







目录
数据结构
- 数据结构是指相互之间存在着一种或多种关系的数据元素的集合和该集合中数据元素之间的关系组成。
- 简单来说,数据结构就是设计数据以何种方式组织并存储在计算机中
- 程序 = 数据结构+算法
百度百科解释
数据结构(data structure)是带有结构特性的数据元素的集合,它研究的是数据的逻辑结构和数据的物理结构以及它们之间的相互关系,并对这种结构定义相适应的运算,设计出相应的算法,并确保经过这些运算以后所得到的新结构仍保持原来的结构类型。简而言之,数据结构是相互之间存在一种或多种特定关系的数据元素的集合,即带“结构”的数据元素的集合。“结构”就是指数据元素之间存在的关系,分为逻辑结构和存储结构。
数据结构的分类 (逻辑结构)
- 集合:数据结构中的元素之间除了“同属一个集合” 的相互关系外,别无其他关系
- 线性结构:数据结构中的元素存在一对一的相互关系
- 树结构:数据结构中的元素存在一对多的相互关系
- 图结构:数据结构中的元素存在多对多的相互关系
栈
栈(stack)又名堆栈,它是一种运算受限的线性表。限定仅在表尾进行插入和删除操作的线性表。这一端被称为栈顶,相对地,把另一端称为栈底。向一个栈插入新元素又称作进栈、入栈或压栈,它是把新元素放到栈顶元素的上面,使之成为新的栈顶元素;从一个栈删除元素又称作出栈或退栈,它是把栈顶元素删除掉,使其相邻的元素成为新的栈顶元素。
- 栈(Stack)是一个数据集合,可以理解为只能在一端进行插入或删除操作得列表
- 栈的特点:后进先出 LIFO(Last-In,First-Out)
- 栈的概念:栈顶、栈底
- 栈的基本操作
- 进栈(压栈):push
- 出栈:pop
- 取栈顶:gettop
- 使用一般的列表结构即可实现栈
- 进栈:li.append
- 出栈:li.pop
- 取栈顶:li[-1]

栈的具体python代码实现
class Stack:
def __init__(self): # 初始化定义栈
self.stack = []
def push(self,element): # 进栈,后进,直接在最后append
self.stack.append(element)
def pop(self): # 出栈,后进先出,直接将最后的元素pop删除
return self.stack.pop()
def get_top(self):
if len(self.stack)>0:
return self.stack[-1]
else:
return None
def is_empty(self): # 判断是否为空栈
return len(self.stack) == 0
# 测试栈的建立
stack = Stack()
stack.push(1)
stack.push(2)
stack.push(3)
print(stack.pop())栈的应用 —— 括号匹配问题
括号匹配问题:给定一个字符串,其中包含小括号、中括号、大括号,求该字符串中的括号是否匹配。
- ([{()}]) 匹配
- []( 不匹配
- [(]) 不匹配
python代码如下
def brace_match(s):
# 创建三种括号对应匹配的字典
match = { '}':'{', ']':'[', ')':'(' }
stack = Stack()
for ch in s:
if ch in { '(','[','{' }:
# 此处进栈的都是左括号
stack.push(ch)
else:
if stack.is_empty():
return False
elif stack.get_top() == match[ch]:
# 将栈顶(即栈中的左括号) 和右括号相匹配
# 如果是同一类,则删除栈中匹配的左括号,否则return False
stack.pop()
else:
return False
# 如果栈空,则说明全部匹配完成 return True,否则则说明还有未匹配的左括号,匹配失败 return False
if stack.is_empty():
return True
else:
return False
# 可自己随意测试一下
print(brace_match('()[][{}]'))队列(Queue)
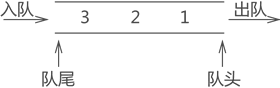
队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。
- 队列是一个数据集合,仅允许在列表的一段进行插入,另一端进行删除。
- 进行插入的一端称为队尾(rear),插入动作称为进队或入队
- 进行删除的一段称为队头(front),删除动作成为出队
- 队列的性质:先进先出(Frist-in,First-out)
队列能否用简单的列表实现?为什么?

不能用简单的列表实现,解释如下:
如果a要出队,如果直接使用pop删除a,其余元素b、c、d、e就要依次挪到前面来,时间复杂度为O(n)太高,一般栈的入栈和出栈都是O(1);那我们使用将 front+1 的方法,即把 front 指向b元素,如图(c)所示,当出队3次后 front 指向e时,这时候如果要进队,rear已经没有位置可以指向和增加了,故这种用简单的列表实现的方式不可取。
我们使用一种新的实现方式:环形队列

环形队列:当队尾(队首)指针 front == Maxsize(队列长度) - 1时,再前进一个位置就自动到0
大家不太好理解的话我们就举有限队列的例子,上图是一个长度12的环形队列,需要解决的问题:见第五个环形图,怎么让L进队,rear从11变为0 —— 取余
每次进队 rear+1(改为每次+1再对12取余数,1+1/12=2,2+1/12=3,11+1/12=0) 出队 front+1一样
- 队首指针前进1: front = (front +1) % MaxSize
- 队尾指针前进1: rear = (rear + 1) % MaxSize
- 队空条件: rear == front
- 队满条件: (rear +1) % MaxSize == front
最后一个环形结构为队满,说明队满的时候不能令rear==front,因为这是队空的条件。为了区分,我们会在 rear 和 front 之间要牺牲一块空间。同时当front 指向0,rear指向11时,也是队满,即满足(rear +1) % MaxSize == front
python代码实现队列
class Queue():
def __init__(self,size=100): # 默认队列size=100,可自定义
# _ 的含义若有不知道的本人博客也有写
self.queue = [0 for _ in range(size)]
self.size = size
self.rear = 0 # 队尾指针
self.front = 0 # 队首指针
def push(self,element): # 入队,先将rear+1,再将元素写到rear+1的位置
if not self.is_filled():
self.rear = (self.rear + 1) % self.size
self.queue[self.rear] = element
else:
raise IndexError("Queue is filled!")
def pop(self): # 出队,先进先出
if not self.is_empty():
self.front = (self.front + 1) % self.size
return self.queue[self.front] # 返回新的位置上的front
else:
raise IndexError("Queue is empty!")
# 判断队空
def is_empty(self):
return self.rear == self.front
# 判断队满
def is_filled(self):
return (self.rear + 1) % self.size == self.front
q = Queue(5)
# 因为会留一个空,所以只能插入n-1
for i in range(4):
q.push(i)
print(q.pop())
q.push(6)双向队列

利用python队列内置模块实现双向队列

具体代码实现如下
from collections import deque
q = deque()
q.append(6) # 队尾进队
print(q.popleft()) # 队首出队
q = deque([1,2,3]) # 建立含有1,2,3的队列而不是空队列
q = deque([1,2,3,4,5],5) # 设置最大长度为 5,队满后 1 出队
# 双向队列
q.appendleft(2) # 队首进队
print(q.pop()) # 队尾出队
# 读取后几行文件里的内容的代码
def tail(n):
with open('test.txt','r') as f:
q = deque(f,n)
return q
for line in tail(5):
print(line,end='')双向队列可以实现Linux类似tail的命令,即取文件后x行,代码如上所示
队列的应用 —— 迷宫问题

使用队列存储当前节点即像 广度优先搜索BFS,即
在面临一个路口时,把所有的岔路口都记下来,然后选择其中一个进入,然后将它的分路情况记录下来,然后再返回来进入另外一个岔路,并重复这样的操作

具体python代码实现迷宫问题
matrix = [
[1,1,1,1,1,1,1,1,1,1],
[1,0,0,1,0,0,0,1,0,1],
[1,0,0,1,0,0,0,1,0,1],
[1,0,0,0,0,1,1,0,0,1],
[1,0,1,1,1,0,0,0,0,1],
[1,0,0,0,1,0,0,0,0,1],
[1,0,1,0,0,0,1,0,0,1],
[1,0,1,1,1,0,1,1,0,1],
[1,1,0,0,0,0,0,0,0,1],
[1,1,1,1,1,1,1,1,1,1]
]
# 存储前后走右四条路
dirs = [
lambda x,y:(x+1,y),
lambda x,y:(x-1,y),
lambda x,y:(x,y-1),
lambda x,y:(x,y+1)
]
def print_r(path):
curNode = path[-1]
realpath = []
while curNode[2] != -1: # 除了起点以外
realpath.append((curNode[0],curNode[1])) # 这样写也可以 --> realpath.append(curNode[0:2])
curNode = path[curNode[2]]
# 当 = -1跳出循环后
realpath.append(curNode[0:2]) # 把起点放进去
realpath.reverse()
for node in realpath:
print(node)
def maze_path_queue(x1,y1,x2,y2):
queue = deque()
queue.append((x1,y1,-1)) # 最开始起点即标记为-1,无其他含义
path = []
while len(queue) > 0:
curNode = queue.popleft() # 出队并且存入
path.append(curNode)
if curNode[0] == x2 and curNode[1] == y2:
# 终点
print_r(path)
return True
for dir in dirs:
nextNode = dir(curNode[0],curNode[1])
if matrix[nextNode[0]][nextNode[1]] == 0:
queue.append((nextNode[0],nextNode[1],len(path) - 1)) # 后续节点进队,记录哪个节点带它进队(path最后一个元素的下标)
matrix[nextNode[0]][nextNode[1]] = 2 # 标记已经走过
# 不需break,四个方向都要找
else:
print("没有路!")
return False
maze_path_queue(1,1,8,8)迷宫问题也可以用栈来写,即深度优先算法DFS回溯法,这里不再赘述了。
深度优先搜索的步骤分为 1.递归下去 2.回溯上来。顾名思义,深度优先,则是以深度为准则,先一条路走到底,直到达到目标。这里称之为递归下去。
否则既没有达到目标又无路可走了,那么则退回到上一步的状态,走其他路。这便是回溯上来。
以上是本人看某站 数据结构与算法课程 最近总结学习的一些内容,求互动啊!可以一起学习、分享经验呀!















 381
381











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









