






Scala
类型
package chapter08
object More_1 {
def main(args: Array[String]): Unit = {
val b:B=new B
println(b.isInstanceOf[B])
println(b.isInstanceOf[A])
println(b.isInstanceOf[Object])
val a=b.asInstanceOf[B]
b.asInstanceOf[Object]
b.asInstanceOf[Any]
val c=10
c.asInstanceOf[Object]
println(c)
}
}
class A
class B extends A
/*
类型转换:
java:
判断 obj instanceof 类型
scala:
判断 b.isInstanceof[B]
类型转换 b.asInstanceOf[A]
*/

隐式转换
package chapter08
object Implicit_4 {
def main(args: Array[String]): Unit = {
implicit val aa:Int=100//隐式值
implicit val bb:Double=900
implicit def doubleToInt(a:Double): Int =a.toInt
val a:Int=10.1
println(a)
foo(10,20)
//foo()//隐式值
foo
f//先隐式值,再默认值
f()//默认值
}
def foo(implicit a:Int,b:Double): Unit ={
println(a)
}
//分别设定隐式和非隐式的参数
/*def foo(a:Int)(implicit b:Double): Unit ={
println(s"$a,$b")
}*/
def f(implicit a:Int=10): Unit ={
println(a)
}
}
/*
隐式转换
1、隐式转换函数
implicit def double2Int(d:Double)=d.toInt
不看函数名,只看参数和返回值类型
将来可以给已有的类增加功能
2、隐式类
implicit class RichFile(file:File){
def readContent1:String={
Source.fromFile(file,"utf-8").mkString
}
}
1、不能顶级
2、主构造必须有参数
3、参数的
3、隐式参数和隐式值
implicit val aa=100
def foo(implicit)
当调用函数的时候,如果不传参数,并且省略括号,就会找隐式值!(只看类型,不看名字)
如果定义了隐式参数,则整个参数列表中所有的参数都是隐式参数
*/
隐式高级用法实例
package chapter08
import java.time.LocalDate
object Implicit_3 {
def main(args: Array[String]): Unit = {
implicit def int2RichDate(day: Int) = new RichDate(day)
val ago = "ago"
val later = "later"
var r1=2 days ago //计算两天前是哪一天 2.days(ago)
var r2 = 4 days later //计算4天前是哪一天 4.days(later)
println(r1)
println(r2)
}
}
class RichDate(day: Int) {
def days(when: String) = {
if ("ago" == when) {
LocalDate.now().plusDays(-day).toString
} else {
LocalDate.now().plusDays(day).toString
}
}
}

枚举类
package chapter08
import java.time.Month
import chapter08.Season.Season
object Enum_1 {
def main(args: Array[String]): Unit = {
val s:Father=Son1
println(Son1.isInstanceOf[Father])
foo(Season.Spring)
}
def foo(s:Season): Unit ={
println(s)
}
}
object Season extends Enumeration{
type Season=Value
val Spring,Summer,autumn,Winter=Value
def judge(month: Int) ={
if(month>=1&&month<=3){
Spring
}
}
}
sealed abstract class Father
object Son1 extends Father
object Son2 extends Father
object Son3 extends Father{
}
/*
sealed 用来修饰的类叫密封类
将来这类的子类只能出现当前文件中
1、模拟枚举
sealed abstract class Father
object Son1 extends Father
object Son2 extends Father
object Son3 extends Father
2、可以使用Java的枚举
scala不能写,只能用Java代码去实现,在Scala中调用
3、Scala也提供了一种官方的枚举类
*/
定长数组
object Array_2 {
def main(args: Array[String]): Unit = {
val arr:Array[Int]=new Array[Int](15)
val arr1:Array[Int]=Array[Int](1,2,3,4,4)
}
}
/*
定长数组的创建
1、通过元素直接初始化数组
val arr=Array[Int](1,2,3)
2、创建的时候指定数组长度
new Array[Int](10)
*/
不可变数组
1)第一种方式定义数组(定长数组)
定义:val arr1 = new ArrayInt
(1)new是关键字
(2)[Int]是指定可以存放的数据类型,如果希望存放任意数据类型,则指定Any
(3)(10),表示数组的大小,确定后就不可以变化
2)第二种方式定义数组
val arr1 = Array(1, 2)
(1)在定义数组时,直接赋值
(2)使用apply方法创建数组对象
package chapter09
object Array_1 {
def main(args: Array[String]): Unit = {
val arr: Array[Int] = Array[Int](1, 2, 3, 4)
for(i <- arr){//遍历数组
print(i+" ")
}
println()
println(arr(0))
arr(0) = 100
println(arr.mkString(","))
arr(0) = 1
val arr1: Array[Int] = arr :+ 100 //<=> arr.+:(100)
println(arr1.mkString(",")) //1,2,3,4,100
val arr2: Array[Int] = 100 +: arr
println(arr2.mkString(",")) //100,1,2,3,4
val arr3: Array[Int] = Array(1, 2, 3, 4, 5)
val arr4: Array[Int] = Array(6, 7, 8, 9, 10)
val arr5: Array[Int] = arr3 ++ arr4//<=> arr3.++(arr4)
println(arr5.mkString(",")) //1,2,3,4,5,6,7,8,9,10
}
}
/*
<>:给xml,scala语言级别的支持xml <user></user>
[]:给了泛型
(index):访问指定索引元素
:+一般用于给不可变的集合添加单个元素到头部
+:一般用于给不可变的集合添加单个元素到头部
++合并两个集合
运算符的结和性
1+2 左结合
+2 右结合
a=3 右结合
只要运算符是以冒号结尾就是右结合
1、Scala没有自己定义自己的数组,底层就是Java的数组
定长数组
2、创建数组
1、直接通过给数组初始化元素的方式创建数组
*/

可变数组
1)定义变长数组
val arr01 = ArrayBuffer[Any](3, 2, 5)
(1)[Any]存放任意数据类型
(2)(3, 2, 5)初始化好的三个元素
(3)ArrayBuffer需要引入scala.collection.mutable.ArrayBuffer
package chapter09
import scala.collection.mutable.ArrayBuffer
object Array_3 {
def main(args: Array[String]): Unit = {
//ArrayBuffer.apply(1,2,3,4)
val buffer: ArrayBuffer[Int] = ArrayBuffer(1, 2, 3, 4)
println("buffer=" + buffer)
val buffer1: ArrayBuffer[Int] = new ArrayBuffer[Int](10)
println("buffer1=" + buffer1)
val buffer3: ArrayBuffer[Int] = buffer :+ 5
println("buffer3=" + buffer3)
//原地修改buffer,在它的尾部添加元素
buffer += 5
println("buffer=" + buffer)
//在头部添加元素
0 +=: buffer
println("buffer=" + buffer)
val buffer4: ArrayBuffer[Int] = buffer ++ buffer3
println("buffer4=" + buffer4)
buffer ++= buffer3 //将buffer3的集合追加到buffer的后面,更新的是buffer1
//buffer2.++:(buffer1)
println("buffer=" + buffer)
//val buffer5:ArrayBuffer[Int]= buffer++=buffer3
buffer ++=: buffer3 //把buffer的元素添加到buffer3的前面,更新的是buffer3
println("buffer3=" + buffer3)
buffer -= 1
println(buffer)
buffer --= buffer3 //移除buffer3中有的元素
//buffer -= (1, 2, 3)已经不推荐使用
println("buffer=" + buffer)
}
}
/*
可变数组
ArrayBuffer
创建:
1、ArraysBuffer(1,2,3)
2、new ArrayBuffer[]()
+= 头部
=+ 尾部
++= 把后面的集合的元素合并到前面的集合中
-= 删除元素,只删除满足的第一个(set 用的比较多)
--= 删除后面集合有的元素
*/

可变数组和不可变数组的转化
arr1.toBuffer //不可长数组转可变数组
arr2.toArray //可变数组转不可变数组
(1)arr2.toArray返回结果才是一个不可变数组,arr2本身没有变化
(2)arr1.toBuffer返回结果才是一个可变数组,arr1本身没有变化
import scala.collection.mutable
import scala.collection.mutable.ArrayBuffer
object Array_4 {
def main(args: Array[String]): Unit = {
val arr1:Array[Int]=Array(1,2,3,4,5,6)
val buffer:mutable.Buffer[Int]=arr1.toBuffer
println(buffer)
val b:ArrayBuffer[Int]=ArrayBuffer(10,20)
val arr2:Array[Int]=b.toArray
println(arr2.mkString(","))
}
}

多维数组
object Array_5 {
def main(args: Array[String]): Unit = {
//多维数组(二维数组),用一维数组模拟的多维数组
//2*3
val arr:Array[Array[Int]]=Array.ofDim[Int](2,3)
arr(0)(1)
for (a1 <- arr) {
for (elem <- a1) {
println(elem)
}
}
}
}
不可变数组的补充
package chapter09
object List_2 {
def main(args: Array[String]): Unit = {
var arr1 = Array(30, 40, 50, 60)//注意使用的是var
println(arr1)//[I@ea4a92b
arr1 :+= 100 //产生了一个新的不可变集合,然后把新的不可变集合赋值给变量
println(arr1)//[I@7e0ea639
//地址变了
println(arr1.mkString(","))
}
}

不可变List
(1)List默认为不可变集合
(2)创建一个List(数据有顺序,可重复)
(3)遍历List
(4)List增加数据
(5)集合间合并:将一个整体拆成一个一个的个体,称为扁平化
(6)取指定数据
(7)空集合Nil
package chapter09
object List_1 {
def main(args: Array[String]): Unit = {
//1、创建有元素的集合
val L1:List[Int]=List[Int](1,2,3)
//2、空list
val L2=List[Int]()
//3、空集合
val L3=Nil
//4、向List添加元素
val L4=L1 :+ 4
println(L4)
val L5= -1 ::0 :: L1
println(L5)
val L6=L5++L4
val L7=L5:::L4
println(L6)
println(L7)
//装逼代码
val L8 = :: [Int](1,1::Nil)
println(L8)
}
}
/*
List
就是列表
默认不可变
List专用:
:: 添加元素
::: 和并集合
*/

可变ListBuffer
和可变Array相似
不可变Set
(1)Set默认是不可变集合,数据无序
(2)数据不可重复
(3)遍历集合
元组
元组也是可以理解为一个容器,可以存放各种相同或不同类型的数据。说的简单点,就是将多个无关的数据封装为一个整体,称为元组。
注意:元组中最大只能有22个元素。
package chapter09
object Tuple_1 {
def main(args: Array[String]): Unit = {
//定义方法:1、原始
val t2:(Int,String)=Tuple2(10,"abc")
1+2
println(t2._1)
println(t2._2)
//2、简化
val t22=(10,"abc")
println(t22._1)
println(t22,1)
//元组
}
}
/*
Tuple
元组,一个特别简单,而且特别重要的一个数据结构
可以封装多个数据,并且类型允许不同
最多到22个
*/

不可变Map
object Map1 {
def main(args: Array[String]): Unit = {
val map1:Map[String,Int]=Map[String,Int](("a",97),("b",99),("d",98),("c",98))
for (elem <- map1) {
println(elem)
println(elem._1)
}
for ((k,v)<-map1){//模式匹配
println(k)
}
println("********")
for((k,98)<-map1){
println(k)
}
}
}
/*
map 映射
默认不可变,具体的实现就是HashMap
Scala的Map,把键和值当作元组(对偶)来处理
*/
object Map2 {
def main(args: Array[String]): Unit = {
//更好的初始化方式
val map1: Map[String, Int] = Map[String, Int](
elems = "a" -> 97,
"b" -> 98,
"c" -> 99)
val map2: Map[String, Int] =map1+("f"->102)
println(map2)
val map3: Map[String, Int] =map1++map2//不重复
println(map3)
//根据key获取值
val v1:Int=map1("a")//一般不使用
println(v1)
val v2=map1.get("a")
println(v2)
//使用较多
val v3=map1.getOrElse("a",100)//如果a不存在,会返回100
println(v3)
}
}

队列和栈
package chapter09
import scala.collection.immutable.Range
import scala.collection.mutable
object Queue1 {
def main(args: Array[String]): Unit = {
val q1:mutable.Queue[Int]=mutable.Queue[Int](10,20,30)
q1.enqueue(40)//可放多个元素<=>q1 +=100
println(q1)
val v=q1.dequeue()//去除前面的元素,并将其返回
println(q1)
println(v)
println("*******")
val s1:mutable.Stack[Int]=mutable.Stack[Int](10,20,30)
s1.push(100)
println(s1)
val p=s1.pop()
println(s1)
println(p)
}
}
/*
队列:
FIFO
提供了两个专门操作队列的元素:
入队
出队
栈:
FILO
专门操作栈的元素
push 入栈
pop 出栈
栈顶和栈底
*/

集合的常用操作(一)
package Collection
object Opt1 {
def main(args: Array[String]): Unit = {
val list1: List[Int] =List(1,2,3,4,5,6,7)
//1、头部元素
println(list1.head)
//2、尾部元素
println(list1.last)
//3、tail:获取去掉第一个元素,剩下的组成的集合:重点
println(list1.tail)
//4、init:去掉最后一个元素,返回剩下的组成的集合
println(list1.init)
//5、长度
println(list1.size)
println(list1.length)
//6、转换成字符串
println(list1.toString())
println(list1.mkString(","))
println(list1.mkString("hello", "-", "?"))//(头部,连接,尾部)
//7、循环遍历(简单)
//8、迭代器
val iterator: Iterator[Int] =list1.iterator
//7.1遍历迭代器(标准方法)
while(iterator.hasNext){
val e:Int=iterator.next()
print(e)
}
println("")
//7.2遍历迭代器2
for(elem<- iterator){
print(elem)
}
println()
//8、是否包含
println(list1.contains(1))
}
}

集合的常用操作(二)
package Collection
import scala.Boolean
import scala.collection.mutable.{ArrayBuffer, ListBuffer}
object Opt2 {
def main(args: Array[String]): Unit = {
val list1:List[Int]=List[Int](1,2,3,4,5,6,0)
//1、反转
println(list1.reverse)
//2、获取前有几个
val list2:List[Int]=list1.take(2)
println(list2)
//3、抛弃前几个
println(list1.drop(2))
//4、获取满足条件的
val list3:List[Int]=list1.takeWhile(x=>x<4)//遇到有不满足条件的就停止
println(list3)//1,2,3
//5、抛弃满足条件的
val list4:List[Int]=list1.dropWhile(x=>x>5)
println(list4)
//6、取后几个
val list5: List[Int] =list1.takeRight(2)
println(list5)
}
}

集合常用操作
(1)获取集合的头head
(2)获取集合的尾(不是头就是尾)tail
(3)集合最后一个数据 last
(4)集合初始数据(不包含最后一个)
(5)反转
(6)取前(后)n个元素
(7)去掉前(后)n个元素
(8)并集
(9)交集
(10)差集
(11)拉链
(12)滑窗
2)案例实操
object TestList {
def main(args: Array[String]): Unit = {
val list1: List[Int] = List(1, 2, 3, 4, 5, 6, 7)
val list2: List[Int] = List(4, 5, 6, 7, 8, 9, 10)
//(1)获取集合的头
println(list1.head)
//(2)获取集合的尾(不是头的就是尾)
println(list1.tail)
//(3)集合最后一个数据
println(list1.last)
//(4)集合初始数据(不包含最后一个)
println(list1.init)
//(5)反转
println(list1.reverse)
//(6)取前(后)n个元素
println(list1.take(3))
println(list1.takeRight(3))
//(7)去掉前(后)n个元素
println(list1.drop(3))
println(list1.dropRight(3))
//(8)并集
println(list1.union(list2))
//(9)交集
println(list1.intersect(list2))
//(10)差集
println(list1.diff(list2))
//(11)拉链 注:如果两个集合的元素个数不相等,那么会将同等数量的数据进行拉链,多余的数据省略不用
println(list1.zip(list2))
//(12)滑窗
list1.sliding(2, 5).foreach(println)
}
}
集合计算初等函数
(1)求和
(2)求乘积
(3)最大值
(4)最小值
(5)排序
2)实操
object TestList {
def main(args: Array[String]): Unit = {
val list: List[Int] = List(1, 5, -3, 4, 2, -7, 6)
//(1)求和
println(list.sum)
//(2)求乘积
println(list.product)
//(3)最大值
println(list.max)
//(4)最小值
println(list.min)
//(5)排序
// (5.1)按照元素大小排序
println(list.sortBy(x => x))
// (5.2)按照元素的绝对值大小排序
println(list.sortBy(x => x.abs))
// (5.3)按元素大小升序排序
println(list.sortWith((x, y) => x < y))
// (5.4)按元素大小降序排序
println(list.sortWith((x, y) => x > y))
}
}
集合计算高等函数
1)过滤
(2)转化/映射
(3)扁平化
(4)扁平化+映射 注:flatMap相当于先进行map操作,在进行flatten操作
(5)分组
(6)简化(规约)
(7)折叠
2)实操
object TestList {
def main(args: Array[String]): Unit = {
val list: List[Int] = List(1, 2, 3, 4, 5, 6, 7, 8, 9)
val nestedList: List[List[Int]] = List(List(1, 2, 3), List(4, 5, 6), List(7, 8, 9))
val wordList: List[String] = List(“hello world”, “hello atguigu”, “hello scala”)
//(1)过滤
println(list.filter(x => x % 2 == 0))
//(2)转化/映射
println(list.map(x => x + 1))
//(3)扁平化
println(nestedList.flatten)
//(4)扁平化+映射 注:flatMap相当于先进行map操作,在进行flatten操作
println(wordList.flatMap(x => x.split(" ")))
//(5)分组
println(list.groupBy(x => x % 2))
}
}
Reduce方法
Reduce简化(规约) :通过指定的逻辑将集合中的数据进行聚合,从而减少数据,最终获取结果。
案例实操
object TestReduce {
def main(args: Array[String]): Unit = {
val list = List(1,2,3,4)
// 将数据两两结合,实现运算规则
val i: Int = list.reduce( (x,y) => x-y )
println("i = " + i)
// 从源码的角度,reduce底层调用的其实就是reduceLeft
//val i1 = list.reduceLeft((x,y) => x-y)
// ((4-3)-2-1) = -2
val i2 = list.reduceRight((x,y) => x-y)
println(i2)
}
}
Fold方法
Fold折叠:化简的一种特殊情况。
(1)案例实操:fold基本使用
object TestFold {
def main(args: Array[String]): Unit = {
val list = List(1,2,3,4)
// fold方法使用了函数柯里化,存在两个参数列表
// 第一个参数列表为 : 零值(初始值)
// 第二个参数列表为:
// fold底层其实为foldLeft
val i = list.foldLeft(1)((x,y)=>x-y)
val i1 = list.foldRight(10)((x,y)=>x-y)
println(i)
println(i1)
}
}
(2)案例实操:两个集合合并
object TestFold {
def main(args: Array[String]): Unit = {
// 两个Map的数据合并
val map1 = mutable.Map("a"->1, "b"->2, "c"->3)
val map2 = mutable.Map("a"->4, "b"->5, "d"->6)
val map3: mutable.Map[String, Int] = map2.foldLeft(map1) {
(map, kv) => {
val k = kv._1
val v = kv._2
map(k) = map.getOrElse(k, 0) + v
map
}
}
println(map3)
}
}
普通WordCount案例
1)需求
单词计数:将集合中出现的相同的单词,进行计数,取计数排名前三的结果
2)需求分析
3)案例实操
object TestWordCount {
def main(args: Array[String]): Unit = {
// 单词计数:将集合中出现的相同的单词,进行计数,取计数排名前三的结果
val stringList = List("Hello Scala Hbase kafka", "Hello Scala Hbase", "Hello Scala", "Hello")
// 1) 将每一个字符串转换成一个一个单词
val wordList: List[String] = stringList.flatMap(str=>str.split(" "))
//println(wordList)
// 2) 将相同的单词放置在一起
val wordToWordsMap: Map[String, List[String]] = wordList.groupBy(word=>word)
//println(wordToWordsMap)
// 3) 对相同的单词进行计数
// (word, list) => (word, count)
val wordToCountMap: Map[String, Int] = wordToWordsMap.map(tuple=>(tuple._1, tuple._2.size))
// 4) 对计数完成后的结果进行排序(降序)
val sortList: List[(String, Int)] = wordToCountMap.toList.sortWith {
(left, right) => {
left._2 > right._2
}
}
// 5) 对排序后的结果取前3名
val resultList: List[(String, Int)] = sortList.take(3)
println(resultList)
}
}
WordCount案例
1)方式一
2)案例实操
object TestWordCount {
def main(args: Array[String]): Unit = {
// 第一种方式(不通用)
val tupleList = List(("Hello Scala Spark World ", 4), ("Hello Scala Spark", 3), ("Hello Scala", 2), ("Hello", 1))
val stringList: List[String] = tupleList.map(t=>(t._1 + " ") * t._2)
//val words: List[String] = stringList.flatMap(s=>s.split(" "))
val words: List[String] = stringList.flatMap(_.split(" "))
//在map中,如果传进来什么就返回什么,不要用_省略
val groupMap: Map[String, List[String]] = words.groupBy(word=>word)
//val groupMap: Map[String, List[String]] = words.groupBy(_)
// (word, list) => (word, count)
val wordToCount: Map[String, Int] = groupMap.map(t=>(t._1, t._2.size))
val wordCountList: List[(String, Int)] = wordToCount.toList.sortWith {
(left, right) => {
left._2 > right._2
}
}.take(3)
//tupleList.map(t=>(t._1 + " ") * t._2).flatMap(_.split(" ")).groupBy(word=>word).map(t=>(t._1, t._2.size))
println(wordCountList)
}
}
3)方式二
4)案例实操
object TestWordCount {
def main(args: Array[String]): Unit = {
val tuples = List((“Hello Scala Spark World”, 4), (“Hello Scala Spark”, 3), (“Hello Scala”, 2), (“Hello”, 1))
// (Hello,4),(Scala,4),(Spark,4),(World,4)
// (Hello,3),(Scala,3),(Spark,3)
// (Hello,2),(Scala,2)
// (Hello,1)
val wordToCountList: List[(String, Int)] = tuples.flatMap {
t => {
val strings: Array[String] = t._1.split(" ")
strings.map(word => (word, t._2))
}
}
// Hello, List((Hello,4), (Hello,3), (Hello,2), (Hello,1))
// Scala, List((Scala,4), (Scala,3), (Scala,2)
// Spark, List((Spark,4), (Spark,3)
// Word, List((Word,4))
val wordToTupleMap: Map[String, List[(String, Int)]] = wordToCountList.groupBy(t=>t._1)
val stringToInts: Map[String, List[Int]] = wordToTupleMap.mapValues {
datas => datas.map(t => t._2)
}
stringToInts
/*
val wordToCountMap: Map[String, List[Int]] = wordToTupleMap.map {
t => {
(t._1, t._2.map(t1 => t1._2))
}
}
val wordToTotalCountMap: Map[String, Int] = wordToCountMap.map(t=>(t._1, t._2.sum))
println(wordToTotalCountMap)
*/
}
}
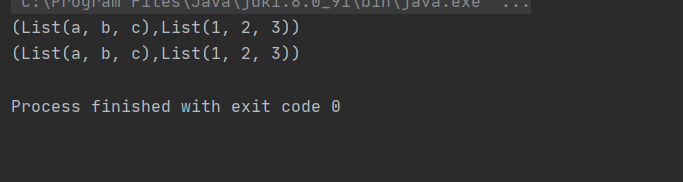
拉链
package Collection
object Zip1 {
def main(args: Array[String]): Unit = {
val list1:List[Int]=List(1,2,3,4,5,6,7)
val list2:List[Int]=List(7,8,9,10,11)
//1、多余的会被抛弃
val list3:List[(Int,Int)]=list1.zip(list2)
println(list3)
//2、多余的使用默认值来进行匹配
val list4:List[(Int,Int)]=list1.zipAll(list2,-1,-2)
println(list4)
//3、和自己的索引进行zip
val list5:List[(Int,Int)]=list1.zipWithIndex
println(list5)
}
}

package Collection
object Zip2 {
def main(args: Array[String]): Unit = {
val list: List[(String, Int)] = List("a" -> 1, "b" -> 2, "c" -> 3)
//list中存储的是二维的元组的时候,才能使用unzip
val t: (List[String], List[Int]) = list.unzip
println(t)
val map=Map[String,Int]("a" -> 1, "b" -> 2, "c" -> 3)
val m=map.unzip
println(m)
}
}
滑窗
package Collection
object Sliding1 {
def main(args: Array[String]): Unit = {
val list1=List(1,2,3,4,5,6)
//滑窗
val it: Iterator[List[Int]] = list1.sliding(3)//(3,2)一次滑三个
for(elem<- it){
println(elem)
}
}
}

GroupBy
package Collection
object GroupByDemo1 {
def main(args: Array[String]): Unit = {
//分组
val list1:List[Int]=List(1,2,3,4)
val map: Map[String, List[Int]] = list1.groupBy(x => if(x%2==0)"偶数" else "奇数")
println(map)
val list2: List[String] =List("hello","hello","word")
val wordMap: Map[String, List[String]] = list2.groupBy(x => x)
println(wordMap)
//对wordMap做一个结构调整
val wordCount = wordMap.map(kv => {
(kv._1, kv._2.size)
})
val result = wordCount.toList.sortBy(-_._2).take(3)
println(result)
}
}

部分应用函数
object PartFunDemo {
def main(args: Array[String]): Unit = {
math.pow(3, 2)
val square: Double => Double = math.pow(_, 2) //部分应用函数
println(square(10))
}
}
reduce(化简)
object ReduceDemo1 {
def main(args: Array[String]): Unit = {
//聚合操作
val list1=List(1,2,3,4,5)
val result:Int=list1.reduce((x,y)=>x+y)//list1.reduce(_+_)
println(result)
//list1.reduceLeft(_+_)从左往右聚合
}
}
Fold
object FoldDemo1 {
def main(args: Array[String]): Unit = {
val list1: List[Int] =List(1,2,3,4,5)
val result: String =list1.foldLeft("")((x,y)=>x+y)
println(result)
val str: String = list1.foldRight("a")((x, y) => x + y)
println(str)
//装逼代码
val i: Int = list1./:(0)(_ + _)
println(i)
}
}
排序
继承Orded或Java中comparable
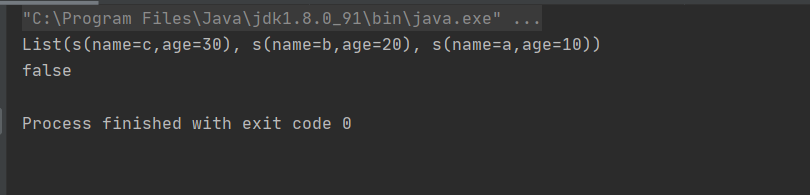
package Sort
object Order {
def main(args: Array[String]): Unit = {
val user1:User=new User("a",10)
val user2:User=new User("b",20)
val user3:User=new User("c",30)
val list=List(user1,user2,user3)
println(list.sorted)
println(user1<user2)
}
class User(val name:String,val age:Int)extends Ordered[User]{
override def compare(that: User): Int = -(this.age-that.age)
override def toString: String = s"s(name=$name,age=$age)"
}
}
使用比较器Ordering
object Sort1 {
def main(args: Array[String]): Unit = {
val list1:List[Int]=List(1,4,3,6,5,2)
println(list1.sorted)
println(list1.sorted.reverse)
val list2=List(new User(10,"a"),new User(20,"b"),new User(15,"c"))
println(list2.sorted)
println(list1.sorted(Ordering.Int.reverse))//对list进行排序
println(list2.sorted(new Ordering[User] {
override def compare(x: User, y: User): Int = x.compareTo(y)
}))
}
}
class User(val age:Int,val name:String) extends Comparable[User]{
override def compareTo(o: User): Int= - this.name.compareTo(o.name)
override def toString: String = s"(age=$age,name=$name)"
}

sorted
默认是自然排序(升序)
1、让排序的类型有自己的功能
Order 就是Java中的Comparable
2、找一个第三方的比较器
Ordering 就是Java中Comparator
一般用Ordering排序较灵活
sortBy
不需要提供任何的逻辑代码,只需要指定排序的指标
sortWith
传递一个函数,然后,在函数里写比较规则
sortBy
package Sort
class Person(val age:Int,val name:String){
override def toString: String = s"[name=$name,age=$age]"
}
object Sort2 {
def main(args: Array[String]): Unit = {
val list1:List[Int]=List(1,4,5,3,7,2,6)
val list2: List[Int] = list1.sortBy(x => x)
println(list2)
val list3=List("hello","word","c","a","b")
println(list3.sortBy(x => x))
//按照字符串的长度排序
println(list3.sortBy(x => x.length))
println(list3.sortBy(x => x.length)(Ordering.Int.reverse))//反转
//先按照长度排,长度相等的时用字母表的升序排列
//多个指标,就放在元组中返回
println(list3.sortBy(x => (x.length, x)))
//先按照长度降序排,长度相等时用字母表的升序排
println(list3.sortBy(x=>(x.length,x))(Ordering.Tuple2(Ordering.Int.reverse,Ordering.String)))
val list=List(new Person(3,"a"),new Person(2,"b"),new Person(3,"c"))
//年龄升序,年龄相等时姓名升序
println(list.sortBy(user => (user.age, user.name)))
}
}

sortWith
package Sort
object Sort3 {
def main(args: Array[String]): Unit = {
val list =List(1,2,3,4,5,6)
println(list.sortWith((x, y) => x > y))
//返回true:第一个排序在前
println(list.sortWith(_ > _))
}
}

模式匹配
(1)如果所有case都不匹配,那么会执行case _ 分支,类似于Java中default语句,若没有case _ 分支,那 么会抛出MatchError。
(2)每个case中,不用break语句,自动中断case。
(3)match case语句可以匹配任何类型,而不只是字面量。
(4)=> 后面的代码块,是作为一个整体执行,可以使用{}括起来,也可以不括。
object PatternDemo1 {
def main(args: Array[String]): Unit = {
val a=10
val b=20
val op=StdIn.readLine("请输入一运算操作符:")
val r=op match {
case "+" =>
println(a+b)
case "-"=>
println(a-b)
case "*"=>
println(a*b)
case "/"=>
println(a/b)
//其它情况
//如果没有该判断,会抛异常
case _=>
println("输入的运算符不正确")
-1
}
println(r)
}
}
package PatternDemo
object PatternDemo2 {
def main(args: Array[String]): Unit = {
var a=1
a match {
case aa =>println(aa)
//case 语句新声明的变量
case 20=>println(20)
}
val Ba =10;
val aA=20;
a=20
a match{
case a=>println(a)
case Ba=>println(Ba)
case aA=>println(aA)//此时的aA是一个变量,不是前面定义的aA
}
}
}
/*
case aa
aa是新声明的,只能在这个case内使用
case Ba
变量是大写字母开头,Scala任务这个变量是一个常量,必须已经定义好的常量
*/

object PatternDemo3 {
def main(args: Array[String]): Unit = {
val a:Any=10
if (a.isInstanceOf[Int]) {
a.asInstanceOf[Int]+10
}
a match {
case a:Int if a>=10 =>println(a+10)
case s:String=>println(s.toUpperCase())
case b:Boolean=>println(b)
case _=>println("类型不匹配")
}
}
}
object PatternDemo4 {
//泛型匹配
def main(args: Array[String]): Unit = {
val arr=Array[Int](1,2)
arr match {
case a:Array[Int]=>println("Array[Int]")
case _ =>println("类型不匹配")
}
val arr1=List[String]("a","3")
//无法匹配
arr1 match {
case a:List[Int]=>println("List[Int]")//输出List[Int]
}
}
}
数组匹配
object PatternDemo5 {
def main(args: Array[String]): Unit = {
//数组匹配
val arr=Array(1,2,3,4)
arr match {
//case Array(1,2,_,_)=>println("Array(1,2,_,_)")
//case Array(1,2,a,b)=>println(a+" "+b)
//case Array(a,b,c,d)=>println(a+" "+b+" "+c+" "+d)//只要是长度为四的数组就能匹配
//case Array(1,2,_*)=>println("Array(1,2,_*)")//匹配不管长度
case Array(1,2,abc@_*)=>println(abc.toList)//获得后面的数据
}
}
}
元组匹配
object PatternDemo6 {
//元组的匹配
def main(args: Array[String]): Unit = {
val t=("list1",20)
t match {
case (a,b)=>println(a)
//case (a:String,b)=>println(a)加限制条件
}
}
}
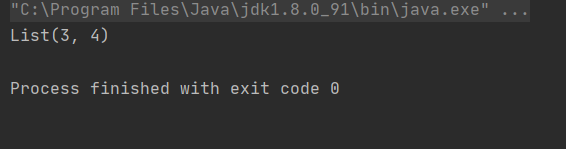
list匹配
object PatternDemo7 {
//List 匹配
//类似于数组匹配
def main(args: Array[String]): Unit = {
val list=List(1,2,3,4,5)
list match {
// case List(1,2,c,d)=>println(s"List(1,2,$c,$d)")
// case List(10,abc@*_)=>println(abc)
// case a::b::c::d::Nil=>println(a)
case a::rest=>println(rest)//与前面的case List(10,abc@*_)=>println(abc)等价
}
}
}
对象匹配(较复杂)
class People(val age:Int,val name:String)
object People{
def apply(age: Int, name: String): People = new People(age, name)
def unapply(p: People): Option[(Int, String)] =if(p!=null){
Some(p.age,p.name)
}else{
None
}
}
object PatternDemo8 {
def main(args: Array[String]): Unit = {
val people =new People(10,"Jack")
people match {
case People(age,name)=>println(age)
case _=>println("不匹配")
}
}
}
/*
case People(age name)=>
回去调用People伴生对象的unapply
*/
Option(对象匹配用到Option)
object OptionDemo {
def main(args: Array[String]): Unit = {
// val op:Option[Int]=get
// if (!op.isEmpty) {
// println(op.get)
// }
val op:Option[Double] = sqrt(9)
if (op.isDefined) {
println(op.get)
}else{
println("没有平方根")
}
}
def sqrt(n:Double)={
if(n>0)Some(math.sqrt(n))
else None
}
def get:Option[Int]=Some(10)
}
序列匹配
object MyArray {
def unapplySeq(s: String) = {
if (s != null) Some(s.split(",").toList)
else None
}
}
object ObjMath {
//序列匹配
def main(args: Array[String]): Unit = {
val names = "lisi,zhangsan,wangwu,zhiling,fengjie"
names match {
case MyArray(a, b, rest@_*) =>
println(a)
println(b)
println(rest)
}
}
}
偏函数
object Pattern2 {
def main(args: Array[String]): Unit = {
val list=List(10,20,1,"aa",false)
val f=new PartialFunction[Any,Int] {
//只对返回值是true是true的那些元素进行处理,是false的跳过
override def isDefinedAt(x: Any): Boolean = x.isInstanceOf[Int]
//是true的时候,交给apply进行处理
override def apply(v1: Any): Int = v1.asInstanceOf[Int]
}
println(list.filter(_.isInstanceOf[Int]))
val a = list.collect(f)
println(a)
}
}

异常处理
package PatternDemo
import java.io.{FileInputStream, IOException}
import scala.io.StdIn
object ExceptionDemo1 {
def main(args: Array[String]): Unit = {
// val r:Int=StdIn.readInt()
// if(r == 0)throw new ArithmeticException("除数不能为0")
try{
var i=1/0
new FileInputStream("aa")
}catch{
case e:ArithmeticException=>
println("发生算术异常")
case e:RuntimeException=>
println("运行时异常")
case _=>println("发生异常")
}finally {
println("hello")
}
println("haha")
try{
foo()
}catch{
case e:IOException=>
println("IOException")
case e: RuntimeException =>
println("RuntimeException")
}
}
@throws(classOf[RuntimeException])
@throws(classOf[IOException])
def foo(): Unit ={
}
}
/*
在Scala中,不强制要求必须异常处理
*/
java和Scala的互转
package JavaScala
import java.util
object JavaScala {
def main(args: Array[String]): Unit = {
val list=new util.ArrayList[Int]()
list.add(1)
list.add(2)
list.add(3)
//java集合转成scala集合
//这些隐式转换可以完成Scala的集合和Java的互转
//我们会调用Java的一些类库,需要的参数一般是Java的集合,从Java的Scala
import scala.collection.JavaConversions._
for (e<- list){
println(e)
}
list += 4
list.add(5)//两种添加方法都可用
for(elem<-list){
println(elem)
}
}
}
/*
java 的集合都是可变的
Scala中的集合有可变的也有不可变的
*/















 267
267











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









