






1 B+树结构 与B树、hash结构、二叉树区别
下面直接列出三种树的数据结构
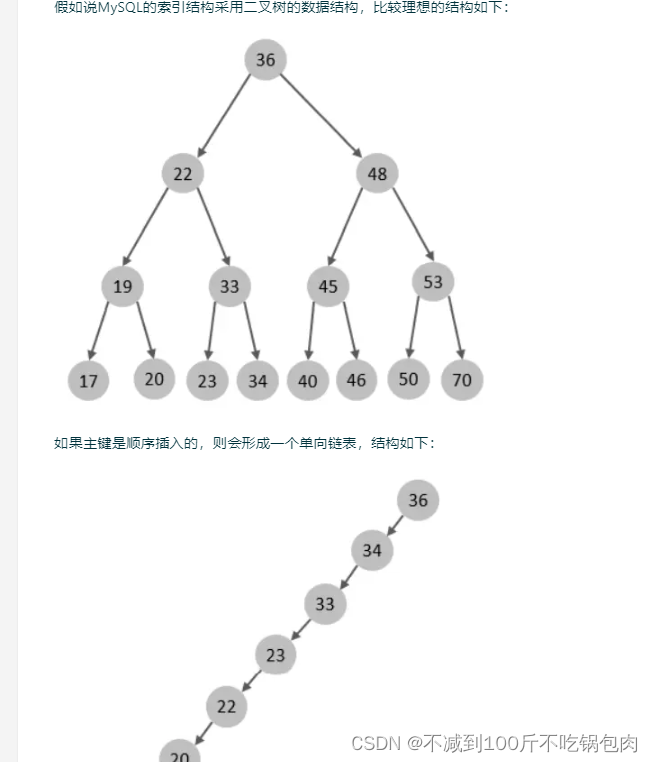
二叉树

B树
5阶的B树,每一个节点最多存储4个key,对应5个指针。
一旦节点存储的key数量到达5,就会裂变,中间元素向上分裂。
在B树中,非叶子节点和叶子节点都会存放数据
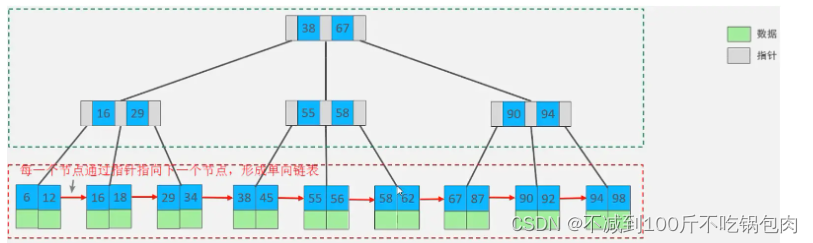
B+树
所有的数据都会出现在叶子节点。
叶子节点形成一个单向链表。
非叶子节点仅仅起到索引数据作用,具体的数据都是在叶子节点存放的
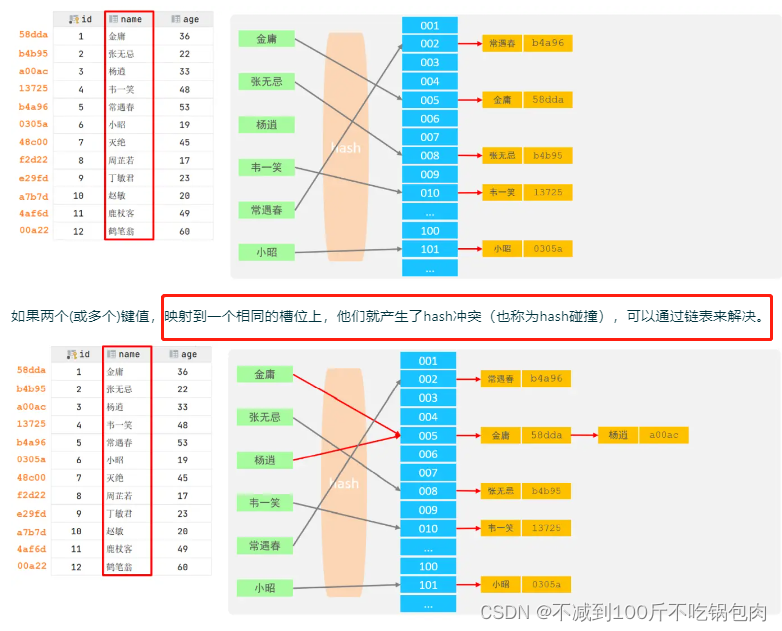
hash树
Hash索引只能用于对等比较(=,in),不支持范围查询(between,>,< ,…)
无法利用索引完成排序操作
查询效率高,通常(不存在hash冲突的情况)只需要一次检索就可以了,效率通常要高于B+tree索引
1.1为什么InnoDB存储引擎选择使用B+tree索引结构?
相对于二叉树,层级更少,搜索效率高;
对于B-tree,无论是叶子节点还是非叶子节点,都会保存数据,这样导致一页中存储的键值减少,指针跟着减少,要同样保存大量数据,只能增加树的高度,导致性能降低;
相对Hash索引,B+tree支持范围匹配及排序操作;
2 索引分类
根据类型:
主键索引、唯一索引、常规索引、全文索引。

根据储存数据结构: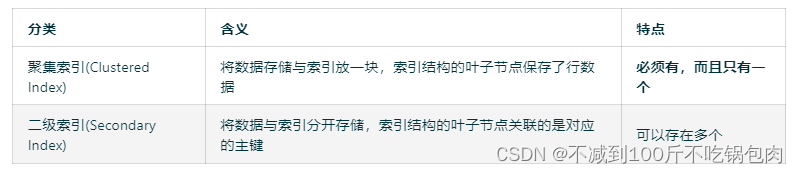
3 sql性能分析
3.1 执行频率
MySQL 客户端连接成功后,通过 show [session|global] status 命令可以提供服务器状态信息。通过如下指令,可以查看当前数据库的INSERT、UPDATE、DELETE、SELECT的访问频次:
-- session 是查看当前会话 ;
-- global 是查询全局数据 ;
SHOW GLOBAL STATUS LIKE 'Com_______';
3.2 慢查询日志
MySQL的慢查询日志默认没有开启,我们可以查看一下系统变量 slow_query_log。
mysql> show variables like 'slow_query_log';
+----------------+-------+
| Variable_name | Value |
+----------------+-------+
| slow_query_log | OFF |
+----------------+-------+
1 row in set (0.01 sec)
开启
# 开启MySQL慢日志查询开关
slow_query_log=1
# 设置慢日志的时间为2秒,SQL语句执行时间超过2秒,就会视为慢查询,记录慢查询日志
long_query_time=2
慢查询日志中,只会记录执行时间超多我们预设时间(2s)的SQL,执行较快的SQL是不会记录的
3.3 explain语法
mysql> EXPLAIN select * from tb_user where id = 1;
+----+-------------+---------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | tb_user | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |
+----+-------------+---------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
重点看possible_keys 、key、key_len 、Extra
3.4 profile的使用
show profiles 能够在做SQL优化时帮助我们了解时间都耗费到哪里去了。通过have_profiling参数,能够看到当前MySQL是否支持profile操作:
mysql> SELECT @@have_profiling;
+------------------+
| @@have_profiling |
+------------------+
| YES |
+------------------+
1 row in set, 1 warning (0.00 sec)
mysql> select @@profiling;
+-------------+
| @@profiling |
+-------------+
| 0 |
+-------------+
1 row in set, 1 warning (0.00 sec)
可以看到,当前MySQL是支持 profile操作的,但是开关是关闭的。可以通过set语句在session/global级别开启profiling:
SET profiling = 1;
开关已经打开了,接下来,我们所执行的SQL语句,都会被MySQL记录,并记录执行时间消耗到哪儿去了。 我们直接执行如下的SQL语句:执行一系列的业务SQL的操作,然后通过如下指令查看指令的执行耗时:
select * from tb_user;
select * from tb_user where id = 1;
select * from tb_user where name = '白起';
select count(*) from tb_sku;
-- 查看每一条SQL的耗时基本情况
show profiles;
-- 查看指定query_id的SQL语句各个阶段的耗时情况
show profile for query query_id;
-- 查看指定query_id的SQL语句CPU的使用情况
show profile cpu for query query_id;
查看每一条SQL的耗时情况:
mysql> show profiles;
+----------+------------+---------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+---------------------------------------------+
| 1 | 0.00035925 | select @@profiling |
| 2 | 0.00047950 | select * from tb_user |
| 3 | 0.00028925 | select * from tb_user where id = 1 |
| 4 | 0.00047600 | select * from tb_user where name = '白起' |
| 5 | 0.00074075 | select count(*) from tb_sku |
+----------+------------+---------------------------------------------+
5 rows in set, 1 warning (0.00 sec)
查看指定SQL各个阶段的耗时情况 :
mysql> show profile for query 4;
+--------------------------------+----------+
| Status | Duration |
+--------------------------------+----------+
| starting | 0.000089 |
| Executing hook on transaction | 0.000006 |
| starting | 0.000007 |
| checking permissions | 0.000005 |
| Opening tables | 0.000032 |
| init | 0.000004 |
| System lock | 0.000007 |
| optimizing | 0.000061 |
| statistics | 0.000182 |
| preparing | 0.000015 |
| executing | 0.000030 |
| end | 0.000003 |
| query end | 0.000003 |
| waiting for handler commit | 0.000006 |
| closing tables | 0.000005 |
| freeing items | 0.000010 |
| cleaning up | 0.000011 |
+--------------------------------+----------+
17 rows in set, 1 warning (0.00 sec)
查看指定query_id的SQL语句CPU的使用情况:
mysql> show profile cpu for query 4;
4 索引的使用
4.1 最左前缀法则
在 tb_user 表中,有一个联合索引,这个联合索引涉及到三个字段,顺序分别为:profession,age,status。
对于最左前缀法则指的是,查询时,最左变的列,也就是profession必须存在(与profession排在后面无关),否则索引全部失效。而且中间不能跳过某一列,否则该列后面的字段索引将失效。
4.2 联合索引
联合索引中,出现范围查询(>,<),范围查询右侧的列索引失效。
具体原因请看添加链接描述
4.3 索引失效的几种场景
我觉得最重要的还是最左前缀法则
1、不要在索引列上进行运算操作, 索引将失效
2、字符串类型字段使用时,不加引号,索引将失效
3、如果仅仅是尾部模糊匹配,索引不会失效。如果是头部模糊匹配,索引失效
4、用or分割开的条件, 如果or前的条件中的列有索引,而后面的列中没有索引,那么涉及的索引都不会被用到
5如果MySQL评估使用索引比全表更慢,则不使用索引。
2、
explain select * from tb_user where profession = '软件工程' and age = 31 and status = '0';
explain select * from tb_user where profession = '软件工程' and age = 31 and status = 0;失效
5、explain select * from tb_user where profession is null;数据全是unnul时有效
explain select * from tb_user where profession is not null;
5 覆盖索引和前缀索引
前者是返回的值都在索引数据结构中,我们可以把需要返回的值,或者是需要回表查询的值创建索引,这样这个查询语句会使用这个覆盖索引
前缀索引是,如果字段很长,我们可以取前几个字符来作为索引
6 索引的设计原理
1、在经常查询,但是少改动的的列中创建索引
2、where、group by 、oder by这些操作的字段加索引
3、尽量使用联合索引,因为联合索引大部分都是覆盖索引,节省空间,避免回表,增加查询效率
4、减少索引数量,太多会影响增删改的效率
5、太长的字段用前缀索引
6、区分度高的创建索引















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









