







 本文深入探讨Spark实现WordCount实例,详细解释执行流程,包括SparkConf和SparkContext的创建,以及DAG有向无环图的概念。通过实例代码展示Scala和Java版本的实现,并与MapReduce的WordCount进行对比,帮助读者理解Spark的计算过程。
本文深入探讨Spark实现WordCount实例,详细解释执行流程,包括SparkConf和SparkContext的创建,以及DAG有向无环图的概念。通过实例代码展示Scala和Java版本的实现,并与MapReduce的WordCount进行对比,帮助读者理解Spark的计算过程。
温馨提示
本公众号专注分享大数据技术Spark、Hadoop等,如果你是初学者、或者是自学者,这里都是可以提供免费资料,也可以加小编微信号:wusc35,小编可以给你学习上、工作上一些建议以及可以给你提供免费的学习资料!学习技术更重要的是在于学习交流!等你来...
注:本公众号纯属个人公益号!免费分享所有学习资料!希望朋友多多支持!多多关注!
回顾一下前面几节,我们已经讲解Spark的作用与优劣、基本原理与核心RDD特征。在有这些基础后,我们来进入一个实战,基于最典型的WordCount实例来综合运用前面所学到的知识点,并进一步详解。对学习技术方面比较喜欢使用图来分析知识点,有图有真相。

首先,编写第一个Spark应用程序 ,我们是如何建立起来的,其入口在哪里呢,需要创建两个对象。
一:val conf = new SparkConf()
.setAppName("WordCount")
.setMaster("local")
创建SparkConf对象,设置Spark应用的配置信息。setAppName() 设置Spark应用程序在运行中的名字;如果是集群运行,就可以在监控页面直观看到我们运行的job任务。setMaster() 设置运行模式、是本地运行,设置为local即可;如果是集群运行,就可以设置程序要连接的Spark集群的master节点的url。
二:val sc = new SparkContext(conf)
创建SparkContext对象, 在Spark中,SparkContext是Spark所有功能的一个入口,你无论是用java、scala,甚至是python编写,都必须要有一个SparkContext,它的主要作用,包括初始化Spark应用程序所需的一些核心组件,包括调度器(DAGSchedule、TaskScheduler),还会去Spark Master节点上进行注册等。所以SparkContext在Spark应用中是很重要的一个对象。
Spark实现WordCount实例执行流程图
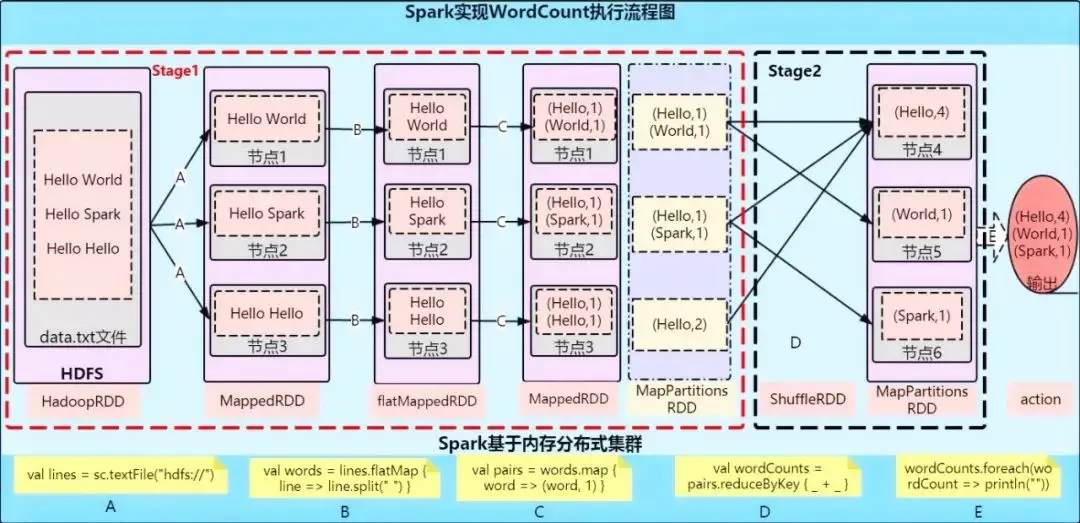
图1-Spark实现WordCount执行流程图
我们先看图中是由两大部分组成,一是Spark基于内存分布式计算集群,二是下面的Scala代码部分。
现在假设我们HDFS上有一个数据文件data.txt文件,需要对其进行WordCount统计计算,如果有对各种算子不了解的同学,也不要紧,代码结合运行流程图一步一步分享。
第A步:val lines = sc.textFile("hdfs://") ,主要功能是加载HDFS中的数据文件进入Spark本地或是集群计算,这里我们使用的是SparkContext的textFile算子,加载后的数据将以每行记录组成元素,元素类型为String。这时我们假设数据被分为3个RDD进入Spark集群的不同节点1、2、3。RDD由Hadoop中HDFS数据文件转变为MappedRDD,这也是创建RDD的一种方式。
第B步:val words = lines.flatMap { line => line.split(" ") } ,主要是对MappedRDD中的每个元素(也就是每一行)进行操作。这里使用transformation中的flatMap算子,作用是可以将一个map数据集转变成为flap数据集,即数据扁平化处理。这里也就是将输入文件的每一行数据,按空格(" ")进行拆分,得到单词数组,再将数组进行扁平化后形成单词字符串,在flatMapRDD中。RDD由MappedRDD转变为flatMappedRDD,这又是创建RDD的一种方式,由RDD创建RDD。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6078
6078

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









