-7
.tx_bytes: 57151724
rx-7
.rx_packets: 512859修改完队列后再次使用RFC2544进行测试,性能比单队列提升了57%。

2 调整队列深度
除了调整网卡的队列数外,也可以修改网卡的队列深度,但是队列深度不是越大越好,具体还是需要看实际的应用场景。对于延时要求高的场景并不适合修改太大的队列深度。
查看当前队列深度为512,修改为1024再次测试:
[root@localhost
~]# ethtool -g enp11s0f2
Ring
parameters for enp11s0f2:
Pre-set
maximums:
RX:
4096
RX
Mini: 0
RX
Jumbo: 0
TX:
4096
Current
hardware settings:
RX:
512
RX
Mini: 0
RX
Jumbo: 0
TX:
512修改tx和rx队列深度为1024:
[root@localhost
~]# ethtool -G enp11s0f3 tx 1024
[root@localhost
~]# ethtool -G enp11s0f3 rx 1024
[root@localhost
~]# ethtool -g enp11s0f2
Ring
parameters for enp11s0f2:
Pre-set
maximums:
RX:
4096
RX
Mini: 0
RX
Jumbo: 0
TX:
4096
Current
hardware settings:
RX:
1024
RX
Mini: 0
RX
Jumbo: 0
TX:
1024再次进行RFC2544测试,这次也是有相应的提升。

3 中断绑定
网卡收包后,内核会触发软中断程序,如果此时运行中断的cpu和网卡不在一个numa上,则性能会降低。
查看网卡pci插槽对应numa node:
[root@localhost
~]# cat /sys/bus/pci/devices/0000\:0b\:00.3/numa_node
0
这里对应的numa
node为0
飞腾S2500有16个numa
node,node8-15和node0所在的物理cpu不同,如果中断跑在上面性能会更加低
[root@localhost
~]# numactl -H
available:
16 nodes (0-15)
node
0 cpus: 0 1 2 3 4 5 6 7
node
0 size: 65009 MB
node
0 free: 46721 MB
node
1 cpus: 8 9 10 11 12 13 14 15
node
1 size: 0 MB
node
1 free: 0 MB
node
2 cpus: 16 17 18 19 20 21 22 23
node
2 size: 0 MB
node
2 free: 0 MB
node
3 cpus: 24 25 26 27 28 29 30 31
node
3 size: 0 MB
node
3 free: 0 MB
node
4 cpus: 32 33 34 35 36 37 38 39
node
4 size: 0 MB
node
4 free: 0 MB
node
5 cpus: 40 41 42 43 44 45 46 47
node
5 size: 0 MB
node
5 free: 0 MB
node
6 cpus: 48 49 50 51 52 53 54 55
node
6 size: 65466 MB
node
6 free: 64663 MB
node
7 cpus: 56 57 58 59 60 61 62 63
node
7 size: 0 MB
node
7 free: 0 MB
node
8 cpus: 64 65 66 67 68 69 70 71
node
8 size: 65402 MB
node
8 free: 63691 MB
node
9 cpus: 72 73 74 75 76 77 78 79
node
9 size: 0 MB
node
9 free: 0 MB
node
10 cpus: 80 81 82 83 84 85 86 87
node
10 size: 0 MB
node
10 free: 0 MB
node
11 cpus: 88 89 90 91 92 93 94 95
node
11 size: 0 MB
node
11 free: 0 MB
node
12 cpus: 96 97 98 99 100 101 102 103
node
12 size: 0 MB
node
12 free: 0 MB
node
13 cpus: 104 105 106 107 108 109 110 111
node
13 size: 0 MB
node
13 free: 0 MB
node
14 cpus: 112 113 114 115 116 117 118 119
node
14 size: 64358 MB
node
14 free: 63455 MB
node
15 cpus: 120 121 122 123 124 125 126 127
node
15 size: 0 MB
node
15 free: 0 MB
node
distances:
node
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
0:
10 20 40 30 20 30 50 40 100 100 100 100 100 100 100 100
1:
20 10 30 40 50 20 40 50 100 100 100 100 100 100 100 100
2:
40 30 10 20 40 50 20 30 100 100 100 100 100 100 100 100
3:
30 40 20 10 30 20 40 50 100 100 100 100 100 100 100 100
4:
20 50 40 30 10 50 30 20 100 100 100 100 100 100 100 100
5:
30 20 50 20 50 10 50 40 100 100 100 100 100 100 100 100
6:
50 40 20 40 30 50 10 30 100 100 100 100 100 100 100 100
7:
40 50 30 50 20 40 30 10 100 100 100 100 100 100 100 100
8:
100 100 100 100 100 100 100 100 10 20 40 30 20 30 50 40
9:
100 100 100 100 100 100 100 100 20 10 30 40 50 20 40 50
10:
100 100 100 100 100 100 100 100 40 30 10 20 40 50 20 30
11:
100 100 100 100 100 100 100 100 30 40 20 10 30 20 40 50
12:
100 100 100 100 100 100 100 100 20 50 40 30 10 50 30 20
13:
100 100 100 100 100 100 100 100 30 20 50 20 50 10 50 40
14:
100 100 100 100 100 100 100 100 50 40 20 40 30 50 10 30
15
:
100 100 100 100 100 100 100 100 40 50 30 50 20 40 30 10查看网卡对应的中断绑定。
tips:系统会有一个中断平衡服务,系统会根据环境负载情况自行分配cpu到各个中断,所以这里为了强行把中断平均的绑定到各个cpu,需要先停止该服务:
[root@localhost ~]
# cat /proc/interrupts | grep enp11s0f3 | cut -d: -f1 | while read i; do echo -ne irq":$i\t bind_cpu: "; cat /proc/irq/$i/smp_affinity_list; done | sort -n -t' ' -k3
irq:
654
bind_cpu:
0
irq:
653
bind_cpu:
1
irq:
656
bind_cpu:
2
irq:
657
bind_cpu:
2
irq:
659
bind_cpu:
3
irq:
655
bind_cpu:
4
irq:
652
bind_cpu:
5
irq:
658
bind_cpu:
6
[root@localhost ~]
# systemctl stop irqbalance.service
手动修改网卡对应的cpu亲和性
echo
0
>
/proc/irq
/654/smp
_affinity_list
echo
1
>
/proc/irq
/653/smp
_affinity_list
echo
2
>
/proc/irq
/656/smp
_affinity_list
echo
3
>
/proc/irq
/657/smp
_affinity_list
echo
4
>
/proc/irq
/659/smp
_affinity_list
echo
5
>
/proc/irq
/655/smp
_affinity_list
echo
6
>
/proc/irq
/652/smp
_affinity_list
echo
7
>
/proc/irq
/658/smp
_affinity_list调整后继续测试RFC2544,又有了一定的性能提升。

通过以上三种优化方式后,性能提升了95%,很显然,如果发生在客户现场,那绝对是值得高兴的一件事。

4 其他优化项
除了以上几种方式外,还有一些日常的调优手段,大家可以试一下针对不同的场景,选择不同的方式。
1、打开tso和gso
利用网卡硬件进行分片或者推迟协议栈分片,以此来降低cpu负载,提升整体性能。
2、调整TLP
调整pcie总线每次数据传输的最大值,根据实际情况调整,bios中可以修改。
3、调整聚合中断
合并中断,减少中断处理次数,根据实际情况调整。
4、应用程序cpu绑定
如果测试是使用类似netperf,qperf的工具,可以使用taskset命令绑定该测试进程到指定cpu。
总结
随着性能测试的发展以及对测试工程师的要求提高,优化性能已经不再是单纯开发同学所要做的事情,使用合适的测试方法和测试工具进行测试,收集数据找到性能瓶颈,并能进行一系列的调优,这才是性能测试团队做的真正有意义以及有价值的事情。
行动吧,在路上总比一直观望的要好,未来的你肯定会感谢现在拼搏的自己!如果想学习提升找不到资料,没人答疑解惑时,请及时加入群: 759968159,里面有各种测试开发资料和技术可以一起交流哦。
最后: 下方这份完整的软件测试视频教程已经整理上传完成,需要的朋友们可以自行领取【保证100%免费】
软件测试面试文档
我们学习必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有字节大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

















 7053
7053











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









