









代码实现效果
运行脚本后,会自动打开b站,按关键词搜索并抓取数据进行保存。
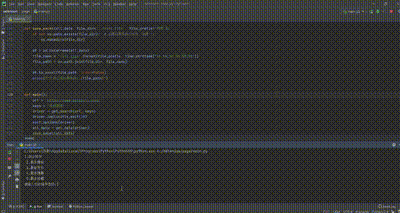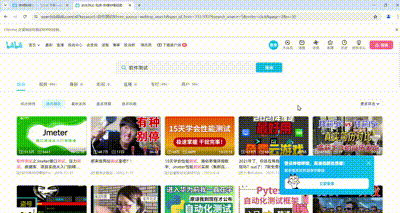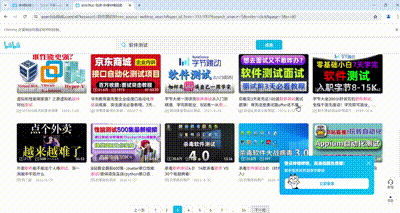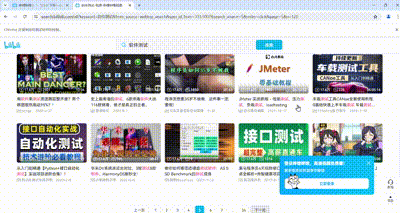
抓取下来的数据,自动保存为xlsx表格
 具体代码
具体代码
"""base.py"""
import time
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
class Base:
# 初始化
def __init__(self, driver):
self.driver = driver
# 查找元素方法
def base_find_element(self, loc, timeout=10, poll_frequency=0.5):
return WebDriverWait(driver=self.driver, timeout=timeout, poll_frequency=poll_frequency).until(
EC.presence_of_element_located(loc))
# 点击方法
def base_click(self, loc):
self.base_find_element(loc).click()
# 输入方法
def base_input(self, loc, value):
element = self.base_find_element(loc)
element.clear()
element.send_keys(value)
# 获取文本方法
def base_get_text(self, loc):
msg = self.base_find_element(loc).text
return msg
# 截图
def base_get_image(self, loc):
self.driver.get_screenshot_as_file("./{}.png".format(time.strftime("%Y_%m_%d_%H_%M_%S")))
# 移动鼠标
def base_move_mouse(self, loc):
ActionChains(self.driver).move_to_element(loc).perform()
from selenium import webdriver
from selenium.webdriver.common.by import By
from openpyxl import Workbook
import os.path
import requests
from Base.base import Base
import os
import pandas as pd
import time
def get_search(url, keys):
# 创建驱动对象,输入B站网址
driver = webdriver.Chrome()
driver.get(url)
# 最大化窗口
driver.maximize_window()
time.sleep(1)
# 搜索框搜索
base = Base(driver)
base.base_find_element((By.XPATH, '//input[@class="nav-search-input"]'))
base.base_input((By.XPATH, '//input[@class="nav-search-input"]'), keys)
base.base_click((By.XPATH, '//div[@class="nav-search-btn"]'))
# 窗口切换
for handle in driver.window_handles:
driver.switch_to.window(handle)
if keys in driver.title:
break
time.sleep(1)
return driver
def sort_options(driver):
print('1.综合排序\n 2.最多播放\n 3.最新发布\n 4.最多弹幕\n 5.最多收藏')
outcome = int(input("请输入你的排序选项:"))
if outcome == 1:
print('===================================综合排序===============================================')
elif outcome == 2:
driver.find_element(By.XPATH, '//button[2][@class="vui_button vui_button--tab mr_sm"]').click()
print('===================================最多播放===============================================')
elif outcome == 3:
driver.find_element(By.XPATH, '//button[3][@class="vui_button vui_button--tab mr_sm"]').click()
print('===================================最新发布===============================================')
elif outcome == 4:
driver.find_element(By.XPATH, '//button[4][@class="vui_button vui_button--tab mr_sm"]').click()
print('===================================最多弹幕===============================================')
elif outcome == 5:
driver.find_element(By.XPATH, '//button[5][@class="vui_button vui_button--tab mr_sm"]').click()
print('===================================最多收藏===============================================')
def get_data(driver):
all_data = []
num = 1
base = Base(driver)
pages_locator = (By.CSS_SELECTOR, '.vui_pagenation--btns button:nth-last-child(2)')
pages_num = base.base_get_text(pages_locator) # 获取页数
while num <= int(pages_num):
print(f'=====================================正在保存第{num}页的数据内容=================================')
try:
page_next = driver.find_element(By.CSS_SELECTOR, '.vui_pagenation--btns button:nth-last-child(1)')
base.base_move_mouse(page_next)
except:
print('===================================最后一页了===============================================')
time.sleep(1)
all_div = driver.find_elements(By.XPATH, '//div[@class="video-list row"]/div') # 获取所有 视频元素
for i in all_div:
# 获取视频关键信息,并返回
try:
title = i.find_element(By.CSS_SELECTOR, 'div h3').get_attribute('title')
link = i.find_element(By.CSS_SELECTOR, 'div a').get_attribute('href')
up_name = i.find_element(By.CSS_SELECTOR, 'div p>a>span:nth-of-type(1)').text
up_time = i.find_element(By.CSS_SELECTOR, 'div p>a>span:nth-of-type(2)').text[1:]
play_num = i.find_element(By.CSS_SELECTOR, 'div span:nth-of-type(1)>span').text
comments_num = i.find_element(By.CSS_SELECTOR, 'div div~span').text
image_link = i.find_element(By.CSS_SELECTOR, 'div picture>img').get_attribute('src')
item = {
'标题': title,
'视频链接': link,
'up主': up_name,
'发布时间': up_time,
'播放量': play_num,
'评论量': comments_num,
'封面': image_link
}
print(item)
all_data.append(item)
except Exception as e:
print(f"抓取数据时出现错误: {e}")
# 获取完该页关键信息后,翻页
try:
next_page_locator = (By.CSS_SELECTOR, '.vui_pagenation--btns button:nth-last-child(1)')
base.base_click(next_page_locator)
time.sleep(3)
num += 1
print('翻页成功')
except:
break
return all_data
def save_excel(all_data, file_dir='../bibi_file', file_prefix='哔哩'):
if not os.path.exists(file_dir): # 如果没有找到文件夹,创建一个
os.makedirs(file_dir)
df = pd.DataFrame(all_data)
file_name = "{}{}.xlsx".format(file_prefix, time.strftime("%Y_%m_%d_%H_%M_%S"))
file_path = os.path.join(file_dir, file_name)
df.to_excel(file_path, index=False)
print(f"文件已成功保存到: {file_path}")
def main():
url = 'https://www.bilibili.com/'
keys = '软件测试'
driver = get_search(url, keys)
driver.implicitly_wait(10)
sort_options(driver)
all_data = get_data(driver)
save_excel(all_data)
driver.quit()
if __name__ == '__main__':
main()















 1160
1160











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









