







在说明k8s的一些使用方法时,我们需要将注意力更多的集中在如何使用k8s本身上,出现警告版本问题时,我们记录下来,后续自行研究即可,这类告警一般在官方文档和命令行中留有充分的解释,在整个k8s架构中,我们需要理解各个组件的规则并运用出来,这些大部分属于标准化操作,重点还是在于不断深入理解各个组件的原理。即使更新版本,原理不会变的情况下,我们需要投入的精力就会事半功倍。
K8S官网:Kubernetes 文档 | Kubernetes
本文留有目录,请自行查看。
Pod管理:
命令:
关于Pod介绍:
Kubernetes通过Pod解决容器的网络通信和数据共享的问题。
集群内部任意节点可以访问Pod,但集群外部无法直接访问
集群内会分配VIP给pod,pod内的容器共享这一个VIP
先熟悉命令:
查看搭建好的集群是否ready:
[root@k8s1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s1 Ready control-plane,master 2d15h v1.23.12
k8s2 Ready <none> 2d14h v1.23.12
k8s3 Ready <none> 2d15h v1.23.12查看所有的pod:
这里显示了所有的pod
[root@k8s1 ~]# kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-flannel kube-flannel-ds-df8rj 1/1 Running 4 (37h ago) 2d15h
kube-flannel kube-flannel-ds-kbqz4 1/1 Running 2 (37h ago) 2d14h
kube-flannel kube-flannel-ds-n5j5h 1/1 Running 6 (71m ago) 2d15h
kube-system coredns-7b56f6bc55-9kjf8 1/1 Running 10 (15h ago) 2d15h
kube-system coredns-7b56f6bc55-rrrjt 1/1 Running 11 (15h ago) 2d15h
kube-system etcd-k8s1 1/1 Running 6 (15h ago) 2d15h
kube-system kube-apiserver-k8s1 1/1 Running 6 (15h ago) 2d15h
kube-system kube-controller-manager-k8s1 1/1 Running 6 (15h ago) 2d15h
kube-system kube-proxy-jcz7l 1/1 Running 2 (37h ago) 2d15h
kube-system kube-proxy-rxcdx 1/1 Running 2 (37h ago) 2d14h
kube-system kube-proxy-vthg8 1/1 Running 5 (15h ago) 2d15h
kube-system kube-scheduler-k8s1 1/1 Running 6 (15h ago) 2d15h
单单查看pod时namespace默认查看的是default:
[root@k8s1 ~]# kubectl get pod
No resources found in default namespace.
[root@k8s1 ~]# kubectl get pod -n ns
No resources found in ns namespace.
[root@k8s1 ~]# kubectl get pod -n kube-flannel
可以选择 -n 查看任意的namespace
NAME READY STATUS RESTARTS AGE
kube-flannel-ds-df8rj 1/1 Running 4 (41h ago) 2d19h
kube-flannel-ds-kbqz4 1/1 Running 2 (41h ago) 2d18h
kube-flannel-ds-n5j5h 1/1 Running 6 (4h41m ago) 2d19h
[root@k8s1 ~]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-7b56f6bc55-9kjf8 1/1 Running 10 (18h ago) 2d19h
coredns-7b56f6bc55-rrrjt 1/1 Running 11 (18h ago) 2d19h
etcd-k8s1 1/1 Running 6 (18h ago) 2d19h
kube-apiserver-k8s1 1/1 Running 6 (18h ago) 2d19h
kube-controller-manager-k8s1 1/1 Running 6 (18h ago) 2d19h
kube-proxy-jcz7l 1/1 Running 2 (41h ago) 2d19h
kube-proxy-rxcdx 1/1 Running 2 (41h ago) 2d18h
kube-proxy-vthg8 1/1 Running 5 (18h ago) 2d19h
kube-scheduler-k8s1 1/1 Running 6 (18h ago) 2d19h
创建一个pod,指定镜像为nginx:
kubectl run demo --image=nginx
[root@k8s1 ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
demo 0/1 ContainerCreating 0 10s
“ContainerCreating” 正在创建中
[root@k8s1 ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
demo 1/1 Running 0 14s
[root@k8s1 ~]# kubectl get pod -o wide
## -o wide 是用来查看pod的详细信息
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
demo 1/1 Running 0 34s 10.244.2.2 k8s2 <none> <none>
##此时pod被创建在k8s2节点上此时在集群内任意节点可以访问pod:
[root@k8s1 ~]# curl 10.244.1.13
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
删除pod:
kubectl delete pod demo此时的pod是自主式pod,删除之后即完全删除
现在创建deployment控制器demo:
[root@k8s1 ~]# kubectl create deployment demo --image=nginx
deployment.apps/demo created
##成功创建
[root@k8s1 ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
demo-6c54f77c95-8rhtd 1/1 Running 0 5s
##查看pod
[root@k8s1 ~]# kubectl get deployments.apps
NAME READY UP-TO-DATE AVAILABLE AGE
demo 1/1 1 1 28s
##查看控制器demo
[root@k8s1 ~]# kubectl delete pod demo-6c54f77c95-8rhtd
pod "demo-6c54f77c95-8rhtd" deleted
##在删除pod demo之后,由于创建了控制器,pod会自愈
[root@k8s1 ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
demo-6c54f77c95-rblxf 0/1 ContainerCreating 0 6s
##此时pod又在被创建
[root@k8s1 ~]# kubectl scale deployment demo --replicas=3
##指定拉伸副本数为三个
deployment.apps/demo scaled
[root@k8s1 ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
demo-6c54f77c95-4chxb 1/1 Running 0 5s
demo-6c54f77c95-rblxf 1/1 Running 0 48s
demo-6c54f77c95-v7t5q 1/1 Running 0 5s
##此时三个pod被创建好了
[root@k8s1 ~]# kubectl scale deployment demo --replicas=1
##此时副本数又被缩回至1个
deployment.apps/demo scaled
[root@k8s1 ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
demo-6c54f77c95-4chxb 1/1 Running 0 37s
##查看pod
此时pod只能被集群内部访问,如果想让集群外访问需要把控制器暴露出来:
[root@k8s1 ~]# kubectl expose deployment demo --port=80 --target-port=80
##--target-por 容器内端口
service/demo exposed
[root@k8s1 ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
demo ClusterIP 10.104.93.185 <none> 80/TCP 10s
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2d16h
此时会创建一个demo的svc
查看此时的svc,endpoint只有一个IP
[root@k8s1 ~]# kubectl describe svc demo
Name: demo
Namespace: default
Labels: app=demo
Annotations: <none>
Selector: app=demo
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.109.224.102
IPs: 10.109.224.102
Port: <unset> 80/TCP
TargetPort: 80/TCP
Endpoints: 10.244.1.14:80
Session Affinity: None
Events: <none>
此时将副本数拉伸为3:
[root@k8s1 ~]# kubectl expose deployment demo --port=80 --target-port=80
service/demo exposed
[root@k8s1 ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
demo-6c54f77c95-4x4m8 1/1 Running 0 57s
demo-6c54f77c95-hbrxk 1/1 Running 0 57s
demo-6c54f77c95-x5bsd 1/1 Running 0 69s
此时查看endpoint:
[root@k8s1 ~]# kubectl describe svc demo
Name: demo
Namespace: default
Labels: app=demo
Annotations: <none>
Selector: app=demo
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.109.224.102
IPs: 10.109.224.102
Port: <unset> 80/TCP
TargetPort: 80/TCP
Endpoints: 10.244.1.14:80,10.244.2.10:80,10.244.2.9:80
Session Affinity: None
Events: <none>
[root@k8s1 ~]#
此时还不能被集群外访问,这里依然只能访问集群内的三个ip原因:此时svc的类型是ClusterIP,我们需要改成NodePort才能在集群外访问:
SVC:k8s的一个微服务,提供pod负载均衡
[root@k8s1 ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
demo ClusterIP 10.109.224.102 <none> 80/TCP 12m
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2d20h
更改svc:
kubectl edit svc demo
type: NodePort[root@k8s1 ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
demo NodePort 10.109.224.102 <none> 80:30151/TCP 17m
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2d21h此时发现绑定了 一个端口(端口不固定)30151
在edge访问:
11/12/13都可以访问
SVC在集群节点上的开放了端口(类似端口映射),在访问端口时就可以访问pod,通过iptables的策略实现

yaml文件(资源清单):
在K8S集群中,需要标准化操作集群,此时需要通过写yaml文件来标准化操作
这些yaml文件有统一规范写法,可以通过简单的方式认识yaml文件的格式:
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: demo
name: demo
spec:
containers:
- image: nginx
name: demo
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
运行和删除yaml文件:
kubectl apply -f pod.yaml
kubectl delete -f pod.yaml进行简单的改写:
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: demo
name: demo
spec:
hostNetwork: true
nodeSelector:
#disktype: ssd
containers:
- image: nginx
name: demo
resources:
limits:
cpu: 0.2
#100m
memory: 256Mi
#+i 1024cache
#not i 1000cache
requests:
cpu: 100m
memory: 100Mi
imagePullPolicy: IfNotPresent
#ports:
#- name: http
# containerPort: 80
# hostPort: 80
#- name:busybox
# image: busybox
# imagePullPolicy: IfNotPresent
# tty: true
# stdin: true
解释:
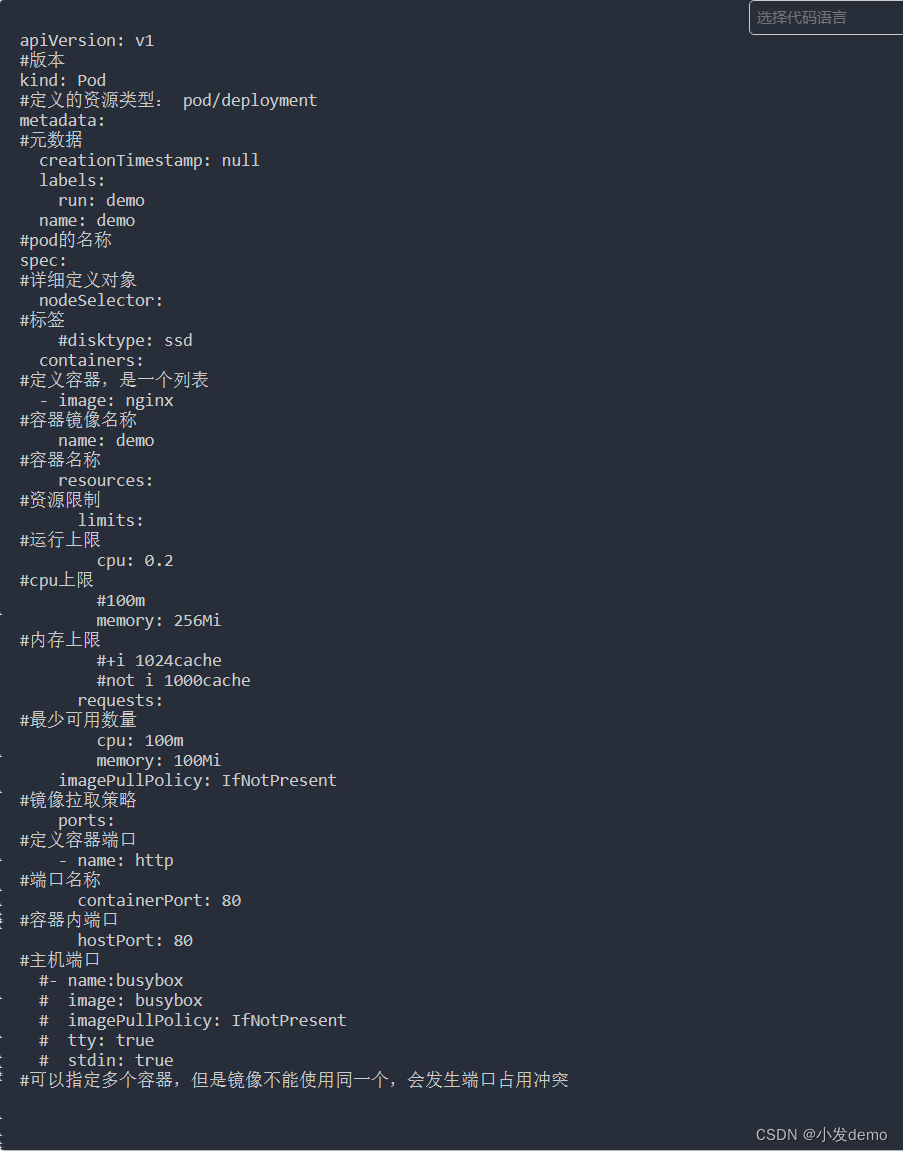
端口名称可以通过命令查看
kubectl get pod -o widek8s1:

k8s2:

k8s3:

QoS(容器的质量控制):
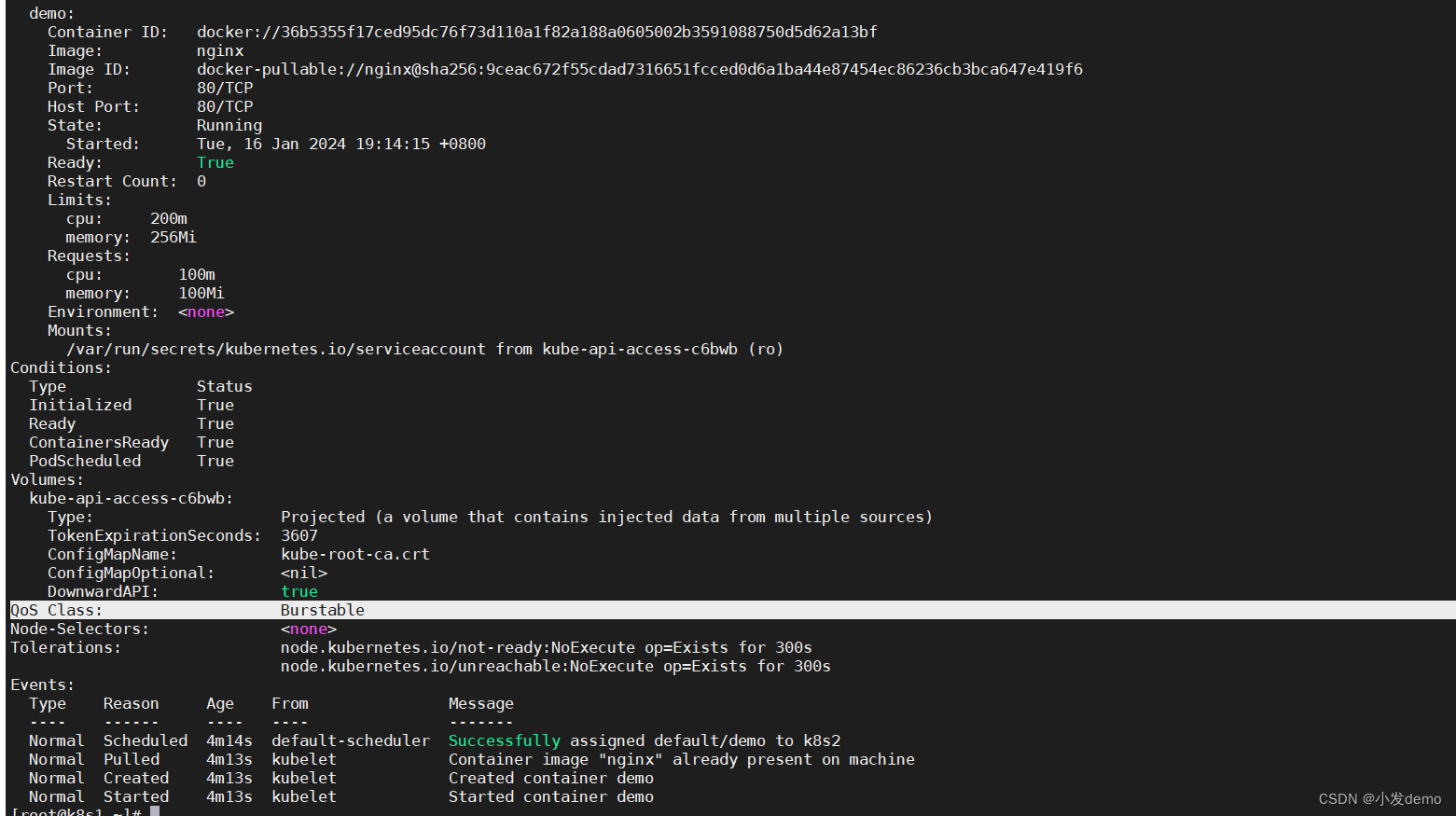
在k8s中,不能直接修改QoSclass的值,只能通过限制resources的资源来设置
设置节点标签:
#查看标签
[root@k8s1 ~]# kubectl label nodes k8s1 disktype=ssd^C
[root@k8s1 ~]# kubectl get nodes --show-labels
NAME STATUS ROLES AGE VERSION LABELS
k8s1 Ready control-plane,master 2d23h v1.23.12 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s1,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node-role.kubernetes.io/master=,node.kubernetes.io/exclude-from-external-load-balancers=
k8s2 Ready <none> 2d21h v1.23.12 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,disktype=ssd,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s2,kubernetes.io/os=linux
k8s3 Ready <none> 2d22h v1.23.12 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s3,kubernetes.io/os=linux
#设置标签
kubectl label nodes k8s1 disktype=ssd访问集群内任何一个节点都可以访问到pod,通过svc暴露
共享网络栈即Pod内的容器不能使用同一个镜像(端口冲突)
hostNetwork:定义是否使用主机网络模式:
通过这个简单的yaml文件来认识和学习yaml文件的编写,以下是一些资源清单的数据类型:
https://cloud.tencent.com/developer/article/2276496
我们重点关注此类内容:
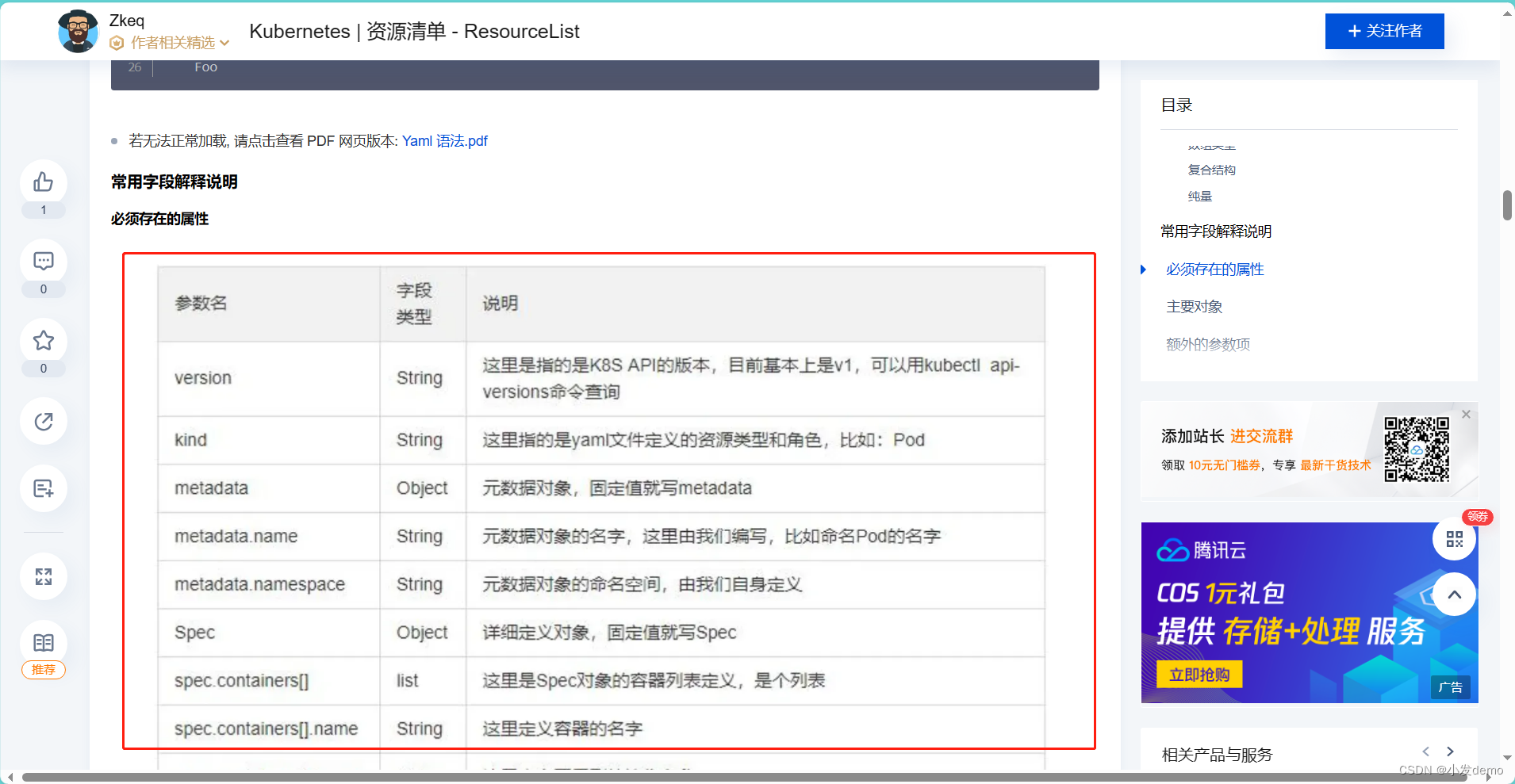
Pod生命周期:
一个pod被创建之前首先会经过初始化,初始化包括容器环境初始化和init容器初始化(可选项,一个接一个初始化),然后再启动主容器。
在主容器启动时,会有探针诊断容器是否正常运行,如果检测异常,则根据策略进行相应的执行操作。
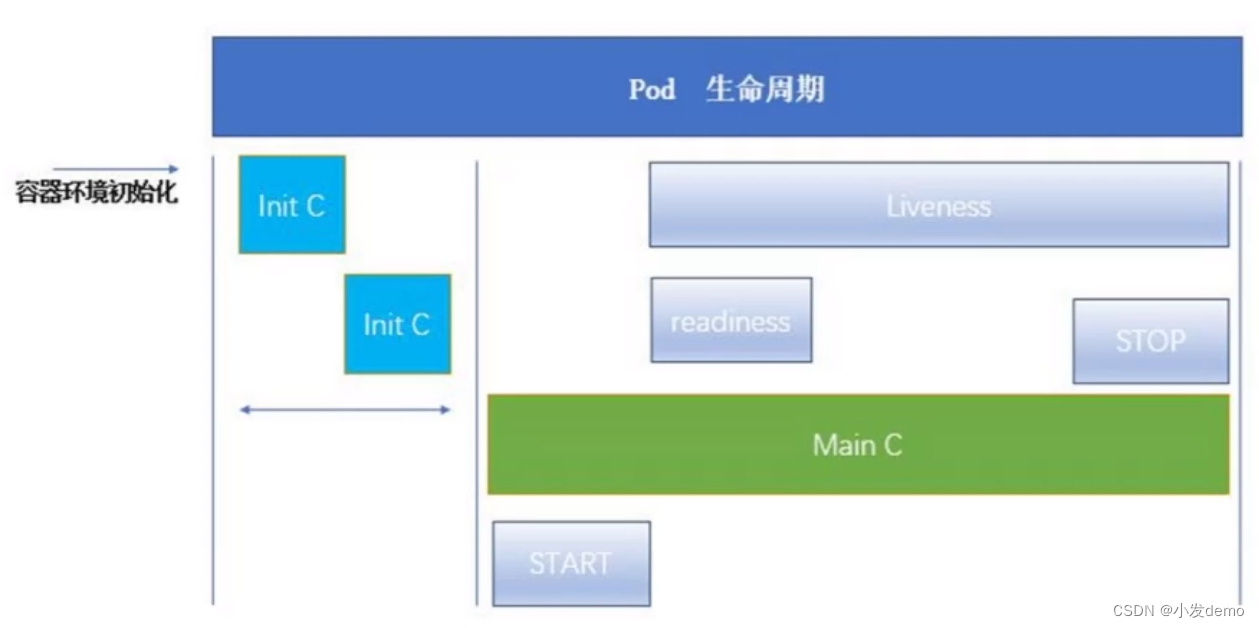
Pod可以包含多个容器,应用运行在这些容器里面,同时 Pod也可以有一个或多个先于应用容器启动的Init容器。
Init容器与普通的容器非常像,除了如下两点:
它们总是运行到完成。
Init 容器不支持 Readiness,因为它们必须在 Pod 就绪之前运行完成,每 个Init容器必须运行成功,下一个才能够运行。
如果 Pod 的 Init 容器失败,Kubernetes 会不断地重启该 Pod,直到 Init 容器成 功为止。然而,如果Pod对应的restartPolicy值为Never,它不会重新启动。
初始化容器可以做什么:
Init容器可以包含一些安装过程中应用容器中不存在的实用工具或个性化代码。
Init 容器可以安全地运行这些工具,避免这些工具导致应用镜像的安全性降低。
应用镜像的创建者和部署者可以各自独立工作,而没有必要联合构建一个单独的应用镜像。
Init容器能以不同于Pod内应用容器的文件系统视图运行。因此, Init容器可具有访问Secrets的权限,而应用容器不能够访问。
由于Init 容器必须在应用容器启动之前运行完成,因此 Init 容器提供了一种机制来阻塞或延迟应用容器的启动,直到满足了一组先决条件。一旦前置条件满足,Pod内的所有的应用容器会并行启动。
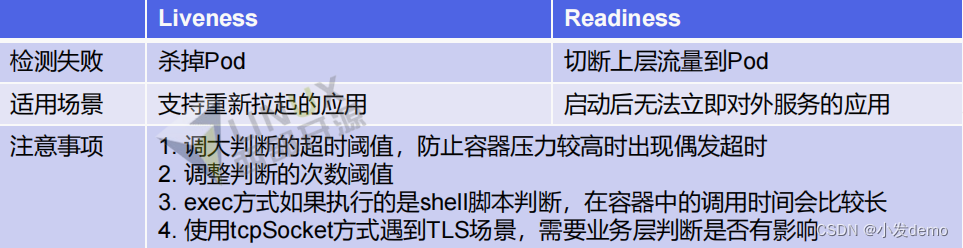
三种探针:
livenessProbe:指示容器是否正在运行。如果存活探测失败,则 kubelet 会杀死容器,并且容器将受到其 重启策略 的影响。如果容器不提供存活探针,则默认状态为 Success 。readinessProbe:指示容器是否准备好服务请求。如果就绪探测失败,端点控制器将从与 Pod 匹配的所有 Service 的端点中删除该 Pod 的 IP 地址。初始延迟之前的就绪状态默认为 Failure 。如果容器不提供就绪探针,则默认状态为 Success 。startupProbe: 指示容器中的应用是否已经启动。如果提供了启动探测 (startup probe),则禁用所有其他探测,直到它成功为止。如果启动探测失败 ,kubelet 将杀死容器,容器服从其重启策略进行重启。如果容器没有提供启动探测,则默认状态为成功Success 。
三种诊断方式:
探针 是由 kubelet 对容器执行的定期诊断 :ExecAction:在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功。TCPSocketAction:对指定端口上的容器的 IP 地址进行 TCP 检查。如果端口打开,则诊断被认为是成功的。HTTPGetAction:对指定的端口和路径上的容器的 IP 地址执行 HTTP Get请求。如果响应的状态码大于等于 200 且小于 400 ,则诊断被认为是成功的。每次探测都将获得以下三种结果之一:成功:容器通过了诊断。失败:容器未通过诊断。未知:诊断失败,因此不会采取任何行动。
参数解释:initialDelaySeconds pod启动后延迟多久进行检测periodSeconds 检测的间隔时间,默认10秒timeoutSeconds 检测的超时时间,默认1秒successThreshold 检测失败后再次判断成功的阈值,默认1次failureThreshold 检测失败的重试次数,默认3次
举例init容器使用:
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: demo
name: demo
spec:
initContainers:
- name: init-container
image: busybox
command: ["/bin/sh", "-c", "until nslookup myservice.default.svc.cluster.local; do echo waiting for myservice; sleep 2; done"]
#hostNerwork: ture
nodeSelector:
disktype: ssd
containers:
- image: nginx
name: demo
resources:
limits:
cpu: 0.2
#100m
memory: 256Mi
#+i 1024cache
#not i 1000cache
requests:
cpu: 100m
memory: 100Mi
imagePullPolicy: IfNotPresent
#ports:
#- name: http
# containerPort: 80
# hostPort: 80
#- name:busybox
# image: busybox
# imagePullPolicy: IfNotPresent
# tty: true
# stdin: true
此时我们加入init容器,init解析svc是否被创建,直到解析成功为止,init容器才会退出,然后运行主容器,很明显集群内svc并没有创建,所以容器会一直处于初始化状态:

此时则需要运行一个svc
---
apiVersion: v1
kind: Service
metadata:
name: myservice
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9376运行svc之后再看pod状态,此时running:
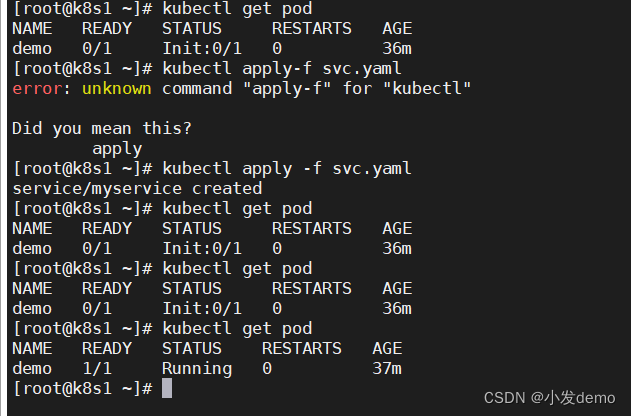
init容器初始化成功之后会退出
举例liveness存活探针使用:
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-http
spec:
containers:
- name: liveness
image: nginx
imagePullPolicy: IfNotPresent
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 1 容器正常启动多长时间之后检测
periodSeconds: 3 #监测频率
timeoutSeconds: 1 #检测超时时间liveness探针通过tcp的方式查看nginx的8080端口是否就绪,显然并没有就绪,通过get pod可以发现pod在被不断重启
[root@k8s1 ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
liveness-http 1/1 Running 0 6s
[root@k8s1 ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
liveness-http 1/1 Running 0 9s
[root@k8s1 ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
liveness-http 1/1 Running 1 (2s ago) 12s此时改回80端口之后,重新apply,pod即可正常运行
readiness就绪探针举例:
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-http
spec:
containers:
- name: liveness
image: nginx
imagePullPolicy: IfNotPresent
livenessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 1
periodSeconds: 3
timeoutSeconds: 1
readinessProbe:
httpGet:
path: /test.html
port: 80
initialDelaySeconds: 1
periodSeconds: 3
timeoutSeconds: 1
在readness探针中,采用了httpGet的方式来诊断容器受否正常运行,此时nginx中并没有test.html页面,容器检测没有ready:
[root@k8s1 ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
liveness-http 0/1 Running 0 3m27s
使用exec进入容器内,创建test.html
[root@k8s1 ~]# kubectl exec liveness-http -- touch /usr/share/nginx/html/test.html
[root@k8s1 ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
liveness-http 1/1 Running 0 34s
一般liveness和readness配合一起使用
如果容器无法启动,
控制器:
控制器官方文档:
Pod 的分类:
自主式 Pod: Pod 退出后不会被创建
控制器管理的Pod:在控制器的生命周期里,始终要维持 Pod的副本数目
控制器类型:Replication Controller和ReplicaSet(推荐使用后者)
Deployment
DaemonSet
StatefulSet
Job
CronJob(周期化)
HPA全称Horizontal Pod Autoscaler(动态弹缩)
Replication Controller和ReplicaSet:
ReplicaSet是下一代的Replication Controller,官方推荐使用ReplicaSet
ReplicaSet和Replication Controller的唯一区别是选择器的支持, ReplicaSet支持 新的基于集合的选择器需求。
ReplicaSet 确保任何时间都有指定数量的 Pod 副本在运行。
虽然ReplicaSets可以独立使用,但今天它主要被Deployments用作协调Pod创建、删除和更新的机制。
Deployment:
Deployment为 Pod和 ReplicaSet 提供了一个申明式的定义方法。
典型的应用场景:
用来创建Pod和ReplicaSet
滚动更新和回滚
扩容和缩容
暂停与恢复
控制器的作用是从etcd中把期望状态载入,不断向期望状态趋近
deployment适用与无状态应用
ReplicaSet控制器示例:
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: deployment-example
spec:
replicas: 3
#可以自定义副本数
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
#自定义容器镜像以及版本
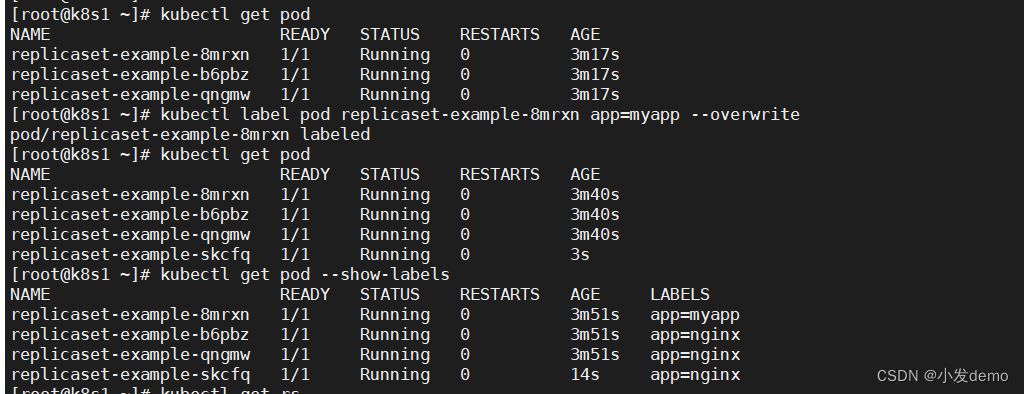
此时8mrxn是无主的,因为这和rs控制器所匹配的标签匹配不上
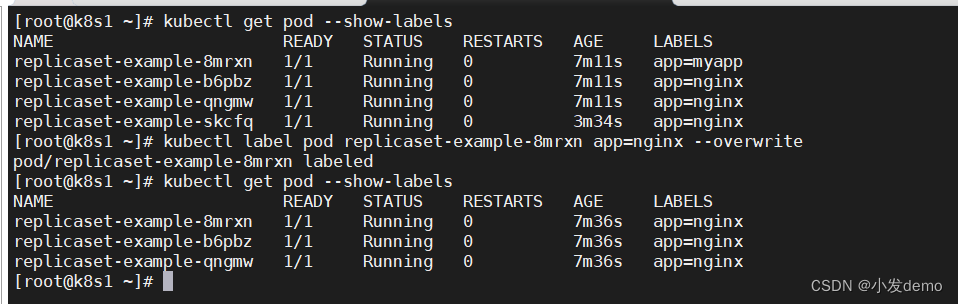
当改回标签的时候,新开的标签会被优先回收
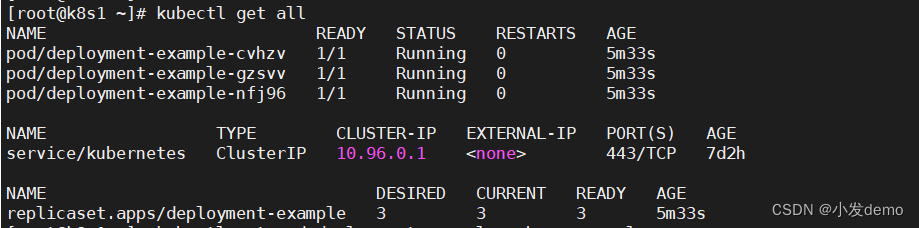
在rs控制器get all时:
在使用deployment控制器时,可以进行更新和回滚
deployment控制器示例:
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-example
spec:
replicas: 6
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: myapp:v1
#修改版本
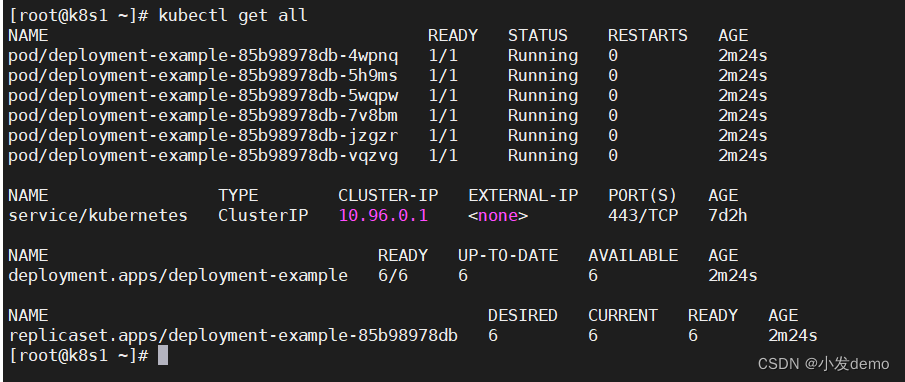
关系:deployment控制器创建rs控制器->pod
deployment控制的rs控制器相当于控制版本
通过修改yaml文件实现版本迭代:
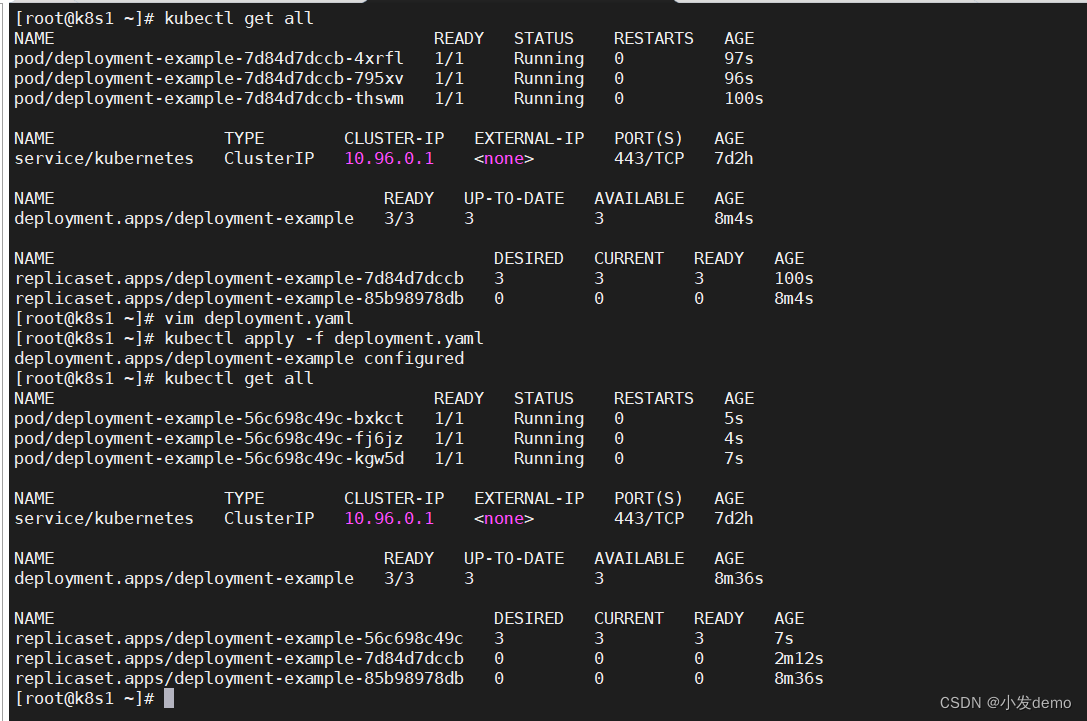
原来的rs控制器没有删掉是为了快速回滚
删除之后回滚速度会下降:
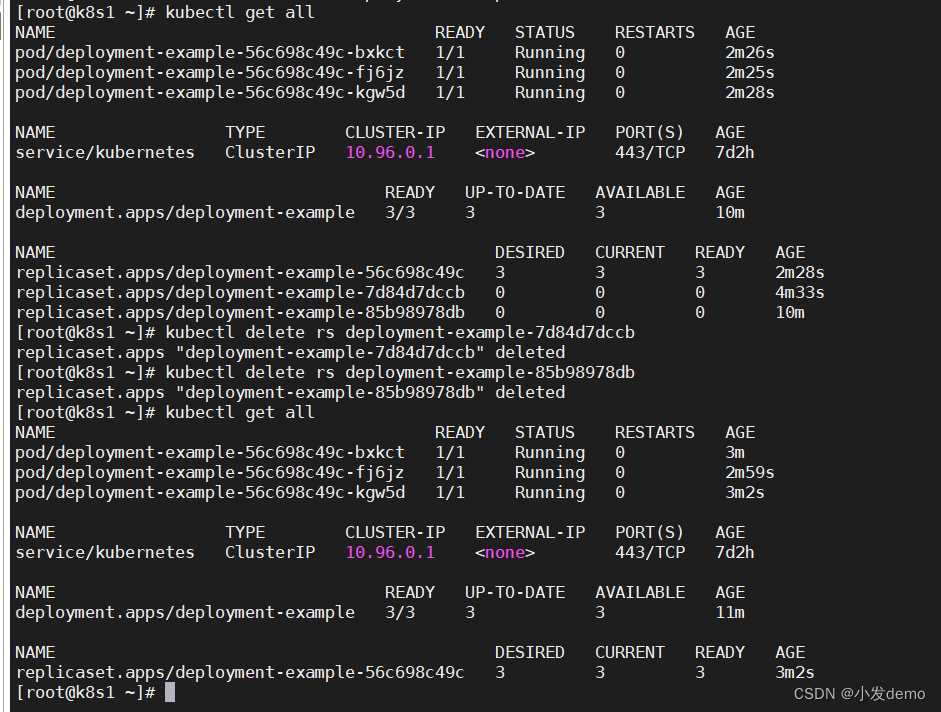
滚动更新:
示例:
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-example
spec:
minReadySeconds: 3
#最短就绪时间
strategy:
rollingUpdate:
maxSurge: 2
#最大峰值
maxUnavailable: 0
#最大不可用
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: myapp:v2
运行yaml文件之前,我们可以查看参数详情:
kubectl explain deployment.spec.strategy.rollingUpdate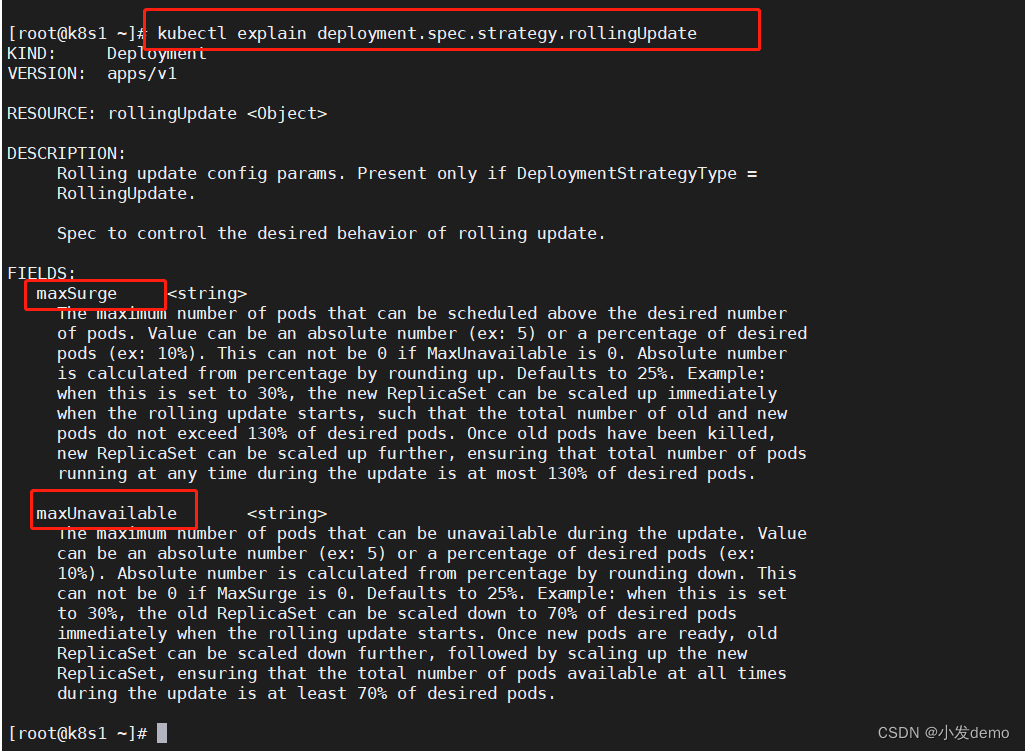
最大峰值表示每一次更新pod数量最多不超过该值

最大不可用:

在修改最大不可用和最大峰值之后,重新运行yaml
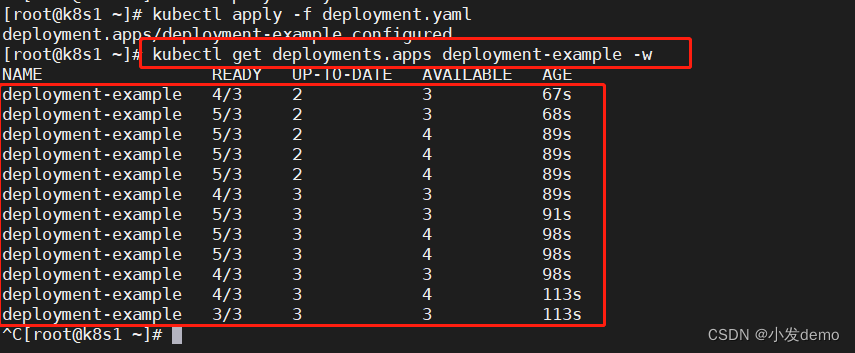
显示效果太快无法观察,除了使用参数,还可以使用init容器来阻塞和用探针来减慢容器的running过程,以便观察结果
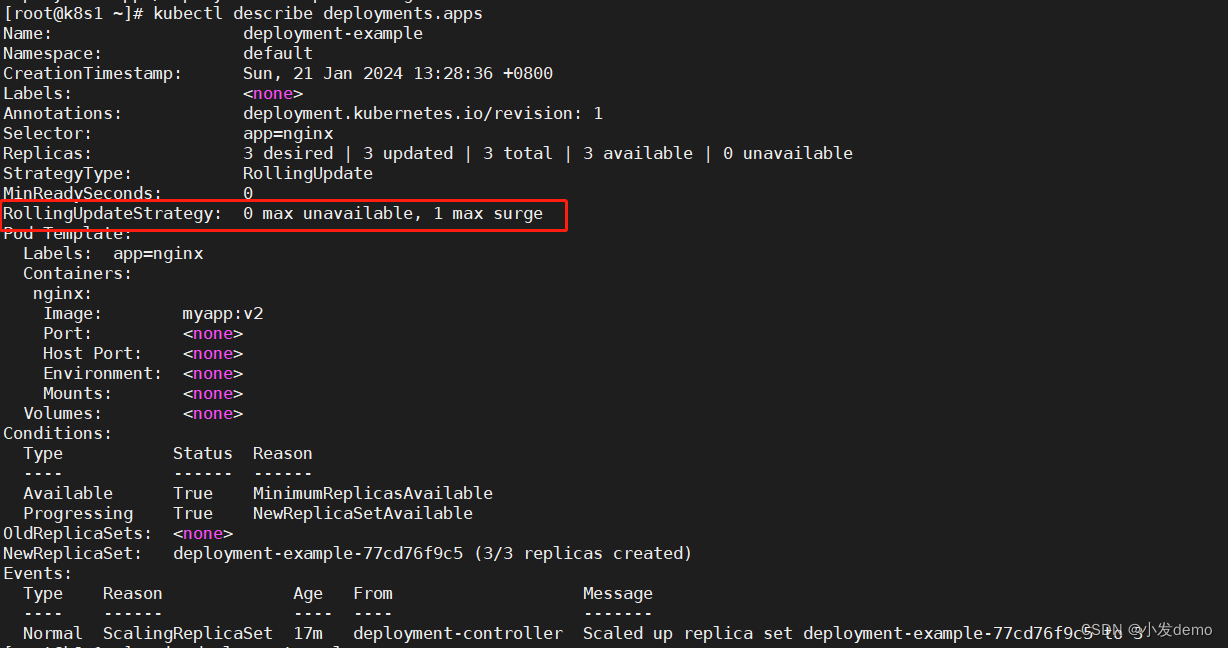
查看pod详细信息:
kubectl get pod deployment-example-XXX -o yaml暂停、回复Deployment的上限过程:
kubectl rollout pause deployment deployment-example此时pod正常运行,但是版本未更新
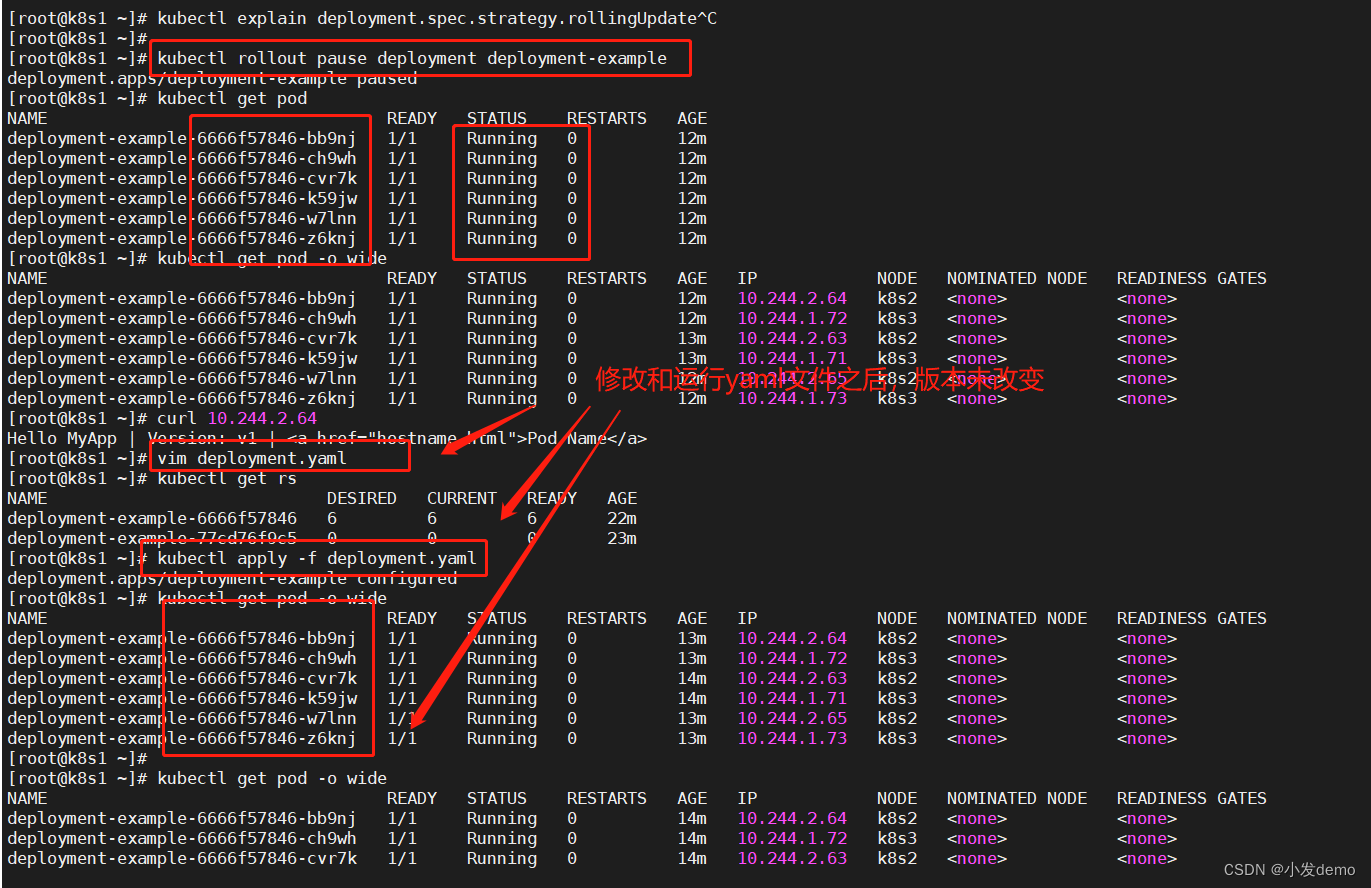
查看deployment上线过程

恢复上线:
kubectl rollout resume deployment deployment-example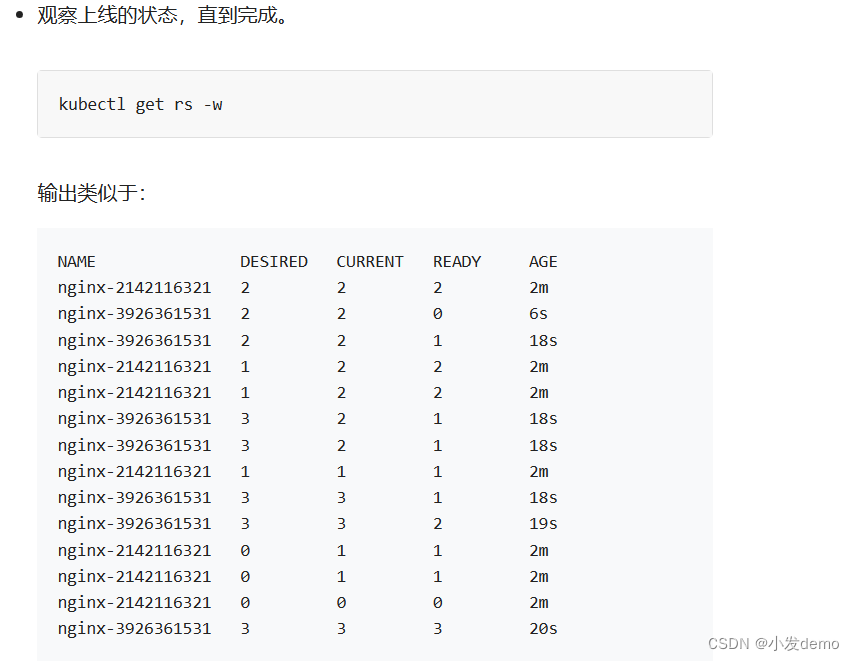
DaemonSet控制器:
DaemonSet 确保全部(或者某些)节点上运行一个 Pod 的副本。当有节点加入集群时, 也会为他们新增一个 Pod 。当有节点从集群移除时,这些Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod 。例如在搭建集群事所使用的kube-flannel.yml网络插件使用的就是此类型控制器。 DaemonSet 的典型用法:在每个节点上运行集群存储 DaemonSet ,例如 glusterd 、 ceph 。在每个节点上运行日志收集 DaemonSet ,例如 fluentd 、 logstash 。在每个节点上运行监控 DaemonSet ,例如 Prometheus Node Exporter、 zabbix agent等。一个简单的用法是在所有的节点上都启动一个 DaemonSet ,将被作为每种类型的 daemon 使用。一个稍微复杂的用法是单独对每种 daemon 类型使用多个 DaemonSet ,但具有不同的标志, 并且对不同硬件类型具有不同的内存、CPU 要求。
DaemonSet 的典型用法:在每个节点上运行集群存储 DaemonSet ,例如 glusterd 、 ceph 。在每个节点上运行日志收集 DaemonSet ,例如 fluentd 、 logstash 。在每个节点上运行监控 DaemonSet ,例如 Prometheus Node Exporter、 zabbix agent等。一个简单的用法是在所有的节点上都启动一个 DaemonSet ,将被作为每种类型的 daemon 使用。一个稍微复杂的用法是单独对每种 daemon 类型使用多个 DaemonSet ,但具有不同的标志, 并且对不同硬件类型具有不同的内存、CPU 要求。
示例:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: daemonset-example
labels:
k8s-app: zabbix-agent
spec:
selector:
matchLabels:
name: zabbix-agent
template:
metadata:
labels:
name: zabbix-agent
spec:
containers:
- name: zabbix-agent
image: nginx
# tolerations:
# - operator: Exists
# effect: NoSchedule
#污点
daemonset一般被调度在worker节点上,master节点一般负责核心组件,不参与调度

此时只有k8s2和k8s3被调度:

去掉注释之后,重新运行之后,此时k8s1也参与调度:

污点
容忍
job控制器:
执行批处理任务,仅执行一次任务,保证任务的一个或多个 Pod 成功结束Job用来做离线任务
示例:
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: perl:5.34.0
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
backoffLimit: 4此时Job运行完毕之后就终止
查看Job信息:
kubectl logs pi-t5ts6查看该pod由谁创建:
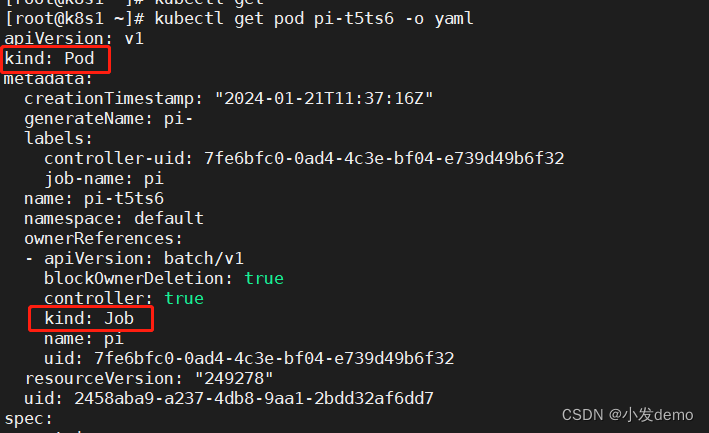
创建多个任务:
cat busybox-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: busybox-job
spec:
parallelism: 1
completions: 5
#需要执行5次任务才算完成
template:
spec:
containers:
- name: busybox
image: busybox:latest
command: [ "/bin/sh", "-c", "sleep 20s" ]
restartPolicy: OnFailure三种Job的执行方式:

CronJob控制器:
Cron Job 创建基于时间调度的 Jobs 。一个 CronJob 对象就像 crontab (cron table) 文件中的一行,它用 Cron 格式进行编写,并周期性地在给定的调度时间执行 Job.
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: cronjob-example
spec:
schedule: "* * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: cronjob
image: busybox
args:
- /bin/sh
- -c
- date; echo Hello from k8s cluster
restartPolicy: OnFailure

关系: CronJob --> Job --> Pod
此时查看的是Job控制器:
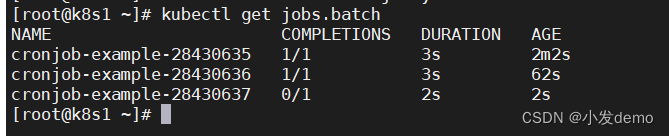
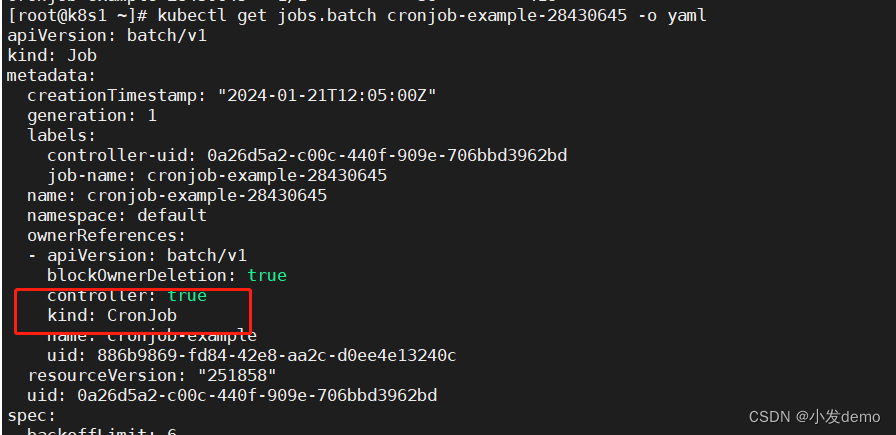
Job控制器由CronJob创建
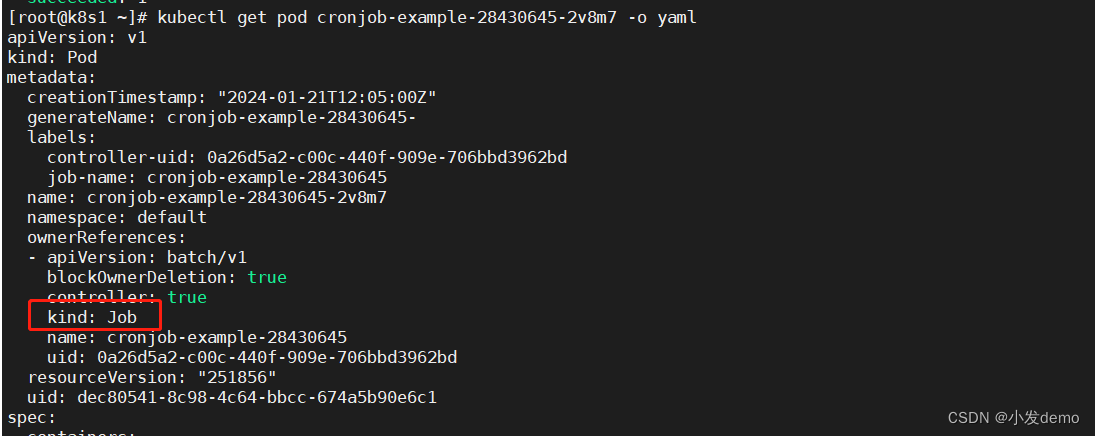
Pod由Job控制器创建:
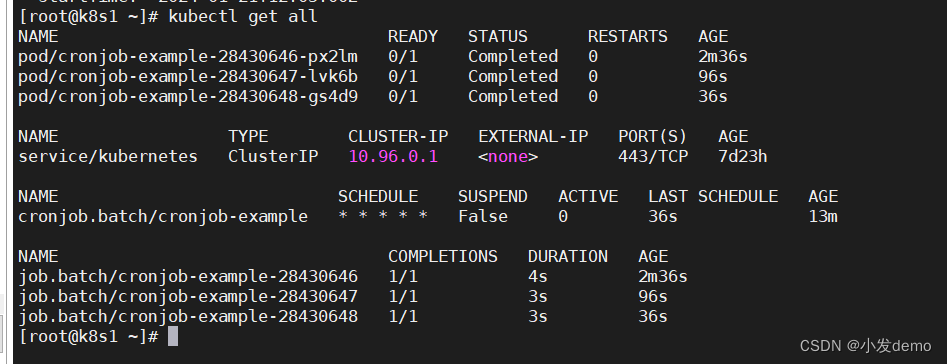
服务Servie(SVC):
Service可以看作是一组提供相同服务的 Pod 对外的访问接口。借助 Service ,应用可以方便地实现服务发现和负载均衡。service默认只支持 4 层负载均衡能力,没有 7 层功能。(可以通过 Ingress 实现和扩展)service 的类型:ClusterIP:默认值, k8s 系统给 service 自动分配的虚拟 IP ,只能在集群内部访问。NodePort:将 Service通过指定的Node上的端口暴露给外部,访问任意一个NodeIP:nodePort都将路由到 ClusterIP。LoadBalancer:在 NodePort 的基础上,借助 cloud provider 创建一个外部的负载均衡器,并将请求转发到 <NodeIP>:NodePort ,此模式只能在云服务器上使用。ExternalName:将服务通过 DNS CNAME 记录方式转发到指定的域名(通过spec.externlName 设定)
Service 是由 kube-proxy 组件,加上 iptables 来共同实现的kube-proxy 通过 iptables 处理 Service 的过程,需要在宿主机上设置相当多的iptables规则,如果宿主机有大量的 Pod ,不断刷新 iptables 规则,会消耗大量的 CPU资源。IPVS 模式的 service ,可以使 K8s 集群支持更多量级的 Pod 。
# yum install -y ipvsadm
//所有节点安装
kubectl edit cm kube-proxy -n kube-system
//修改IPVS模式
mode: "ipvs"
kubectl get pod -n kube-system |grep kube-proxy | awk '{system("kubectl delete pod "$1" -n kube-system")}'
//更新kube-proxy pod开启之后,k8s可以支持更多的pod数量,也可以降低cpu资源消耗


k8s通过 CNI 接口接入其他插件来实现网络通讯。目前比较流行的插件有 flannel , calico 等。CNI插件存放位置: # cat /etc/cni/net.d/10-flannel.conflist插件使用的解决方案如下:虚拟网桥,虚拟网卡,多个容器共用一个虚拟网卡进行通信。多路复用:MacVLAN ,多个容器共用一个物理网卡进行通信。硬件交换:SR-LOV,一个物理网卡可以虚拟出多个接口,这个性能最好。容器间通信:同一个 pod 内的多个容器间的通信,通过 lo 即可实现;pod 之间的通信:同一节点的pod 之间通过 cni 网桥转发数据包。不同节点的pod 之间的通信需要网络插件支持。pod和 service 通信 : 通过 iptables 或 ipvs 实现通信, ipvs 取代不了 iptables ,因为 ipvs 只能做负载均衡,而做不了nat 转换。pod 和外网通信: iptables 的 MASQUERADE 。Service 与集群外部客户端的通信;( ingress 、 nodeport 、 loadbalancer )
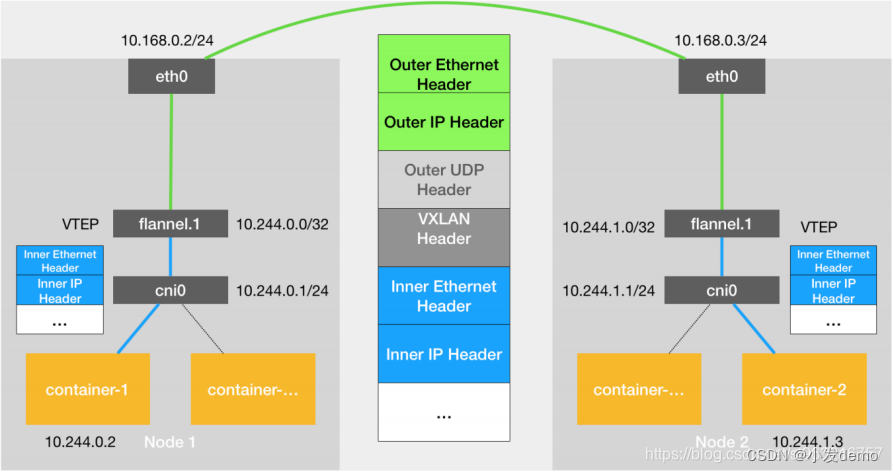
VXLAN,即 Virtual Extensible LAN (虚拟可扩展局域网),是 Linux 本身支持的一网种网络虚拟化技术。VXLAN 可以完全在内核态实现封装和解封装工作,从而通过“隧道”机制,构建 出覆盖网络(Overlay Network )。VTEP:VXLAN Tunnel End Point (虚拟隧道端点),在 Flannel 中 VNI 的默认值是 1 ,这也是为什么宿主机的VTEP 设备都叫 flannel.1 的原因。Cni0: 网桥设备,每创建一个pod 都会创建一对 veth pair 。其中一端是 pod 中的 eth0 ,另一端是Cni0 网桥中的端口(网卡)。Flannel.1: TUN设备( 虚拟网卡 ) ,用来进行 vxlan 报文的处理(封包和解包)。不同 node 之间的pod 数据流量都从 overlay 设备以隧道的形式发送到对端。Flanneld:flannel 在每个主机中运行 flanneld 作为 agent ,它会为所在主机从集群的网络地址空间中,获取一个小的网段subnet ,本主机内所有容器的 IP 地址都将从中分配。同时Flanneld 监听 K8s 集群数据库,为 flannel.1 设备提供封装数据时必要的 mac 、 ip 等网络数据信息。
当容器发送IP 包,通过 veth pair 发往 cni 网桥,再路由到本机的 flannel.1 设备进行处理。VTEP设备之间通过二层数据帧进行通信,源 VTEP 设备收到原始 IP 包后,在上面加上一个目的MAC 地址,封装成一个内部数据帧,发送给目的 VTEP 设备。内部数据桢,并不能在宿主机的二层网络传输,Linux 内核还需要把它进一步封装成为宿主机的一个普通的数据帧,承载着内部数据帧通过宿主机的eth0 进行传输。Linux会在内部数据帧前面,加上一个VXLAN 头, VXLAN 头里有一个重要的标志叫VNI,它是 VTEP 识别某个数据桢是不是应该归自己处理的重要标识。flannel.1设备只知道另一端flannel.1 设备的 MAC 地址,却不知道对应的宿主机地址是什么。在linux 内核里面,网络设备进行转发的依据,来自 FDB 的转发数据库,这个flannel.1网桥对应的 FDB 信息,是由 flanneld 进程维护的。linux内核在 IP 包前面再加上二层数据帧头,把目标节点的 MAC 地址填进去, MAC 地址从宿主机的ARP 表获取。此时flannel.1设备就可以把这个数据帧从 eth0 发出去,再经过宿主机网络来到目标节点的 eth0 设备。目标主机内核网络栈会发现这个数据帧有 VXLAN Header ,并且 VNI为1, Linux内核会对它进行拆包,拿到内部数据帧,根据VNI的值,交给本机flannel.1设备处理, flannel.1 拆包,根据路由表发往 cni 网桥,最后到达目标容器
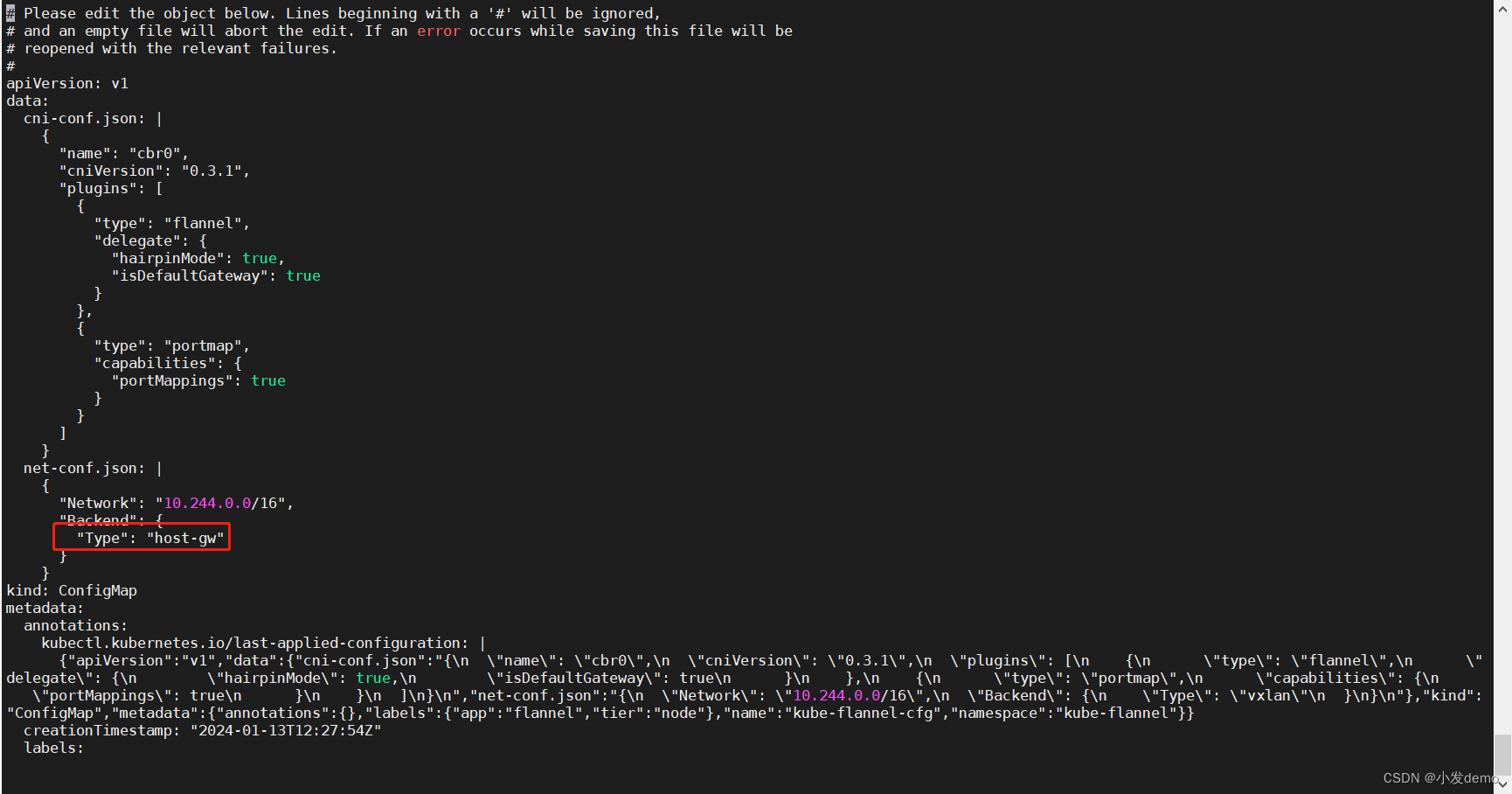
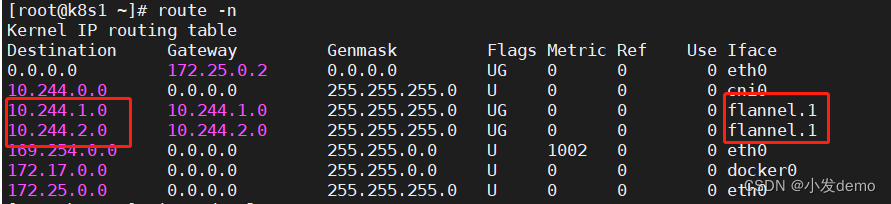
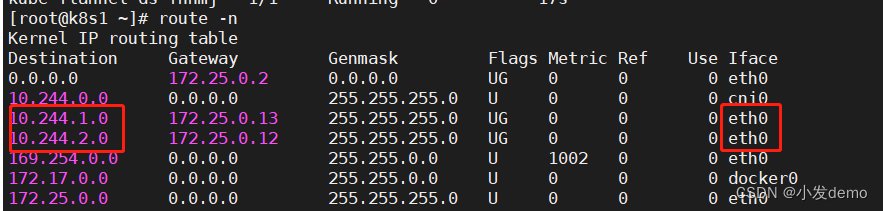
kubectl -n kube-flannel edit cm kube-flannel-cfg
创建service(ClusterIP模式):
可以使用域名和IP地址来访问svc
apiVersion: v1
kind: Service
metadata:
name: svc1
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: nginx
type: ClusterIP在拉起控制器的yaml文件(指定副本数为3即可)和svc的yaml文件之后
我们可以通过dig来查询集群内svc的IP地址
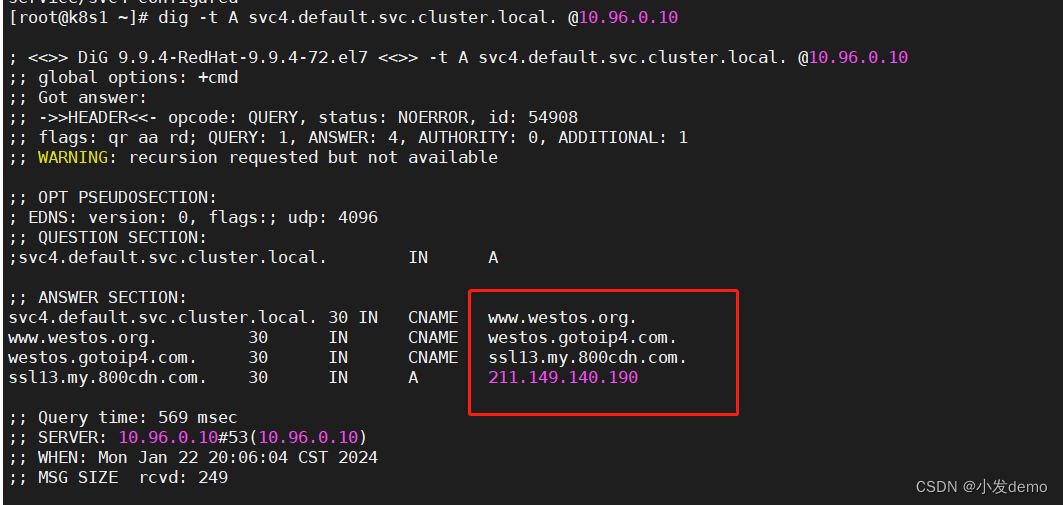
[root@k8s1 ~]# dig -t A svc1.default.svc.cluster.local. @10.96.0.10
#svc1是控制器的名称,default是控制器所在的namespace,后面的svc.cluster.local是固定写法
#@10.96.0.10需要加上,否则查询出的是虚拟机的解析
; <<>> DiG 9.9.4-RedHat-9.9.4-72.el7 <<>> -t A svc1.default.svc.cluster.local. @10.96.0.10
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 50926
;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
;; QUESTION SECTION:
;svc1.default.svc.cluster.local. IN A
;; ANSWER SECTION:
svc1.default.svc.cluster.local. 30 IN A 10.98.187.234
此时看到svc被解析出来
;; Query time: 1 msec
;; SERVER: 10.96.0.10#53(10.96.0.10)
;; WHEN: Mon Jan 22 17:55:41 CST 2024
;; MSG SIZE rcvd: 105
[root@k8s1 ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 8d
svc1 ClusterIP 10.98.187.234 <none> 80/TCP 10m
再通过创建的pod来访问:
kubectl run demo -it --rm --image=busyboxplus[root@k8s1 ~]# kubectl run demo -it --rm --image=busyboxplus
If you don't see a command prompt, try pressing enter.
/ # nslookup svc1.default.svc.cluster.local.
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: svc1.default.svc.cluster.local.
Address 1: 10.98.187.234 svc1.default.svc.cluster.local
/ # curl svc1
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
/ # cat /etc/resolv.conf
nameserver 10.96.0.10
search default.svc.cluster.local svc.cluster.local cluster.local
options ndots:5
/ # nslookup kubernetes
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: kubernetes
Address 1: 10.96.0.1 kubernetes.default.svc.cluster.local
/ # Session ended, resume using 'kubectl attach demo -c demo -i -t' command when the pod is running
pod "demo" deleted
[root@k8s1 ~]# kubectl run demo -it --rm --image=busyboxplus
If you don't see a command prompt, try pressing enter.
/ # nslookup kube-dns.kube-system
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: kube-dns.kube-system
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local[root@k8s1 ~]# kubectl get svc -A
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 8d
default svc1 ClusterIP 10.98.187.234 <none> 80/TCP 13m
kube-system kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 8d无头服务:
Headless Service “ 无头服务 ”:Headless Service 不需要分配一个 VIP ,而是直接以 DNS 记录的方式解析出被代理 Pod的IP 地址。域名格式: $(servicename).$(namespace).svc.cluster.local
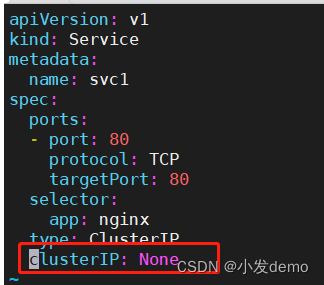

此时解到的IP地址直接解到三个pod上且负载均衡
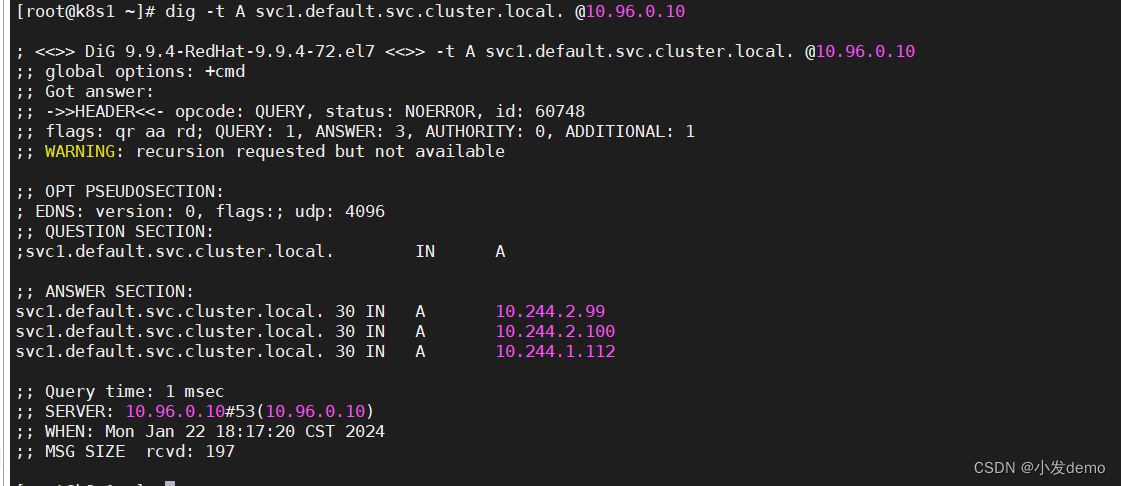

此时不需要解析IP直接访问到pod的IP地址
NodePort方式:
可以通过外部访问
nodeprt方式需要注意,一个节点访问一个端口
创建一个svc2的yaml,delete原来的svc文件
[root@k8s1 ~]# cat svc2.yaml
apiVersion: v1
kind: Service
metadata:
name: svc2
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: nginx
type: NodePort运行之后可以看到svc2的类型是nodeport:

此时就可以通过访问集群任意节点加端口来访问pod:
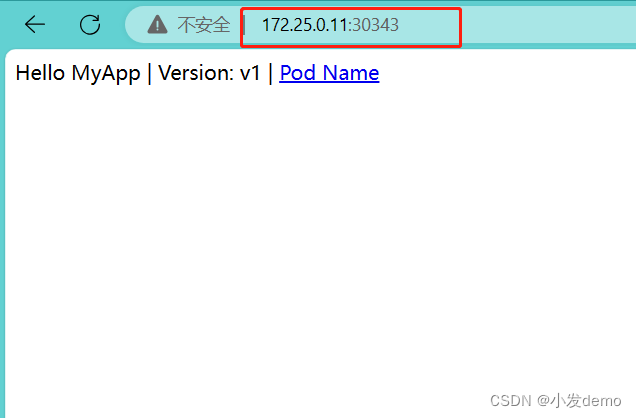
如果我们指定端口为33333:
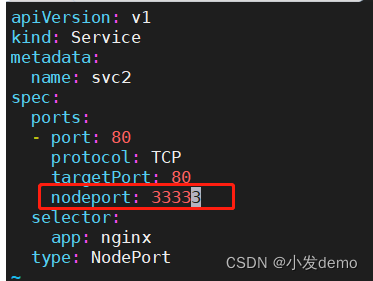
此时再运行svc2.yaml:
报错超过有效端口范围,此时修改k8s的默认端口范围:
vim /etc/kubernetes/manifests/kube-apiserver.yaml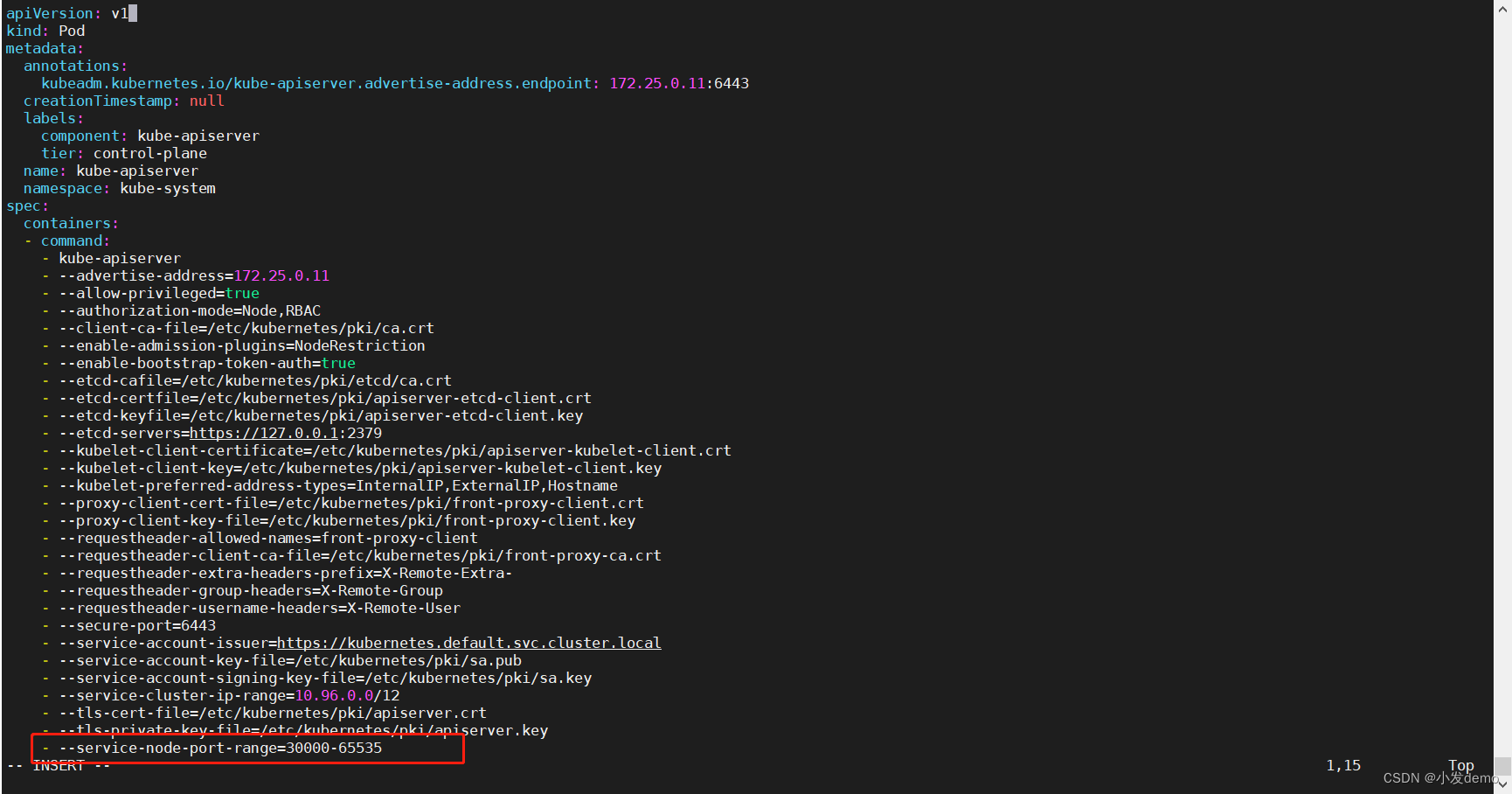
此时kubelet会自动重启apiserver:

短暂等待之后即可连上,如果上时间连不上,检查范围是否书写有误:

此时再运行svc2.yaml文件:

这样可以解决pod过多而端口不够使用
LoadBalancer(metallb):
同样可以通过外部访问
从外部访问 Service 的第二种方式,适用于公有云上的 Kubernetes 服务。这时候,你可以指定一个 LoadBalancer 类型的 Service。在 service 提交后, Kubernetes 就会调用 CloudProvider 在公有云上为你创建一个负载均衡服务,并且把被代理的 Pod 的 IP 地址配置给负载均衡服务做后端。
[root@k8s1 ~]# mkdir metallb拉取yaml文件:
没有wget则需要下载,可能需要多拉取几次
wget https://raw.githubusercontent.com/metallb/metallb/v0.13.7/config/manifests/metallb-native.yaml对于metallb-native.yaml,我们需要更改镜像拉取位置:
image: metallb/controller:v0.13.7
image: metallb/speaker:v0.13.7此时我们登录harbor仓库,创建metallb库:
docker pull quay.io/metallb/controller:v0.13.7
docker pull quay.io/metallb/speaker:v0.13.7然后给镜像打标签,上传镜像:
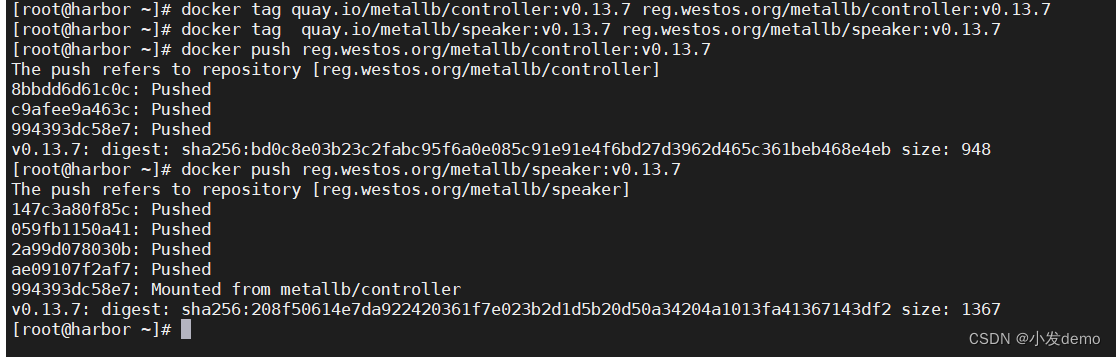
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: first-pool
namespace: metallb-system
spec:
addresses:
- 172.25.0.100-172.25.0.200
网络地址段
---
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: example
namespace: metallb-system
#如果有多个地址池
spec:
ipAddressPools:
- first-pool
#则可以从ipAddressPools中进行选择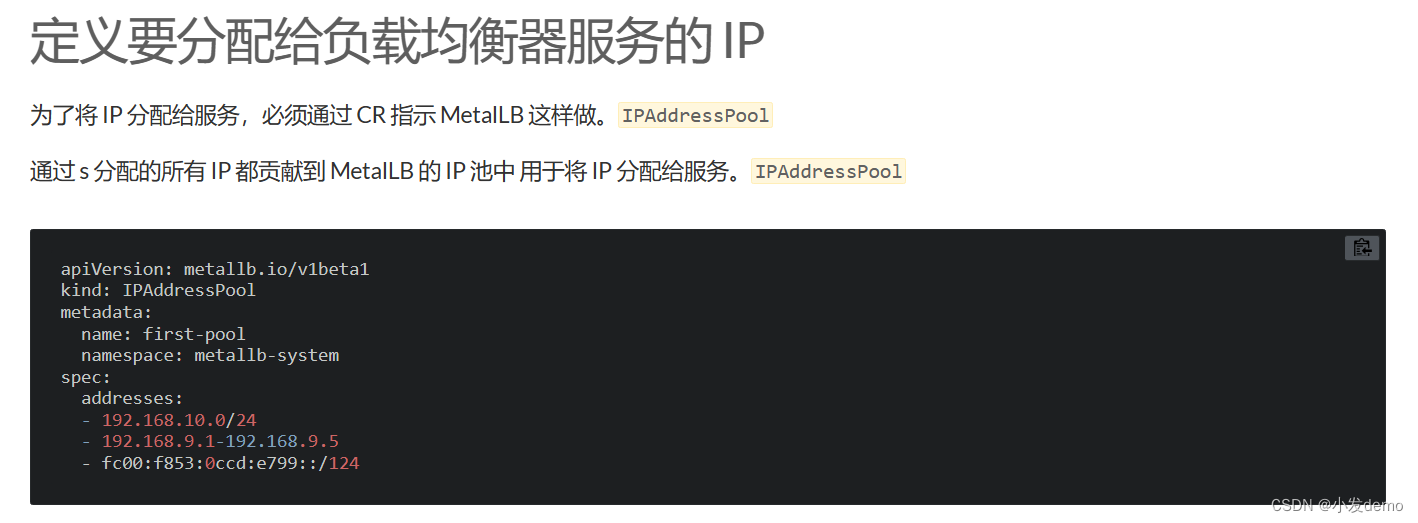
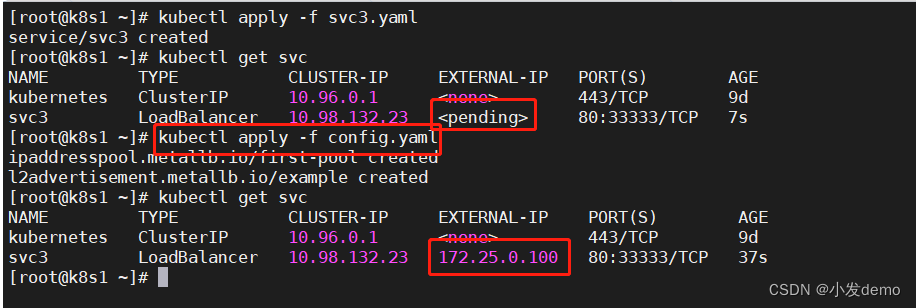
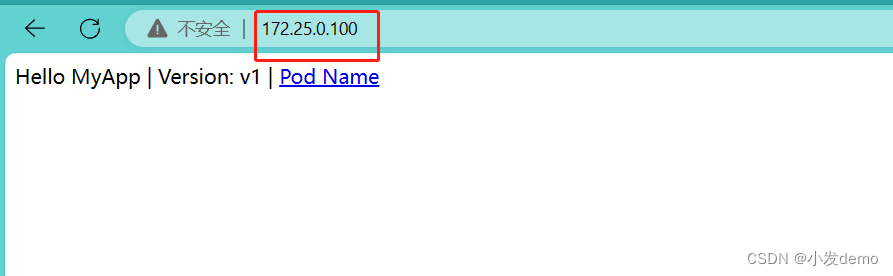
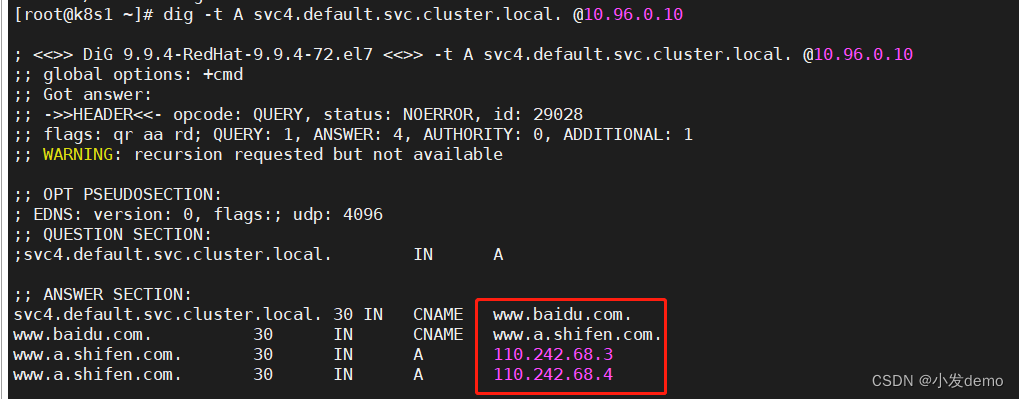
ExternalName:
apiVersion: v1
kind: Service
metadata:
name: svc4
spec:
type: ExternalName
externalName: www.baidu.com对于集群之间的相互访问,而外部的集群访问不稳定会随之而更改,此时需要在稳定的集群内部做出最小的改变来访问其他集群
Ingress:
一种全局的、为了代理不同后端 Service 而设置的负载均衡服务,就是 Kubernetes 里的Ingress 服务。Ingress由两部分组成: Ingress controller 和 Ingress 服务。Ingress Controller 会根据你定义的 Ingress 对象,提供对应的代理能力。业界常用的各种反向代理项目,比如 Nginx 、 HAProxy 、 Envoy 、 Traefik 等,都已经为 Kubernetes 专门维护了对应的 Ingress Controller 。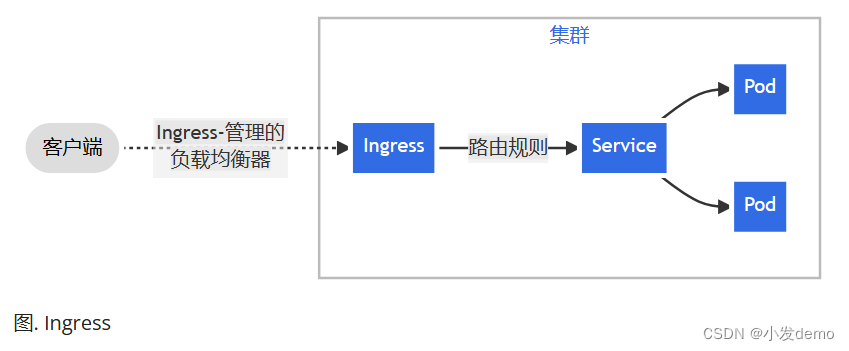
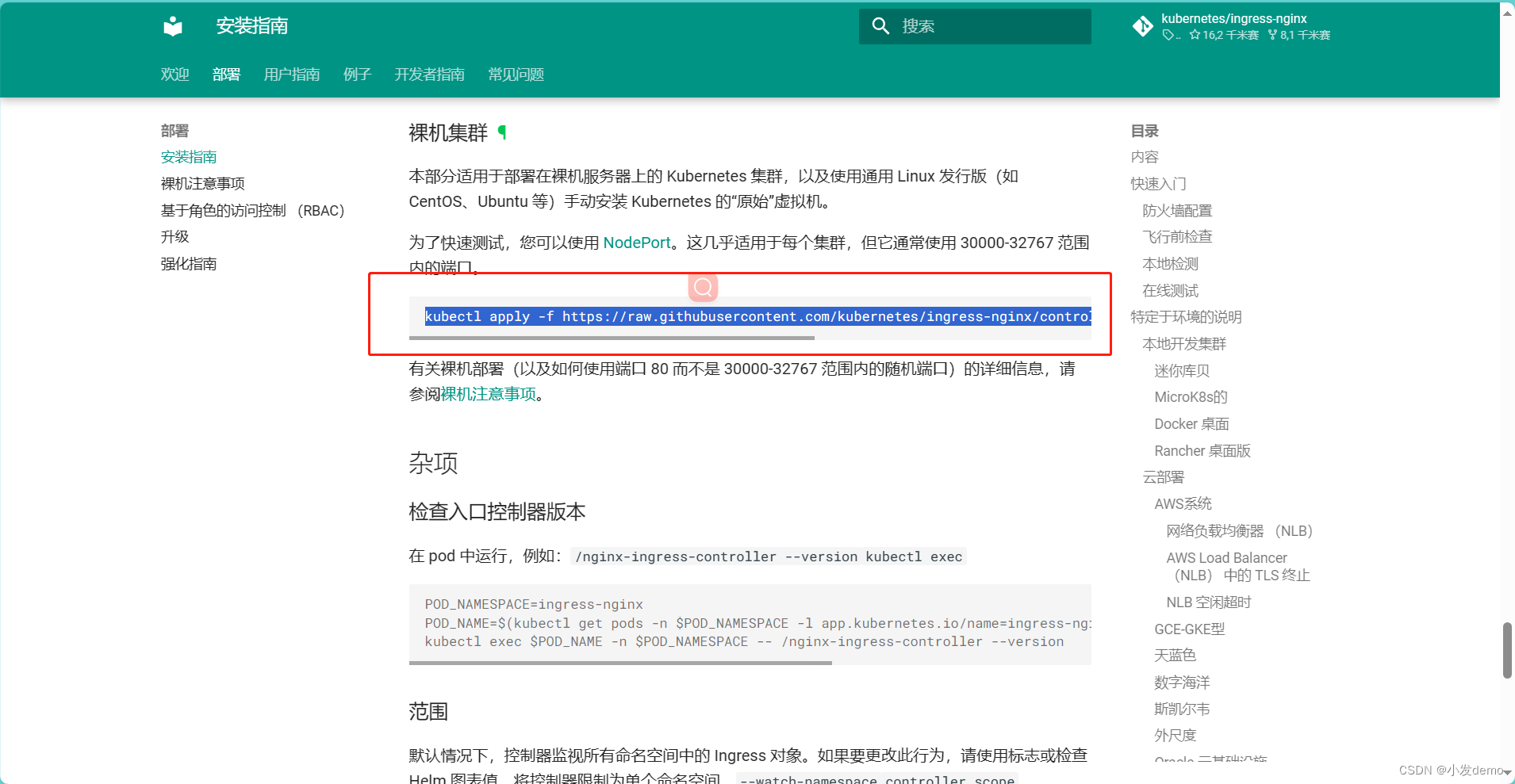
mkdir ingress
wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.4.0/deploy/static/provider/baremetal/deploy.yaml我们使用1.4.0版本即可,如果拉取不下来记得多拉取几次
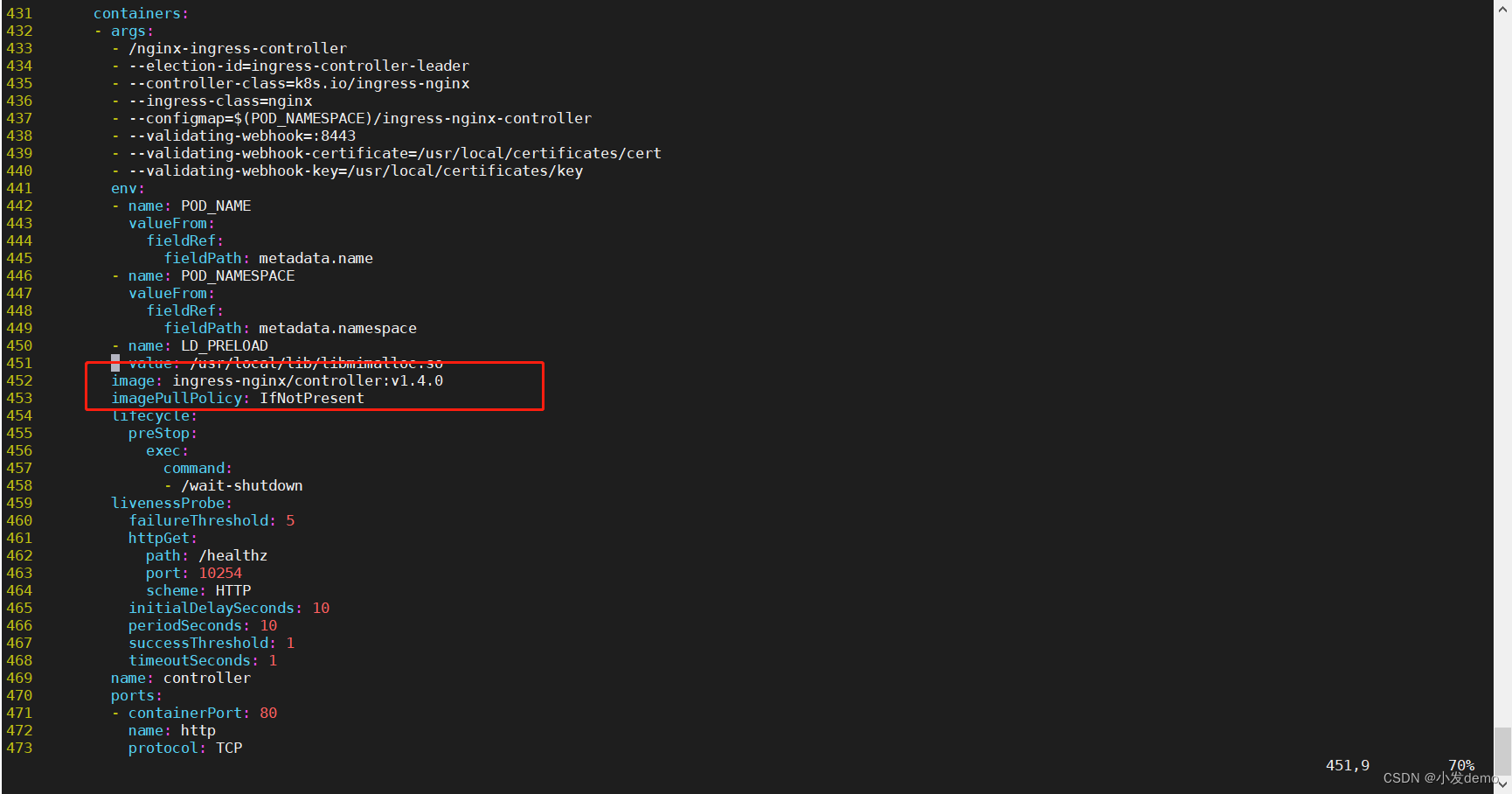
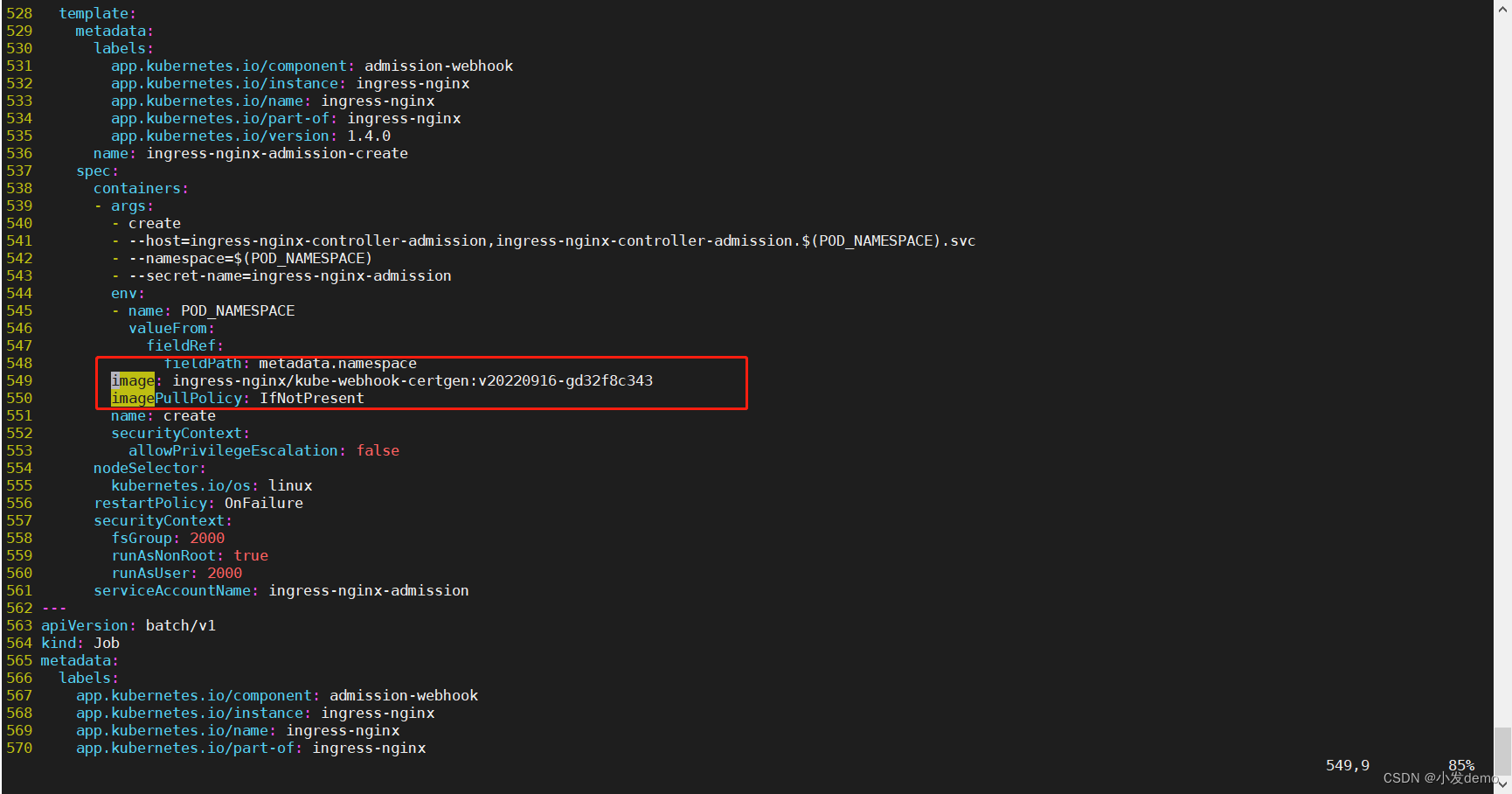
拉取下来之后更改镜像位置,一共需要拉取两个镜像,更改位置有两处:
docker pull echolixiaopeng/ingress-nginx-controller:v1.4.0
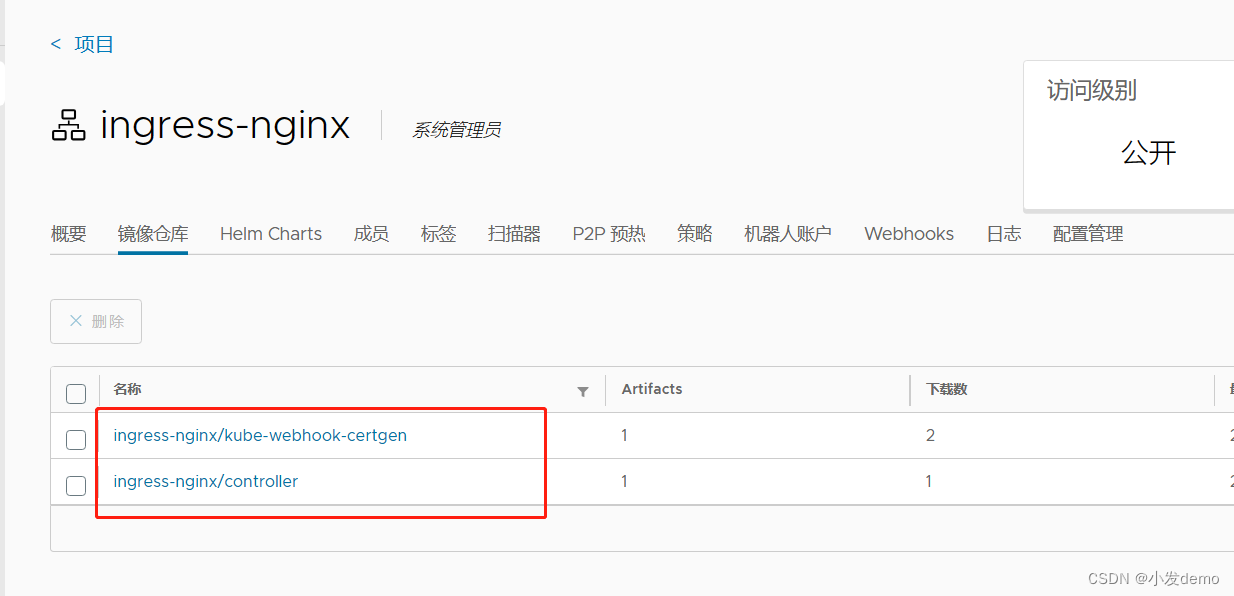
docker pull xin053/kube-webhook-certgen:v20220916-gd32f8c343在harbor仓库新建ingress-nginx仓库设为公共,然后更改标签和上传镜像
root@k8s1 ingress]# kubectl apply -f deploy.yaml
[root@k8s1 ingress]# kubectl get all -n ingress-nginx
NAME READY STATUS RESTARTS AGE
pod/ingress-nginx-admission-create-ch9bc 0/1 Completed 0 15h
pod/ingress-nginx-admission-patch-lm5dz 0/1 Completed 0 15h
pod/ingress-nginx-controller-5d67f9886-4zv6j 1/1 Running 1 (14h ago) 15h
#主要看pod/ingress-nginx-controller-5d67f9886-4zv6j是否running
#pod/ingress-nginx-controller-5d67f9886-4zv6j实际封装的就是nginx
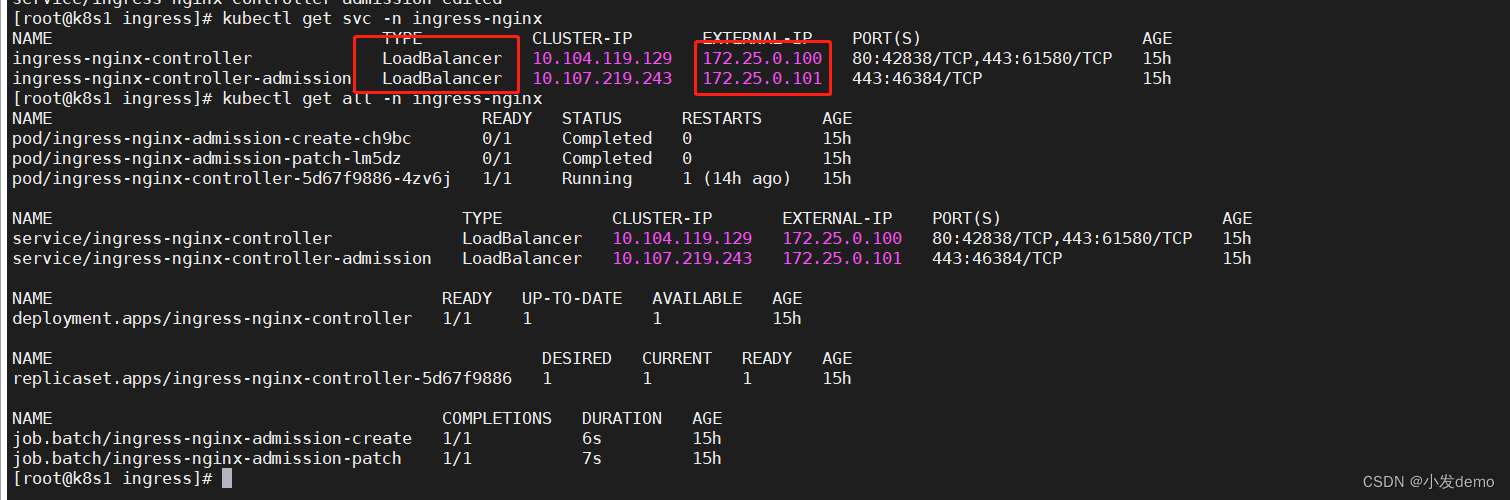
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/ingress-nginx-controller LoadBalancer 10.104.119.129 172.25.0.100 80:42838/TCP,443:61580/TCP 15h
service/ingress-nginx-controller-admission ClusterIP 10.107.219.243 <none> 443/TCP 15h
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/ingress-nginx-controller 1/1 1 1 15h
NAME DESIRED CURRENT READY AGE
replicaset.apps/ingress-nginx-controller-5d67f9886 1 1 1 15h
NAME COMPLETIONS DURATION AGE
job.batch/ingress-nginx-admission-create 1/1 6s 15h
job.batch/ingress-nginx-admission-patch 1/1 7s 15h
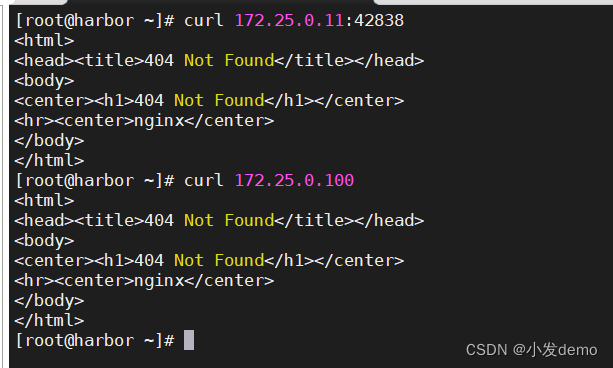
我们可以设置svc的暴露方式,通过mrtallb目录下的config.yaml文件从LousterIP改为Load Balancer:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: demo-ingress
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
#rewrite-target: 重定向到跟路径
spec:
ingressClassName: nginx
rules:
- http:
paths:
- path: /foo
pathType: Prefix
backend:
service:
name: svc1
port:
number: 80
paths:
- path: /bar
pathType: Prefix
backend:
service:
name: svc2
port:
number: 80
创建第二个服务以实现效果:
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-myapp
spec:
#minReadySeconds: 3
strategy:
rollingUpdate:
maxSurge: 2
maxUnavailable: 0
replicas: 3
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp
image: myapp:v2
---
apiVersion: v1
kind: Service
metadata:
name: svc2
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: myapp
type: ClusterIP
此时运行第二个deployment,在harbor查看效果:

apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: demo-ingress
#annotations:
# nginx.ingress.kubernetes.io/rewrite-target: /
spec:
ingressClassName: nginx
rules:
- host: www1.westos.org
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: svc1
port:
number: 80
- host: www2.westos.org
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: svc2
port:
number: 80
在基于域名访问时,需要在harbor节点加上解析,否则访问不到:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
172.25.0.10 harbor reg.westos.org
172.25.0.11 k8s1
172.25.0.12 k8s2
172.25.0.13 k8s3
172.25.0.14 k8s4
172.25.0.15 k8s5
172.25.0.16 k8s6
172.25.0.100 www1.westos.org www2.westos.org用DaemonSet结合nodeselector来部署ingress-controller到特定的node上,然后使用HostNetwork直接把该pod与宿主机node的网络打通,直接使用宿主机的80/443端口就能访问服务
优点是整个请求链路最简单,性能相对NodePort模式更好。
缺点是由于直接利用宿主机节点的网络和端口,一个node只能部署一个ingress-controller pod。
比较适合大并发的生产环境使用
#修改ingress controller部署文件
vim mandatory.yaml
kind: DaemonSet //改为DaemonSet控制器
replicas: 1 //删除replicas
hostNetwork: true //使用HostNetwork
nodeSelector: //修改节点选择
type: "ingress"
设置ingress controller节点的标签
kubectl label nodes server6 type=ingress
TLS配置:
创建证书:
注意创建的证书和svc或者其他,需要调用时,他们应该在同一域(namespace)内
openssl req -x509 -sha256 -nodes -days 365 -newkey rsa:2048 -keyout tls.key -out tls.crt -subj "/CN=nginxsvc/O=nginxsvc"
#移动到ingress下
mv tls.crt tls.key ingress/
[root@k8s1 ~]# kubectl get secrets
NAME TYPE DATA AGE
basic-auth Opaque 1 3h16m
default-token-67c64 kubernetes.io/service-account-token 3 9d
tls-secret kubernetes.io/tls 2 3h32m
创建新的yaml文件来认证和加密:
官网:Welcome - Ingress-Nginx Controller
加密:
vim ingress-https.yamlapiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-https
#annotations:
# nginx.ingress.kubernetes.io/rewrite-target: /
spec:
tls:
- hosts:
- www1.westos.org
secretName: tls-secret
ingressClassName: nginx
rules:
- host: www1.westos.org
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: svc1
port:
number: 80
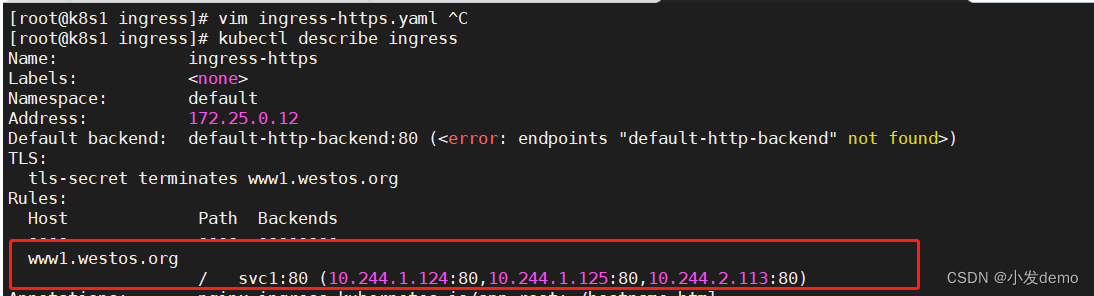
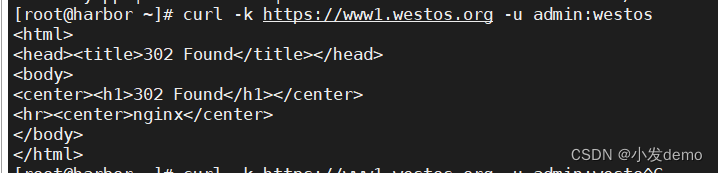
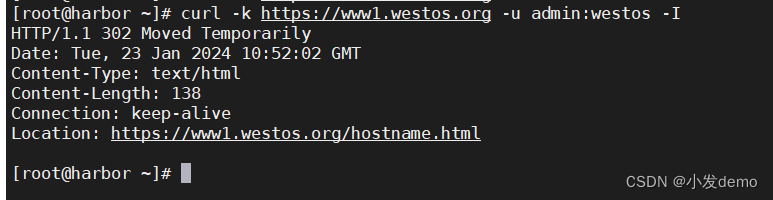
curl -I www1.westos.org
curl -k https://www1.westos.org
#-k 不校验证书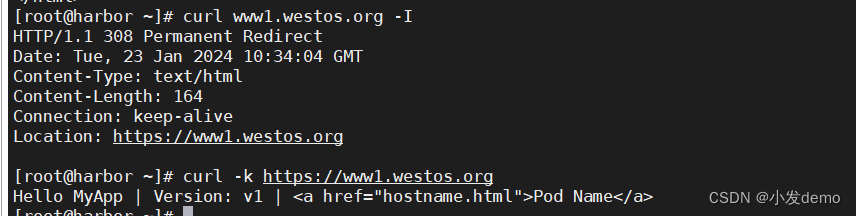
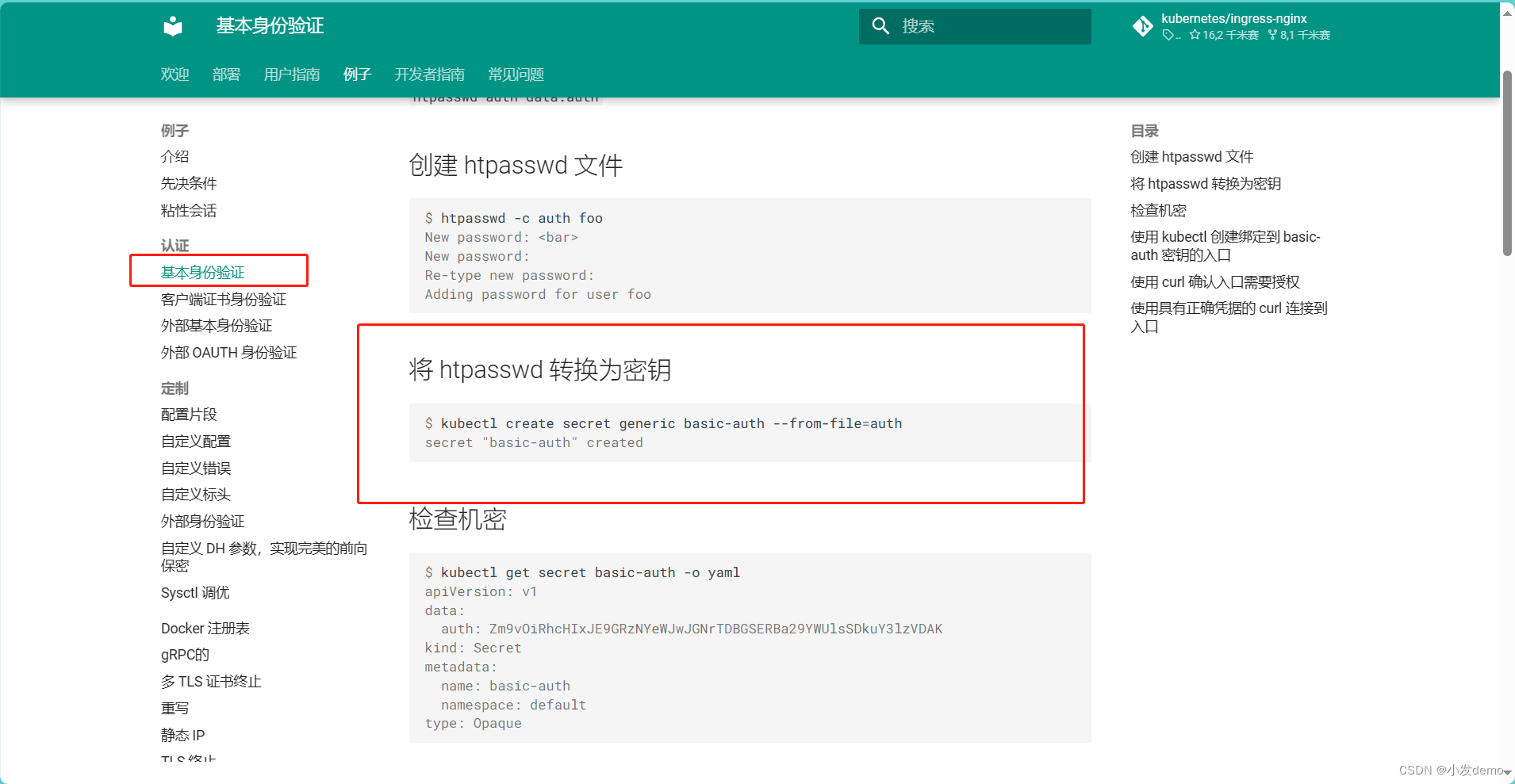
yum install -y httpd-tools.x86_64htpasswd -Bc auth admin
admin将资源创建到集群中:
kubectl create secret generic basic-auth --from-file=auth
kubectl get secret basic-auth -o yaml
查看继续写入配置:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-https
annotations:
nginx.ingress.kubernetes.io/auth-type: basic
#激活认证
nginx.ingress.kubernetes.io/auth-secret: basic-auth
#使用secret
nginx.ingress.kubernetes.io/auth-realm: 'Authentication Required - admin'
#输出信息
# nginx.ingress.kubernetes.io/rewrite-target: /
spec:
tls:
- hosts:
- www1.westos.org
secretName: tls-secret
ingressClassName: nginx
rules:
- host: www1.westos.org
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: svc1
port:
number: 80
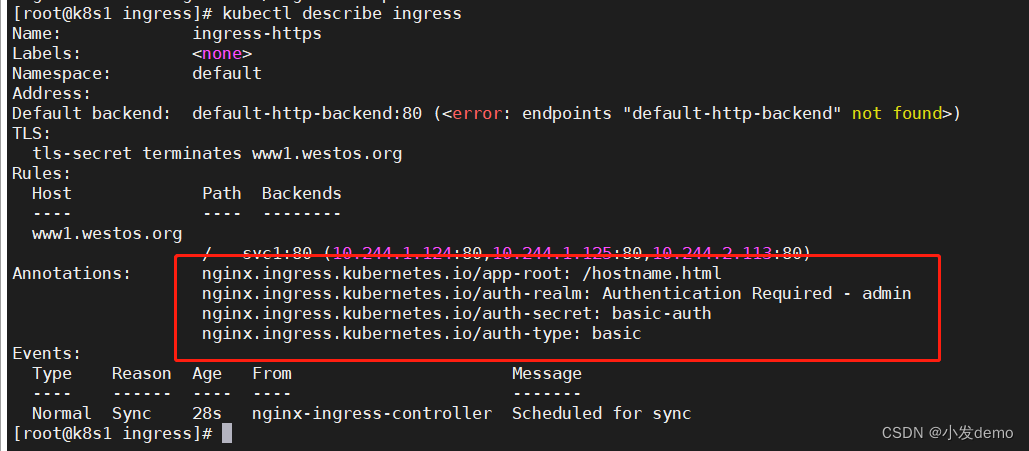
重新运行,然后再harbor访问,此时需要输入用户名和密码:
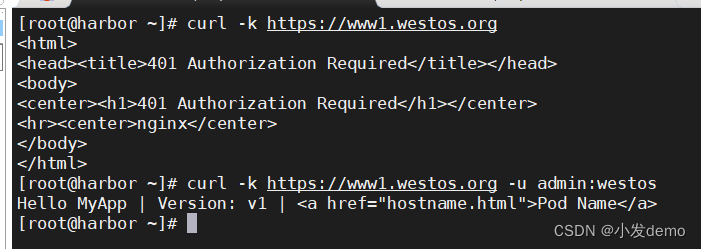
重定向:
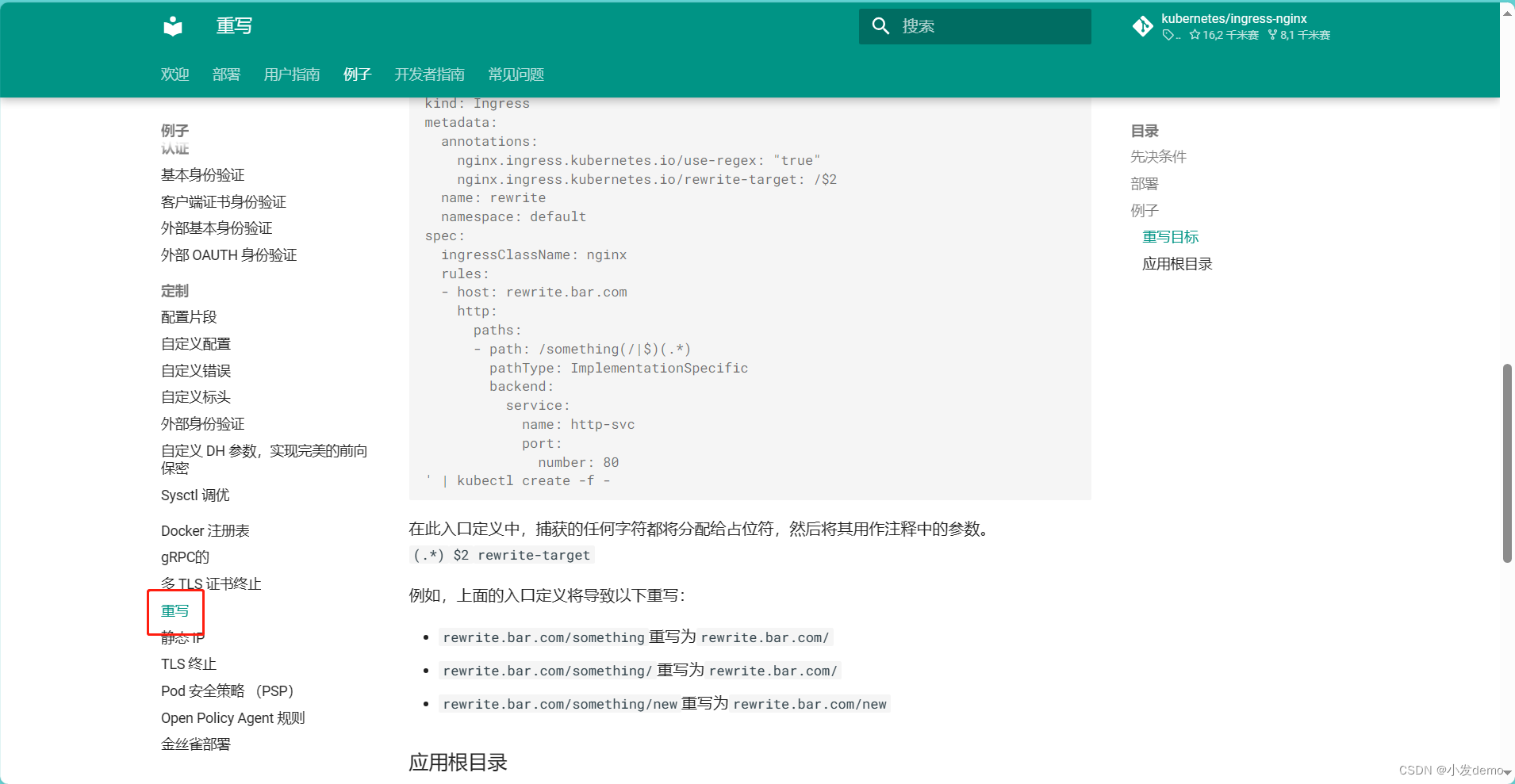
在ingress-https.yaml中加入:
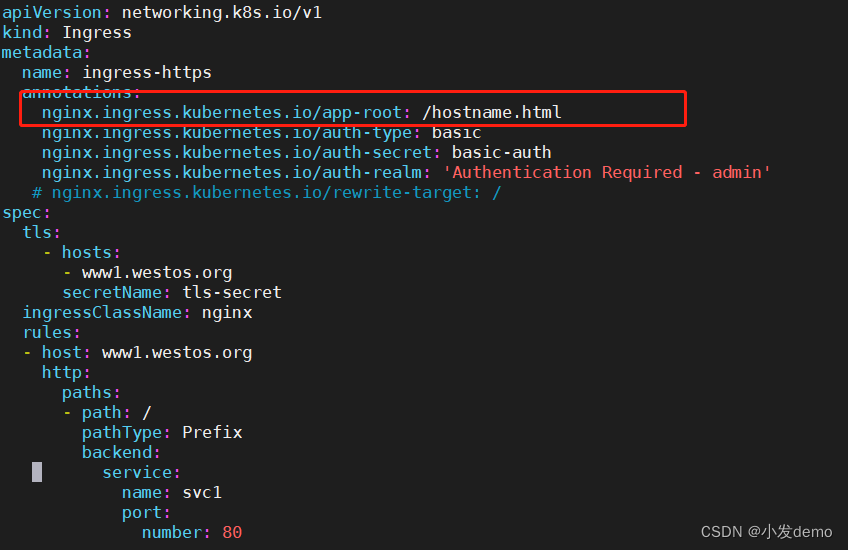
重定向的规则
(HTTP/FTP/FILE) Fetch the HTTP-header only! HTTP-servers feature the command HEAD which this uses to get nothing but the header of a document. When used on an FTP or FILE file, curl displays the file size and last modification time only.
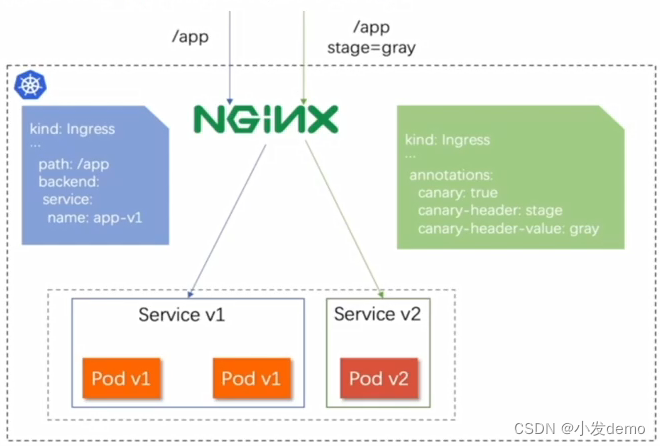
金丝雀发布(灰度发布):

apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: myapp-v1-ingress
spec:
ingressClassName: nginx
rules:
- host: myapp.westos.org
http:
paths:
- pathType: Prefix
path: /
backend:
service:
name: svc1
port:
number: 80
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
nginx.ingress.kubernetes.io/canary: "true"
#nginx.ingress.kubernetes.io/canary-by-header: stage
#nginx.ingress.kubernetes.io/canary-by-header-value: gray
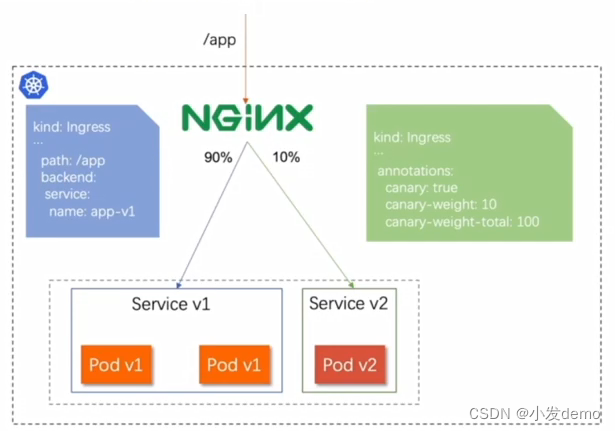
nginx.ingress.kubernetes.io/canary-weight: "40"
#权重
nginx.ingress.kubernetes.io/canary-weightr-total: "100"
#总量
name: myapp-v2-ingress
spec:
ingressClassName: nginx
rules:
- host: myapp.westos.org
http:
paths:
- pathType: Prefix
path: /
backend:
service:
name: svc2
port:
number: 80
使用脚本来查流量分布情况:
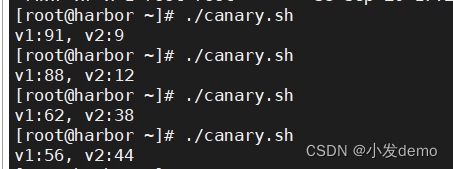
#!/bin/bash
v1=0
v2=0
for (( i=0; i<100; i++))
do
response=`curl -s myapp.westos.org |grep -c v1`
v1=`expr $v1 + $response`
v2=`expr $v2 + 1 - $response`
done
echo "v1:$v1, v2:$v2"Calico网络插件:
calico 简介:flannel实现的是网络通信, calico 的特性是在 pod 之间的隔离。通过BGP 路由,但大规模端点的拓扑计算和收敛往往需要一定的时间和计算资源。纯三层的转发,中间没有任何的NAT 和 overlay ,转发效率最好。Calico 仅依赖三层路由可达。 Calico 较少的依赖性使它能适配所有 VM、 Container、白盒或者混合环境场景。
calico网络架构:Felix:监听ECTD中心的存储获取事件,用户创建pod后,Felix负责将其网卡、IP、MAC都设 置好,然后在内核的路由表里面写一条,注明这个IP应该到这张网卡。同样如果用户制定了隔 离策略,Felix同样会将该策略创建到ACL中,以实现隔离。BIRD:一个标准的路由程序,它会从内核里面获取哪一些IP的路由发生了变化,然后通过标准 BGP的路由协议扩散到整个其他的宿主机上,让外界都知道这个IP在这里,路由的时候到这里来。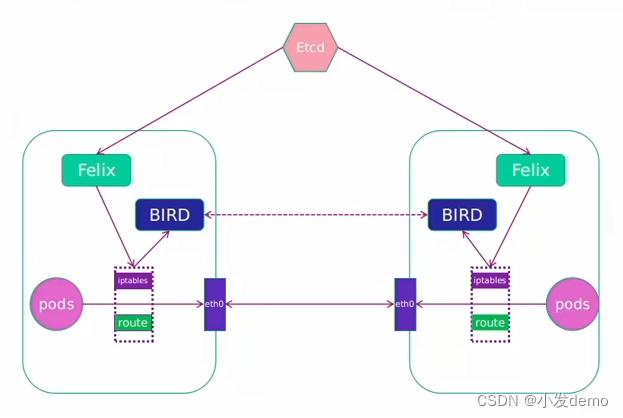
IPIP工作模式:适用于互相访问的pod不在同一个网段中,跨网段访问的场景。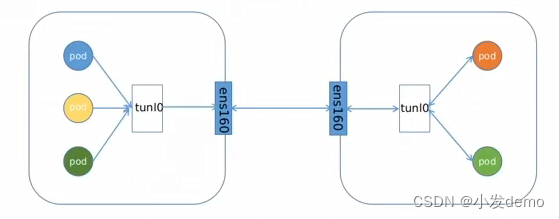 BGP工作模式:适用于互相访问的pod在同一个网段,适用于大型网络。
BGP工作模式:适用于互相访问的pod在同一个网段,适用于大型网络。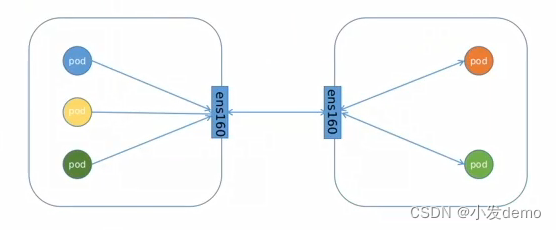
NetworkPolicy策略模型:控制某个namespace下的pod的网络出入站规则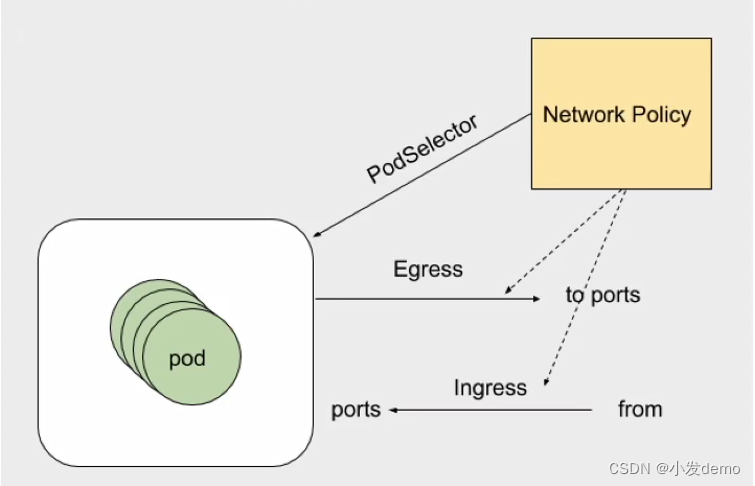
参照官网,我们使用的是3.24.3版本,首先先获取yaml文件:
wget https://raw.githubusercontent.com/projectcalico/calico/v3.24.3/manifests/calico.yaml修改镜像文件位置为calico,然后通过harbor仓库拉取镜像,修改标签并上传,做好本地化处理。
一共有五处,两处cni,两处node,一处controllers
然后拉取镜像:
docker pull docker.io/calico/kube-controllers:v3.24.3
docker pull docker.io/calico/cni:v3.24.3
docker pull docker.io/calico/node:v3.24.3修改标签:
images|grep calico| awk '{system("docker tag "$1":"$2" reg.westos.org/"$1":"$2" ")}'上传harbor之前我们需要建立calico仓库:
images|grep calico| awk '{system("docker tag "$1":"$2" reg.westos.org/"$1":"$2" ")}'
docker images|grep calico|grep -v ^calico| awk '{system (" docker push "$1":"$2" ")}'calico也是一种和flannel类似的网络插件,在运行calico之前,我们需要去除flannel插件:
kubectl delete -f kube-flannel.yml
删除三个节点的flannel文件,注意三个节点都要删除:
rm -rf /etc/cni/net.d/10-flannel.conflist此时再运行calico插件:
kubectl apply -f calico.yaml
[root@k8s1 calico]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-58c694dbfc-rftjk 1/1 Running 1 (15h ago) 17h
calico-node-ctqpc 1/1 Running 1 (15h ago) 17h
calico-node-q5p4h 1/1 Running 1 (41m ago) 17h
calico-node-wk4dw 1/1 Running 1 (15h ago) 17h
coredns-7b56f6bc55-9kjf8 1/1 Running 20 (15h ago) 10d
coredns-7b56f6bc55-rrrjt 1/1 Running 21 (15h ago) 10d
etcd-k8s1 1/1 Running 16 (15h ago) 10d
kube-apiserver-k8s1 1/1 Running 4 (15h ago) 44h
kube-controller-manager-k8s1 1/1 Running 19 (15h ago) 10d
kube-proxy-8skn5 1/1 Running 3 (15h ago) 43h
kube-proxy-f7hh9 1/1 Running 3 (41m ago) 43h
kube-proxy-lphn7 1/1 Running 4 (15h ago) 43h
kube-scheduler-k8s1 1/1 Running 20 (15h ago) 10d
calicorunning之后根据了k8s官网来书写网络策略:
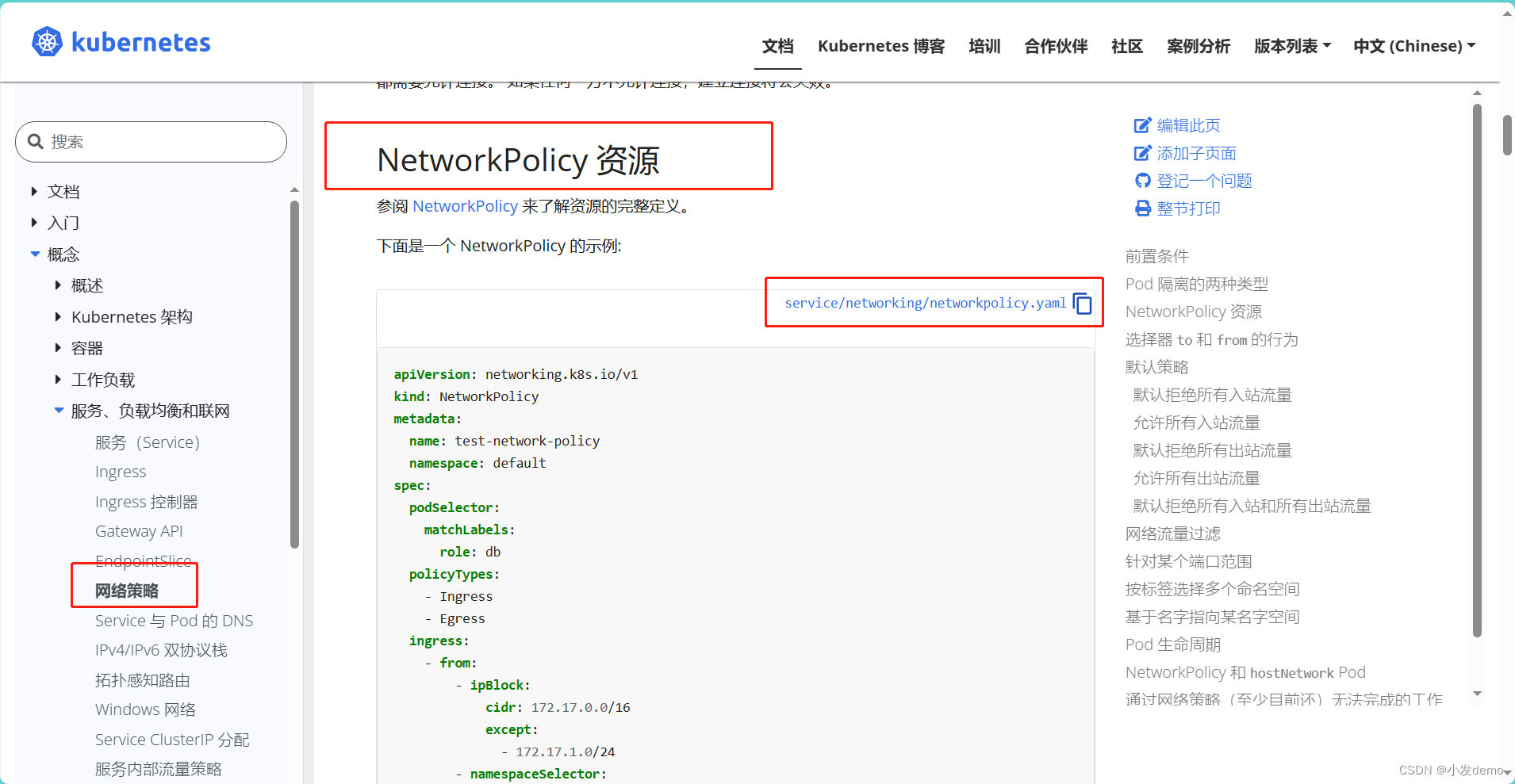
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: default
spec:
podSelector:
#通过podSelector来选择控制对象
matchLabels:
app: nginx
#标签
policyTypes:
- Ingress
#这里做入栈控制为主
ingress:
- from:
#- ipBlock:
# cidr: 172.17.0.0/16
# except:
# - 172.17.1.0/24
#- namespaceSelector:
# matchLabels:
# project: test
- podSelector:
matchLabels:
role: frontend
ports:
- protocol: TCP
port: 80当我们只使用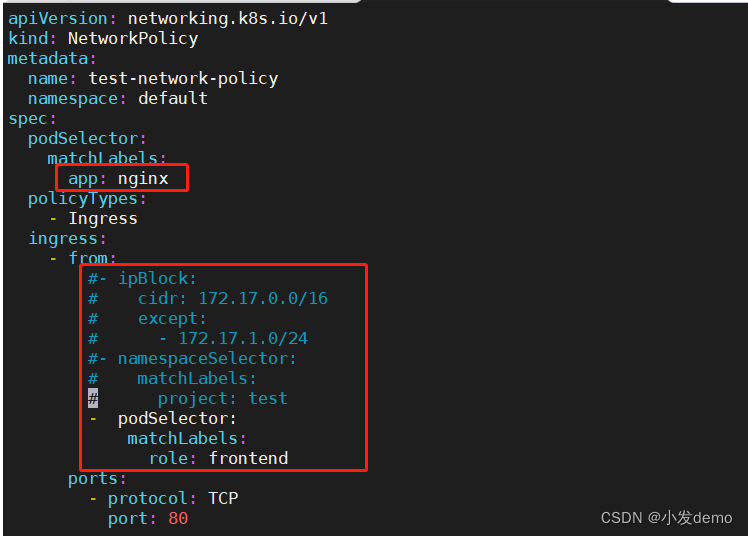
解释:此时的networkpolicy控制的pod是标签带有nginx的,对于该pod需要访问的pod具有
role=frontend标签才可以
此时:
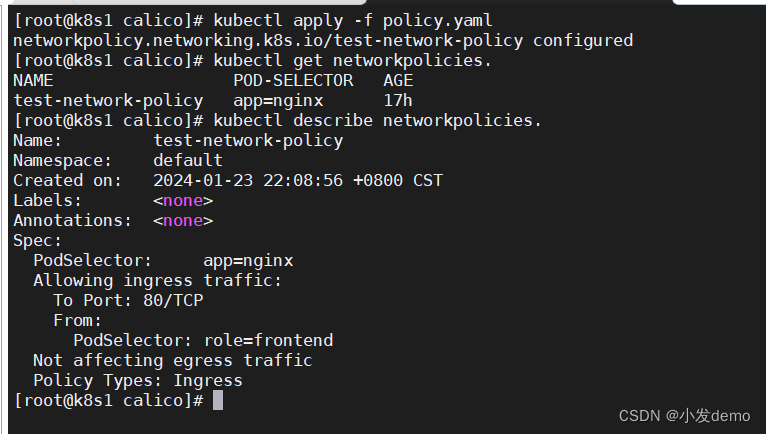
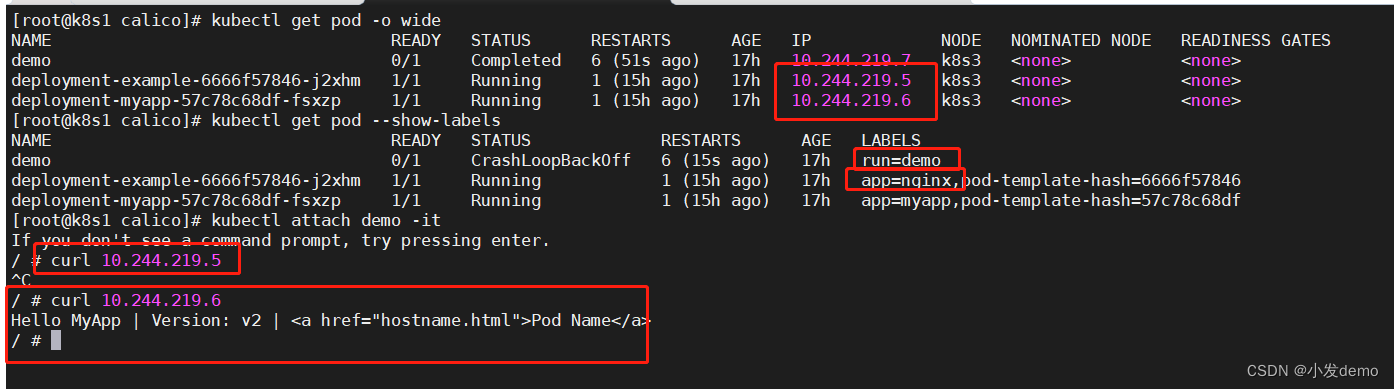
此时demo是没有role=frontend这个标签的,所以在访问example这个pod时,无法访问,但是在访问myapp这个pod时,networkpolicy并没有控制这个pod的规则 ,所以可以正常访问
当我们给demo加上标签时:
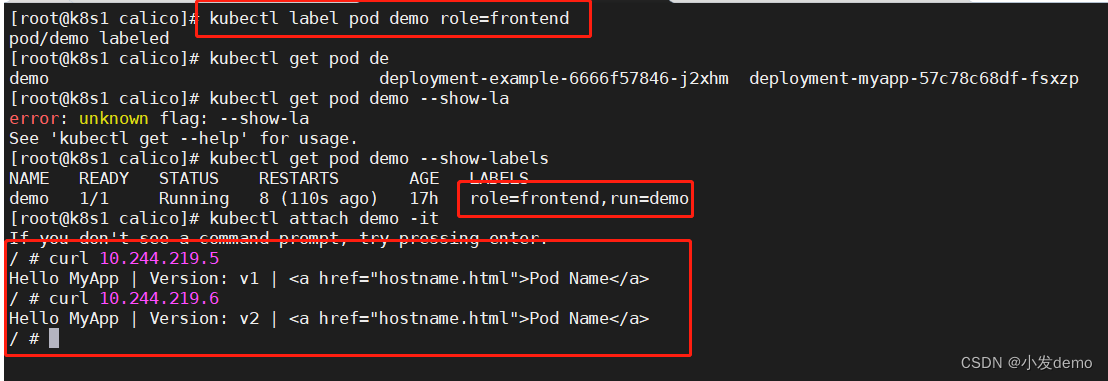
但是此时作为其他namespace的pod是无法访问的:

如果需要其他pod也可以访问到控制的pod,我们需要调整:
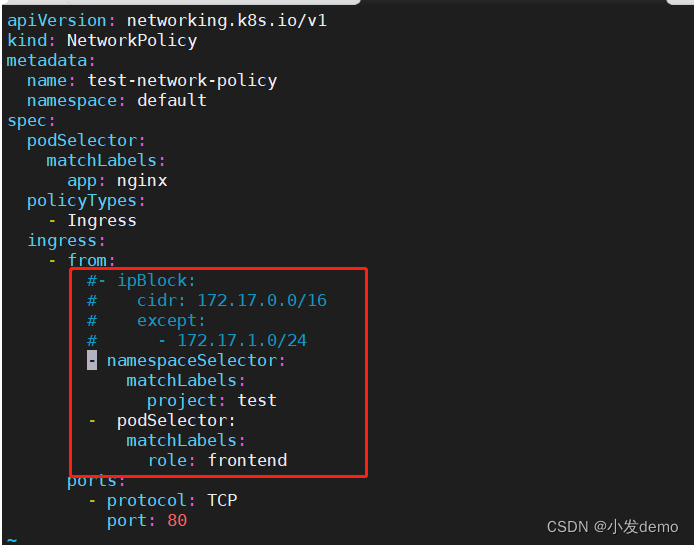
这里是两个列表的规则,满足其一即可访问pod。
重新运行,然后在新建的test namespace中运行busybosplus:
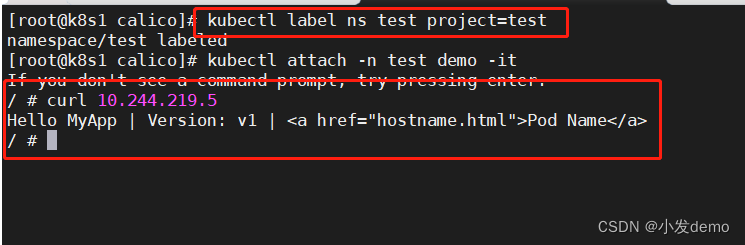
此时我们在test这个namespace中,由于test带有project=test这个标签,所以test内的所有pod都可以访问networkpolicy控制的pod
此时我们再次修改:
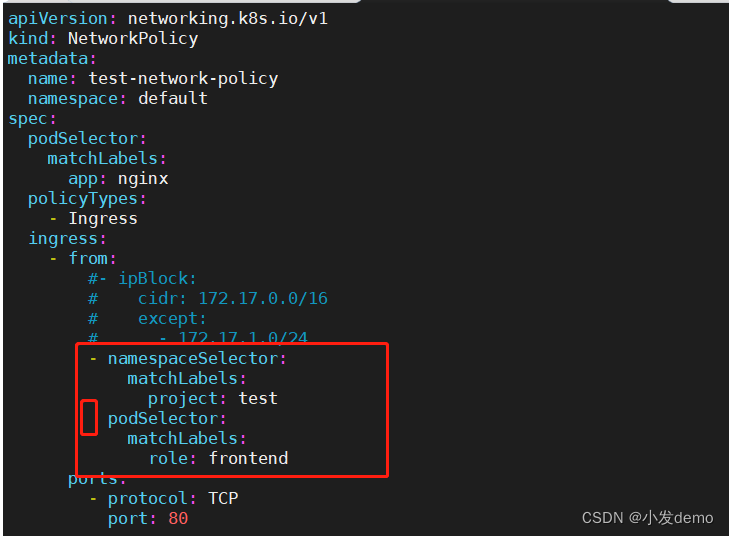
这里空色部分表示且,意为属于一个列表中的两条规则,需要同时满足
此时运行policy之后:
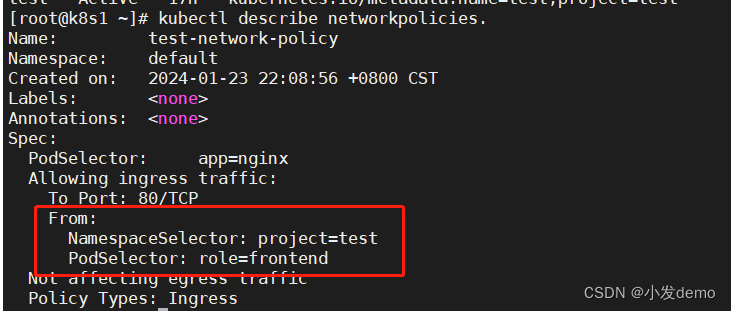
意为不仅要是namespace带有project=test,还要pod带有role=frontend才可以访问networkpolicy控制的pod,之前我对demo加上role=frontend了标签。所以这里可以成功访问
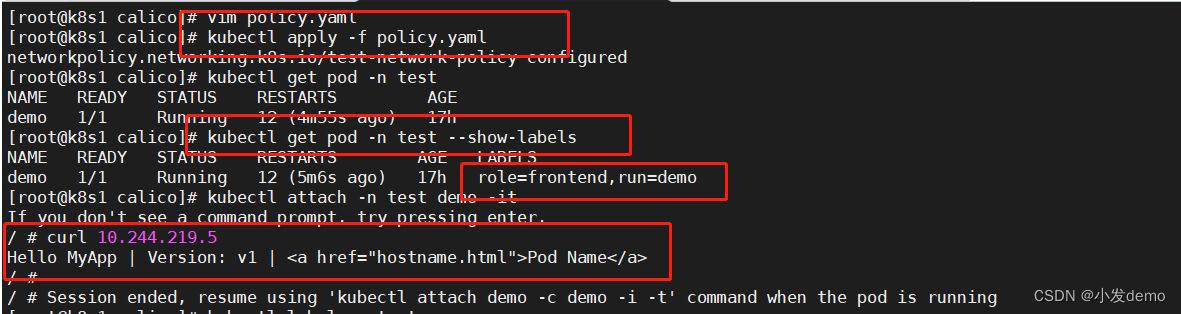
当我们去掉demo的标签之后(去掉标签可以通过命令执行,也可以通过edit来修改而热生效):

















 1370
1370











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









