







数据湖、湖仓一体是当前大数据领域技术发展的重要趋势。近几年开源数据湖技术如 Apache Hudi、Apache Iceberg、Apache Paimon、DeltaLake 等不断涌现,基于湖仓一体架构的统一元数据管理、数据治理也越来越受到关注。从传统数仓到数据湖、湖仓一体架构,从流批一体计算到基于数据湖的流批一体存储,越来越多的企业基于开源技术,在集成、计算、存储、查询分析等方面不断优化,建设形成适合自身业务发展的湖仓平台。本章我们将介绍 Apache Paimon 的概念以及 Flink Paimon 相关的实现方式。
目录
Apache Paimon 简介
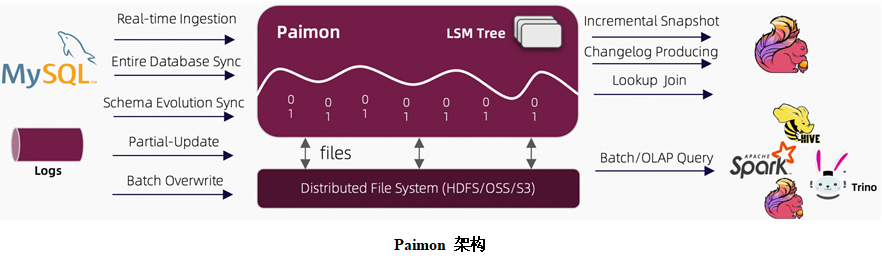
Apache Paimon 是一个流数据湖平台,具有高速数据摄取、变更日志跟踪和高效的实时分析的能力。2022 年 1 月,Flink Table Store 诞生,孵化一年后,2023 年 1 月,产生了正式 0.3 的版本,之后从 Flink 社区迁到 Apache 社区,并改名为 Apache Paimon,不再是 Flink 存储,而是面向社区所有计算引擎的存储。

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 2258
2258

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











