







数据库相关整理
1.冯诺依曼体系

1.输入设备:键盘、鼠标、麦克风等等…
2.输出设备: 显示器,音箱等等…
3.外存储器: 机械硬盘,固态硬盘:
4.内存储器:内存条;
5.cpu: 计算机的核心。
2.数据库的简单指令 (建议全敲)
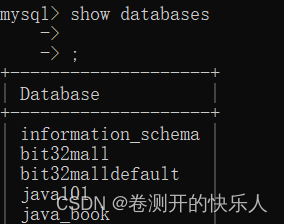
显示数据集合命令: show databases;
创建数据库:create database

使用数据库: use + 数据库名;
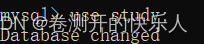
删除数据库: drop database + 数据库名;

查看表结构 :desc + 表名;
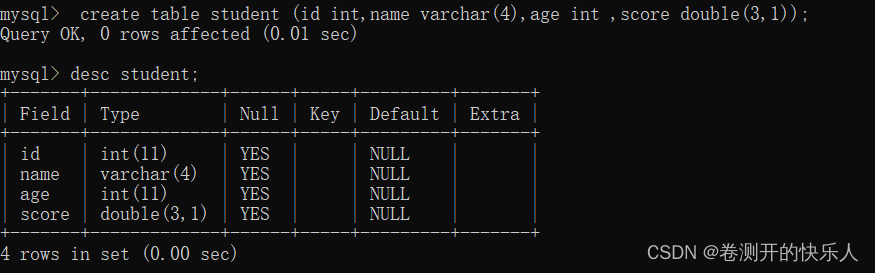
创建表: comment增加字段说明
create table if not exists student (
id int comment ‘编号’,
name varchar(4) comment ‘名字’,
age int comment ‘年龄’,
score double(3,1) comment ‘分数’
);

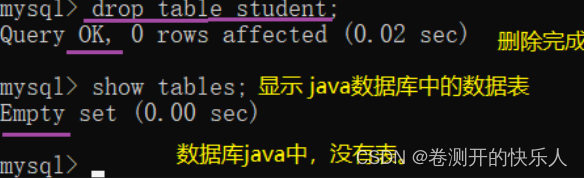
删除表: drop table + 表名:

3.数据库的增删改查
增加:
增加一条语句: insert into student values (1,’sjy‘,18,10.0);

增加多条语句: insert into student (id,name,age,score)values (2,‘sb’,19,19.9),(3,‘kl’,20,78.4);

删除
删除表 命令 : drop table 表名;
跟删除库的操作是一样的,删除表也是一种危险操作。 - 谨慎对待 - 严重程度是一样的,删除了,多半是恢复不了的。
查询
全列查询 select * from + 表名;(这个操作往往禁用)

查询单个列表 select + 列表 from +表名;
查询去重 select distinct + 列表 + 表名;
查询排序 select order by 这里有两种排序方式一个是升序 asc(默认) desc 降序
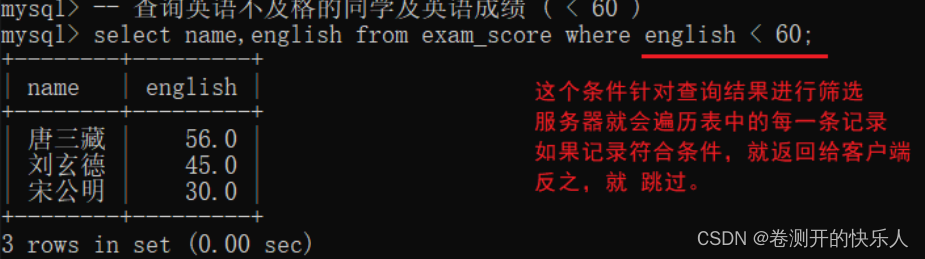
select 中的 条件查询:关键字 where
在 select 查询语句的后面加上一个 where 语句,后面跟上一个具体的筛选条件。
命令格式:select 列名,列名… from 表名 where 筛选条件;
作用:把查询结果中满足筛选条件的记录保留,把不满足筛选条件的记录给过滤掉。
and与or

分页查询
select 列名 from 表名 limit N offset M;
修改
update 表名 set 列名 = 值,列名 = 值… where 条件;
此处的修改是针对“满足where条件”的记录进行的。
【update的修改是会作用硬盘上的原始数据(原始数据改变了),条件千万一定要仔细写!!!!(避免误改)】
如果 没有 where 条件的限制,update 操作会将 指定的列,每一行的数据都修改。
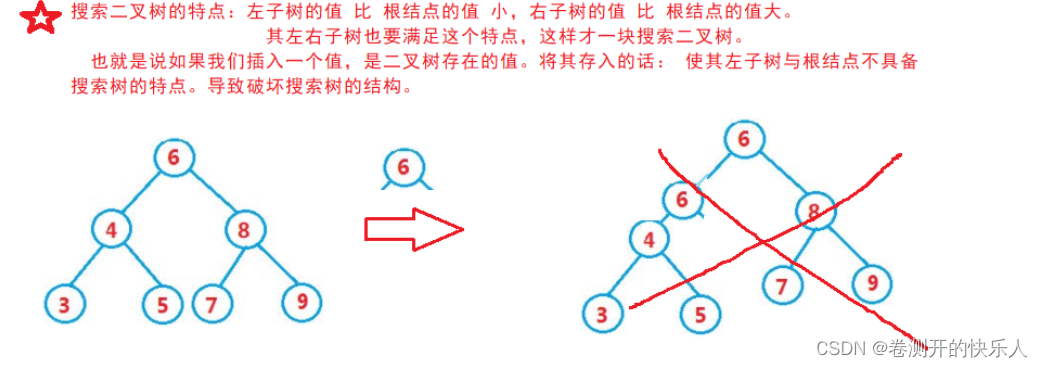
数据库的约束类型
约束就是我们的数据库在使用的时候,对于里面能够存储的数据所提出的要求和限制。
程序员就可以借助约束来完成更好的校验
1.not null - 指示某列不能存储 NULL 值
如果使用 not null 指示某列不能存储 NULL 值时,尝试往这里插入空值,就会直接报错。
简单来说,not null 用于创建数据表时,指定 列的插入值的情况不能为空值,必须是具体的数据
2.unique - 保证某列的每行必须有唯一的值。
3.default - 规定没有给列赋值时的默认值
4.primary key - 主键约束 - 日常开发中最常使用的约束!也是最重要的约束
primary key 主键约束 相当于 not null 和 unique 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
主键约束,相当于数据的唯一身份标识,类似身份证号码。
创建表的时候,很多时候都需要指定的主键。
5.foreign key - 保证一个表中的数据匹配另一个表中的值的参照完整性。
外键的概念:

外键约束语法:create table 子表名(列名 类型,列名 类型,… 列名 类型, foreign key (子表中置为外键的 列名) references 父表名(依赖的父表中列名));
数据库的进阶操作
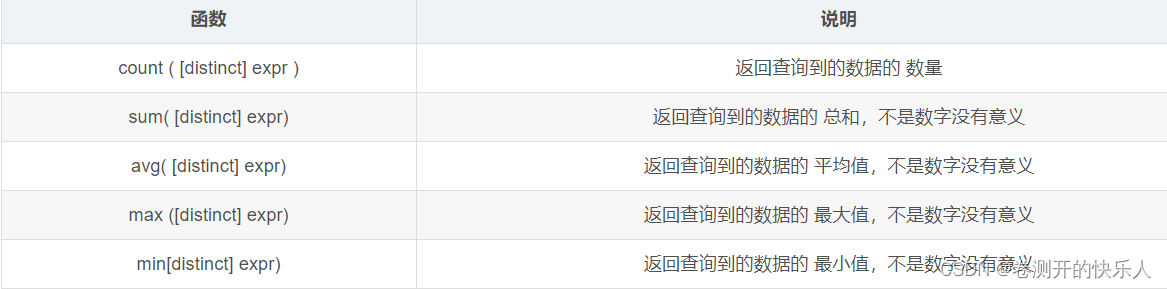
聚合查询:就是把 多行的数据给进行了关联操作。
常见的聚合函数如下图:
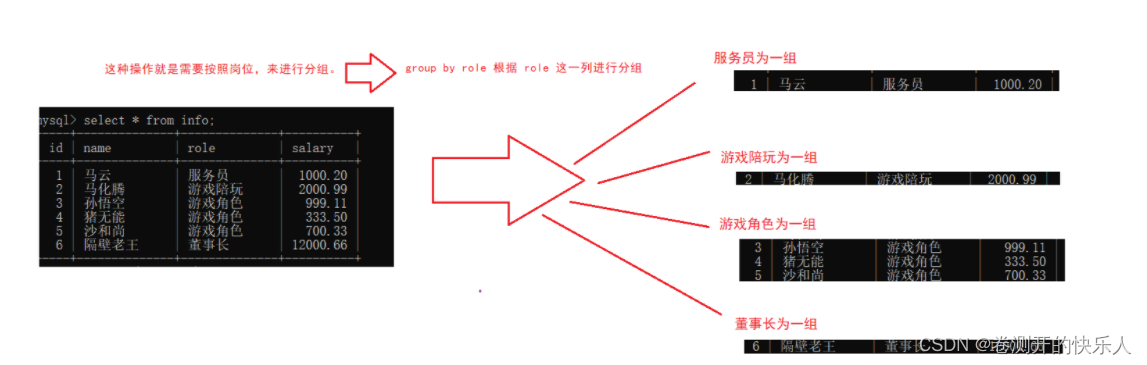
group by
having 操作 是和 group by 配套使用的。
select 中使用 group by 子句可以对指定列进行分组查询。需要满足:使用 group by 进行分组查
询时,select 指定的字段必须是“分组依据字段”(相同的字段为一组),其他字段若想出现在select 中则必须包含在聚合函数中。
group by 子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用 where 语句,而需要用having。
注意!上面红色句子的 “group by 子句进行分组以后” 的 “以后”两个字!!!
意思是如果数据先进行了分组之后,是不能使用where来制定条件的,只能是有having 来 制定条件。
反过来理解:在对数据进行分组之前,是可以使用 where 来制定条件的。
where 和 having的区别:
where 是在数据分组之前进行制定条件,来筛选数据。
having 是根据 分组之后的数据,进行指定条件,筛选每个分组中数据。
联合查询 - 多表查询 - 重点
先根据类似求笛卡尔积的操作把需要联合的表连到一起。(这一步在实际开发中十分浪费资源)
连接方式这是join独有的方式
就是将两个表的公共部分连接到一起。
左外的话就是连空值也包含进来。
外连接
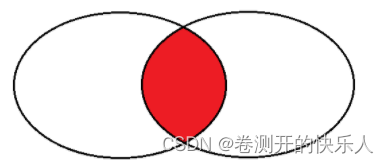
左外连接
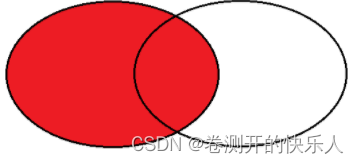
重点部分
索引
面试题
1、索引是用来干什么的?
给信息分配一个id,方便能够快速找寻到该数据
2、索引的使用的场景
数据库 的 查询功能,对于海量信息的查询,有这巨大作用。
3、索引的好处与坏处
好处:大幅度提升查找的效率,
坏处:占用额外的存储空间,使得“增删改”操作的执行的速度下降。
4、索引背后的数据结构
B+树,然后给他讲讲B+树是怎么实现 以及它的特点。
索引的优缺点
另外,思考一个问题:树的目录一旦决定了,后续每次对书的内容进行调整时,都可能会印象到目录的准确性,就需要重新调整目录。
数据库的索引也是一样的情况:当我们 对 数据进行“增删改”操作的时候,往往也需要同步调整索引的结构。
索引带来的好处:提高了查询效率
索引带来的坏处:占用了更多的空间,拖慢了增删查改的速度。
索引 背后的数据结构 - 面试考点
【B+ 树 是 数据库中最常见的数据结构】
想要 理解 B+ 树,需要先理解它的前身 B 树( B-树:这个是B树的另一种写法,而不是B减树)
B树是一种n叉树,并且他的每个结点可以存储多个值,将多个值进行排序然后划分区间,以此类推。
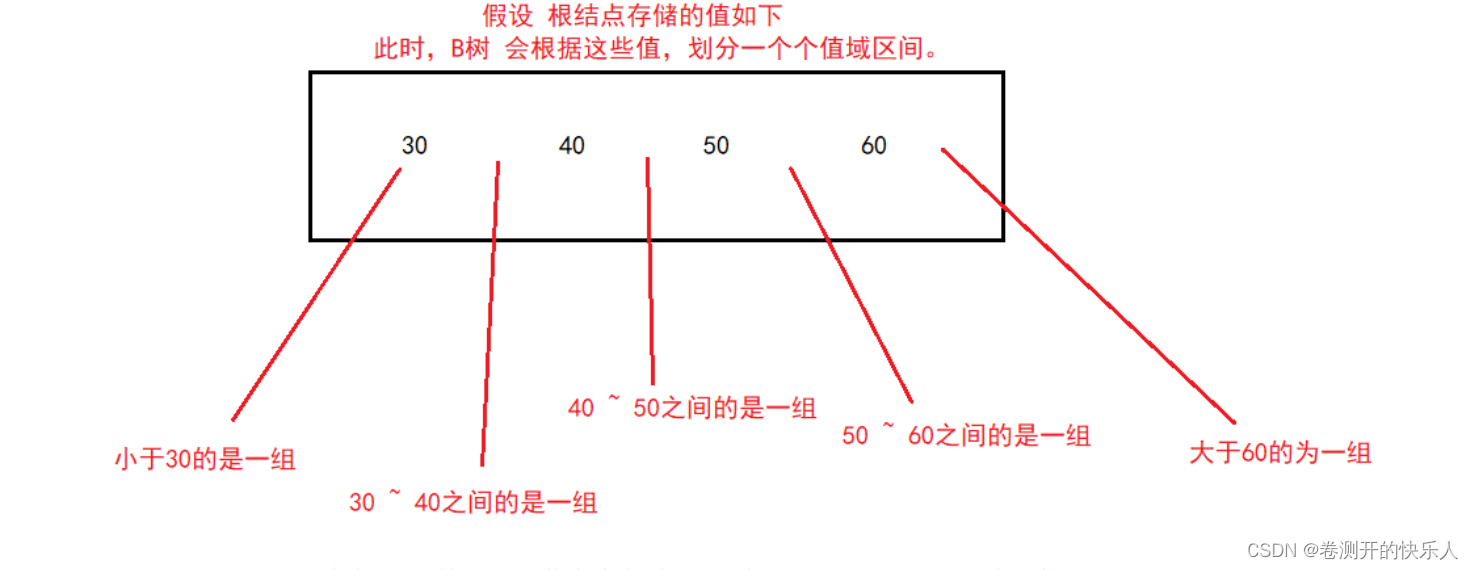
在确定区间的时候B树会进行多次比较,为什么不用二叉搜索树呢,是因为二叉搜索树,比较一次就会进行一次io操作,io操作耗费的时间和资源,远远比比较的资源消耗的多。因此还是通过多次比较来进行一次io的B树更加符合。
有了B树的基础,我们就可以来了解B+ 树 了。也就是 索引背后的数据结构。
B+树也是一颗n叉树,每个结点也有很多数值(不同的是这是一个左开右闭的区间),
B+树的特点
特点1:每个值都是一个左开右闭的区间
特点2:区间个数和结点个数相同
特点3:叶子结点用链表连接
特点4:某个结点的父结点,包含子结点的最大值。
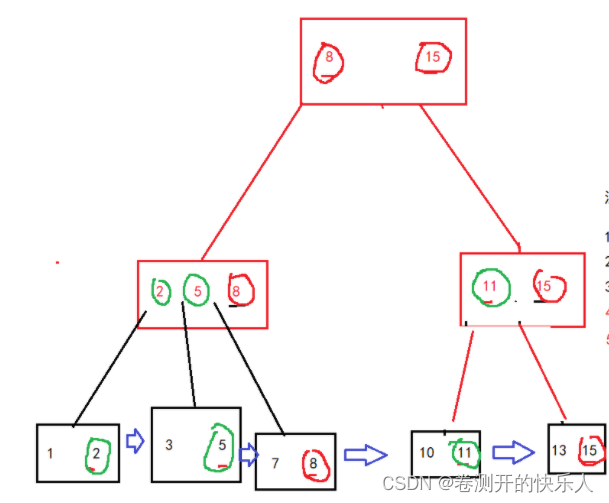
因此:
1、使用B+树进行查找的时候,整体IO次数比较少。
2、所有的查询最终多会落在叶子结点上,每次查询的 IO 次数都是差不多的,故查询的速度是稳定的,相差不大。
3、叶子结点用链表链接之后,非常适合进行范围查找
4、所有的数据存储(数据又称载荷)都是放到叶子结点上的。也就是说非叶子结点中只需要保存key值就可以了。因此非叶子节点整体占用空间较小,甚至可以加载到内存中。(一旦能够全部放在内存里,此时硬盘上的IO次数几乎就为零了)
另外,B树虽然不是很适合数据库,但是它的通用强,不像B+树一样,就是为了数据库而生的。换个场景,可能B+树就不行了。.主要还是根据实际情况来选择合适的数据结构。这也向我们印证了,为什么要学习数据结构!
事务(当面试官问道事务全回答了)
事务诞生的目的就是为了把若干个独立的操作给打包成一个整体。
在SQL中,有的复杂的任务需要多个SQL 执行。
有的时候,也需要同样打包在一起,前一个SQL 就是为了给后一个SQL 提供支持。
如果后面的SQL不执行了,或者出错了。那么前面的SQL也就失去了意义。
这样的情况,我们就能借助 事务 来进行。
总之,事务就是把很多东西打包在一起,要做就全做完,不做就一个也别做。
事务的四大特性
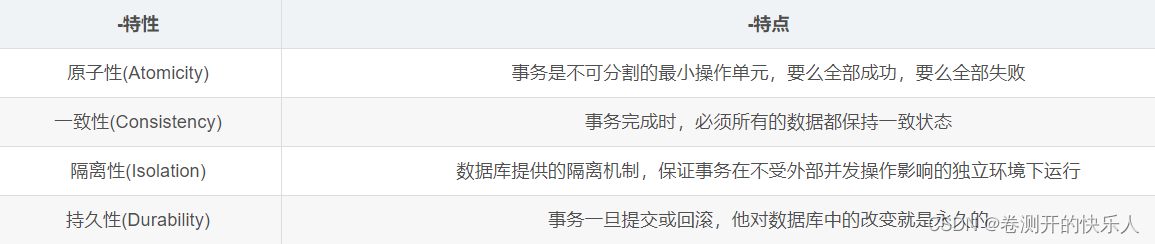
acid怎么保证的
原子性(A):由undo log日志保证的,它记录了需要回滚的日志信息,事务回滚时撤销已经执行成功的sql语句
一致性 (C):由其他三大特性进行保证,程序代码要保证业务上的一致性
隔离性(I):由MVCC来保证
持久性(D):由内存+redo log来保证,mysql修改数据同时在内存和redo log记录这次操作,宕机(死机)的时候可以从redo log中恢复
事务的使用
开启事务:start transaction;
简单来说
1、当我们将要执行多句SQL时,先输入 start transaction;
2、之后,便是执行多行 sql 语句。
3、最后 执行完之后,我们要以 rollback / commit 作为返回,
rollback 代表执行失败,进行“回滚”,而 commit 就是执行成功提交的意思。
start transaction;
// transaction 与 commit 之间,就是事务中的若干操作
-- 阿里巴巴账户减少2000
update accout set money=money-2000 where name = '阿里巴巴';
-- 四十大盗账户增加2000
update accout set money=money+2000 where name = '四十大盗';
commit;
由事务的第四个特性引出一个关键字:并发
因为cpu上有非常多的核心,所以执行的时候,为了提高效率,用这些来加快任务的完成。
那么,问题就来了:在数据库中,并发执行多个事务的时候,修改 / 读取的 收据,是同一个数据的时候,就会出现一些问题。
而事务的隔离性就是解决上述问题。
所以我们这里事务的隔离性,主要就是针对并发执行事务的场景。
因此要想理解并发执行事故,我们就必须要理解什么是并发,并发:就是同时执行多个任务。
那么我们这里的并发执行事故:一个数据库服务器同时执行多个事务。
并发执行事故所带来的问题
1.脏读
脏读,读的是还未提交事务的数据
放在数据库中:事务A在对某个数据进行修改的同时,事务B 去 读取了 这个 数据。
此时,事务B 读到的很可能是一个“脏数据”(这个数据是一个临时的结果,而不是最终的结果)
解决方法
就是给 写操作 加上锁。
意思就是 在 写的过程中,别人看不到的。(加锁的状态)
写完之后,别人看到了。(解除枷锁)
2.不可重复读
指的是事务读了几次,读到的结果都是不一样的。
解决方法
给 读操作也上锁。
现在的 情况就是 我们写博客的时候,读者不能阅读;读者阅读的时候,我们不能改博客。
意味着我们必须得等到读者读完了,才能进行修改。
因此通过给读操作也加上锁,就可以解决不可重复读的问题。
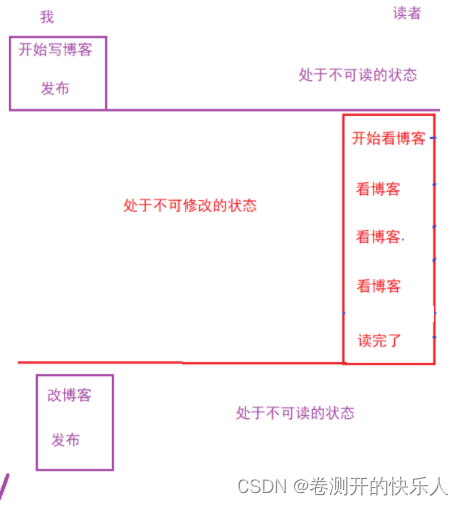
3.幻读
读的内容没有改变,但是读的个数发生改变,这个问题叫做幻读。
解决方法
想要解决幻读问题的办法至于一个,彻底 串行化 执行。
简单来说,就是一个个来,出完一个事务,再处理一下事务,以此类推。
这种执行方式,隔离性最高,并发性最低,数据最可靠,速度最慢。
MySQL中事务的隔离级别
1、read uncommitted :允许读取未提交的数据,并发程度最高,隔离最低,会带有脏读 + 不可重复读 + 幻读问题
2、read committed:只允许读取 提交之后的数据,相当于写加锁。并发性降低,隔离性提高。解决脏读,但带有 不可重复读 + 幻读问题
3、repeatable read:相当于给读和写操作都上锁了,并发性进一步降低,隔离性进一步提高。解决脏读、不可重复读,但带有 幻读问题。
4、serializable:串行化,并发性降到最低(串行执行),隔离程度最高,解决了脏读、不可重复读、幻读问题。但是运行的速度是最低的。
MySQL 可以通过修改 配置文件(my.ini) 来进行设置当前的隔离级别。
这样就可以根据实际情况,来决定使用哪种隔离级别。
如何查询当前服务器数据库的隔离级别 与 设置当前的隔离级别的指令
//设置read uncommitted级别:
set session transaction isolation level read uncommitted;
中文意思:设置 会话事务 的隔离级别为 read uncommitted
//设置read committed级别:
set session transaction isolation level read committed;
中文意思:设置 会话事务 的隔离级别为 read committed
//设置repeatable read级别:
set session transaction isolation level repeatable read;
中文意思:设置 会话事务 的隔离级别为 repeatable read
//设置serializable级别:
set session transaction isolation level serializable;
中文意思:设置 会话事务 的隔离级别为 serializable
JDBC编程
JDBC是什么
JDBC是Java中的一组API,这组API里面包括了,一些类和方法来实现数据库的基本操作。
JAVA组织的各个厂商的驱动,和JDBC对接,程序员只需要掌握JDBC就可以操作各种数据库。
就和显卡有很多,但是都可以安装到电脑上,那是因为我们的驱动,打个驱动就好,jdbc同时也要到pom.xml打上数据库的驱动。
JDBC的基本流程
1、创建 DataSource 对象,需要填写数据库地址,账号,密码。这个对象描述了数据库服务器在哪,用的是哪个数据库。
2.让代码和数据库服务器建立连接
3.进行操作数据库:以插入数据为例
4、执行SQL
5、此时 SQL 已经执行完毕,然后需要我们去释放资源
import com.mysql.jdbc.jdbc2.optional.MysqlDataSource;
import javax.sql.DataSource; // JDBC 所在的包,用于提供 JDBC 的 类和方法。
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class TestJDBC {
public static void main(String[] args) throws SQLException {
// 1、创建好数据源
// DataSource 就是 JDBC 当中一个重要的 “类”(实际上它是接口)
DataSource dataSource = new MysqlDataSource();
// 设置数据库所在的地址
((MysqlDataSource)dataSource).setURL("jdbc:mysql://127.0.0.1:3306/java?characterEncoding=utf8&useSSL=false");
// 设置 登录数据库的用户名
((MysqlDataSource)dataSource).setUser("root");
// 设置登录数据库的密码
((MysqlDataSource)dataSource).setPassword("123456");
//2、让代码与数据库服务器建立连接
Connection connection = dataSource.getConnection();
//进行操作数据库:以插入数据为例
//关键所在就是构造一个 SQL 语句。
String sql = "insert into student values(1,'张三')";
//但是呢,光有一个String类型的SQL还不行。需要把这个String 包装成一个“语句对象”。
PreparedStatement preparedStatement= connection.prepareStatement(sql);
//4、执行SQL:真正访问数据库服务器,插入数据
// SQL 里面的 insert、update、delete,都是是哦用 executeUpdate 方法
// 【可以这么理解:这三操作其实都是在更新数据。而 executeUpdate 的中文意思就是执行更新】
// select 很特殊,使用的是 executeQuery 方法。
// 【而 select 不涉及数据更新操作,它只是查询数据的内容。executeQuery的中文意思就是 执行询问/执行查询】
int ret = preparedStatement.executeUpdate();
// preparedStatement.executeUpdate() 就是拿着我们构造好的 语句对象去进行相应的操作。
// 并且它会返回一个整数,意思就是 这个操作 影响到了几行
System.out.println(ret);
//5、此时 SQL 已经执行完毕,然后需要我们去释放资源
preparedStatement.close();
connection.close();
}
}
















 672
672











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











