







###克鲁斯卡尔算法的作用是:构建图的最小生成树。
####克鲁斯卡尔算法 Kruskal的构造过程:
1、初始化图:n个顶点,n个连通分量(如果两个顶点的连通分量相同,表示两点在同一个连通图中)。把所有的边(包含这个边两端的两个顶点)放入优先级队列中,按照权重从小到大。
2、选择最小权重的边,如果这个边的头顶点的和尾顶点的连通分量不同,则合并头和尾两个分量(整个连通图的点都需要修改,具体看代码)。舍弃该边。(连通分量用整数表示)
3、重复第二步,直到所有的顶点都连接着同一个连通分量里面。

##代码实现:
package _kruskal;
import java.util.Arrays;
public class KruskalCase {
public static void main(String[] args) {
char[] vertexs = {'A', 'B', 'C', 'D', 'E', 'F', 'G'};
//克鲁斯卡尔算法的邻接矩阵
int matrix[][] = {
/*A*//*B*//*C*//*D*//*E*//*F*//*G*/
/*A*/ { 0, 12, INF, INF, INF, 16, 14},
/*B*/ { 12, 0, 10, INF, INF, 7, INF},
/*C*/ { INF, 10, 0, 3, 5, 6, INF},
/*D*/ { INF, INF, 3, 0, 4, INF, INF},
/*E*/ { INF, INF, 5, 4, 0, 2, 8},
/*F*/ { 16, 7, 6, INF, 2, 0, 9},
/*G*/ { 14, INF, INF, INF, 8, 9, 0}
};
//大家可以在去测试其它的邻接矩阵,结果都可以得到最小生成树.
//创建KruskalCase 对象实例
KruskalCase kruskalCase = new KruskalCase(vertexs, matrix);
//输出构建的
kruskalCase.print();
kruskalCase.kruskal();
}
private int edgeNum; //边的个数
private char[] vertexs; //顶点数组
private int[][] matrix; //邻接矩阵
//使用 INF 表示两个顶点不能连通
private static final int INF = Integer.MAX_VALUE;
//构造器
public KruskalCase(char[] vertexs, int[][] matrix) {
//初始化顶点数和边的个数
int vlen = vertexs.length;
//初始化顶点, 复制拷贝的方式
this.vertexs = new char[vlen];
for(int i = 0; i < vertexs.length; i++) {
this.vertexs[i] = vertexs[i];
}
//初始化边, 使用的是复制拷贝的方式
this.matrix = new int[vlen][vlen];
for(int i = 0; i < vlen; i++) {
for(int j= 0; j < vlen; j++) {
this.matrix[i][j] = matrix[i][j];
}
}
//统计边的条数
for(int i =0; i < vlen; i++) {
for(int j = i+1; j < vlen; j++) {
if(this.matrix[i][j] != INF) {
edgeNum++;
}
}
}
}
public void kruskal() {
int index = 0; //表示最后结果数组的索引
int[] ends = new int[edgeNum]; //用于保存"已有最小生成树" 中的每个顶点在最小生成树中的终点
//创建结果数组, 保存最后的最小生成树
EData[] rets = new EData[edgeNum];
//获取图中 所有的边的集合 , 一共有12边
EData[] edges = getEdges();
System.out.println("图的边的集合=" + Arrays.toString(edges) + " 共"+ edges.length); //12
//按照边的权值大小进行排序(从小到大)
sortEdges(edges);
//遍历edges 数组,将边添加到最小生成树中时,判断是准备加入的边否形成了回路,如果没有,就加入 rets, 否则不能加入
for(int i=0; i < edgeNum; i++) {
//获取到第i条边的第一个顶点(起点)
int p1 = getPosition(edges[i].start); //p1=4
//获取到第i条边的第2个顶点
int p2 = getPosition(edges[i].end); //p2 = 5
//获取p1这个顶点在已有最小生成树中的终点
int m = getEnd(ends, p1); //m = 4
//获取p2这个顶点在已有最小生成树中的终点
int n = getEnd(ends, p2); // n = 5
//是否构成回路
if(m != n) { //没有构成回路
ends[m] = n; // 设置m 在"已有最小生成树"中的终点 <E,F> [0,0,0,0,5,0,0,0,0,0,0,0]
rets[index++] = edges[i]; //有一条边加入到rets数组
}
}
//<E,F> <C,D> <D,E> <B,F> <E,G> <A,B>。
//统计并打印 "最小生成树", 输出 rets
System.out.println("最小生成树为");
for(int i = 0; i < index; i++) {
System.out.println(rets[i]);
}
}
//打印邻接矩阵
public void print() {
System.out.println("邻接矩阵为: \n");
for(int i = 0; i < vertexs.length; i++) {
for(int j=0; j < vertexs.length; j++) {
System.out.printf("%12d", matrix[i][j]);
}
System.out.println();//换行
}
}
/**
* 功能:对边进行排序处理, 冒泡排序
* @param edges 边的集合
*/
private void sortEdges(EData[] edges) {
for(int i = 0; i < edges.length - 1; i++) {
for(int j = 0; j < edges.length - 1 - i; j++) {
if(edges[j].weight > edges[j+1].weight) {//交换
EData tmp = edges[j];
edges[j] = edges[j+1];
edges[j+1] = tmp;
}
}
}
}
/**
*
* @param ch 顶点的值,比如'A','B'
* @return 返回ch顶点对应的下标,如果找不到,返回-1
*/
private int getPosition(char ch) {
for(int i = 0; i < vertexs.length; i++) {
if(vertexs[i] == ch) {//找到
return i;
}
}
//找不到,返回-1
return -1;
}
/**
* 功能: 获取图中边,放到EData[] 数组中,后面我们需要遍历该数组
* 是通过matrix 邻接矩阵来获取
* EData[] 形式 [['A','B', 12], ['B','F',7], .....]
* @return
*/
private EData[] getEdges() {
int index = 0;
EData[] edges = new EData[edgeNum];
for(int i = 0; i < vertexs.length; i++) {
for(int j=i+1; j <vertexs.length; j++) {
if(matrix[i][j] != INF) {
edges[index++] = new EData(vertexs[i], vertexs[j], matrix[i][j]);
}
}
}
return edges;
}
/**
* 功能: 获取下标为i的顶点的终点(), 用于后面判断两个顶点的终点是否相同
* @param ends : 数组就是记录了各个顶点对应的终点是哪个,ends 数组是在遍历过程中,逐步形成
* @param i : 表示传入的顶点对应的下标
* @return 返回的就是 下标为i的这个顶点对应的终点的下标, 一会回头还有来理解
*/
private int getEnd(int[] ends, int i) { // i = 4 [0,0,0,0,5,0,0,0,0,0,0,0]
while(ends[i] != 0) {
i = ends[i];
}
return i;
}
}
//创建一个类EData ,它的对象实例就表示一条边
class EData {
char start; //边的一个点
char end; //边的另外一个点
int weight; //边的权值
//构造器
public EData(char start, char end, int weight) {
this.start = start;
this.end = end;
this.weight = weight;
}
//重写toString, 便于输出边信息
@Override
public String toString() {
return "EData [<" + start + ", " + end + ">= " + weight + "]";
}
}
##测试
打印邻接矩阵
0 12 2147483647 2147483647 2147483647 16 14
12 0 10 2147483647 2147483647 7 2147483647
2147483647 10 0 3 5 6 2147483647
2147483647 2147483647 3 0 4 2147483647 2147483647
2147483647 2147483647 5 4 0 2 8
16 7 6 2147483647 2 0 9
14 2147483647 2147483647 2147483647 8 9 0
[EData{start=A, end=B, weight=12}, EData{start=A, end=F, weight=16}, EData{start=A, end=G, weight=14}, EData{start=B, end=C, weight=10}, EData{start=B, end=F, weight=7}, EData{start=C, end=D, weight=3}, EData{start=C, end=E, weight=5}, EData{start=C, end=F, weight=6}, EData{start=D, end=E, weight=4}, EData{start=E, end=F, weight=2}, EData{start=E, end=G, weight=8}, EData{start=F, end=G, weight=9}]
最小生成树为
EData{start=E, end=F, weight=2}
EData{start=C, end=D, weight=3}
EData{start=D, end=E, weight=4}
EData{start=B, end=F, weight=7}
EData{start=E, end=G, weight=8}
EData{start=A, end=B, weight=12}
# 知其然不知其所以然,大厂常问面试技术如何复习?
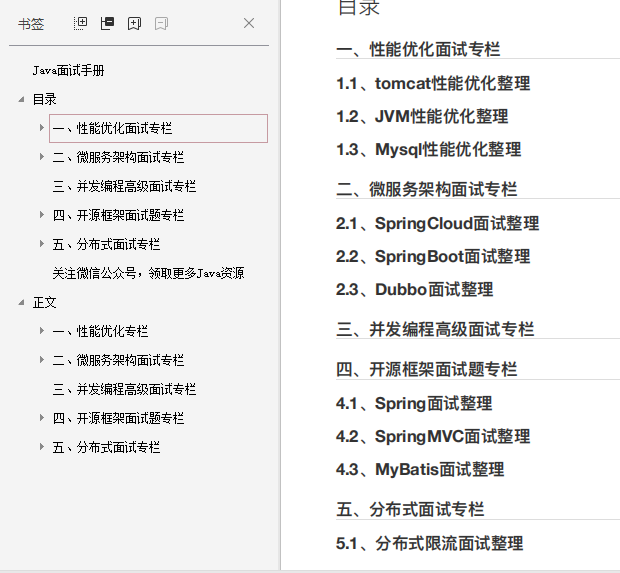
**1、热门面试题及答案大全**
面试前做足功夫,让你面试成功率提升一截,这里一份热门350道一线互联网常问面试题及答案助你拿offer
> [**面试宝典+书籍+核心知识获取:戳这里免费下载**](https://docs.qq.com/doc/DSmxTbFJ1cmN1R2dB)!诚意满满!!!
**2、多线程、高并发、缓存入门到实战项目pdf书籍**



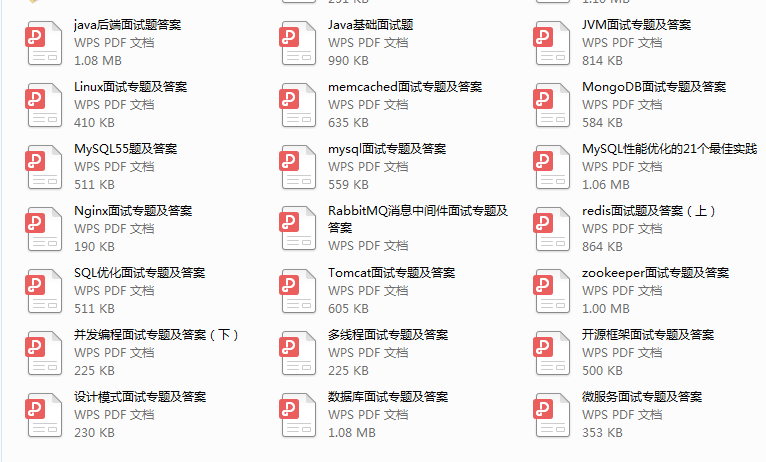
**3、文中提到面试题答案整理**
**4、Java核心知识面试宝典**
覆盖了**JVM 、JAVA集合、JAVA多线程并发、JAVA基础、Spring原理、微服务、Netty与RPC、网络、日志、Zookeeper、Kafka、RabbitMQ、Hbase、MongoDB 、Cassandra、设计模式、负载均衡、数据库、一致性算法 、JAVA算法、数据结构、算法、分布式缓存、Hadoop、Spark、Storm的大量技术点且讲解的非常深入**



志、Zookeeper、Kafka、RabbitMQ、Hbase、MongoDB 、Cassandra、设计模式、负载均衡、数据库、一致性算法 、JAVA算法、数据结构、算法、分布式缓存、Hadoop、Spark、Storm的大量技术点且讲解的非常深入**
[外链图片转存中...(img-RoGtZm18-1623422491438)]
[外链图片转存中...(img-mGd8Xk9a-1623422491439)]
[外链图片转存中...(img-Z9a9c0fD-1623422491439)]















 2373
2373











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









