







原文地址:[2501.12381] Parallel Sequence Modeling via Generalized Spatial Propagation Network
发表会议:暂定
作者:王洪军(英伟达实习生)、Byeon Wonmin、徐嘉瑞、顾金伟、许嘉淳、王小龙、韩凯、Kautz Jan、刘思非
团队:英伟达、香港大学、加州大学圣地亚哥分校
读前必看:
本人是做时间序列的,觉得CV方向的这篇论文可以分享一下,这里因不是专业的所以实验部分略过。思考:GSPN是构建在convolution基础上,也许把此模块放到时间序列中,有可能进一步提高算法的预测准确度。把其中的convolution或注意力用GSPN替换等。这里欢迎大家探讨!
摘要:
一种名为广义空间传播网络(GSPN)的新型注意力机制。GSPN能够自然地捕捉图像中的二维空间结构,这与传统的注意力模型不同。与处理多维数据时将其作为一维序列的其他模型(如Transformer和Mamba)相比,GSPN直接在空间连贯的图像数据上操作,并通过线扫描方法形成了像素间的密集连接。GSPN的核心是其Stability-Context Condition,它保证了在二维序列上的稳定传播,并显著提高了计算效率,因为它将处理的数据量减少到了原始数量的平方根。
GSPN使用可学习的、依赖输入的权重,并且不需要位置嵌入,这使其在空间保真度上表现出色,并在图像分类、图像生成和文本到图像生成等视觉任务中达到了最先进性能。
Transformer的局限性:
首先,它的计算复杂度是二次的,这意味着计算成本随着数据规模的增长而迅速增加。这在in-depth context modeling(例如高分辨率图像)时尤其成问题,因为这类任务需要大量的计算资源。 其次,Transformer模型将数据视为结构无关的tokens(标记或元素),忽略了数据中的空间连贯性。这种忽略空间结构的设计在视觉任务中是不利的,因为视觉任务中保持位置关系是非常关键的。
科普:
- 状态空间模型(SSMs):利用线性递归动态来有效地捕捉长距离依赖关系。
- 线性注意力方法:一种策略是利用核方法,另一种策略是通过改变计算顺序来利用矩阵乘法的结合律。
- 增强空间一致性的目的:空间一致性是指图像中相邻像素之间的相似性。通过增强这种一致性,可以提高图像的质量和后续处理的效果。
- 二维线性传播的挑战:
- 矩阵权重:在一维扫描中,像素之间的关系可以用标量权重表示。但在二维扫描中,每个像素与其前一行的相邻像素之间的关系需要用矩阵来表示。这意味着在传播过程中涉及到矩阵乘法的累积计算。
- 稳定性问题:如果这些矩阵的特征值较大,可能会导致不稳定现象,如指数增长,导致数值溢出。相反,如果特征值过小,信号可能会快速衰减,导致信息丢失。 权重减少与稳定性:为了保持稳定性,可能需要减少权重的大小,但这会限制每个像素的感受野(即它能够感知到的相邻像素范围),从而减弱长距离依赖性。
引言关键点
GSPN是一种针对图像处理优化的注意力机制,它通过引入稳定性-上下文条件来确保有效的信息传播,并通过并行化的线扫描操作来提高计算效率,同时保持了二维空间结构信息的完整性。这使得GSPN在处理图像等多维数据时比现有的注意力机制更具优势。如图1所示
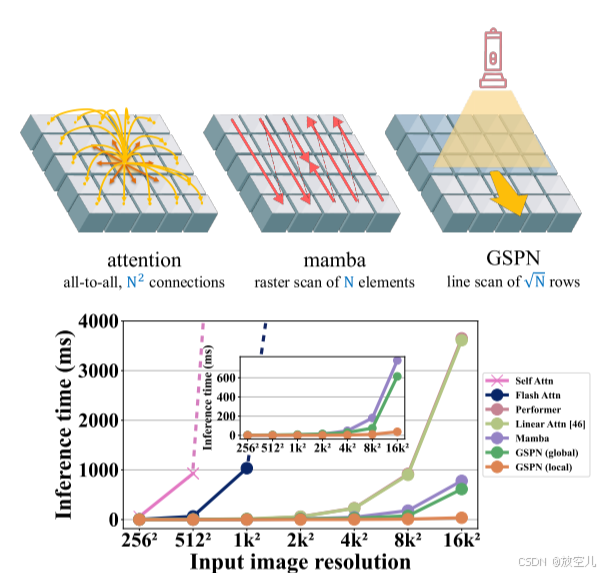
关键设计保留:使用3向连接来提高参数效率。这意味着网络中每个像素只与它的三个相邻像素(而不是所有相邻像素)相连,从而减少了参数数量。
GSPN通过4个方向的整合(即上、下、左、右)确保了像素之间的完全连接性,形成了一种密集的成对连接。
两种GSPN的变种: 一种捕捉整个输入的全局上下文。 另一种集中于局部区域,以实现更快的传播。 这些变种使得GSPN能够无缝地集成到现代视觉架构中,作为现有注意力模块的直接替代。
GSPN引入了一个可学习的合并器,它从所有扫描方向聚合空间信息,增强了模型动态适应视觉数据二维结构。
科普:
混叠问题是指由于处理过程中的采样或其他操作导致的信息丢失或失真。
方法
二维(2D)线性传播的基本原理和过程:
-
基本概念:2D线性传播通过按行或按列的顺序处理图像数据。
-
图像表示:图像被表示为一个三维张量
,其中 n 是图像的边长,C 是颜色通道数。
-
线性递归过程:隐藏层状态通过一个线性递归公式更新
,该公式结合了前一行的隐藏状态和当前行的输入像素。
-
输出计算:最终的输出是通过将隐藏层状态与输出权重逐元素相乘得到的
。
-
展开形式:隐藏状态
和输入
被转换为向量形式,并通过一个下三角矩阵 G 来计算输出。
-
与线性注意力的关系:通过将输入替换为值
并使用前馈网络层来参数化输出权重
和注意力权重
,可以将2D线性传播与线性注意力机制联系起来
。
-
应用:这种方法可以推广到任意尺寸的图像,并适用于多种图像处理任务,如特征提取和分类。
稳定性-上下文条件
本节主要探讨了如何设计一个乘积项来实现数据点之间稳定且有效的长距离信息传播。这一节强调了即使在数据点 i 和 j 相距较远的情况下,通过确保
是一个密集矩阵和
这两个条件,可以保证
和
之间存在密集的交互。这样,
中的每个元素都能成为
中所有元素的加权平均,从而确保信息的稳定性和有效传播。 此外,这一节介绍了两个定理,统称为“稳定性-上下文条件”,以满足上述要求。
- 定理1指出,如果所有的矩阵
都是行随机的,那么
就能得到满足。行随机矩阵是指其所有元素非负且每行元素之和为1的矩阵。
- 定理2进一步确保了当所有矩阵
如何设计一个高效的传播层来满足稳定性-上下文条件
-
目标:实现一个传播层,使得每个像素能够从其周围的像素接收信息,同时保持计算的效率和可扩展性。
-
方法:
-
直接方法:学习一个完整的矩阵 w,每个像素输出 n 个权重,将前一行的所有像素与当前行的每个像素连接起来,并归一化权重,使它们的和为1。这种方法会增加特征维度的数量。
-
改进方法:每个像素只与前一行的三个像素(左上、中上和右上)连接,使 w 成为一个三对角矩阵。这样可以减少特征维度的数量,同时满足稳定性-上下文条件。
-
-
线扫描:采用从四个方向(左到右、上到下、反之亦然)进行线扫描的方法,以确保所有像素之间有密集的成对连接。图2所示
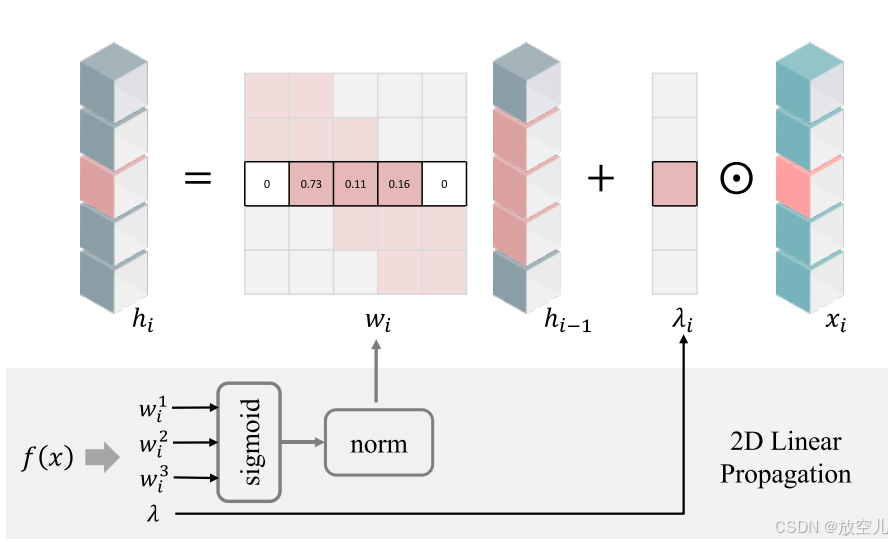
图2.二维线性传播。对于第i行,隐藏状态hi中的每一项通过以下方式计算:
(1)来自隐藏层hi−1的三个相邻值的加权和,其中权重形成归一化的三对角矩阵wi,以及(2)当前输入xi与λ的元素乘积。wi和λ都是可学习的和依赖于输入的参数。wi中的权重是通过应用sigmoid激活,然后进行逐行归一化来获得的。 -
行随机矩阵:
-
定义:行随机矩阵是指矩阵中所有元素非负,且每行元素之和为1的矩阵。
-
应用:为了确保矩阵 w 是行随机的,对每个非零元素应用sigmoid函数,然后对每行的元素进行归一化,使它们的和为1。每个非零元素可以表示为:
,其中 k 索引第 i 行的
个非零元素。
-
-
高效CUDA实现:
-
通过自定义的CUDA内核实现线性传播层,采用并行结构,每个块有512个线程,每个网格有
个块,其中 B 表示小批量大小,k 表示传播方向的数量。
-
每个线程沿着传播方向处理输入图像中的单个像素,实现完全并行化。
-
-
总结:这种设计有效地减少了内核循环长度,促进了高效和可扩展的线性传播。通过使用三对角矩阵和CUDA并行计算,可以在保持稳定性和上下文相关性的同时,提高计算效率。
GSPN架构
GSPN是一个通用的序列传播模块,可以无缝集成到神经网络中,用于各种视觉任务。图三是其结构图。
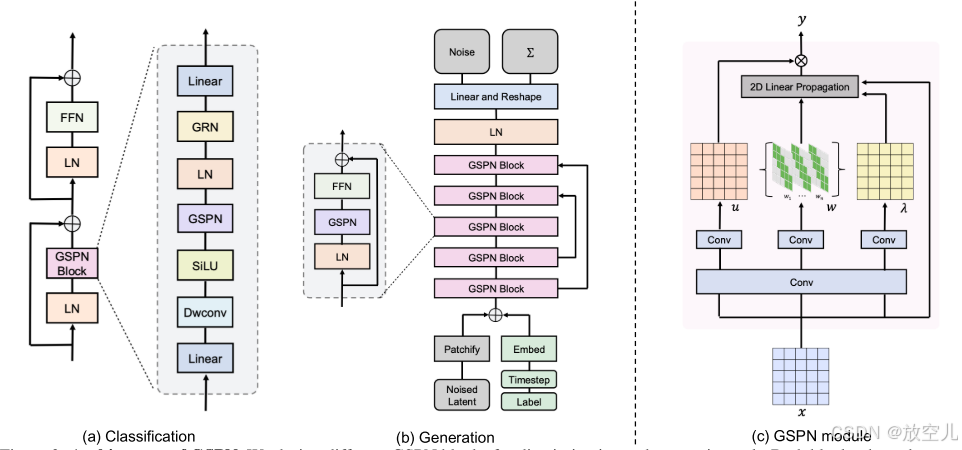
GSPN模块的设计
-
基本架构:
-
图像分类和生成任务的顶级设计共享基本的架构原则,这些原则是从成功的计算机视觉模型中借鉴而来的。
-
为了公平比较,这些架构只整合了常用的模块,包括可分离卷积、层归一化(LN)、门控残差网络(GRN)、前馈网络(FFN)和非线性激活函数。
-
-
全局与局部GSPN:
-
全局GSPN:这种GSPN在整张图像上操作,捕捉长距离依赖关系,称为全局GSPN。
-
局部GSPN:为了提高效率,引入了局部GSPN,它通过限制传播序列长度到局部区域来减少计算量。局部GSPN将一个空间维度分成 g 个不重叠的组,每个组包含满足特定条件的索引子集。在每个组内,局部GSPN根据公式计算隐藏状态。
-
-
分组策略:
-
这种分组策略使得计算可以并行进行,与全局GSPN相比,复杂度降低了 g 倍,在极端情况下(g=n)达到 O(1) 复杂度。
-
默认情况下,局部GSPN的组大小 g=2。
-
总结:全局GSPN模块来捕捉长距离依赖和整体特征,局部GSPN模块来保持空间结构和局部一致性。
GSPN在宏观和微观尺度上的关键设计原则,并将其与传统的注意力机制和Mamba模块进行了对比。
- 全局与局部GSPN的结合: 在早期阶段应用局部GSPN模块,以高效处理细粒度的空间细节。 随后使用全局GSPN模块聚合长距离上下文信息,以实现更高层次的语义理解。 这种层次化设计在准确性和效率之间实现了最佳权衡。
- 可学习的合并优于手动设计: 以前的工作(如SPN)通过最大池化操作手动合并多方向扫描信息,而GSPN实现了一个线性层,以动态聚合来自不同扫描方向的特征。 这种数据驱动的合并策略使网络能够根据当前输入传播自适应地加权和组合方向信息。
- 无需位置嵌入: GSPN设计表明,对于分类和生成任务,显式的位置嵌入是不必要的,因为空间信息已经通过扫描过程固有地编码。 这种设计选择有效地解决了最近工作中指出的混叠问题,同时偏离了依赖于可学习APE(绝对位置嵌入)和正弦函数或RoPE(旋转位置编码)的传统DiT方法。
- 减少归一化层: 通过最小化归一化层,我们在不牺牲性能的情况下提高了计算效率并减少了模型复杂性。 这表明在GSPN中,传统上广泛使用的归一化层可能是多余的,因为权重已经通过稳定性-上下文条件进行了归一化。
- GLU在GSPN中效果不佳: 与Mamba不同,经验证据表明门控线性单元(GLU)对GSPN没有显著好处。 这一观察结果表明2D线性传播可能已经提供了门控机制。
局限性
图1所示,在高分辨率图像上,GSPN的推理速度比其他方法快,尤其是在使用局部模块时。
-
内存限制:为了适应内存限制,特征维度被设置为1。
-
CUDA内核:尽管理论上GSPN在高分辨率下有优势,但实际的CUDA实现由于内存访问和共享内存使用效率问题,性能不如预期。
前向传播(Forward Pass)
-
计算位置:对于4D张量中的每个位置 (n,c,h,w),计算三个方向的连接(对角向上、水平、对角向下)。
-
使用门控:这些操作使用门控 G1,G2,G3 来实现,相当于在 h 和 w 维度之间进行矩阵乘法。
-
分组计算:计算被分为 g 组,其中 g=1 表示全局GSPN,g>1 表示局部GSPN。
-
最终隐藏状态:最终的隐藏状态 H 结合了输入转换
和方向连接 hype。

算法1
-
输入:需要输入张量 X, B, G1, G2, G3。
-
参数:需要知道图像的宽度(width)和每个线程块处理的项目数(kNItems)。
-
输出:确保输出张量 H。
-
步骤:
-
计算分组数 g,这是宽度除以每个线程块处理的项目数。
-
计算总的计算次数 count,这是分组数乘以高度、通道数和批次数。
-
使用两层循环遍历所有的计算项目。外层循环遍历每个项目,内层循环使用并行for循环(parfor)来处理每个项目。
-
在内层循环中,计算每个位置的索引 n,c,h,k,然后从输入张量中提取相应的数据。
-
使用门控 G1,G2,G3 和隐藏状态 H 计算三个方向的连接(对角向上、水平、对角向下)。
-
将这些连接相加得到 hhype,然后与输入转换 xhype 相加得到最终的隐藏状态 H。
-
反向传播(Backward Pass)
-
计算梯度:通过反向传播计算所有输入 (X,B,G1,G2,G3) 的梯度。
-
梯度流动:对于每个位置,梯度从未来的时步流入
。
-
输入梯度:输入梯度
通过 B 值计算,而门控梯度 (
) 使用误差项和先前的隐藏状态。

-
输入:需要输入张量 X, B, G1, G2, G3, H, Hdiff。
-
参数:同样需要知道图像的宽度(width)和每个线程块处理的项目数(kNItems)。
-
输出:确保输出张量 Xdiff, Bdiff, G1diff, G2diff, G3diff, Hdiff。
-
步骤:
-
同样计算分组数 g 和总的计算次数 count。
-
使用两层循环遍历所有的计算项目。外层循环遍历每个项目,内层循环使用并行for循环(parfor)来处理每个项目。
-
在内层循环中,计算每个位置的索引 n,c,h,k,然后从输出的梯度张量中提取相应的数据。
-
更新 hdiff 与未来时间步的贡献。
-
计算输入梯度 Xdiff 和门控梯度 G1diff,G2diff,G3diff。
-
代码讲解
代码部分,为了大家更好的阅读和探讨我在飞书进行上传,因作者还暂未开源所以未讲解,开源后我会立刻上传到此飞书链接:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









