






摘要
本周对比了《Paint by Example》和《IP-Adapter》两篇文章,分析它们在图像编辑与扩散模型中的创新设计。《Paint by Example》提出了图像示例引导的编辑任务,通过引入信息瓶颈和自监督策略,提升了编辑的自然性和准确性;《IP-Adapter》则以轻量级模块,实现了图像提示与文本提示在扩散模型中的无缝结合,兼容ControlNet等结构控制工具。在此基础上,结合两者优势,思考了在时尚图像编辑领域的应用方向。同时,还学习了《AnyDoor: Zero-shot Object-level Image Customization》论文,了解了通过ID和细节特征提取,支持零样本下灵活的目标编辑,为未来的服装换装、虚拟试穿等应用提供了重要思路。
abstract
This week, two articles, “Paint by Example” and “IP-Adapter”, were compared to analyze their innovative designs in image editing and diffusion models. “Paint by Example” proposes an editing task guided by image examples. By introducing information bottlenecks and self-supervised strategies, it enhances the naturalness and accuracy of editing. “IP-Adapter” realizes the seamless integration of image prompts and text prompts in the diffusion model with a lightweight module and is compatible with structural control tools such as ControlNet. On this basis, combining the advantages of both, the application directions in the field of fashion image editing were considered. Meanwhile, the paper “AnyDoor: Zero-shot Object-level Image Customization” was also studied, and it was understood that through ID and detail feature extraction, flexible target editing under zero-shot conditions is supported, providing important ideas for future applications such as clothing dress-up and virtual try-on.
1.两篇文章的创新点
Paint by Example
- 提出图像示例引导的语义图像合成任务,填补了text-to-image之外的编辑方式;
- 引入信息瓶颈机制防止trival copy;
- 利用自监督训练方式与随机mask配合,有效解决了train-test domain gap;
- 可调用mask形状与相似度控制机制,增强用户编辑自由度。
IP-Adapter
- 创新性提出解耦交叉注意力机制,分别处理图像和文本特征,克服了传统adapter融合效果差的问题;
- 模块极轻量,支持plug-and-play;
- 支持任意的衍生扩散模型结合,保持风格一致性;
- 完美兼容ControlNet等结构控制工具,支持多模态生成。
2.在方法上的差异
| 方面 | Paint by Example | IP-Adapter |
|---|---|---|
| 条件输入 | 图像 + mask | 图像 + 可选文本 |
| 架构基础 | Diffusion model(Stable Diffusion) | 基于Stable Diffusion |
| 模型修改 | 利用CLIP图像嵌入,仅用class token并配合信息瓶颈设计 | 引入 解耦交叉注意力(Decoupled Cross-Attention) 模块处理图像特征,原模型冻结 |
| 训练方式 | 自监督(利用图像自身合成“参考-源”对) | 使用图文对训练,仅训练22M参数的小模块 |
| 控制能力 | 提供mask形状控制、相似度控制(classifier-free guidance) | 可控制图像与文本融合程度,可与结构控制模块(如ControlNet)组合 |
| 输出特性 | 单步推理、高质量、可调编辑区域 | 多模态输入,风格多样,可在多模型上泛化应用 |
3.个人思考
通过上述这两篇论文,想利用这两个方法结合到自己的方向上,以下是个人的思考:
利用Paint by Example 的优势
- 服装区域编辑控制可以借助其任意形状mask机制;
- 使用信息瓶颈机制和自监督训练策略,能帮助提升在自己的模型上无监督或少标注数据下的学习效果;
- 对于通用分割模型协同策略,可以借鉴source image+examplar image构成方式,实现风格转移与内容融合。
融合IP-Adapter的优势
4. IP-Adapter的模块化适配策略可以集成在扩散模型编辑管线中,不破坏原模型;
5. 解耦注意力机制可用于服装图像提示的精细风格迁移;
6. 兼容ControNet/T2I-Adapter可以实现服装编辑+人体姿态控制的高级联动。
4.视觉AI任意门
本周阅读的论文《AnyDoor: Zero-shot Object-level Image Customization》,实现了零样本的图像嵌入,主要功能是“图像传送”,点击两下鼠标,就能把物体无缝传送到照片场景中,光线角度和透视也能自动适应。例如,将女生的蓝色短袖换成其他样式的红色衣服。所以。有了它,网购衣服也可以直接看上身效果了。

论文摘要
anydoor将目标物体以和谐的方式传送到用户指定的位置的新的场景,模型只训练一次,而不是为每个对象调优参数,在推理阶段轻松地推广到不同的对象场景组合。这样具有挑战性的零样本设置需要对某个对象进行充分的表征。为此,使用细节特征补充了常用的身份特征,这些细节特征经过精心设计,以保持纹理细节,但允许灵活的局部变化(例如,照明、方向、姿势等),支持对象与不同的环境良好地融合。
工作原理
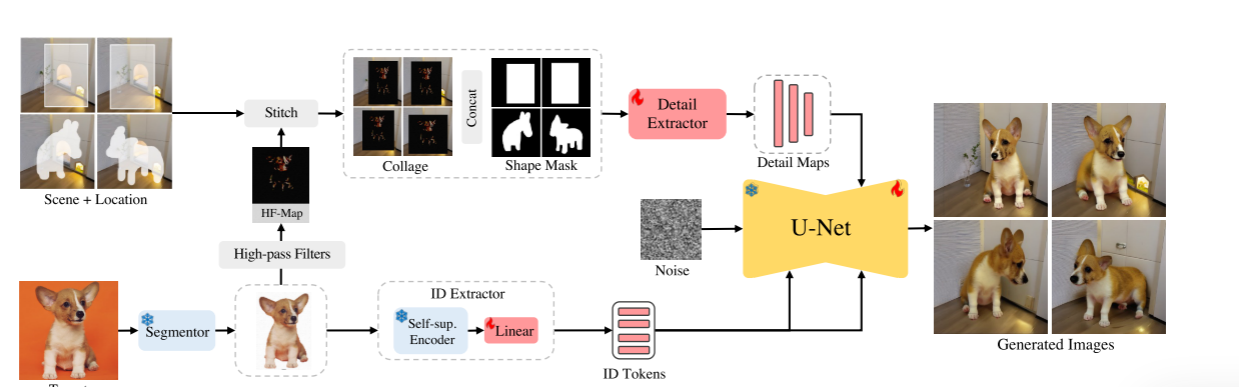
- AnyDoor目的是将对象传送到用户指定位置的场景。首先采用分割模块从对象中删除背景,然后使用ID提取器获取其身份信息。然后,我们对“干净”的对象应用高通滤波器,将所得的高频图(HF-Map)与期望位置的场景拼接起来,并使用细节提取器以纹理细节补充ID提取器。最后,将ID标记和细节图注入预训练的扩散模型,以产生最终的合成,其中目标对象与其周围环境良好地融合,但具有良好的局部变化。火焰和雪花分别指可学习和冻结的参数。
- 要想实现物体的传送,首先就要对其进行提取。不过在将包含目标物体的图像送入提取器之前,AnyDoor首先会对其进行背景消除。然后,AnyDoor会进行自监督式的物体提取并转换成token。这一步使用的编码器是以目前最好的自监督模型DINO-V2为基础设计的。为了适应角度和光线的变化,除了提取物品的整体特征,还需要额外提取细节信息。这一步中,为了避免过度约束还设计了一种用高频图表示特征信息的方式。

ID提取器是一种专注于焦点区域的视觉细节提取器。"Attention"指的是用于该ID(DINO-V2)的注意力图提取器的骨干部分,而"HF-Map"则指用于细节提取器中使用的高频率图。这两个模块侧重于互补的全局和局部信息。 最后一步就是将这些信息进行注入。利用获取到的token,AnyDoor通过文生图模型对图像进行合成。具体来说,AnyDoor使用的是带有ControlNet的Stable Diffusion。
实验代码
下面这段代码主要管理潜空间分布,支持扩散模型的采样、KL正则计算、推理输出,起到了连接Encoder、Decoder和训练目标的关键作用。
class AbstractDistribution:
def sample(self):
raise NotImplementedError()
def mode(self):
raise NotImplementedError()
class DiracDistribution(AbstractDistribution):
def __init__(self, value):
self.value = value
def sample(self):
return self.value
def mode(self):
return self.value
class DiagonalGaussianDistribution(object):
def __init__(self, parameters, deterministic=False):
self.parameters = parameters
self.mean, self.logvar = torch.chunk(parameters, 2, dim=1)
self.logvar = torch.clamp(self.logvar, -30.0, 20.0)
self.deterministic = deterministic
self.std = torch.exp(0.5 * self.logvar)
self.var = torch.exp(self.logvar)
if self.deterministic:
self.var = self.std = torch.zeros_like(self.mean).to(device=self.parameters.device)
def sample(self):
x = self.mean + self.std * torch.randn(self.mean.shape).to(device=self.parameters.device)
return x
def kl(self, other=None):
if self.deterministic:
return torch.Tensor([0.])
else:
if other is None:
return 0.5 * torch.sum(torch.pow(self.mean, 2)
+ self.var - 1.0 - self.logvar,
dim=[1, 2, 3])
else:
return 0.5 * torch.sum(
torch.pow(self.mean - other.mean, 2) / other.var
+ self.var / other.var - 1.0 - self.logvar + other.logvar,
dim=[1, 2, 3])
def nll(self, sample, dims=[1,2,3]):
if self.deterministic:
return torch.Tensor([0.])
logtwopi = np.log(2.0 * np.pi)
return 0.5 * torch.sum(
logtwopi + self.logvar + torch.pow(sample - self.mean, 2) / self.var,
dim=dims)
def mode(self):
return self.mean
def normal_kl(mean1, logvar1, mean2, logvar2):
"""
source: https://github.com/openai/guided-diffusion/blob/27c20a8fab9cb472df5d6bdd6c8d11c8f430b924/guided_diffusion/losses.py#L12
Compute the KL divergence between two gaussians.
Shapes are automatically broadcasted, so batches can be compared to
scalars, among other use cases.
"""
tensor = None
for obj in (mean1, logvar1, mean2, logvar2):
if isinstance(obj, torch.Tensor):
tensor = obj
break
assert tensor is not None, "at least one argument must be a Tensor"
# Force variances to be Tensors. Broadcasting helps convert scalars to
# Tensors, but it does not work for torch.exp().
logvar1, logvar2 = [
x if isinstance(x, torch.Tensor) else torch.tensor(x).to(tensor)
for x in (logvar1, logvar2)
]
return 0.5 * (
-1.0
+ logvar2
- logvar1
+ torch.exp(logvar1 - logvar2)
+ ((mean1 - mean2) ** 2) * torch.exp(-logvar2)
)
ClassEmbedder主要是做类别控制的,比如生成狗/猫/车,不给类别也可以自由生成(无条件版本)。
🔹 同时支持dropout机制让模型学会无条件生成。
class ClassEmbedder(nn.Module):
def __init__(self, embed_dim, n_classes=1000, key='class', ucg_rate=0.1):
super().__init__()
self.key = key
self.embedding = nn.Embedding(n_classes, embed_dim)
self.n_classes = n_classes
self.ucg_rate = ucg_rate
def forward(self, batch, key=None, disable_dropout=False):
if key is None:
key = self.key
# this is for use in crossattn
c = batch[key][:, None]
if self.ucg_rate > 0. and not disable_dropout:
mask = 1. - torch.bernoulli(torch.ones_like(c) * self.ucg_rate)
c = mask * c + (1-mask) * torch.ones_like(c)*(self.n_classes-1)
c = c.long()
c = self.embedding(c)
return c
def get_unconditional_conditioning(self, bs, device="cuda"):
uc_class = self.n_classes - 1 # 1000 classes --> 0 ... 999, one extra class for ucg (class 1000)
uc = torch.ones((bs,), device=device) * uc_class
uc = {self.key: uc}
return uc
def disabled_train(self, mode=True):
"""Overwrite model.train with this function to make sure train/eval mode
does not change anymore."""
return self
FrozenT5Embedder主要是把文字提示词(prompt)转成稳定的、不可学习的条件向量,供后续模块(比如扩散U-Net)使用。
🔹 因为冻结住了,不会因为少量任务数据而导致预训练文本特征崩坏。
class FrozenT5Embedder(AbstractEncoder):
"""Uses the T5 transformer encoder for text"""
def __init__(self, version="google/t5-v1_1-large", device="cuda", max_length=77, freeze=True): # others are google/t5-v1_1-xl and google/t5-v1_1-xxl
super().__init__()
self.tokenizer = T5Tokenizer.from_pretrained(version)
self.transformer = T5EncoderModel.from_pretrained(version)
self.device = device
self.max_length = max_length # TODO: typical value?
if freeze:
self.freeze()
def freeze(self):
self.transformer = self.transformer.eval()
#self.train = disabled_train
for param in self.parameters():
param.requires_grad = False
def forward(self, text):
batch_encoding = self.tokenizer(text, truncation=True, max_length=self.max_length, return_length=True,
return_overflowing_tokens=False, padding="max_length", return_tensors="pt")
tokens = batch_encoding["input_ids"].to(self.device)
outputs = self.transformer(input_ids=tokens)
z = outputs.last_hidden_state
return z
def encode(self, text):
return self(text)
FrozenCLIPEmbedder 是一个 固定的(冻结的)CLIP文本编码器,
它的功能是:把输入的自然语言文本 prompt,通过CLIP模型处理,转成向量表征(embedding),用于后续图像生成(如扩散模型U-Net中的Cross-Attention)。
class FrozenCLIPEmbedder(AbstractEncoder):
"""Uses the CLIP transformer encoder for text (from huggingface)"""
LAYERS = [
"last",
"pooled",
"hidden"
]
def __init__(self, version="openai/clip-vit-large-patch14", device="cuda", max_length=77,
freeze=True, layer="last", layer_idx=None): # clip-vit-base-patch32
super().__init__()
assert layer in self.LAYERS
self.tokenizer = CLIPTokenizer.from_pretrained(version)
self.transformer = CLIPTextModel.from_pretrained(version)
self.device = device
self.max_length = max_length
if freeze:
self.freeze()
self.layer = layer
self.layer_idx = layer_idx
if layer == "hidden":
assert layer_idx is not None
assert 0 <= abs(layer_idx) <= 12
def freeze(self):
self.transformer = self.transformer.eval()
#self.train = disabled_train
for param in self.parameters():
param.requires_grad = False
def forward(self, text):
batch_encoding = self.tokenizer(text, truncation=True, max_length=self.max_length, return_length=True,
return_overflowing_tokens=False, padding="max_length", return_tensors="pt")
tokens = batch_encoding["input_ids"].to(self.device)
outputs = self.transformer(input_ids=tokens, output_hidden_states=self.layer=="hidden")
if self.layer == "last":
z = outputs.last_hidden_state
elif self.layer == "pooled":
z = outputs.pooler_output[:, None, :]
else:
z = outputs.hidden_states[self.layer_idx]
return z
def encode(self, text):
return self(text)
5.论文结论
AnyDoor模型主要用于一键换脸/换衣、虚拟试穿、在线PS等业务场景。可以让很多不懂技术的电商卖家,也能实现专业PS的功能。但目前效果还略微粗糙,需要继续精雕细琢。另外交互对用户来说还不是特别方便,相信AnyDoor一定也会进一步的优化。
6.总结
通过本周对《Paint by Example》和《IP-Adapter》的深入对比学习,理解了在扩散模型中提升图像编辑灵活性与控制精度的不同路径。《Paint by Example》强调以图像示例为引导,优化局部编辑自然性,而《IP-Adapter》则以模块化、轻量的方式实现了多模态输入的无缝结合。结合两者特点,对个人时尚编辑方向启发巨大,计划融合mask控制与多模态提示,提升服装编辑效果。同时阅读了《AnyDoor》,了解了零样本对象迁移的细节处理技术,为实现更智能、用户友好的图像编辑系统奠定了基础。
参考文献
https://arxiv.org/abs/2211.13227
https://arxiv.org/pdf/2308.06721.pdf
https://arxiv.org/abs/2307.09481


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









