







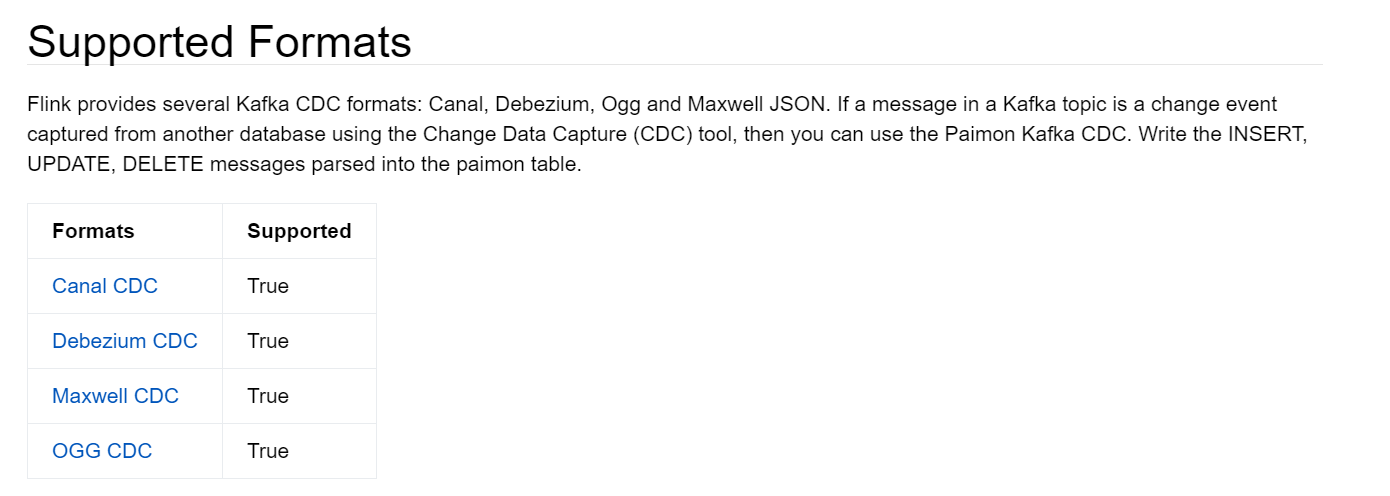
Flink提供了几种KafkaCDC格式:canal-json、debezium-json、ogg-json、maxwell-json。如果Kafka主题中的消息是使用更改数据捕获(CDC)工具从另一个数据库捕获的更改事件,则可以使用Paimon 的KafkaCDC。将解析后的INSERT、UPDATE、DELETE消息写入到paimon表中。Paimon官网列出支持的格式如下:
FlinkSQL CDC
目前Flink1.20版本自身的kafka-connector中支持的cdc数据格式主要是三种,分别是debezium、maxwell和cancel。

Maxwell
Maxwell简介
以Maxwell为例,Maxwell是一个 CDC(变更日志数据捕获)工具,可以将变更从 MySQL 实时传输到 Kafka、Kinesis 和其他流式连接器中。Maxwell 为变更日志提供了统一的格式模式,并支持使用 JSON 序列化消息。
Flink 支持将 Maxwell JSON 消息解释为 Flink SQL 系统中的 INSERT/UPDATE/DELETE 消息。这在许多情况下都很有用,例如
- 将数据库的增量数据同步到其他系统
- 审计日志
- 数据库的实时物化视图
- 时间连接数据库表的变化历史等等。
Flink 还支持将 Flink SQL 中的 INSERT/UPDATE/DELETE 消息编码为 Maxwell JSON 消息,并发送到 Kafka 等外部系统。但是,目前 Flink 无法将 UPDATE_BEFORE 和 UPDATE_AFTER 合并为单个 UPDATE 消息。因此,Flink 将 UPDATE_BEFORE 和 UDPATE_AFTER 编码为 DELETE (-D)和 INSERT Maxwell (+I)消息。
FlinkSQL集成Maxwell
Maxwell官方文档:Data Format - Maxwell's Daemon
Maxwell 为 changelog 提供了统一的格式,下面是一个从 MySQLproducts表捕获的 JSON 格式的更新操作的简单示例:
{
"database":"test",
"table":"e",
"type":"insert", -- 事件类型
"ts":1477053217,
"xid":23396,
"commit":true,
"position":"master.000006:800911",
"server_id":23042,
"thread_id":108,
"primary_key": [1, "2016-10-21 05:33:37.523000"],
"primary_key_columns": ["id", "c"],
"data":{
"id":111,
"name":"scooter",
"description":"Big 2-wheel scooter",
"weight":5.15
},
"old":{
"weight":5.18,
}
}假设此消息已同步到 Kafka 主题,那么我们可以使用以下Flink SQL的 DDL 来使用此主题并解释更改事件,注册成flink表。
CREATE TABLE topic_products (
-- schema is totally the same to the MySQL "products" table
id BIGINT,
name STRING,
description STRING,
weight DECIMAL(10, 2)
) WITH (
'connector' = 'kafka',
'topic' = 'products_binlog',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'testGroup',
'format' = 'maxwell-json'
)除此之外还可以配置一些格式元数据字段,比如数据库,表名、主键列、连接器处理事件的时间戳等,另外还有一些Maxwell和FlinkSQL映射的高级配置,可参考官网:Maxwell | Apache Flink
Paimon CDC
0.8版本的paimon对上面flink这三种cdc工具的数据格式都支持了,可以直接上手使用。目前flink社区主要是阿里的人在维护,canel本身是阿里推出的开源cdc工具,因此paimon中优先最早支持的cdc格式就是Canal CDC format,不过后续像什么maxwell这些都支持了。
canal cdc
canal的cdc数据格式如下,测试数据为一条mysql的update事件,mysql的表有四个字段,主键为id,将weight字段的值由5.15 update 成了 5.18。
{
"data": [
{
"id": "111",
"name": "scooter",
"description": "Big 2-wheel scooter",
"weight": "5.18"
}
],
"database": "inventory",
"es": 1589373560000,
"id": 9,
"isDdl": false,
"mysqlType": {
"id": "INTEGER",
"name": "VARCHAR(255)",
"description": "VARCHAR(512)",
"weight": "FLOAT"
},
"old": [
{
"weight": "5.15"
}
],
"pkNames": [
"id"
],
"sql": "",
"sqlType": {
"id": 4,
"name": 12,
"description": 12,
"weight": 7
},
"table": "products",
"ts": 1589373560798,
"type": "UPDATE"
}一、测试kafka的正常消费
创建topic paimon_canal_test 并插入标准的canal cdc数据
kafka-console-producer.sh --broker-list node002:9092,node003:9092 --topic paimon_canal_test
kafka-console-consumer.sh --bootstrap-server node002:9092,node003:9092 --topic paimon_canal_test -from-beginning

二、canal Paimon表同步
使用表同步,kafka的topic只能包含一张表的数据,同步到paimon的一张表中。paimon cdc同步kafka数据仍然使用action包来提交,提交参数如下,主要分为三部分:目标库和表的配置、kafka的配置、catalog和table的conf配置,paimon表不存在会自动创建。
<FLINK_HOME>/bin/flink run \
/path/to/paimon-flink-action-0.8.2.jar \
kafka_sync_table
--warehouse <warehouse-path> \
--database <database-name> \
--table <table-name> \
[--partition_keys <partition_keys>] \
[--primary_keys <primary-keys>] \
[--type_mapping to-string] \
[--computed_column <'column-name=expr-name(args[, ...])'> [--computed_column ...]] \
[--kafka_conf <kafka-source-conf> [--kafka_conf <kafka-source-conf> ...]] \
[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]] \
[--table_conf <paimon-table-sink-conf> [--table_conf <paimon-table-sink-conf> ...]]bin/flink run \
/opt/model/flink-1.18.1/opt/paimon-flink-action-0.8-20240709.052248-82.jar \
kafka-sync-table \
--warehouse hdfs://node001:8020/paimon/hive \
--database default \
--table ods_kafka_user_info_cdc \
--primary-keys id \
--kafka-conf properties.bootstrap.servers=node002:9092 \
--kafka-conf topic=paimon_canal_test \
--kafka-conf properties.group.id=paimon_group \
--kafka-conf scan.startup.mode=earliest-offset \
--kafka-conf value.format=canal-json \
--catalog-conf metastore=hive \
--catalog-conf uri=thrift://node001:9083 \
--table-conf bucket=4 \
--table-conf changelog-producer=input \
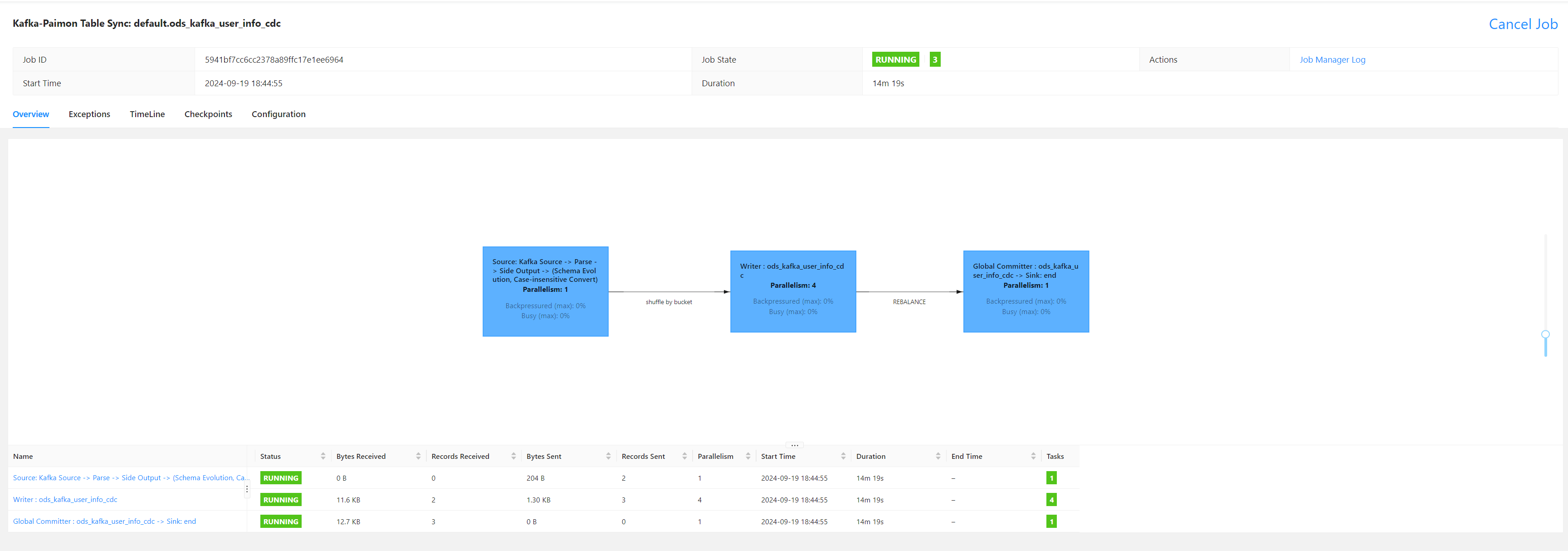
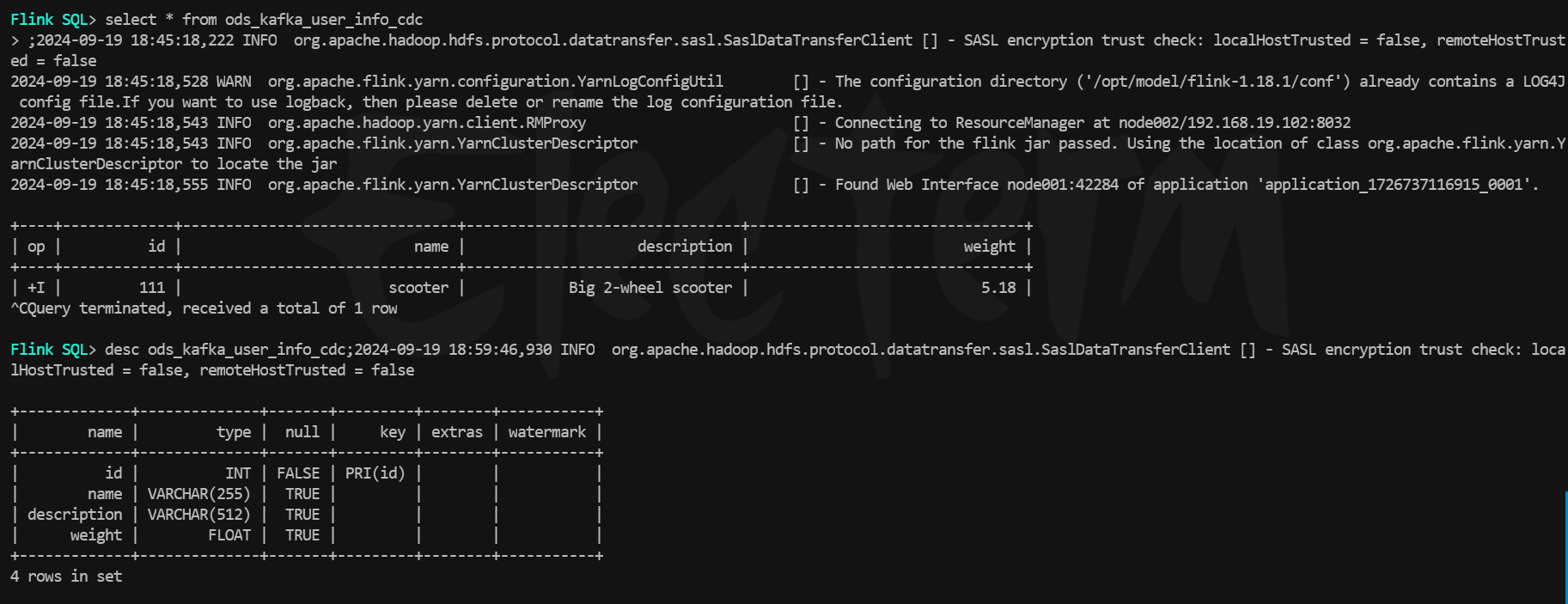
--table-conf sink.parallelism=4执行上述上面提交命令,查看Flink集群的UI,任务已经被成功提交运行了,在sql客户端种查询,paimon表已经自动被创建好了,执行查询,数据已经进来了,由于这里只有一条测试数据,即使是update操作也看不到-D +I这种,因为数据只有一条,不过已经能证明测试成功了。
三、canel Paimon 库同步
表同步的方式只能应用于单表对应一个kafka topic,在大数据生产环境下,一般很少会为每张表配置一个topic,一般是按业务域或数据主题划分,将统一主题的表的cdc日志都写入一个topic,再使用flink进行消费分流处理。Paimon支持将kafka多个或一个topic同步到一个paimon数据库中,可以自动识别出不同的表的数据,插入到对应的paimon表中,提交参数如下,和表同步基本一样。
<FLINK_HOME>/bin/flink run \
/path/to/paimon-flink-action-0.8.2.jar \
kafka_sync_database
--warehouse <warehouse-path> \
--database <database-name> \
[--table_prefix <paimon-table-prefix>] \
[--table_suffix <paimon-table-suffix>] \
[--including_tables <table-name|name-regular-expr>] \
[--excluding_tables <table-name|name-regular-expr>] \
[--type_mapping to-string] \
[--kafka_conf <kafka-source-conf> [--kafka_conf <kafka-source-conf> ...]] \
[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]] \
[--table_conf <paimon-table-sink-conf> [--table_conf <paimon-table-sink-conf> ...]][--table_prefix <paimon-table-prefix>] paimon表前缀
[--table_suffix <paimon-table-suffix>] paimon表后缀
[--including_tables <table-name|name-regular-expr>] 包含表的数据列
[--excluding_tables <table-name|name-regular-expr>] 不包含表的数据列
(一)kafka单topic多表数据
- 继续使用paimon_canal_test的topic,并新增一张spu_info表,使用生产者插入两条测试数据,来源于不同的mysql表的变更日志
{"data":[{"id":"111","name":"scooter","description":"Big 2-wheel scooter","weight":"5.19"}],"database":"inventory","es":1589373560000,"id":9,"isDdl":false,"mysqlType":{"id":"INTEGER","name":"VARCHAR(255)","description":"VARCHAR(512)","weight":"FLOAT"},"old":[{"weight":"5.18"}],"pkNames":["id"],"sql":"","sqlType":{"id":4,"name":12,"description":12,"weight":7},"table":"products","ts":1589373560799,"type":"UPDATE"}
{"data":[{"spu_id":"10001","spu_name":"apple15 plus"}],"database":"inventory","es":1589373560000,"id":9,"isDdl":false,"mysqlType":{"spu_id":"INTEGER","spu_name":"VARCHAR(255)"},"old":[{"spu_name":"apple15"}],"pkNames":["spu_id"],"sql":"","sqlType":{"spu_id":4,"spu_name":12},"table":"spu_info","ts":1589373560799,"type":"UPDATE"}- 提交任务到flink集群,从一个kafka主题中同步多表数据到paimon数据库
bin/flink run \
/opt/model/flink-1.18.1/opt/paimon-flink-action-0.8-20240709.052248-82.jar \
kafka-sync-database \
--warehouse hdfs://node001:8020/paimon/hive \
--database default \
--table-prefix "ods_" \
--table-suffix "_cdc" \
--schema-init-max-read 500 \
--kafka-conf properties.bootstrap.servers=node002:9092 \
--kafka-conf topic=paimon_canal_test \
--kafka-conf properties.group.id=paimon_group \
--kafka-conf scan.startup,mode=earliest-offset \
--kafka-conf value.format=canal-json \
--catalog-conf metastore=hive \
--catalog-conf uri=thrift://node001:9083 \
--table-conf bucket=1 \
--table-conf changelog-producer=input \
--table-conf sink.parallelism=1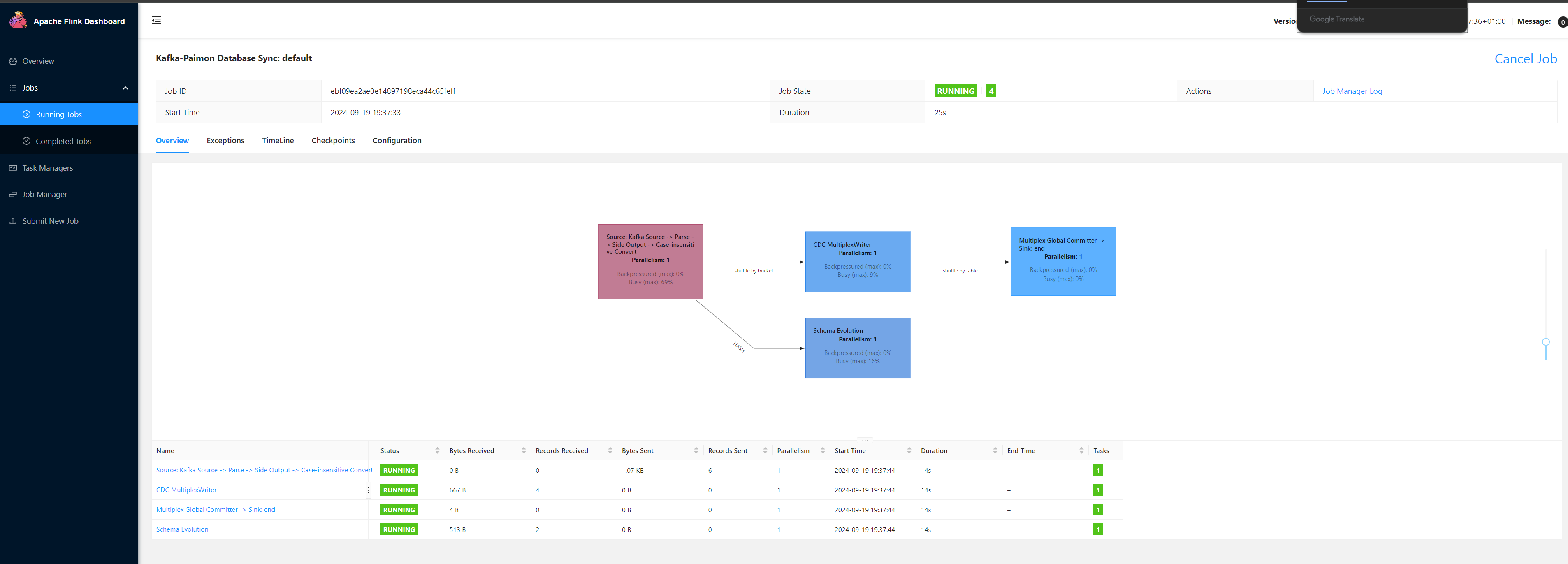
- 测试paimon表
- 表结构:两张表均被创建并且字段对应
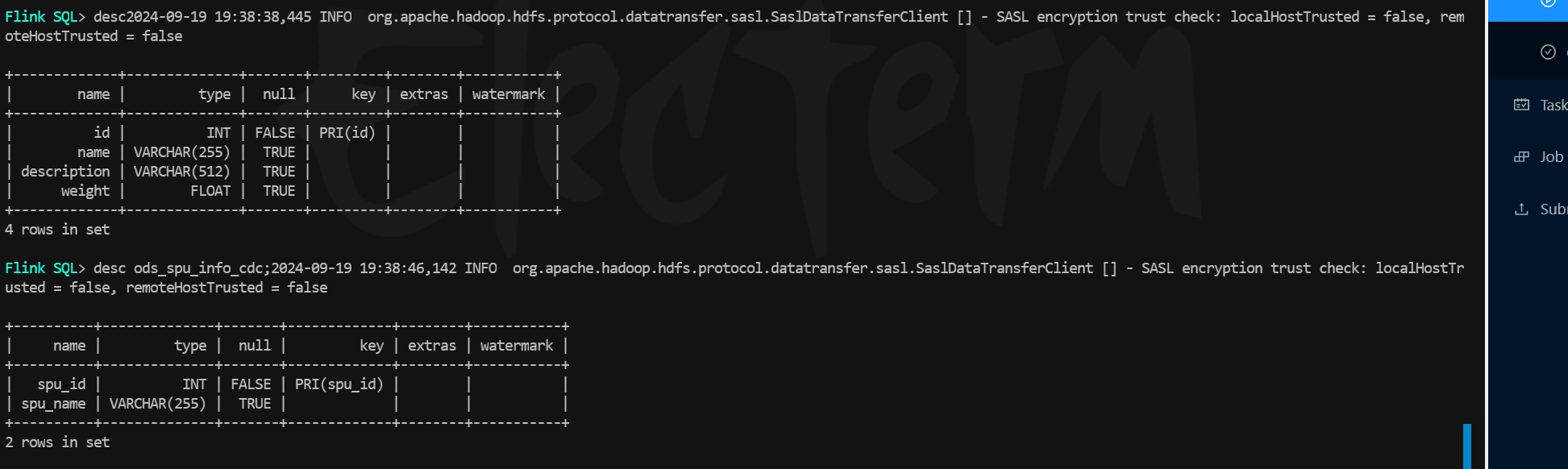
- 新增数据:topic中不同mysql表的changelog被写入到了对应的paimon表中,注意这里products表中只有一条数据的原因是因为使用了和上一次测试同样的消费者组,因此不会产生-D数据,从上次的offset继续消费了。
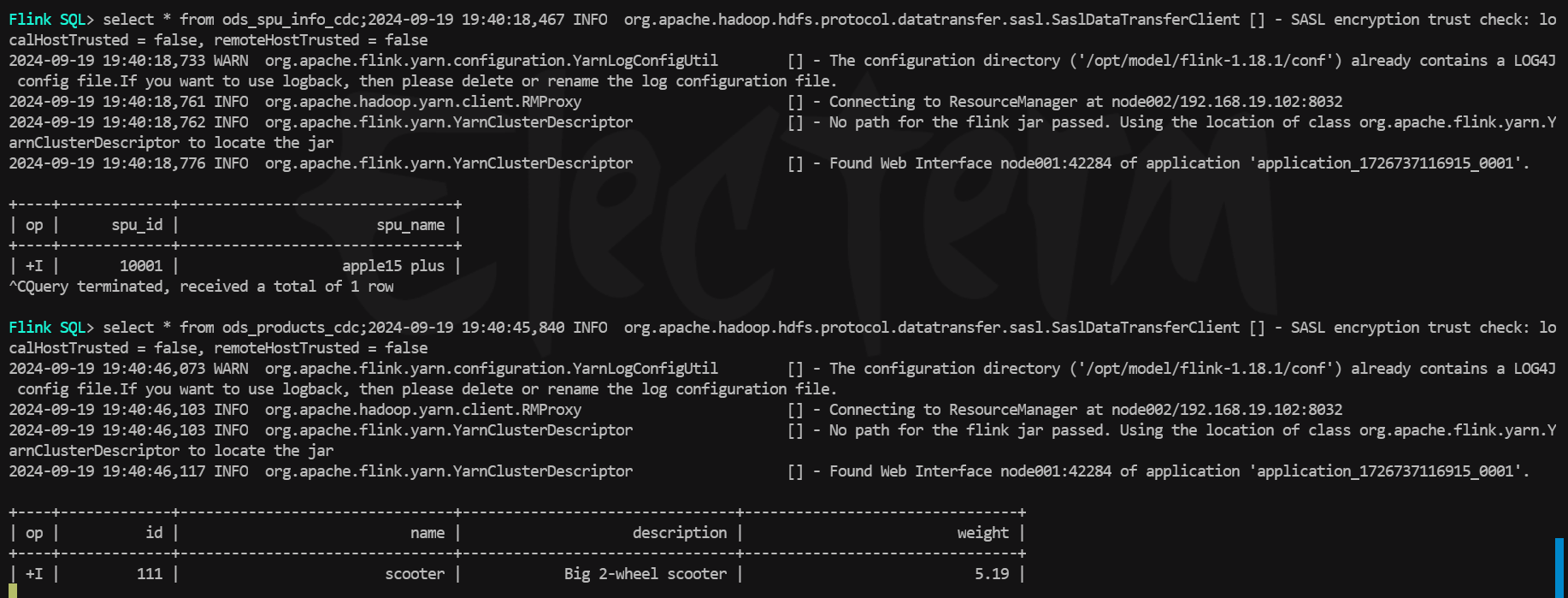
(二)kakfa多topic多表数据
还可以将多个topic中的多张表自动识别,写入对应的paimon表中,实现逻辑是类似的,提交参数也大致相同
bin/flink run \
/opt/model/flink-1.18.1/opt/paimon-flink-action-0.8-20240709.052248-82.jar \
kafka-sync-database \
--warehouse hdfs://node001:8020/paimon/hive \
-database default \
--table-prefix "ods_" \
--table-suffix "_cdc_2" \
--kafka-conf properties.bootstrap.servers=node002:9092 \
--kafka-conf topic="paimon_canal;paimon_canal_1" \
--kafka-conf properties.group.id=paimon_group_2 \
--kafka-conf scan.startup.mode=earliest-offset \
--kafka-conf value.format=canal-json \
--catalog-conf metastore=hive \
-catalog-conf uri=thrift://hadoop102:9083 \
--table-conf bucket=1 \
--table-conf changelog-producer=input \
--table-conf sink.parallelism=1注意这里的kafka-conf中的topic列表,topic之间要以;分割,不然flink无法识别会报错,不过在paimon的官网文档上给的是topic分隔符是',',经过测试会报错的,不知道后续版本会不会修改。
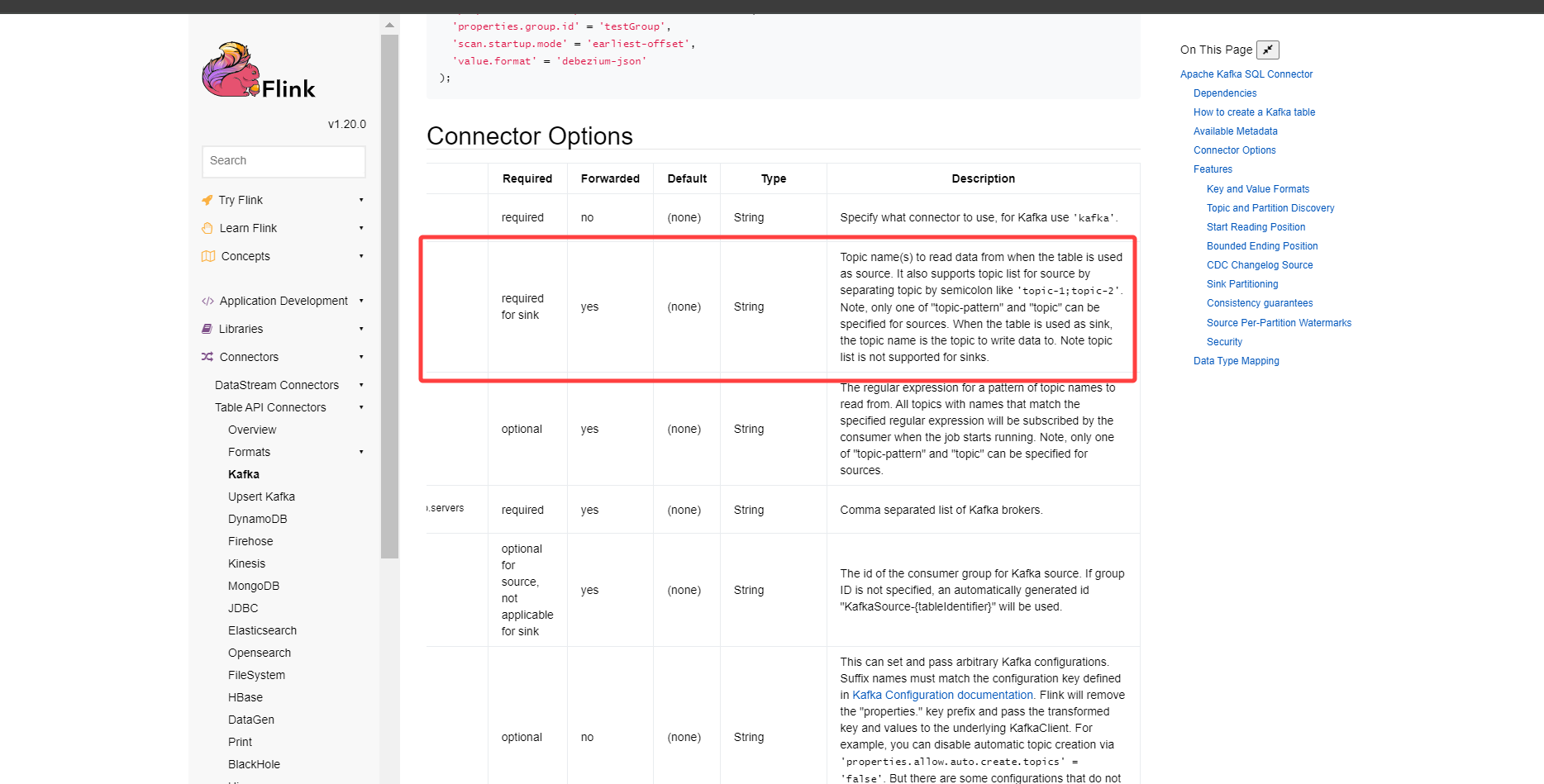















 535
535

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









