










在对网页数据爬取时会出现字符集不对应而影响爬取出来的数据是一些看不懂的语言
本次解决方法使用的是某电影网站
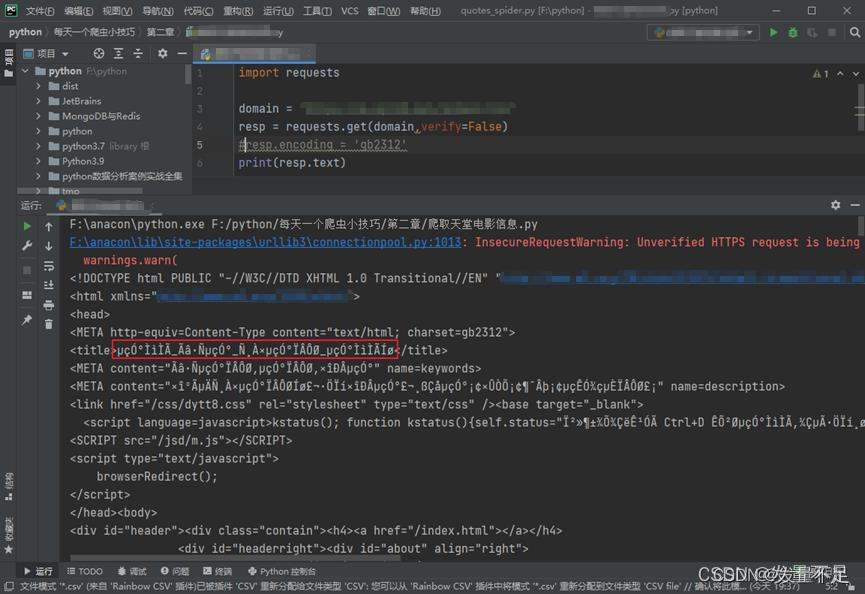
所以我们要添加上网页对应的字符集编码
字符集编码存放的两个位置
1.浏览器网页的源代码靠前位置有一个叫做 charset= 的东西这就是字符集编码
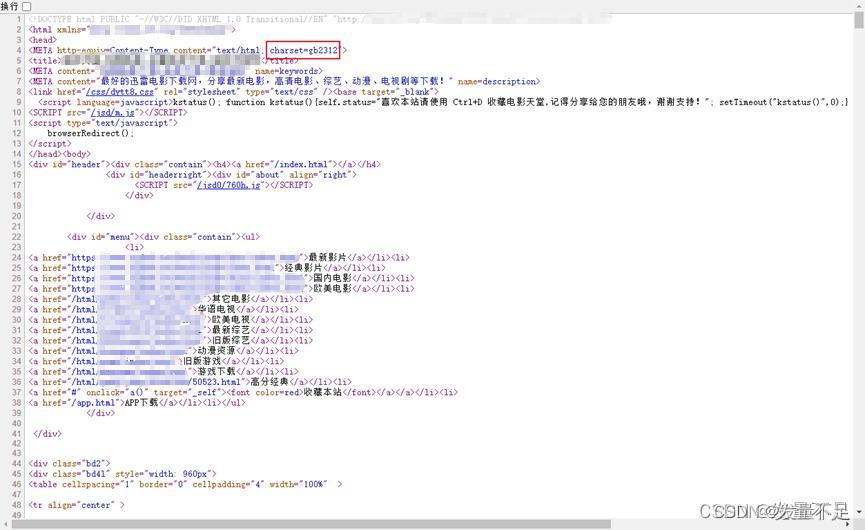
2.在爬取出来的页面源代码也可以找到charset= 这个字符集编码
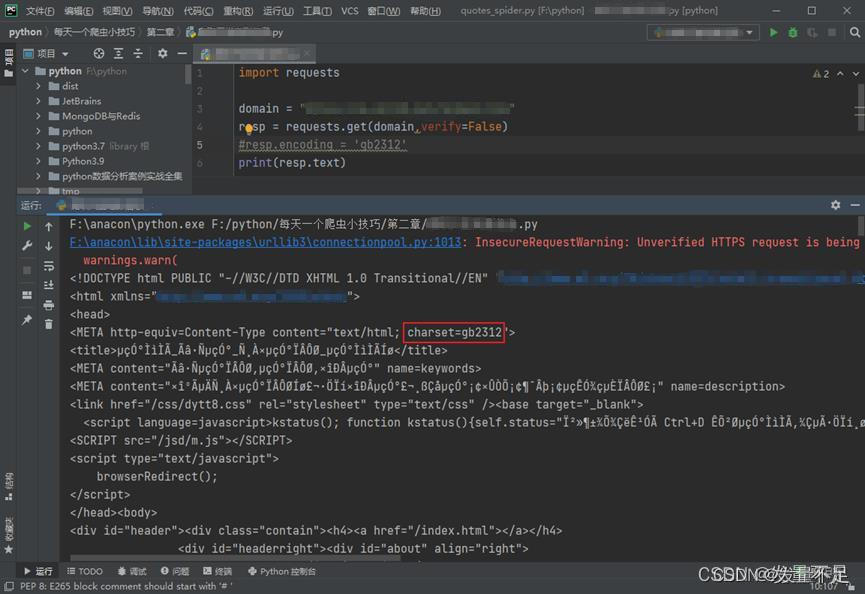
##添加指定字符集编码代码##
resp.encoding = 'gb2312'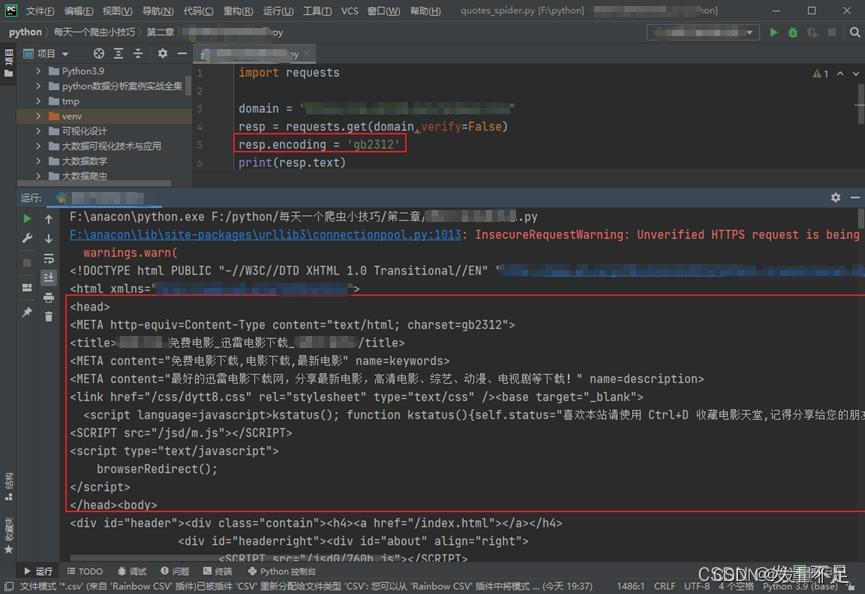
resp.encoding = 'gb2312'
 3320
3320











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




























