







文章目录
逻辑回归与正则化
2.1 逻辑回归
2.1.1 分类问题
在本专栏第一篇文章里介绍的线性回归,是一种解决回归问题的有力算法。在本篇文章中,要介绍一种叫做逻辑回归的算法来解决同为监督学习的分类问题。不同于回归,分类问题所需要预测的 y y y 值往往是离散型数据。
分类问题在实际生活中也很常见:比如判断一封电子邮件是非垃圾邮件(0)还是垃圾邮件(1),肿瘤是良性的(0)还是恶性的(1)……
我们将从最简单的二元分类开始讨论,我们将
y
y
y 可能属于的两个类分别称为负类与正类,因此有
y
∈
{
0
,
1
}
y \in \{0,1\}
y∈{0,1},其中0表示负类,1表示正类。
以吴恩达老师视频中所举的肿瘤为例,来探讨一下线性回归对于分类问题的可行性。

假设我们利用线性回归作出了假设函数
h
θ
(
x
)
h_\theta(x)
hθ(x)(如图粉色直线),并有规定阈值为0.5:凡假设出的
y
≥
0.5
y\ge 0.5
y≥0.5,则肿瘤为恶性;
y
<
0.5
y < 0.5
y<0.5,则肿瘤为良性。这对于初始的8个数据点(图中左侧的八个样本)看似是一个比较好的分类器,但一旦加入了一个比较“夸张”的样本(图中最右侧的样本),则再次利用线性回归算法得到的假设函数会变化(如图蓝色直线)这样可能使得某些恶性的样本会被线性回归判定为“良性”(左数第5、6个样本均在阈值左侧)。与此同时,我们发现当对某些尺寸的肿瘤进行分类时,利用线性回归算法所得到的
y
y
y 可能远大于1或远小于0,输出值与离散值相差甚远。综上,我们可以得出线性回归算法不适用于分类问题的结论。
究其原因,线性回归算法无法将预测值控制在离散值范围内,因此我们需要一种算法,可以保证我们的预测值在分类所需要的离散值范围内(在二元分类即保证在0到1之间)我们从而要学习逻辑回归算法,这里需要说明逻辑回归所得到的假设函数满足 0 ≤ h θ ( x ) ≤ 1 0\le h_\theta(x)\le 1 0≤hθ(x)≤1.
2.1.2 假说表示与决策边界
逻辑回归要求输出变量范围在0到1之间,因此逻辑回归的模型假设是
h
θ
(
x
)
=
g
(
θ
T
x
)
h_\theta(x)=g(\theta^T x)
hθ(x)=g(θTx),其中
x
x
x 代表特征向量,
g
g
g 代表逻辑函数。
逻辑函数是一个形如S的函数,公式为:
g
(
z
)
=
1
1
+
e
−
z
g(z)=\frac{1}{1+e^{-z}}
g(z)=1+e−z1
函数图像大致为:

我们可以发现逻辑函数正是我们想要的假设,全部控制在0到1之间。因此假设函数可表示为:
h
θ
(
x
)
=
1
1
+
e
−
θ
T
x
h_\theta(x)=\frac{1}{1+e^{-\theta^Tx}}
hθ(x)=1+e−θTx1
h
θ
(
x
)
h_\theta(x)
hθ(x) 在分类问题中的意义为根据输入特征向量
x
x
x 预测
y
=
1
y=1
y=1 的可能性,即
h
θ
(
x
)
=
P
(
y
=
1
∣
x
;
θ
)
h_\theta(x)=P(y=1|x;\ \theta)
hθ(x)=P(y=1∣x; θ) . 由于
P
(
y
=
0
∣
x
;
θ
)
+
P
(
y
=
1
∣
x
;
θ
)
=
1
P(y=0|x;\ \theta)+P(y=1|x;\ \theta)=1
P(y=0∣x; θ)+P(y=1∣x; θ)=1,因此可以轻松计算出在特征向量为
x
x
x 时
y
=
0
y=0
y=0的可能性为
P
(
y
=
0
∣
x
;
θ
)
=
1
−
P
(
y
=
1
∣
x
;
θ
)
=
1
−
h
θ
(
x
)
P(y=0|x;\ \theta)=1-P(y=1|x;\ \theta)=1-h_\theta(x)
P(y=0∣x; θ)=1−P(y=1∣x; θ)=1−hθ(x).
接下来我们将从可视化角度来探讨假设函数的作用,即几何意义。由逻辑函数的图像可知,当 z = 0 z=0 z=0 时, g ( z ) = 0.5 g(z)=0.5 g(z)=0.5; z > 0 z>0 z>0时, g ( z ) > 0.5 g(z)>0.5 g(z)>0.5; z < 0 z<0 z<0时, g ( z ) < 0.5 g(z)<0.5 g(z)<0.5.又因为 z = θ T x z=\theta^Tx z=θTx,有 θ T x ≥ 0 \theta^Tx\ge0 θTx≥0 时,预测 y = 1 y=1 y=1; θ T x < 0 \theta^Tx<0 θTx<0 时,预测 y = 0 y=0 y=0.
假设我们已有一个模型: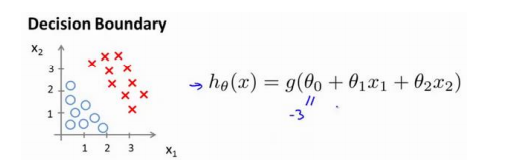
且已经通过某些方法得到向量:
θ
=
[
−
3
1
1
]
\theta= \begin{bmatrix} -3\quad 1 \quad 1 \end{bmatrix}
θ=[−311],因此
−
3
+
x
1
+
x
2
≥
0
-3+x_1+x_2\ge0
−3+x1+x2≥0,即
x
1
+
x
2
≥
3
x_1+x_2\ge 3
x1+x2≥3 时,预测值
y
=
1
y=1
y=1. 我们可在图像中加入直线
x
1
+
x
2
=
3
x_1+x_2= 3
x1+x2=3 ,便是决策边界,将
y
=
1
y=1
y=1 与
y
=
0
y=0
y=0 的区域分开。

同理,当遇到比较复杂的模型时,可引入平方项特征,如图所示。

假设函数可设为
h
θ
(
x
)
=
g
(
θ
0
+
θ
1
x
1
+
θ
2
x
2
+
θ
3
x
1
2
+
θ
4
x
2
2
)
h_\theta(x)=g(\theta_0+\theta_1x_1+\theta_2x_2+\theta_3x_1^2+\theta_4x_2^2)
hθ(x)=g(θ0+θ1x1+θ2x2+θ3x12+θ4x22),通过某些方法得到向量
θ
=
[
−
1
0
0
1
1
]
\theta= \begin{bmatrix} -1\quad 0 \quad 0\quad 1\quad 1 \end{bmatrix}
θ=[−10011] ,因此可以得到决策边界为
x
1
2
+
x
2
2
=
1
x_1^2+x_2^2=1
x12+x22=1的圆形。我们可以用复杂的多项式得到形状复杂的决策边界。
2.1.3 代价函数及其简化形式
在逻辑回归中,我们同样有代价函数来评价当前参数向量
θ
\theta
θ 是否合理,来衡量当前分类器的准确性。逻辑回归的代价函数可写成如下形式:
J
(
θ
)
=
1
m
∑
i
=
1
m
C
o
s
t
(
h
θ
(
x
(
i
)
)
,
y
(
i
)
)
C
o
s
t
(
h
θ
(
x
)
,
y
)
=
{
−
l
n
(
h
θ
(
x
)
)
if
y
=
1
−
l
n
(
1
−
h
θ
(
x
)
)
if
y
=
0
N
o
t
e
:
y
=
0
o
r
1
a
l
w
a
y
s
.
J(\theta)=\frac{1}{m}\sum_{i=1}^mCost(h_\theta(x^{(i)}),\ y^{(i)})\\ Cost(h_\theta(x),\ y)= \begin{cases} -ln(h_\theta(x)) &\text{if } y=1 \\ -ln(1-h_\theta(x)) &\text{if } y=0 \end{cases}\\ Note:y=0\ or\ 1\ always.
J(θ)=m1i=1∑mCost(hθ(x(i)), y(i))Cost(hθ(x), y)={−ln(hθ(x))−ln(1−hθ(x))if y=1if y=0Note:y=0 or 1 always.
我们很容易发现,在Cost函数中当
y
=
1
y=1
y=1 时
h
θ
(
x
)
h_\theta(x)
hθ(x) 越趋向1的过程中,
C
o
s
t
Cost
Cost 在趋向于0,而
h
θ
(
x
)
h_\theta(x)
hθ(x) 越趋向0的过程中,
C
o
s
t
Cost
Cost 在趋向于无穷大,当
y
=
0
y=0
y=0 时同理。之所以抛弃线性回归中的代价函数是因为原来的代价函数是一个非凸函数(因为sigmoid函数的非线性),有多个局部最小值,因此不利于梯度下降法的展开。逻辑回归的代价函数可以证明是一个凸函数,没有局部最优值,适宜使用梯度下降法。但是目前的
C
o
s
t
Cost
Cost 还是一个分段函数,不够直接,我们可以写出其简化形式:
C
o
s
t
(
h
θ
(
x
)
,
y
)
=
−
y
⋅
l
n
(
h
θ
(
x
)
)
−
(
1
−
y
)
⋅
l
n
(
1
−
h
θ
(
x
)
)
Cost(h_\theta(x),\ y)=-y\cdot ln(h_\theta(x))-(1-y)\cdot ln(1-h_\theta(x))
Cost(hθ(x), y)=−y⋅ln(hθ(x))−(1−y)⋅ln(1−hθ(x))
因此简化的代价函数为:
J
(
θ
)
=
−
1
m
∑
i
=
1
m
[
y
(
i
)
⋅
l
n
(
h
θ
(
x
(
i
)
)
)
+
(
1
−
y
(
i
)
)
⋅
l
n
(
1
−
h
θ
(
x
(
i
)
)
)
]
J(\theta)=-\frac{1}{m}\sum_{i=1}^m[y^{(i)}\cdot ln(h_\theta(x^{(i)}))+(1-y^{(i)})\cdot ln(1-h_\theta(x^{(i)}))]
J(θ)=−m1i=1∑m[y(i)⋅ln(hθ(x(i)))+(1−y(i))⋅ln(1−hθ(x(i)))]
2.1.4 梯度下降以及高级优化
我们想要拟合出参数
θ
\theta
θ ,就需要使得代价函数
J
(
θ
)
J(\theta)
J(θ) 最小,这里我们用到的算法是梯度下降法。同样地,特征缩放依然重要。逻辑回归的梯度下降算法为:
R
e
p
e
a
t
θ
j
=
θ
j
−
α
1
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
x
j
(
i
)
s
i
m
u
l
t
a
n
e
o
u
s
l
y
u
p
d
a
t
e
a
l
l
θ
j
Repeat\\ \theta_j=\theta_j-\alpha\frac{1}{m}\sum_{i=1}^m(h_\theta(x^{(i)})-y^{(i)})x_j^{(i)}\\ simultaneously\ update\ all\ \theta_j
Repeatθj=θj−αm1i=1∑m(hθ(x(i))−y(i))xj(i)simultaneously update all θj
原理为
θ
j
=
θ
j
−
α
∂
∂
θ
j
J
(
θ
)
.
\theta_j=\theta_j-\alpha\frac{\partial}{\partial \theta_j}J(\theta).
θj=θj−α∂θj∂J(θ).关键是求出
∂
∂
θ
j
J
(
θ
)
\frac{\partial}{\partial \theta_j}J(\theta)
∂θj∂J(θ),推导过程如下:
∂
∂
θ
j
J
(
θ
)
=
∂
∂
θ
j
[
−
1
m
∑
i
=
1
m
[
y
(
i
)
⋅
l
n
(
h
θ
(
x
(
i
)
)
)
+
(
1
−
y
(
i
)
)
⋅
l
n
(
1
−
h
θ
(
x
(
i
)
)
)
]
=
∂
∂
θ
j
[
−
1
m
∑
i
=
1
m
[
y
(
i
)
⋅
l
n
(
1
1
+
e
−
θ
T
x
(
i
)
)
+
(
1
−
y
(
i
)
)
⋅
l
n
(
1
−
1
1
+
e
−
θ
T
x
(
i
)
)
]
=
∂
∂
θ
j
[
−
1
m
∑
i
=
1
m
[
−
y
(
i
)
⋅
l
n
(
1
+
e
−
θ
T
x
(
i
)
)
−
(
1
−
y
(
i
)
)
⋅
l
n
(
1
+
e
θ
T
x
(
i
)
)
]
=
−
1
m
∑
i
=
1
m
[
−
y
(
i
)
−
x
j
(
i
)
e
−
θ
T
x
(
i
)
1
+
e
−
θ
T
x
(
i
)
−
(
1
−
y
(
i
)
)
x
j
(
i
)
e
θ
T
x
(
i
)
1
+
e
θ
T
x
(
i
)
]
=
−
1
m
∑
i
=
1
m
[
y
(
i
)
x
j
(
i
)
e
−
θ
T
x
(
i
)
1
+
e
−
θ
T
x
(
i
)
−
(
1
−
y
(
i
)
)
x
j
(
i
)
e
θ
T
x
(
i
)
1
+
e
θ
T
x
(
i
)
]
=
−
1
m
∑
i
=
1
m
y
(
i
)
x
j
(
i
)
−
x
j
(
i
)
e
θ
T
x
(
i
)
+
y
(
i
)
x
j
(
i
)
e
θ
T
x
(
i
)
1
+
e
θ
T
x
(
i
)
=
−
1
m
∑
i
=
1
m
y
(
i
)
(
1
+
e
θ
T
x
(
i
)
)
−
e
θ
T
x
(
i
)
1
+
e
θ
T
x
(
i
)
x
j
(
i
)
=
−
1
m
∑
i
=
1
m
(
y
(
i
)
−
e
θ
T
x
(
i
)
1
+
e
θ
T
x
(
i
)
)
x
j
(
i
)
=
−
1
m
∑
i
=
1
m
(
y
(
i
)
−
1
1
+
e
−
θ
T
x
(
i
)
)
x
j
(
i
)
=
−
1
m
∑
i
=
1
m
[
y
(
i
)
−
h
θ
(
x
(
i
)
)
]
x
j
(
i
)
=
1
m
∑
i
=
1
m
[
h
θ
(
x
(
i
)
)
−
y
(
i
)
]
x
j
(
i
)
\begin{aligned} \frac{\partial}{\partial \theta_j}J(\theta)&=\frac{\partial}{\partial \theta_j}[-\frac{1}{m}\sum_{i=1}^m[y^{(i)}\cdot ln(h_\theta(x^{(i)}))+(1-y^{(i)})\cdot ln(1-h\theta(x^{(i)}))]\\ &=\frac{\partial}{\partial \theta_j}[-\frac{1}{m}\sum_{i=1}^m[y^{(i)}\cdot ln(\frac{1}{1+e^{-\theta^Tx^{(i)}}})+(1-y^{(i)})\cdot ln(1-\frac{1}{1+e^{-\theta^Tx^{(i)}}})]\\ &=\frac{\partial}{\partial \theta_j}[-\frac{1}{m}\sum_{i=1}^m[-y^{(i)}\cdot ln(1+e^{-\theta^Tx^{(i)}})-(1-y^{(i)})\cdot ln(1+e^{\theta^Tx^{(i)}})]\\ &=-\frac{1}{m}\sum_{i=1}^m[-y^{(i)}\frac{-x_j^{(i)}e^{-\theta^Tx^{(i)}}}{1+e^{-\theta^Tx^{(i)}}}-(1-y^{(i)})\frac{x_j^{(i)}e^{\theta^Tx^{(i)}}}{1+e^{\theta^Tx^{(i)}}}]\\ &=-\frac{1}{m}\sum_{i=1}^m[y^{(i)}\frac{x_j^{(i)}e^{-\theta^Tx^{(i)}}}{1+e^{-\theta^Tx^{(i)}}}-(1-y^{(i)})\frac{x_j^{(i)}e^{\theta^Tx^{(i)}}}{1+e^{\theta^Tx^{(i)}}}]\\ &=-\frac{1}{m}\sum_{i=1}^m\frac{y^{(i)}x_j^{(i)}-x_j^{(i)}e^{\theta^Tx^{(i)}}+y^{(i)}x_j^{(i)}e^{\theta^Tx^{(i)}}}{1+e^{\theta^Tx^{(i)}}}\\ &=-\frac{1}{m}\sum_{i=1}^m\frac{y^{(i)}(1+e^{\theta^Tx^{(i)}})-e^{\theta^Tx^{(i)}}}{1+e^{\theta^Tx^{(i)}}}x_j^{(i)}\\ &=-\frac{1}{m}\sum_{i=1}^m(y^{(i)}-\frac{e^{\theta^Tx^{(i)}}}{1+e^{\theta^Tx^{(i)}}})x_j^{(i)}\\ &=-\frac{1}{m}\sum_{i=1}^m(y^{(i)}-\frac{1}{1+e^{-\theta^Tx^{(i)}}})x_j^{(i)}\\ &=-\frac{1}{m}\sum_{i=1}^m[y^{(i)}-h_\theta(x^{(i)})]x_j^{(i)}\\ &=\frac{1}{m}\sum_{i=1}^m[h_\theta(x^{(i)})-y^{(i)}]x_j^{(i)}\\ \end{aligned}
∂θj∂J(θ)=∂θj∂[−m1i=1∑m[y(i)⋅ln(hθ(x(i)))+(1−y(i))⋅ln(1−hθ(x(i)))]=∂θj∂[−m1i=1∑m[y(i)⋅ln(1+e−θTx(i)1)+(1−y(i))⋅ln(1−1+e−θTx(i)1)]=∂θj∂[−m1i=1∑m[−y(i)⋅ln(1+e−θTx(i))−(1−y(i))⋅ln(1+eθTx(i))]=−m1i=1∑m[−y(i)1+e−θTx(i)−xj(i)e−θTx(i)−(1−y(i))1+eθTx(i)xj(i)eθTx(i)]=−m1i=1∑m[y(i)1+e−θTx(i)xj(i)e−θTx(i)−(1−y(i))1+eθTx(i)xj(i)eθTx(i)]=−m1i=1∑m1+eθTx(i)y(i)xj(i)−xj(i)eθTx(i)+y(i)xj(i)eθTx(i)=−m1i=1∑m1+eθTx(i)y(i)(1+eθTx(i))−eθTx(i)xj(i)=−m1i=1∑m(y(i)−1+eθTx(i)eθTx(i))xj(i)=−m1i=1∑m(y(i)−1+e−θTx(i)1)xj(i)=−m1i=1∑m[y(i)−hθ(x(i))]xj(i)=m1i=1∑m[hθ(x(i))−y(i)]xj(i)
如果你对上一篇文章印象深刻的话,可以发现逻辑回归的梯度下降的形式居然与线性回归中的一模一样,但由于假设函数
h
θ
(
x
)
h_\theta(x)
hθ(x) 的不同,这两个算法实际上是两个不同的算法,只是
∂
∂
θ
j
J
(
θ
)
\frac{\partial}{\partial \theta_j}J(\theta)
∂θj∂J(θ) 计算结果一致产生的结果。
在算法实现的过程中可以像第一篇文章中一样利用两次 for 循环,一次用来记录 iter 迭代次数,一次用来记录不同的参数 θ j \theta_j θj把结果保存在temp中,退出循环后再一次性赋值给新的 θ \theta θ。当然也可以利用向量化的方法一次性将向量 θ \theta θ 更新。
然而梯度下降算法并不是唯一算法,还有一些更复杂更高级的算法帮助我们拟合参数 θ \theta θ,比如BFGS 共轭梯度法(变尺度法)、L-BFGS 限制变尺度法等。这些高级算法的优点有无需手动选择学习率 α \alpha α,它可以利用内部的线性搜索算法自动尝试不同的 α \alpha α ,并自动选择一个合适的 α \alpha α;并且这些高级算法的收敛速度往往快于梯度下降法。我们可以合理的利用库去找到 θ \theta θ,从而代替梯度下降法,比如MATLAB的fminunc函数,Python的spicy库中的scipy.optimize.minimize函数等等。
2.1.5 多类别分类:一对多
上文中的分析都是基于二元分类,而现实中往往都是多元分类。比如生活中的邮件:工作、朋友、家人,可以分别用
y
=
1
y=1
y=1,
y
=
2
y=2
y=2,
y
=
3
y=3
y=3 表示。
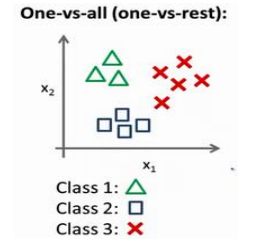
我们的处理方法是将其分成3个二元分类问题。实际上我们可以创建一个“伪训练集”:类型1设为正类,类型2和类型3设为负类。同理,依次将类型2、类型3单独设为正类,也就得到3个二元分类问题。我们可以将每个模型简记为
h
θ
(
i
)
(
x
)
=
P
(
y
=
i
∣
x
;
θ
)
.
h_\theta^{(i)}(x)=P(y=i|x; \theta).
hθ(i)(x)=P(y=i∣x;θ). 在分类时,我们输入
x
x
x 到3个模型中,最终我们选择使得
h
θ
(
i
)
(
x
)
h_\theta^{(i)}(x)
hθ(i)(x) 最大的
i
i
i.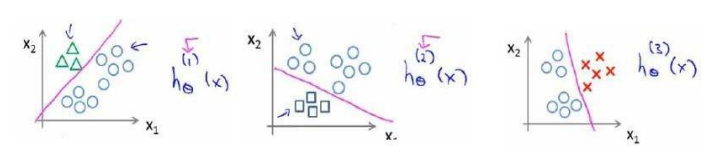
2.2 正则化(Regularization)
2.2.1 过拟合的问题
我们已经学习了线性回归与逻辑回归两种算法,在实现这些算法时,选择特征是一个关键步骤。在上一篇文章中,正规方程法可能出现不可逆的情况,有可能是因为特征过多导致,而我们当时提到了一个有力的解决方法是正则化。我们需要了解欠拟合,过拟合的相关概念。

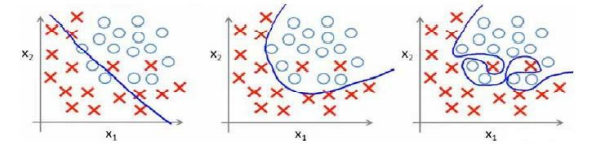
上面两个例子中,第一幅图都是欠拟合的情况,原因是特征量过少;第三幅图选择特征过多,过于强调拟合数据,从而削弱了预测新数据的功能,这种情况我们称作过拟合;因此中间的模型更加合适。
如果发现了过拟合的问题,我们可以从两个角度入手考虑:
- 丢弃一些不能帮助我们正确预测的特征。可以手工选择,也可以借助一些算法选择(如PCA),这种方法可能让我们失去一些有用信息。
- 正则化,保留所有特征,减小参数大小,从而让每个特征都为最终的模型作出一些贡献。
2.2.2 线性回归中的正则化
我们需要应用正则化于代价函数中,帮助我们防止过拟合的情况。新的代价函数为:
J
(
θ
)
=
1
2
m
[
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
+
λ
∑
j
=
1
n
θ
j
2
]
J(\theta)=\frac{1}{2m}[\sum_{i=1}^m(h_\theta(x^{(i)})-y^{(i)})^2+\lambda\sum_{j=1}^n\theta_j^2]
J(θ)=2m1[i=1∑m(hθ(x(i))−y(i))2+λj=1∑nθj2]
需要说明的是,我们不对
θ
0
\theta_0
θ0 进行缩小。经过正则化后的模型与过拟合情况的模型对比如图所示。

上式中的
λ
\lambda
λ 称作正则化参数,如果
λ
\lambda
λ 过大,则会把除
θ
0
\theta_0
θ0 外的所有参数近似为0,从而
h
θ
(
x
)
=
θ
0
h_\theta(x)=\theta_0
hθ(x)=θ0 ,也就是上图红线所示的情况,造成欠拟合。
因为代价函数的变化,线性回归的梯度下降算法也要有一定的变化。
R
e
p
e
a
t
u
n
t
i
l
c
o
n
v
e
r
g
e
n
c
e
θ
0
=
θ
0
−
α
1
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
x
0
(
i
)
θ
j
=
θ
j
−
α
[
1
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
x
j
(
i
)
+
λ
m
θ
j
]
=
θ
j
(
1
−
α
λ
m
)
−
α
1
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
x
j
(
i
)
Repeat\ until\ convergence\\ \theta_0=\theta_0-\alpha\frac{1}{m}\sum_{i=1}^m(h_\theta(x^{(i)})-y^{(i)})x_0^{(i)}\\ \begin{aligned} \theta_j&=\theta_j-\alpha[\frac{1}{m}\sum_{i=1}^m(h_\theta(x^{(i)})-y^{(i)})x_j^{(i)}+\frac{\lambda}{m}\theta_j]\\ &=\theta_j(1-\alpha\frac{\lambda}{m})-\alpha\frac{1}{m}\sum_{i=1}^m(h_\theta(x^{(i)})-y^{(i)})x_j^{(i)} \end{aligned}
Repeat until convergenceθ0=θ0−αm1i=1∑m(hθ(x(i))−y(i))x0(i)θj=θj−α[m1i=1∑m(hθ(x(i))−y(i))xj(i)+mλθj]=θj(1−αmλ)−αm1i=1∑m(hθ(x(i))−y(i))xj(i)
可以看出,正则化对梯度下降的影响是对每个
θ
j
\theta_j
θj 都减小了一个额外值。
同样地,正则化也对正规方程的形式产生了变化。
θ
=
(
X
T
X
+
λ
[
0
1
1
…
1
]
)
−
1
X
T
y
\theta=\Bigg(X^TX+\lambda\begin{bmatrix} 0\\ &1\\ &&1\\ &&&…\\ &&&&1 \end{bmatrix} \Bigg)^{-1}X^Ty
θ=(XTX+λ⎣⎢⎢⎢⎢⎡011…1⎦⎥⎥⎥⎥⎤)−1XTy
公式中的矩阵维度是
(
n
+
1
)
×
(
n
+
1
)
(n+1)\times (n+1)
(n+1)×(n+1). 推导过程如下:
J
(
θ
)
=
1
2
m
[
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
+
λ
∑
j
=
1
n
θ
j
2
]
=
1
2
m
[
(
X
θ
−
y
)
T
(
X
θ
−
y
)
+
λ
θ
′
T
θ
]
=
1
2
m
(
θ
T
X
T
X
θ
−
θ
T
X
T
y
−
y
T
X
θ
+
y
T
y
+
λ
θ
′
T
θ
)
\begin{aligned} J(\theta)&=\frac{1}{2m}[\sum_{i=1}^m(h_\theta(x^{(i)})-y^{(i)})^2+\lambda\sum_{j=1}^n\theta_j^2]\\ &=\frac{1}{2m}[(X\theta-y)^T(X\theta-y)+\lambda \theta'^T\theta]\\ &=\frac{1}{2m}(\theta^TX^TX\theta-\theta^TX^Ty-y^TX\theta+y^Ty+\lambda\theta'^T\theta) \end{aligned}
J(θ)=2m1[i=1∑m(hθ(x(i))−y(i))2+λj=1∑nθj2]=2m1[(Xθ−y)T(Xθ−y)+λθ′Tθ]=2m1(θTXTXθ−θTXTy−yTXθ+yTy+λθ′Tθ)
注意:因为我们不需要对
θ
0
\theta_0
θ0 正则化,所以这里的
θ
′
=
[
0
θ
1
…
θ
n
]
=
[
0
1
1
…
1
]
θ
\theta'=\begin{bmatrix} 0\\ \theta_1\\ …\\ \theta_n \end{bmatrix}=\begin{bmatrix} 0\\ &1\\ &&1\\ &&&…\\ &&&&1 \end{bmatrix}\theta
θ′=⎣⎢⎢⎡0θ1…θn⎦⎥⎥⎤=⎣⎢⎢⎢⎢⎡011…1⎦⎥⎥⎥⎥⎤θ 此外需要用到矩阵求导公式
∂
x
T
x
∂
x
=
2
x
∂
A
x
x
=
A
T
∂
x
T
B
x
=
B
∂
x
T
A
x
∂
x
=
(
A
+
A
T
)
x
\begin{gathered} \frac{\partial x^Tx}{\partial x}=2x\\ \frac{\partial Ax}{x}=A^T\\ \frac{\partial x^TB}{x}=B\\ \frac{\partial x^TAx}{\partial x}=(A+A^T)x \end{gathered}
∂x∂xTx=2xx∂Ax=ATx∂xTB=B∂x∂xTAx=(A+AT)x
因此对
J
(
θ
)
J(\theta)
J(θ)求偏导
θ
\theta
θ
∂
J
(
θ
)
∂
θ
=
1
m
(
X
T
X
θ
−
X
T
y
+
λ
[
0
1
1
…
1
]
θ
)
=
0
θ
=
(
X
T
X
+
λ
[
0
1
1
…
1
]
)
−
1
X
T
y
\begin{gathered} \frac{\partial J(\theta)}{\partial \theta}=\frac{1}{m}(X^TX\theta-X^Ty+\lambda \begin{bmatrix} 0\\ &1\\ &&1\\ &&&…\\ &&&&1 \end{bmatrix}\theta)=0\\ \theta=\Bigg(X^TX+\lambda\begin{bmatrix} 0\\ &1\\ &&1\\ &&&…\\ &&&&1 \end{bmatrix} \Bigg)^{-1}X^Ty \end{gathered}
∂θ∂J(θ)=m1(XTXθ−XTy+λ⎣⎢⎢⎢⎢⎡011…1⎦⎥⎥⎥⎥⎤θ)=0θ=(XTX+λ⎣⎢⎢⎢⎢⎡011…1⎦⎥⎥⎥⎥⎤)−1XTy
2.2.3 逻辑回归中的正则化
与线性回归类似,把正则化思想与逻辑回归结合,得到新的代价函数公式:
J
(
θ
)
=
−
1
m
∑
i
=
1
m
[
y
(
i
)
⋅
l
n
(
h
θ
(
x
(
i
)
)
)
+
(
1
−
y
(
i
)
)
⋅
l
n
(
1
−
h
θ
(
x
(
i
)
)
)
]
+
λ
2
m
∑
j
=
1
n
θ
j
2
J(\theta)=-\frac{1}{m}\sum_{i=1}^m[y^{(i)}\cdot ln(h_\theta(x^{(i)}))+(1-y^{(i)})\cdot ln(1-h\theta(x^{(i)}))]+\frac{\lambda}{2m}\sum_{j=1}^n\theta_j^2
J(θ)=−m1i=1∑m[y(i)⋅ln(hθ(x(i)))+(1−y(i))⋅ln(1−hθ(x(i)))]+2mλj=1∑nθj2
为了得到最小化的代价函数的
θ
\theta
θ ,得到新的梯度下降算法:
R
e
p
e
a
t
θ
0
=
θ
0
−
α
1
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
x
0
(
i
)
θ
j
=
θ
j
−
α
[
1
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
x
j
(
i
)
+
λ
m
θ
j
]
f
o
r
j
=
1
,
2
…
,
n
s
i
m
u
l
t
a
n
e
o
u
s
l
y
u
p
d
a
t
e
a
l
l
θ
j
Repeat\\ \theta_0=\theta_0-\alpha\frac{1}{m}\sum_{i=1}^m(h_\theta(x^{(i)})-y^{(i)})x_0^{(i)}\\ \theta_j=\theta_j-\alpha[\frac{1}{m}\sum_{i=1}^m(h_\theta(x^{(i)})-y^{(i)})x_j^{(i)}+\frac{\lambda}{m}\theta_j]\\ for\ j\ =1,2…,n\\ simultaneously\ update\ all\ \theta_j
Repeatθ0=θ0−αm1i=1∑m(hθ(x(i))−y(i))x0(i)θj=θj−α[m1i=1∑m(hθ(x(i))−y(i))xj(i)+mλθj]for j =1,2…,nsimultaneously update all θj
同样地,梯度下降算法的公式与线性回归中的形式一样,但是因为我们知道逻辑回归中的
h
θ
(
x
)
h_\theta(x)
hθ(x) 与线性回归不同,从而有本质区别。除此之外,
θ
0
\theta_0
θ0 同样不参与正则化。
2.3 配套作业的Python实现
2.3.1 逻辑回归
1. 问题背景
本练习需要我们建立一个逻辑回归模型来预测一个学生是否会被大学录取。假设你是一个大学管理员,有历史申请人的两次考试结果与录取结果作为训练集。构建的模型可以使得基于两次考试分数给出入学概率。
2. 数据可视化
首先我们要导入所需的包。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use("fivethirtyeight") # 样式美化
from sklearn.metrics import classification_report # 评价报告
再初步预览数据集。
data = pd.read_csv('ex2data1.txt', names=['exam1', 'exam2', 'admitted'])
data.head()#看前五行
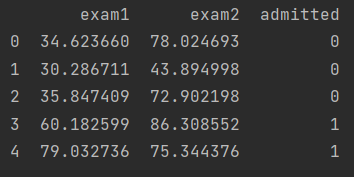
data.describe()

对数据集进行可视化处理。
sns.set(context="notebook", style="darkgrid", palette=sns.color_palette("RdBu", 2))
sns.lmplot(x='exam1', y='exam2', hue='admitted', data=data,
height=6,
fit_reg=False,
scatter_kws={"s": 50}
)
plt.show()

接下来,我们需要对数据进行处理,以便建立模型。在这里我们分别得到ndarray形式的X与y. 其次也需要注意是否特征缩放。
def get_X(df):
ones = pd.DataFrame({'ones': np.ones(len(df))})
data = pd.concat([ones, df], axis=1) # 按列合并数据
return data.iloc[:, :-1].values
def get_y(df):
return np.array(df.iloc[:, -1])
def normalize_frature(df):
return df.apply(lambda column:(column - column.mean()) / column.std()) # 特征缩放
X = get_X(data)
print(X.shape)
y = get_y(data)
print(y.shape)
(100, 3)
(100,)
3. sigmoid 函数
回顾前文提到的sigmoid函数:
h
θ
(
x
)
=
1
1
+
e
−
θ
T
x
h_\theta(x)=\frac{1}{1+e^{-\theta^Tx}}
hθ(x)=1+e−θTx1
def sigmoid(z):
return 1 / (1 + np.exp(-z))
我们可以对该函数进行可视化处理。
fig, ax = plt.subplots(figsize=(8, 6))
ax.plot(np.arange(-10, 10, step=0.01),
sigmoid(np.arange(-10, 10, step=0.01)))
ax.set_ylim((-0.1, 1.1))
ax.set_xlabel('z', fontsize=18)
ax.set_ylabel('g(z)', fontsize=18)
ax.set_title('sigmoid function', fontsize=18)
plt.show()

4. 代价函数与梯度下降
J
(
θ
)
=
1
m
∑
i
=
1
m
[
−
y
(
i
)
⋅
l
n
(
h
θ
(
x
(
i
)
)
)
−
(
1
−
y
(
i
)
)
⋅
l
n
(
1
−
h
θ
(
x
(
i
)
)
)
]
J(\theta)=\frac{1}{m}\sum_{i=1}^m[-y^{(i)}\cdot ln(h_\theta(x^{(i)}))-(1-y^{(i)})\cdot ln(1-h_\theta(x^{(i)}))]
J(θ)=m1i=1∑m[−y(i)⋅ln(hθ(x(i)))−(1−y(i))⋅ln(1−hθ(x(i)))]
首先初始化
θ
\theta
θ
theta = theta=np.zeros(3)
def cost(theta, X, y):
''' cost fn is -l(theta) for you to minimize'''
return np.mean(-y * np.log(sigmoid(X @ theta)) - (1 - y) * np.log(1 - sigmoid(X @ theta)))
# X @ theta与X.dot(theta)等价
可计算出
θ
=
[
0
,
0
,
0
]
\theta=[0,0,0]
θ=[0,0,0]时的代价函数值为0.6931471805599453.
梯度下降算法为
R
e
p
e
a
t
θ
j
=
θ
j
−
α
1
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
x
j
(
i
)
s
i
m
u
l
t
a
n
e
o
u
s
l
y
u
p
d
a
t
e
a
l
l
θ
j
Repeat\\ \theta_j=\theta_j-\alpha\frac{1}{m}\sum_{i=1}^m(h_\theta(x^{(i)})-y^{(i)})x_j^{(i)}\\ simultaneously\ update\ all\ \theta_j
Repeatθj=θj−αm1i=1∑m(hθ(x(i))−y(i))xj(i)simultaneously update all θj
因此我们首先计算梯度
∂
∂
θ
j
J
(
θ
)
=
1
m
∑
i
=
1
m
[
h
θ
(
x
(
i
)
)
−
y
(
i
)
]
x
j
(
i
)
\frac{\partial}{\partial \theta_j}J(\theta)=\frac{1}{m}\sum_{i=1}^m[h_\theta(x^{(i)})-y^{(i)}]x_j^{(i)}
∂θj∂J(θ)=m1i=1∑m[hθ(x(i))−y(i)]xj(i)
等价的批量计算梯度方法
1
m
⋅
X
T
⋅
[
s
i
g
m
o
i
d
(
X
θ
)
−
y
]
\frac{1}{m}\cdot X^T\cdot [sigmoid(X \theta)-y]
m1⋅XT⋅[sigmoid(Xθ)−y]
def gradient(theta, X, y):
"""
这个写法不够批量化,可直接用矩阵实现同样效果
grad_theta_0 = np.mean(X[:,0] * (sigmoid(X @ theta) - y))
grad_theta_1 = np.mean(X[:,1] * (sigmoid(X @ theta) - y))
grad_theta_2 = np.mean(X[:,2] * (sigmoid(X @ theta) - y))
grad = np.array([grad_theta_0, grad_theta_1, grad_theta_2])
return grad
"""
def gradient(theta, X, y):
return (1 / len(X)) * X.T @ (sigmoid(X @ theta) - y)
可计算出此时梯度为[ -0.1, -12.00921659, -11.26284221]
def gradientDescent(X, y, theta, alpha, iters):
temp = np.zeros(theta.size)
parameters = theta.size
for i in range(iters):
for j in range(parameters):
temp[j] = theta[j] - alpha * gradient(theta, X, y)[j]
theta = temp
return theta
alpha = 0.001
iters = 100000
theta = gradientDescent(X, y, theta, alpha, iters)
print(theta)
print(cost(theta, X, y))
# 可能因为学习率与迭代次数的问题,效果不理想
因此我们采用参数拟合的高级优化方法,直接得到理想参数,使用scipy.optimize.minimize方法。
import scipy.optimize as opt
res = opt.minimize(fun=cost, x0=theta, args=(X, y), method='Newton-CG', jac=gradient)

使用训练集验证模型。
def predict(x, theta):
y_pred = (sigmoid(x @ theta) > 0.5).astype(int)
return y_pred
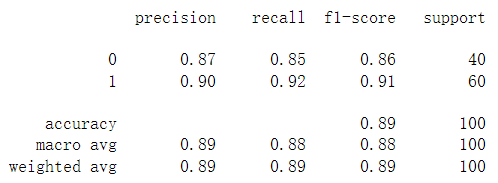
final_theta = res.x
y_pred = predict(X, final_theta)
print(classification_report(y, y_pred))
5.寻找决策边界
print(res.x) # this is final theta
最终
θ
=
[
−
25.15632676
0.20619166
0.20143109
]
\theta=[-25.15632676\quad0.20619166\quad0.20143109]
θ=[−25.156326760.206191660.20143109].
我们知道在sigmoid函数中z值大于0,判定为1;小于等于0,判定为0.因此决策边界为
x
θ
=
0
x\theta=0
xθ=0
θ
0
+
θ
1
x
1
+
θ
2
x
2
=
0
x
2
=
−
θ
1
θ
2
x
1
−
θ
0
θ
2
\theta_0+\theta_1x_1+\theta_2x_2=0\\ \\ \quad \\ x_2=-\frac{\theta_1}{\theta_2}x_1-\frac{\theta_0}{\theta_2}
θ0+θ1x1+θ2x2=0x2=−θ2θ1x1−θ2θ0
coef = -(res.x / res.x[2]) # find the equation
print(coef)
x = np.arange(130, step=0.1)
y = coef[0] + coef[1]*x
sns.set(context="notebook", style="ticks", font_scale=1.5)
sns.lmplot(x='exam1', y='exam2', hue='admitted', data=data,
height=6,
fit_reg=False,
scatter_kws={"s": 25}
)
plt.plot(x, y, 'grey')
plt.xlim(0, 130)
plt.ylim(0, 130)
plt.title('Decision Boundary')
plt.show()

2.3.2 逻辑回归的正则化
1.问题背景
利用逻辑回归正则化预测制造厂的微芯片是否通过质量保证 (QA)。 在 QA 期间,每个微芯片都经过各种测试,以确保它运行正常。假设你是工厂的产品经理,你有一些微芯片在两种不同测试中的测试结果。 从这两个测试中,您想确定是否应接受微芯片或拒绝。为了帮助您做出决定,您有一个测试结果数据集在过去的微芯片上,您可以从中构建逻辑回归模型。
2.数据可视化
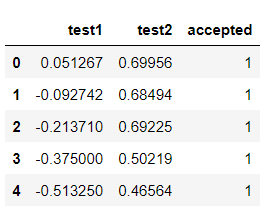
df = pd.read_csv('ex2data2.txt', names=['test1', 'test2', 'accepted'])
df.head()
sns.set(context="notebook", style="ticks", font_scale=1.5)
sns.lmplot(x='test1', y='test2', hue='accepted', data=df,
height=6,
fit_reg=False,
scatter_kws={"s": 50}
)
plt.title('Regularized Logistic Regression')
plt.show()

3.特征映射(feature mapping)
通过将数据可视化可得出决策边界不再是一条简单直线的结论,因此我们需要用多项式来得到合适的决策边界。

def feature_mapping(x, y, power, as_ndarray=False):
"""return mapped features as ndarray or dataframe"""
data = {"f{}{}".format(i - p, p): np.power(x, i - p) * np.power(y, p)
for i in np.arange(power + 1)
for p in np.arange(i + 1)
}
if as_ndarray:
return pd.DataFrame(data).values
else:
return pd.DataFrame(data)
x1 = np.array(df.test1)
x2 = np.array(df.test2)
data = feature_mapping(x1, x2, power=6)
print(data.shape)
data.head()

以6次为例,我们得到了28个特征。
4.正则化逻辑回归代价函数与正则化梯度
theta = np.zeros(data.shape[1])# f00即多加的常数项
X = feature_mapping(x1, x2, power=6, as_ndarray=True)
print(X.shape)
y = get_y(df)
print(y.shape)
J ( θ ) = − 1 m ∑ i = 1 m [ y ( i ) ⋅ l n ( h θ ( x ( i ) ) ) + ( 1 − y ( i ) ) ⋅ l n ( 1 − h θ ( x ( i ) ) ) ] + λ 2 m ∑ j = 1 n θ j 2 J(\theta)=-\frac{1}{m}\sum_{i=1}^m[y^{(i)}\cdot ln(h_\theta(x^{(i)}))+(1-y^{(i)})\cdot ln(1-h\theta(x^{(i)}))]+\frac{\lambda}{2m}\sum_{j=1}^n\theta_j^2 J(θ)=−m1i=1∑m[y(i)⋅ln(hθ(x(i)))+(1−y(i))⋅ln(1−hθ(x(i)))]+2mλj=1∑nθj2
def regularized_cost(theta, X, y, l=1):
theta_j1_to_n = theta[1:]# 不需要将theta_0正则化
regularized_term = (l / (2 * len(X))) * np.power(theta_j1_to_n, 2).sum()
return cost(theta, X, y) + regularized_term
def regularized_gradient(theta, X, y, l=1):
theta_j1_to_n = theta[1:]
regularized_theta = (l / len(X)) * theta_j1_to_n
# by doing this, no offset is on theta_0
regularized_term = np.concatenate([np.array([0]), regularized_theta])
return gradient(theta, X, y) + regularized_term
同样地,我们利用scipy.optimize找到最优参数。
import scipy.optimize as opt
print('init cost = {}'.format(regularized_cost(theta, X, y)))
res = opt.minimize(fun=regularized_cost, x0=theta, args=(X, y), method='Newton-CG', jac=regularized_gradient)
print(res)

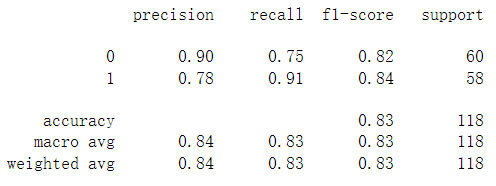
final_theta = res.x
y_pred = predict(X, final_theta)
print(classification_report(y, y_pred))
5. 使用不同的
λ
\lambda
λ,画出决策边界
与第一题不同,此题项数为28个!不易直接得到x2与x1之间的关系式,因此我们通过建立一系列网格,找到那些足够优秀的点(近似于0),标出即可,如果网格足够密集,那么绘制出的图形便是连续的。
def draw_boundary(power, l):
# """
# power: polynomial power for mapped feature
# l: lambda constant
# """
density = 1000
threshhold = 2 * 10**-2.4
final_theta = feature_mapped_logistic_regression(power, l)
x, y = find_decision_boundary(density, power, final_theta, threshhold)
df = pd.read_csv('ex2data2.txt', names=['test1', 'test2', 'accepted'])
sns.lmplot(x='test1', y='test2', hue='accepted', data=df, height=6, fit_reg=False, scatter_kws={"s": 100})
plt.scatter(x, y, c='r', s=10)
plt.title('Decision boundary')
plt.show()
def feature_mapped_logistic_regression(power, l):
# """for drawing purpose only.. not a well generealize logistic regression
# power: int
# raise x1, x2 to polynomial power
# l: int
# lambda constant for regularization term
# """
df = pd.read_csv('ex2data2.txt', names=['test1', 'test2', 'accepted'])
x1 = np.array(df.test1)
x2 = np.array(df.test2)
y = get_y(df)
X = feature_mapping(x1, x2, power, as_ndarray=True)
theta = np.zeros(X.shape[1])
res = opt.minimize(fun=regularized_cost,
x0=theta,
args=(X, y, l),
method='TNC',
jac=regularized_gradient)
final_theta = res.x
return final_theta
def find_decision_boundary(density, power, theta, threshhold):
t1 = np.linspace(-1, 1.5, density)
t2 = np.linspace(-1, 1.5, density)
cordinates = [(x, y) for x in t1 for y in t2]
x_cord, y_cord = zip(*cordinates)
mapped_cord = feature_mapping(x_cord, y_cord, power) # this is a dataframe
inner_product = mapped_cord.values @ theta
decision = mapped_cord[np.abs(inner_product) < threshhold]
return decision.f10, decision.f01
draw_boundary(power=6, l=1) #set lambda = 1

draw_boundary(power=6, l=0) # set lambda < 0.1 过拟合

draw_boundary(power=6, l=50) # set lambda > 10 欠拟合
















 1656
1656











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









