







Lesson 4.6 逻辑回归的手动实现
讨论完梯度下降的相关内容之后,接下来我们尝试使用梯度下降算法求解逻辑回归损失函数,并且通过一系列实验来观察逻辑回归的模型性能。
# 科学计算模块
import numpy as np
import pandas as pd
# 绘图模块
import matplotlib as mpl
import matplotlib.pyplot as plt
# 自定义模块
from ML_basic_function import *
一、逻辑回归损失函数的梯度计算表达式
对于任何模型的手动实现,首先我们都需要考虑关于其损失函数的梯度计算表达式。并且为了方便代码实现,我们需要尽可能的使用矩阵形式进行表示。在线性回归中,我们通过矩阵求导运算,可以非常快速的求解出用矩阵形式表示的损失函数梯度表达式,而在逻辑回归中,由于损失函数表达式的不同,这个过程会略微复杂一些。
在Lesson 4.2中,我们从极大似然估计和KL离散两个角度推导了逻辑回归损失函数,对于二分类为逻辑回归模型来说,假设数据集是m行n列的一个数据集,则二分类交叉熵损失函数如下:
b i n a r y C E ( w ^ ) = − 1 m ∑ i = 1 m [ y ( i ) ⋅ l o g ( p 1 ( x ^ ( i ) ; w ^ ) ) + ( 1 − y ( i ) ) ⋅ l o g ( 1 − p 1 ( x ^ ( i ) ; w ^ ) ) ] binaryCE(\hat w)= -\frac{1}{m}\sum^m_{i=1}[y^{(i)} \cdot log(p_1(\hat x^{(i)};\hat w))+(1-y^{(i)}) \cdot log(1-p_1(\hat x^{(i)};\hat w))] binaryCE(w^)=−m1i=1∑m[y(i)⋅log(p1(x^(i);w^))+(1−y(i))⋅log(1−p1(x^(i);w^))]
其中n为样本数量, x ^ ( i ) \hat x^{(i)} x^(i)为第i条样本(添加了最后全是1的列), w ^ \hat w w^为带截距项的线性方程系数向量, p 1 p_1 p1为某条样本在当前参数下逻辑回归输出结果,即预测该样本为1的概率, y ( i ) y^{(i)} y(i)为第 i i i条样本的真实类别。对于上述BCE损失函数,梯度表达式为:
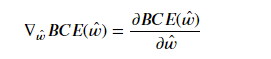
其中 w ^ = [ w 1 , w 2 , w 3 , . . . , w n , b ] \hat w=[w_1, w_2, w_3, ..., w_n, b] w^=[w1,w2,w3,...,wn,b],因此上式可进一步展开:
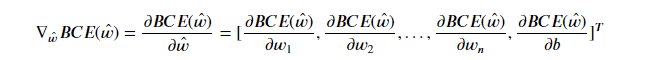
而 l o g ( p 1 ( x ^ ( i ) ; w ^ ) ) = l o g ( S i g m o i d ( x ^ ( i ) ⋅ w ^ ) ) log(p_1(\hat x^{(i)}; \hat w)) = log(Sigmoid(\hat x^{(i)} \cdot \hat w)) log(p1(x^(i);w^))=log(Sigmoid(x^(i)⋅w^)),我们对带入某条数据后的某个参数进行求导,例如对 w i w_i wi进行求导,则可得:
l o g ( p 1 ( x ^ ( i ) ; w ^ ) ) ′ = l o g ( S i g m o i d ( x ^ ( i ) ⋅ w ^ ) ) ′ = 1 S i g m o i d ( x ^ ( i ) ⋅ w ^ ) ⋅ S i g m o i d ′ ( x ^ ( i ) ⋅ w ^ ) log(p_1(\hat x^{(i)}; \hat w))' = log(Sigmoid(\hat x^{(i)} \cdot \hat w))'=\frac{1}{Sigmoid(\hat x^{(i)} \cdot \hat w)} \cdot Sigmoid'(\hat x^{(i)} \cdot \hat w) log(p1(x^(i);w^))′=log(Sigmoid(x^(i)⋅w^))′=Sigmoid(x^(i)⋅w^)1⋅Sigmoid′(x^(i)⋅w^)
对于Sigmoid函数来说,有 S i g m o i d ′ ( x ) = S i g m o i d ( x ) ( 1 − S i g m o i d ( x ) ) Sigmoid'(x) = Sigmoid(x)(1-Sigmoid(x)) Sigmoid′(x)=Sigmoid(x)(1−Sigmoid(x)),因此上式可进一步得到:
l o g ( p 1 ( x ^ ( i ) ; w ^ ) ) ′ = ( 1 − S i g m o i d ( x ^ ( i ) ⋅ w ^ ) ) ⋅ ( x ^ ( i ) ⋅ w ^ ) ′ log(p_1(\hat x^{(i)}; \hat w))' = (1-Sigmoid(\hat x^{(i)} \cdot \hat w)) \cdot (\hat x^{(i)} \cdot \hat w)' log(p1(x^(i);w^))′=(1−Sigmoid(x^(i)⋅w^))⋅(x^(i)⋅w^)′
其中 x ^ ( i ) ⋅ w ^ = w 1 x 1 ( i ) + w 2 x 2 ( i ) + . . . + w n x n ( i ) + b \hat x^{(i)} \cdot \hat w=w_1x_1^{(i)}+w_2x_2^{(i)}+...+w_nx_n^{(i)}+b x^(i)⋅w^=w1x1(i)+w2x2(i)+...+wnxn(i)+b,对 w i w_i wi求导可得:
( x ^ ( i ) ⋅ w ^ ) ′ = x i ( i ) (\hat x^{(i)} \cdot \hat w)' = x_i^{(i)} (x^(i)⋅w^)′=xi(i)
当然,对截距求导可得:
( x ^ ( i ) ⋅ w ^ ) ′ = 1 (\hat x^{(i)} \cdot \hat w)' = 1 (x^(i)⋅w^)′=1
因此,在 l o g ( p 1 ( x ^ ( i ) ; w ^ ) ) log(p_1(\hat x^{(i)}; \hat w)) log(p1(x^(i);w^))中对 w i w_i wi求导可得:
l o g ( p 1 ( x ^ ( i ) ; w ^ ) ) ′ = ( 1 − S i g m o i d ( x ^ ( i ) ⋅ w ^ ) ) ⋅ x i ( i ) log(p_1(\hat x^{(i)}; \hat w))' = (1-Sigmoid(\hat x^{(i)} \cdot \hat w)) \cdot x_i^{(i)} log(p1(x^(i);w^))′=(1−Sigmoid(x^(i)⋅w^))⋅xi(i)
而在 l o g ( p 1 ( x ^ i ; w ^ ) ) log(p_1(\hat x_i; \hat w)) log(p1(x^i;w^))中对 b b b求导可得:
l o g ( p 1 ( x ^ ( i ) ; w ^ ) ) ′ = ( 1 − S i g m o i d ( x ^ ( i ) ⋅ w ^ ) ) ⋅ 1 log(p_1(\hat x^{(i)}; \hat w))' = (1-Sigmoid(\hat x^{(i)} \cdot \hat w)) \cdot 1 log(p1(x^(i);w^))′=(1−Sigmoid(x^(i)⋅w^))⋅1
类似的,在 ( 1 − y ( i ) ) ⋅ l o g ( 1 − p 1 ( x ^ ( i ) ; w ^ ) ) (1-y^{(i)}) \cdot log(1-p_1(\hat x^{(i)};\hat w)) (1−y(i))⋅log(1−p1(x^(i);w^))中对 w i w_i wi求导可得:
( 1 − y ( i ) ) ⋅ l o g ′ ( 1 − p 1 ( x ^ ( i ) ; w ^ ) ) = ( 1 − y ( i ) ) ⋅ l o g ′ ( 1 − S i g m o i d ( x ^ ( i ) ⋅ w ^ ) ) = ( 1 − y ( i ) ) ⋅ 1 ( 1 − S i g m o i d ( x ^ ( i ) ⋅ w ^ ) ) ⋅ ( − S i g m o i d ′ ( x ^ ( i ) ⋅ w ^ ) ) \begin{aligned} (1-y^{(i)}) \cdot log'(1-p_1(\hat x^{(i)};\hat w)) & = (1-y^{(i)}) \cdot log'(1-Sigmoid(\hat x^{(i)} \cdot \hat w)) \\ &=(1-y^{(i)}) \cdot \frac{1}{(1-Sigmoid(\hat x^{(i)} \cdot \hat w))} \cdot (-Sigmoid'(\hat x^{(i)} \cdot \hat w)) \end{aligned} (1−y(i))⋅log′(1−p1(x^(i);w^))=(1−y(i))⋅log′(1−Sigmoid(x^(i)⋅w^))=(1−y(i))⋅(1−Sigmoid(x^(i)⋅w^))1⋅(−Sigmoid′(x^(i)⋅w^))
同样,由于 S i g m o i d ′ ( x ) = S i g m o i d ( x ) ( 1 − S i g m o i d ( x ) ) Sigmoid'(x) = Sigmoid(x)(1-Sigmoid(x)) Sigmoid′(x)=Sigmoid(x)(1−Sigmoid(x)),所以上式可得:
( 1 − y ( i ) ) ⋅ l o g ′ ( 1 − p 1 ( x ^ ( i ) ; w ^ ) ) = ( 1 − y ( i ) ) ⋅ ( − S i g m o i d ( x ^ ( i ) ⋅ w ^ ) ) ⋅ ( x ^ ( i ) ⋅ w ^ ) ′ = ( 1 − y ( i ) ) ⋅ ( − S i g m o i d ( x ^ ( i ) ⋅ w ^ ) ) ⋅ x i ( i ) \begin{aligned} (1-y^{(i)}) \cdot log'(1-p_1(\hat x^{(i)};\hat w)) & = (1-y^{(i)}) \cdot (-Sigmoid(\hat x^{(i)} \cdot \hat w)) \cdot (\hat x^{(i)} \cdot \hat w)' \\ &=(1-y^{(i)}) \cdot (-Sigmoid(\hat x^{(i)} \cdot \hat w)) \cdot x_i^{(i)} \end{aligned} (1−y(i))⋅log′(1−p1(x^(i);w^))=(1−y(i))⋅(−Sigmoid(x^(i)⋅w^))⋅(x^(i)⋅w^)′=(1−y(i))⋅(−Sigmoid(x^(i)⋅w^))⋅xi(i)
类似的,当对截距项b求导时
( 1 − y ( i ) ) ⋅ l o g ′ ( 1 − p 1 ( x ^ ( i ) ; w ^ ) ) = ( 1 − y ( i ) ) ⋅ ( − S i g m o i d ( x ^ ( i ) ⋅ w ^ ) ) ⋅ 1 (1-y^{(i)}) \cdot log'(1-p_1(\hat x^{(i)};\hat w))= (1-y^{(i)}) \cdot (-Sigmoid(\hat x^{(i)} \cdot \hat w)) \cdot 1 (1−y(i))⋅log′(1−p1(x^(i);w^))=(1−y(i))⋅(−Sigmoid(x^(i)⋅w^))⋅1
将上述结果带入 ∂ B C E ( w ^ ) ∂ w i \frac{\partial BCE(\hat w)}{\partial w_i} ∂wi∂BCE(w^),当对 w i w_i wi进行求导时:
∂ B C E ( w ^ ) ∂ w i = ( − 1 m ∑ i = 1 m [ y ( i ) ⋅ l o g ( p 1 ( x ^ ( i ) ; w ^ ) ) + ( 1 − y ( i ) ) ⋅ l o g ( 1 − p 1 ( x ^ ( i ) ; w ^ ) ) ] ) ′ = − 1 m ∑ i = 1 m [ y ( i ) ⋅ l o g ′ ( p 1 ( x ^ ( i ) ; w ^ ) ) + ( 1 − y ( i ) ) ⋅ l o g ′ ( 1 − p 1 ( x ^ ( i ) ; w ^ ) ) ] = − 1 m ∑ i = 1 m [ y ( i ) ⋅ ( 1 − S i g m o i d ( x ^ ( i ) ⋅ w ^ ) ) ⋅ x i ( i ) + ( 1 − y ( i ) ) ⋅ ( − S i g m o i d ( x ^ ( i ) ⋅ w ^ ) ) ⋅ x i ( i ) ) ] = − 1 m ∑ i = 1 m [ x i ( i ) y ( i ) − x i ( i ) y ( i ) S i g m o i d ( x ^ ( i ) ⋅ w ^ ) − x i ( i ) S i g m o i d ( x ^ ( i ) ⋅ w ^ ) + x i ( i ) y ( i ) S i g m o i d ( x ^ ( i ) ⋅ w ^ ) ] = 1 m ∑ i = 1 m ( x i ( i ) ( S i g m o i d ( x ^ ( i ) ⋅ w ^ ) − y ( i ) ) ) = 1 m ∑ i = 1 m ( x i ( i ) ( y ^ ( i ) − y ( i ) ) ) \begin{aligned} \frac{\partial BCE(\hat w)}{\partial w_i} &= (-\frac{1}{m}\sum^m_{i=1}[y^{(i)} \cdot log(p_1(\hat x^{(i)};\hat w))+(1-y^{(i)}) \cdot log(1-p_1(\hat x^{(i)};\hat w))])' \\ &=-\frac{1}{m}\sum^m_{i=1}[y^{(i)} \cdot log'(p_1(\hat x^{(i)};\hat w))+(1-y^{(i)}) \cdot log'(1-p_1(\hat x^{(i)};\hat w))] \\ &=-\frac{1}{m}\sum^m_{i=1}[y^{(i)} \cdot (1-Sigmoid(\hat x^{(i)} \cdot \hat w)) \cdot x_i^{(i)} + (1-y^{(i)}) \cdot (-Sigmoid(\hat x^{(i)} \cdot \hat w)) \cdot x_i^{(i)})] \\ &=-\frac{1}{m}\sum^m_{i=1}[ x_i^{(i)}y^{(i)}-x_i^{(i)}y^{(i)}Sigmoid(\hat x^{(i)} \cdot \hat w) - x_i^{(i)}Sigmoid(\hat x^{(i)} \cdot \hat w)+x_i^{(i)}y^{(i)}Sigmoid(\hat x^{(i)} \cdot \hat w) ] \\ &=\frac{1}{m}\sum^m_{i=1}(x_i^{(i)}(Sigmoid(\hat x^{(i)} \cdot \hat w)-y^{(i)})) \\ &=\frac{1}{m}\sum^m_{i=1}(x_i^{(i)}(\hat y^{(i)}-y^{(i)})) \end{aligned} ∂wi∂BCE(w^)=(−m1i=1∑m[y(i)⋅log(p1(x^(i);w^))+(1−y(i))⋅log(1−p1(x^(i);w^))])′=−m1i=1∑m[y(i)⋅log′(p1(x^(i);w^))+(1−y(i))⋅log′(1−p1(x^(i);w^))]=−m1i=1∑m[y(i)⋅(1−Sigmoid(x^(i)⋅w^))⋅xi(i)+(1−y(i))⋅(−Sigmoid(x^(i)⋅w^))⋅xi(i))]=−m1i=1∑m[xi(i)y(i)−xi(i)y(i)Sigmoid(x^(i)⋅w^)−xi(i)Sigmoid(x^(i)⋅w^)+xi(i)y(i)Sigmoid(x^(i)⋅w^)]=m1i=1∑m(xi(i)(Sigmoid(x^(i)⋅w^)−y(i)))=m1i=1∑m(xi(i)(y^(i)−y(i)))
对截距项b进行求导时:
∂ B C E ( w ^ ) ∂ b = 1 m ∑ i = 1 m 1 ⋅ ( y ^ ( i ) − y ( i ) ) \frac{\partial BCE(\hat w)}{\partial b} = \frac{1}{m}\sum^m_{i=1}1 \cdot (\hat y^{(i)}-y^{(i)}) ∂b∂BCE(w^)=m1i=1∑m1⋅(y^(i)−y(i))
其实,根据定义, x ( i ) = [ x 1 ( i ) , x 2 ( i ) , . . . , x n ( i ) , 1 ] x^{(i)}=[x_1^{(i)}, x_2^{(i)}, ..., x_n^{(i)}, 1] x(i)=[x1(i),x2(i),...,xn(i),1], x n + 1 ( i ) = 1 x^{(i)}_{n+1}=1 xn+1(i)=1,1就是 x ( i ) x^{(i)} x(i)的第 n + 1 n+1 n+1个分量

我们令 X X X为添加最后一列全是1的特征矩阵, y y y是标签数组:

则上式前半部分可简化为:
[ ∑ i = 1 m x 1 ( i ) S i g m o i d ( x ^ ( i ) ⋅ w ^ ) ∑ i = 1 m x 2 ( i ) S i g m o i d ( x ^ ( i ) ⋅ w ^ ) . . . ∑ i = 1 m x n ( i ) S i g m o i d ( x ^ ( i ) ⋅ w ^ ) ∑ i = 1 m S i g m o i d ( x ^ ( i ) ⋅ w ^ ) ] = [ x 1 ( 1 ) , x 1 ( 2 ) , . . . , x 1 ( m ) x 2 ( 1 ) , x 2 ( 2 ) , . . . , x 2 ( m ) . . . x m ( 1 ) , x m ( 2 ) , . . . , x m ( m ) 1 , 1 , . . . , 1 , 1 ] ⋅ [ S i g m o i d ( x ^ ( 1 ) ⋅ w ^ ) S i g m o i d ( x ^ ( 2 ) ⋅ w ^ ) . . . S i g m o i d ( x ^ ( m ) ⋅ w ^ ) ] = [ x 1 ( 1 ) , x 2 ( 1 ) , . . . , x n ( 1 ) , 1 x 1 ( 2 ) , x 2 ( 2 ) , . . . , x n ( 2 ) , 1 . . . x 1 ( m ) , x 2 ( m ) , . . . , x n ( m ) , 1 ] T ⋅ S i g m o i d ( [ x 1 ( 1 ) , x 2 ( 1 ) , . . . , x n ( 1 ) , 1 x 1 ( 2 ) , x 2 ( 2 ) , . . . , x n ( 2 ) , 1 . . . x 1 ( m ) , x 2 ( m ) , . . . , x n ( m ) , 1 ] ⋅ [ w 1 w 2 . . . w n b ] ) = X ^ T S i g m o i d ( X ^ ⋅ w ^ ) \begin{aligned} \left [\begin{array}{cccc} \sum^m_{i=1}x_1^{(i)}Sigmoid(\hat x^{(i)} \cdot \hat w) \\ \sum^m_{i=1}x_2^{(i)}Sigmoid(\hat x^{(i)} \cdot \hat w) \\ . \\ . \\ . \\ \sum^m_{i=1}x_n^{(i)}Sigmoid(\hat x^{(i)} \cdot \hat w) \\ \sum^m_{i=1}Sigmoid(\hat x^{(i)} \cdot \hat w) \\ \end{array}\right] &=\left [\begin{array}{cccc} x^{(1)}_1, x^{(2)}_1, ... ,x^{(m)}_1 \\ x^{(1)}_2, x^{(2)}_2, ... ,x^{(m)}_2 \\ . \\ . \\ . \\ x^{(1)}_m, x^{(2)}_m, ... ,x^{(m)}_m \\ 1, 1, ... ,1, 1 \\ \end{array}\right] \cdot \left [\begin{array}{cccc} Sigmoid(\hat x^{(1)} \cdot \hat w) \\ Sigmoid(\hat x^{(2)} \cdot \hat w) \\ . \\ . \\ . \\ Sigmoid(\hat x^{(m)} \cdot \hat w) \\ \end{array}\right] \\ &=\left [\begin{array}{cccc} x^{(1)}_1, x^{(1)}_2, ... ,x^{(1)}_n, 1 \\ x^{(2)}_1, x^{(2)}_2, ... ,x^{(2)}_n, 1 \\ . \\ . \\ . \\ x^{(m)}_1, x^{(m)}_2, ... ,x^{(m)}_n, 1 \\ \end{array}\right]^T \cdot Sigmoid( \left [\begin{array}{cccc} x^{(1)}_1, x^{(1)}_2, ... ,x^{(1)}_n, 1 \\ x^{(2)}_1, x^{(2)}_2, ... ,x^{(2)}_n, 1 \\ . \\ . \\ . \\ x^{(m)}_1, x^{(m)}_2, ... ,x^{(m)}_n, 1 \\ \end{array}\right] \cdot \left [\begin{array}{cccc} w_1 \\ w_2 \\ . \\ . \\ . \\ w_n \\ b \\ \end{array}\right]) \\ &= \hat X^T Sigmoid(\hat X \cdot \hat w) \end{aligned} ⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡∑i=1mx1(i)Sigmoid(x^(i)⋅w^)∑i=1mx2(i)Sigmoid(x^(i)⋅w^)...∑i=1mxn(i)Sigmoid(x^(i)⋅w^)∑i=1mSigmoid(x^(i)⋅w^)⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡x1(1),x1(2),...,x1(m)x2(1),x2(2),...,x2(m)...xm(1),xm(2),...,xm(m)1,1,...,1,1⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤⋅⎣⎢⎢⎢⎢⎢⎢⎡Sigmoid(x^(1)⋅w^)Sigmoid(x^(2)⋅w^)...Sigmoid(x^(m)⋅w^)⎦⎥⎥⎥⎥⎥⎥⎤=⎣⎢⎢⎢⎢⎢⎢⎢⎡x1(1),x2(1),...,xn(1),1x1(2),x2(2),...,xn(2),1...x1(m),x2(m),...,xn(m),1⎦⎥⎥⎥⎥⎥⎥⎥⎤T⋅Sigmoid(⎣⎢⎢⎢⎢⎢⎢⎢⎡x1(1),x2(1),...,xn(1),1x1(2),x2(2),...,xn(2),1...x1(m),x2(m),...,xn(m),1⎦⎥⎥⎥⎥⎥⎥⎥⎤⋅⎣⎢⎢⎢⎢⎢⎢⎢⎢⎡w1w2...wnb⎦⎥⎥⎥⎥⎥⎥⎥⎥⎤)=X^TSigmoid(X^⋅w^)
同时,后半部分可简化为:
[ ∑ i = 1 m x 1 ( i ) y ( i ) ∑ i = 1 m x 2 ( i ) y ( i ) . . . ∑ i = 1 m x n ( i ) y ( i ) ∑ i = 1 m y ( i ) ] = [ x 1 ( 1 ) , x 2 ( 1 ) , . . . , x n ( 1 ) , 1 x 1 ( 2 ) , x 2 ( 2 ) , . . . , x n ( 2 ) , 1 . . . x 1 ( m ) , x 2 ( m ) , . . . , x n ( m ) , 1 ] T ⋅ [ y ( 1 ) y ( 2 ) . . . y ( m ) ] = X ^ T ⋅ y \begin{aligned} \left [\begin{array}{cccc} \sum^m_{i=1}x_1^{(i)}y^{(i)} \\ \sum^m_{i=1}x_2^{(i)}y^{(i)} \\ . \\ . \\ . \\ \sum^m_{i=1}x_n^{(i)}y^{(i)} \\ \sum^m_{i=1}y^{(i)} \\ \end{array}\right] = \left [\begin{array}{cccc} x^{(1)}_1, x^{(1)}_2, ... ,x^{(1)}_n, 1 \\ x^{(2)}_1, x^{(2)}_2, ... ,x^{(2)}_n, 1 \\ . \\ . \\ . \\ x^{(m)}_1, x^{(m)}_2, ... ,x^{(m)}_n, 1 \\ \end{array}\right]^T \cdot \left [\begin{array}{cccc} y^{(1)} \\ y^{(2)} \\ . \\ . \\ . \\ y^{(m)} \\ \end{array}\right]=\hat X^T \cdot y \end{aligned} ⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡∑i=1mx1(i)y(i)∑i=1mx2(i)y(i)...∑i=1mxn(i)y(i)∑i=1my(i)⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤=⎣⎢⎢⎢⎢⎢⎢⎢⎡x1(1),x2(1),...,xn(1),1x1(2),x2(2),...,xn(2),1...x1(m),x2(m),...,xn(m),1⎦⎥⎥⎥⎥⎥⎥⎥⎤T⋅⎣⎢⎢⎢⎢⎢⎢⎡y(1)y(2)...y(m)⎦⎥⎥⎥⎥⎥⎥⎤=X^T⋅y
因此,逻辑回归损失函数的梯度计算公式为:
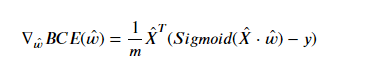
并且,据此我们可以定义逻辑回归的梯度计算公式:
def logit_gd(X, w, y):
"""
逻辑回归梯度计算公式
"""
m = X.shape[0]
grad = X.T.dot(sigmoid(X.dot(w)) - y) / m
return grad
其实,无论是理论推导还是手动实现,对于机器学习的建模流程来说,只要我们采用梯度下降方法进行参数求解,就需要有以下环节:根据算法原理构建损失函数——根据损失函数构建梯度更新表达式——根据梯度表达式进行参数更新,而在这个过程中,损失函数的构建和梯度表达式的计算其实都是涉及理论部分内容相对较深而实践过程高度重复的,即一旦我们推导出逻辑回归模型的梯度计算公式,在未来长期建模过程中该式都无须更改甚至无须关注,而这部分功能代码,往往都是封装在更高级框架里面的函数或者类。这也是导致我们在调库实现机器学习建模时往往会忽视损失函数和梯度更新表达式的函数形式,而只看重最终建模结果。
当然,这么做其实无可厚非,对于初中级用户来说,首先最重要的是完成建模整个流程,然后在此基础之上不断精进建模技巧。但无论何时,我们都需要知道工具和框架都只是实现的一种途径,其背后的原理才是能够解决问题的关键。














 1200
1200











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









