






本任务需要使用 root 用户完成相关配置,安装 Hadoop需要配置前置环境。命令中要求使用绝对路径,具体要求如下:
(1)从 Master 中的/opt/software 目录下将文件hadoop-3.1.3.tar.gz、jdk-8u191-linux-x64.tar.gz 安装包解压到/opt/module 路径中(若路径不存在,则需新建),将 JDK 解压命令复制并粘贴至客户端桌面【M1-T1-SUBT1-提交结果 1.docx】中对应的任务序号下;
创建 /opt/module 目录(如果它不存在)
mkdir -p /opt/module

切换到 /opt/software 目录
cd /opt/software

解压 Hadoop 和 JDK 安装包到 /opt/module
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/

tar -zxvf jdk-8u191-linux-x64.tar.gz -C /opt/module/

(2)修改 Master 中/etc/profile 文件,设置 JDK 环境变量并使其生效,配置完毕后在 Master 节点分别执行“java-version”和“javac”命令,将命令行执行结果分别截图并粘贴至客户端桌面【M1-T1-SUBT1-提交结果 2.docx】中对应的任务序号下;
JDK 环境变量配置
export JAVA_HOME=/opt/module/jdk1.8.0_191
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar

然后,使环境变量生效:source /etc/profile

检查java和javac命令是否可用:
java -version
javac

(3)请完成 host 相关配置,将三个节点分别命名为master、slave1、slave2,并做免密登录,用 scp 命令并使用绝对路径从 Master 复制 JDK 解压后的安装文件到 slave1、slave2 节点(若路径不存在,则需新建),并配置 slave1、slave2 相关环境变量,将全部 scp 复制 JDK 的命令复制并粘贴至客户端桌面【M1-T1-SUBT1-提交结果 3.docx】中对应的任务序号下;
编辑 /etc/hosts 文件,添加以下内容:
10.0.0.80 master
10.0.0.175 slave1
10.0.0.192 slave2

scp -r /etc/hosts slave1:/etc/hosts
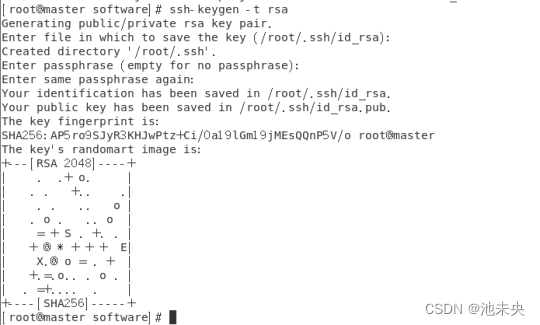
接下来,配置免密登录。在Master节点上生成密钥对,并将公钥复制到slave1和slave2节点:
在 Master 上生成密钥对
ssh-keygen -t rsa
将公钥复制到 slave1
ssh-copy-id slave1

将公钥复制到 slave2
ssh-copy-id slave2

使用scp命令复制 JDK 到slave1和slave2节点,并配置相应的环境变量。您需要在每个节点上编辑 /etc/profile 文件并设置 JDK 环境变量,然后执行 source /etc/profile 以使更改生效。
scp -r /etc/profile slave1:/etc/profile
scp -r /etc/profile slave2:/etc/profile

从 Master 复制 JDK 到 slave1
scp -r /opt/module/jdk1.8.0_191 slave1:/opt/module/
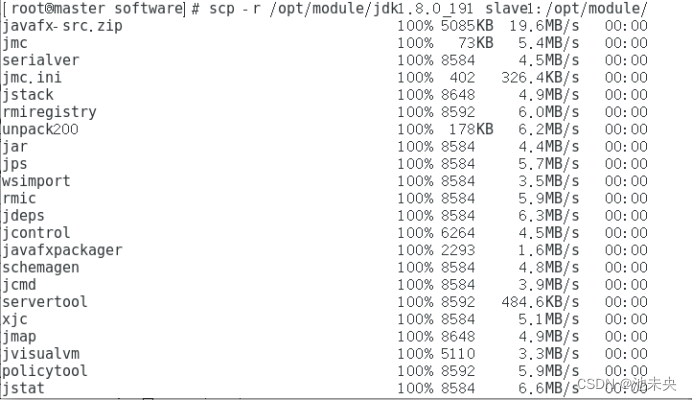
从 Master 复制 JDK 到 slave2
scp -r /opt/module/jdk1.8.0_191 slave2:/opt/module/

在slave1和slave2节点上执行 java -version 和 javac 命令,确保 JDK 正确安装和配置。
(4)在 Master 将 Hadoop 解压到/opt/module(若路径不存在,则需新建)目录下,并将解压包分发至 slave1、slave2 中,其中 master、slave1、slave2 节点均作为datanode,配置好相关环境,初始化 Hadoop 环境 namenode,将初始化命令及初始化结果截图(截取初始化结果日志最后20 行即可)粘贴至客户端桌面【M1-T1-SUBT1-提交结果4.docx】中对应的任务序号下;
hadoop的环境变量配置
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
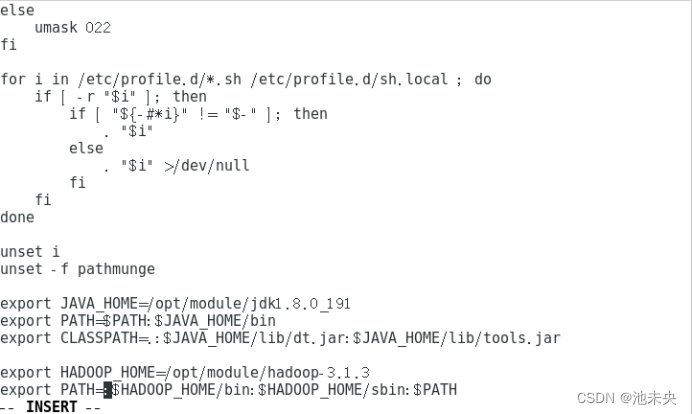
使环境变量生效:source /etc/profile

scp -r /etc/profile slave1:/etc/profile
scp -r /etc/profile slave2:/etc/profile

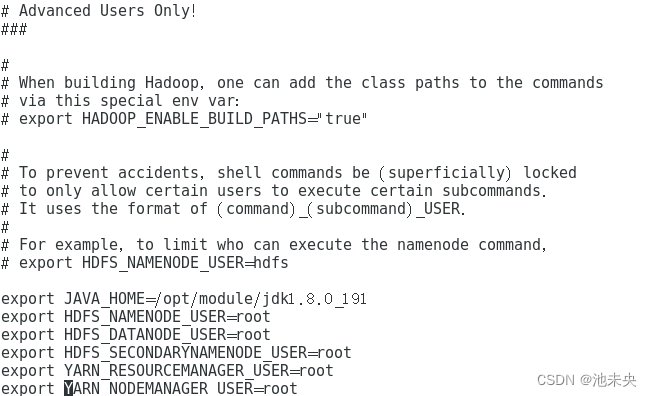
接下来,您需要在所有节点上配置Hadoop环境,编辑hadoop-env.sh文件以设置JAVA_HOME环境变量:cd /opt/module/hadoop-3.1.3/etc/hadoop/,编辑hadoop-env.sh:vi hadoop-env.sh。
export JAVA_HOME=/opt/module/jdk1.8.0_191
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
core-site.xml这个文件通常包含Hadoop集群的通用配置,例如文件系统(HDFS)的地址和Hadoop临时目录的位置。
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>

要配置所有节点作为DataNode,您需要在hdfs-site.xml文件中设置相应的配置。编辑这个文件以添加或修改以下属性:vi hdfs-site.xml
添加或修改以下内容:
<configuration>
<!-- 指定HDFS副本数量为3,因为您有3个节点 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- NameNode的web界面地址 -->
<property>
<name>dfs.namenode.http-address</name>
<value>master:9870</value>
</property>
<!-- NameNode的secondary地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9868</value>
</property>
<!-- DataNode的地址 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///opt/module/hadoop-3.1.3/data/dn</value>
</property>
</configuration>

mapred-site.xml这个文件包含MapReduce作业的配置,例如作业跟踪URL和JobHistory服务器的地址。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/lib/*</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>

yarn-site.xml这个文件包含YARN的配置,例如ResourceManager的地址、NodeManager的配置以及调度器等。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>

配置workers,命令为:vi workers
master
slave1
slave2

然后,将Hadoop目录复制到slave1和slave2节点:
scp -r /opt/module/hadoop-3.1.3 slave1:/opt/module/

scp -r /opt/module/hadoop-3.1.3 slave2:/opt/module/

使用命令hadoop version来验证我们的Hadoop环境是否安装成功,如下图,我们可以看到Hadoop的版本号以及其他信息,证明我们的Hadoop安装成功。

在Master节点上,执行以下命令来初始化NameNode:
hdfs namenode -format

这个命令会创建一个新的fsImage,这是HDFS文件系统的元数据快照,它会在NameNode启动时加载。
(5)启动 Hadoop 集群(包括 hdfs 和 yarn),使用 jps命令查看 Master 节点与 slave1 节点的 Java 进程,将 jps命令与结果截图粘贴至客户端桌面【M1-T1-SUBT1-提交结果5.docx】中对应的任务序号下。
使用以下命令启动 Hadoop 集群:
start-all.sh

使用 jps 命令查看 Java 进程:
jps
















 816
816











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









