







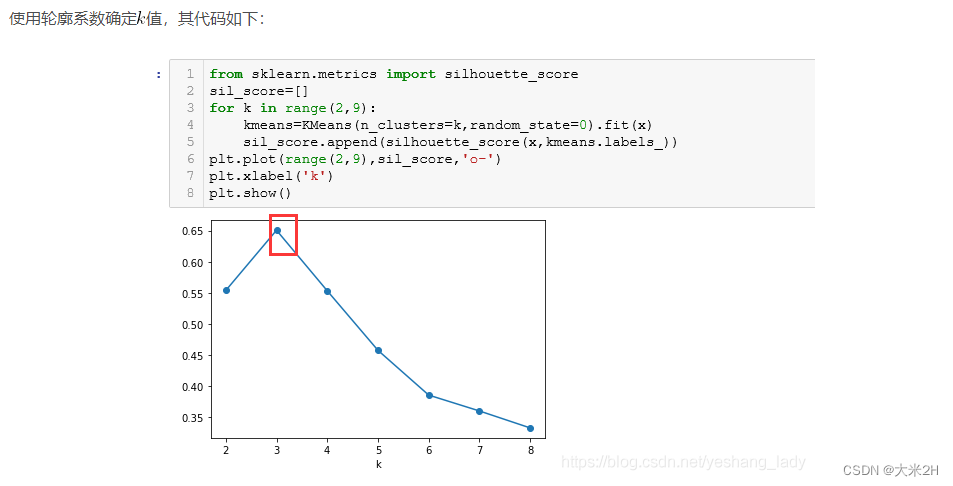
尽管我们可以通过SSE来表示当前K-Means聚类模型效果好坏(甚至作为损失函数),但SSE却不能作为模型超参数(K)的选取依据。其实我们不难发现,伴随K增加,模型整体SSE将会逐渐下降。不过,尽管如此,其实K-Means快速聚类中,还是有部分指标可以一定程度上给出聚成几类的指导意见,其中最有名的就是轮廓系数(silhouette coefficient,简称sc)。注意,对于K-Means来说,这些指标只能参考,最终聚成几类,还应该主要参考模型的业务背景。

尽管轮廓系数可以在[-1, 1]区间内取值,但我们并不希望轮廓系数出现负值,此时代表组内的平均距离要大于组外平均距离的最小值,此时说明聚类算法无效。我们希望
b
i
>
a
i
b_i>a_i
bi>ai,并且希望
a
i
a_i
ai尽可能的小,此时
s
i
s_i
si也就趋近于1,而当轮廓系数趋于0时,则说明各簇重叠现象明显。并且,非常重要的一点是,轮廓系数取值的大小一定程度上能够给K的取值提供建议,当轮廓系数比较大时,往往说明数据在特征空间中本身的分布情况就和聚类的类别数量相同。
更详细代码请参考链接
from sklearn.metrics import silhouette_score
ss = []
for i in range(2, 12):
km = KMeans(n_clusters=i).fit(X)
ss.append(silhouette_score(X, km.labels_))
ss = []
ss
[0.5917969390803755,
0.6753180189915984,
0.580872808406484,
0.47687683047050644,
0.3685113521594094,
0.3653820829962011,
0.3639995054273048,
0.3524637605205039,
0.3579462241667135,
0.3682450219445942]
能够发现,当K取值为3时轮廓系数取值最高,也就是说明从特征空间的数据分布来看,整体呈现聚成三类的趋势。当然,这个我们创建数据集时赋予的规律一致。
不过,仍然需要强调的是,除非特征矩阵在特征空间的“分界”非常明显,才能在轮廓系数上有明显差异。而聚类算法在分类上的性能,其实也远远弱于有监督学习算法。















 5210
5210











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









