







数据
(文章结尾附pom依赖)
java scala python scala scala java
hadoop spark hadoop spark spark
mapreduce spark spark hive
hive spark hadoop mapreduce spark
spark hive sql sql spark hive hive spark
hdfs hdfs mapreduce mapreduce spark hive
sparkcore版
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @Todo: Spark_core的词频计算
* @auther: Cjp
* @date: 2021/7/12 17:25
*/
object SparkCoreCount {
def main(args: Array[String]): Unit = {
//todo:1.构建SparkContext对象
val sc:SparkContext = {
//构建SparkConf配置管理对象,类似于Hadoop中的configuration对象
val conf = new SparkConf()
.setMaster("local[2]")//指定运行模式
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))//指定运行程序的名称
//.set("key","value")//指定额外的属性
//返回SparkContext的对象
SparkContext.getOrCreate(conf)
}
//调整日志级别
sc.setLogLevel("WARN")
//todo:2.实现数据的转换处理
//step1:读取数据
//val inputRDD:RDD[String] = sc.textFile(args(0))
val inputRDD:RDD[String] = sc.textFile("./datas/wordcount/wordcount.data")
println(s"总行数 = ${inputRDD.count()}")
println(s"第一行 = ${inputRDD.first()}")
println(s"第二行 = ${inputRDD.take(2)(1)}")
println(s"最后一行 = ${inputRDD.take(inputRDD.count().toInt)(inputRDD.count().toInt-1)}")
//step2:处理数据
val wcRDD:RDD[(String,Int)]= inputRDD
.filter(line => line != null && line.trim.length > 0)//过滤空行
.flatMap(line => line.trim.split("\\s+"))//将每个单词分割提取
.map(word => (word,1))//构建二元数组
.reduceByKey((tmp,item) => tmp + item)//按照key进行分组聚合
//step3:保存结果
wcRDD.foreach(println)
//wcRDD.saveAsTextFile(args(1) + "-" + System.currentTimeMillis())
//wcRDD.saveAsTextFile("./datas/wordcount/output" + "-" + System.currentTimeMillis())
//todo:3.释放SparkContext对象
//Thread.sleep(1000)
sc.stop()
}
}
运行结果:

SparkDSL版
import org.apache.spark.sql.{Dataset, SparkSession}
/**
* @Todo: SparkSQL使用 DSL方式开发 Wordcount程序
* @auther: Cjp
* @date: 2021/7/15 20:42
*/
object wcSparkDSL {
def main(args: Array[String]): Unit = {
//todo:1-构建驱动对象:sparksession
val spark:SparkSession = SparkSession
.builder()//构建一个建造器
.master("local[2]")//配置运行模式
.appName(this.getClass.getSimpleName.stripSuffix("$"))//设置程序名称
// .config("key","value")//配置其他属性(内存,核数)
.getOrCreate()//返回一个sparksession对象
//更改日志级别
spark.sparkContext.setLogLevel("WARN")
//引入隐式转换
import spark.implicits._
import org.apache.spark.sql.functions._
//todo:2-实现处理的逻辑
//step1:读取数据
val inputData: Dataset[String] = spark.read.textFile("datas/wordcount/wordcount.data")
//step2:转换数据
val rsData = inputData
.filter(line => line != null && line.trim.length >0)//过滤空行
.flatMap(line => line.trim.split("\\s+"))//得到每个单词
.groupBy($"value")//对value这一列进行分组
.count()//统计每组的个数
.orderBy($"count".desc)//降序排序
//step3:保存结果
/* inputData.printSchema() //打印表
inputData.show()//输出数据
//注:show(numRows, truncate = true):打印数据,numRows:打印行数,默认20行,
// truncate:如果字段的值过长,是否省略显示。默认为true,省略显示*/
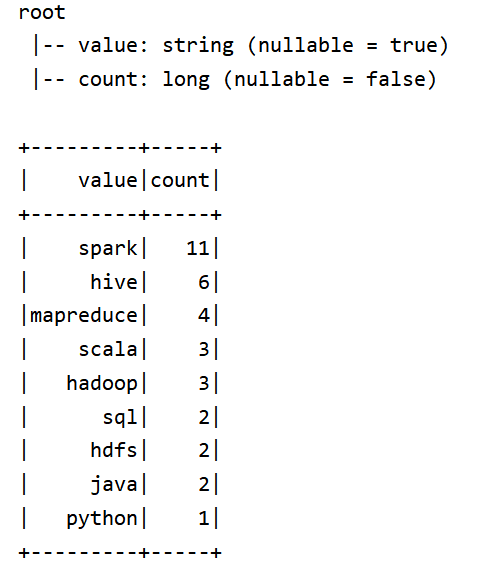
rsData.printSchema()
rsData.show()
//todo:3-释放资源
spark.stop()
}
}
运行结果:
SparkSQL版
import org.apache.spark.sql.{Dataset, SparkSession}
/**
* @Todo: SparkSQL使用 SQL方式开发 Wordcount程序
* @auther: Cjp
* @date: 2021/7/15 20:43
*/
object wcSparkSQL {
def main(args: Array[String]): Unit = {
//todo:1-构建驱动对象:sparksession
val spark:SparkSession = SparkSession
.builder()//构建一个建造器
.master("local[2]")//配置运行模式
.appName(this.getClass.getSimpleName.stripSuffix("$"))//设置程序名称
// .config("key","value")//配置其他属性(内存,核数)
.getOrCreate()//返回一个sparksession对象
//更改日志级别
spark.sparkContext.setLogLevel("WARN")
/* //引入隐式转换
import spark.implicits._
import org.apache.spark.sql.functions._*/
//todo:2-实现处理的逻辑
//step1:读取数据
val inputData: Dataset[String] = spark.read.textFile("datas/wordcount/wordcount.data")
/* inputData.printSchema() //打印表
inputData.show()//输出数据
//注:show(numRows, truncate = true):打印数据,numRows:打印行数,默认20行,
// truncate:如果字段的值过长,是否省略显示。默认为true,省略显示*/
//step2:转换数据
//注册视图
inputData.createOrReplaceTempView("tmp_view_input")
//SQL转换
val rsData = spark.sql(
"""
|select
| word,count(1) as cn
|from
| (select
| explode(split(value," ")) as word
| from tmp_view_input
| ) as tmp
|group by word
|order by cn desc
""".stripMargin)
//step3:保存结果
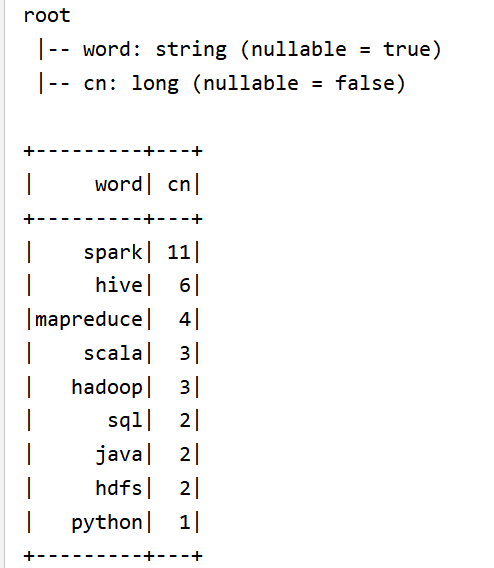
rsData.printSchema()
rsData.show()
//todo:3-释放资源
spark.stop()
}
}
结果展示:
pom依赖:
<!-- 指定仓库位置,依次为aliyun、cloudera和jboss仓库 -->
<repositories>
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
<repository>
<id>jboss</id>
<url>http://repository.jboss.com/nexus/content/groups/public</url>
</repository>
</repositories>
<properties>
<scala.version>2.11.12</scala.version>
<scala.binary.version>2.11</scala.binary.version>
<spark.version>2.4.5</spark.version>
<hadoop.version>2.6.0-cdh5.16.2</hadoop.version>
<hbase.version>1.2.0-cdh5.16.2</hbase.version>
<mysql.version>8.0.19</mysql.version>
</properties>
<dependencies>
<!-- 依赖Scala语言 -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- Spark Core 依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Spark SQL 依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Spark SQL 与 Hive 集成 依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive-thriftserver_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-avro_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Hadoop Client 依赖 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- HBase Client 依赖 -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-hadoop2-compat</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.version}</version>
</dependency>
<!-- MySQL Client 依赖 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
</dependencies>
<build>
<outputDirectory>target/classes</outputDirectory>
<testOutputDirectory>target/test-classes</testOutputDirectory>
<resources>
<resource>
<directory>${project.basedir}/src/main/resources</directory>
</resource>
</resources>
<!-- Maven 编译的插件 -->
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>















 2454
2454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









