






1.1.1 HDFS简介及概念
1、HDFS源于Google在2003年10月份发表的GFS(Google File System)论文,HDFS(Hadoop Distributed File System)是hadoop生态系统的一个重要组成部分,是hadoop中的的存储组件,在整个Hadoop中的地位非同一般,是最基础的一部分,因为它涉及到数据存储,MapReduce等计算模型都要依赖于存储在HDFS中的数据。HDFS是一个分布式文件系统,以流式数据访问模式存储超大文件,将数据分块存储到一个商业硬件集群内的不同机器上。
这里重点介绍其中涉及到的几个概念:
(1)超大文件:目前的hadoop集群能够存储几百TB甚至PB级的数据。
(2)流式数据访问:HDFS的访问模式是:一次写入,多次读取,更加关注的是读取整个数据集的整体时间。
(3)商用硬件:HDFS集群的设备不需要多么昂贵和特殊,只要是一些日常使用的普通硬件即可,正因为如此,hdfs节点故障的可能性还是很高的,所以必须要有机制来处理这种单点故障,保证数据的可靠。
(4)不支持低时间延迟的数据访问:hdfs关心的是高数据吞吐量,不适合那些要求低时间延迟数据访问的应用。
(5)单用户写入,不支持任意修改:hdfs的数据以读为主,只支持单个写入者,并且写操作总是以添加的形式在文末追加,不支持在任意位置进行修改。
2、NameNode(名称节点)
NameNode是HDFS集群的主服务器,通常称为名称节点或者主节点,一旦NameNode关闭,就无法访问Hadoop集群,NameNode主要以元数据的形式进行管理和储蓄,用于维护文件系统名称并管理客户端对文件的访问;NameNode记录对文件系统名称空间或其属性的任何更改操作;Hdfs负责整个数据集群的管理,并且在配置文件中可以设置备份数量,这些信息都有由NameNode存储。
3、DataNode(数据节点)
DataNode是HDFS集群中的从服务器,通常称为数据节点。文件系统存储文件的方式是将文件切分成多个数据块,这些数据块实际上是存储在DataNode节点中的,因此DataNode机器需要配置大量磁盘空间。它与NameNode保持不断的通信,DataNode在客户端或者NameNode的调度下,存储并检索数据块,对数据块进行创建、删除等操作,并且定期向NameNode发送所存储的数据块列表。
4、Metadata(元数据)
元数据从类型上分可分三种信息形式,一是维护HDFS文件系统中文件和目录的信息,例如文件名、目录名、父目录信息、文件大小、创建时间、修改时间等;二是记录文件内容存储相关信息,例如文件分块情况、副本个数、每个副本所在的DataNode信息等;三是用来记录HDFS中所有DataNode的信息,用于DataNode管理。
1.1.2 HDFS的特性
1.HDFS 中的文件在物理上是分块存储(block),块的大小可以通过配置参数(dfs.blocksize)来规定,默认大小在 hadoop2.x 版本中是 128M,老版本中是 64M
2.HDFS 文件系统会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件
3.namenode 是 HDFS 集群主节点,负责维护整个 hdfs 文件系统的目录树,以及每一个路径(文件)所对应的 block 块信息(block 的 id,及所在的 datanode 服务器)
4.datanode 是 HDFS 集群从节点,每一个 block 都可以在多个 datanode 上存储多个副本(副本数量也可以通过参数设置 dfs.replication,默认是 3)
5.HDFS 是设计成适应一次写入,多次读出的场景,且不支持文件的修改
1.1.3 HDFS的优缺点
优点:
1.可构建在廉价机器上,通过多副本提高可靠性,提供了容错和恢复机制
2.高容错性,数据自动保存多个副本,副本丢失后,自动恢复
3.适合批处理,移动计算而非数据,数据位置暴露给计算框架
4.适合大数据处理,GB、TB、甚至 PB 级数据
5.流式文件访问,一次性写入,多次读取,保证数据一致性
缺点:
1.低延迟数据访问,不适合于低延迟高吞吐
2.小文件存取,不适用与小文件存储,占用空间,寻道时间超过读取时间
3.不支持并发写入,和随机读取。HDFS同一时间只能有一个写入者,并且不 支持多次插入,只能追加
1.1.4 HDFS的架构
1、HDFS采用主从结构(Master/Slave架构)
2、HDFS集群是由一个NameNode或多个DataNode组成。
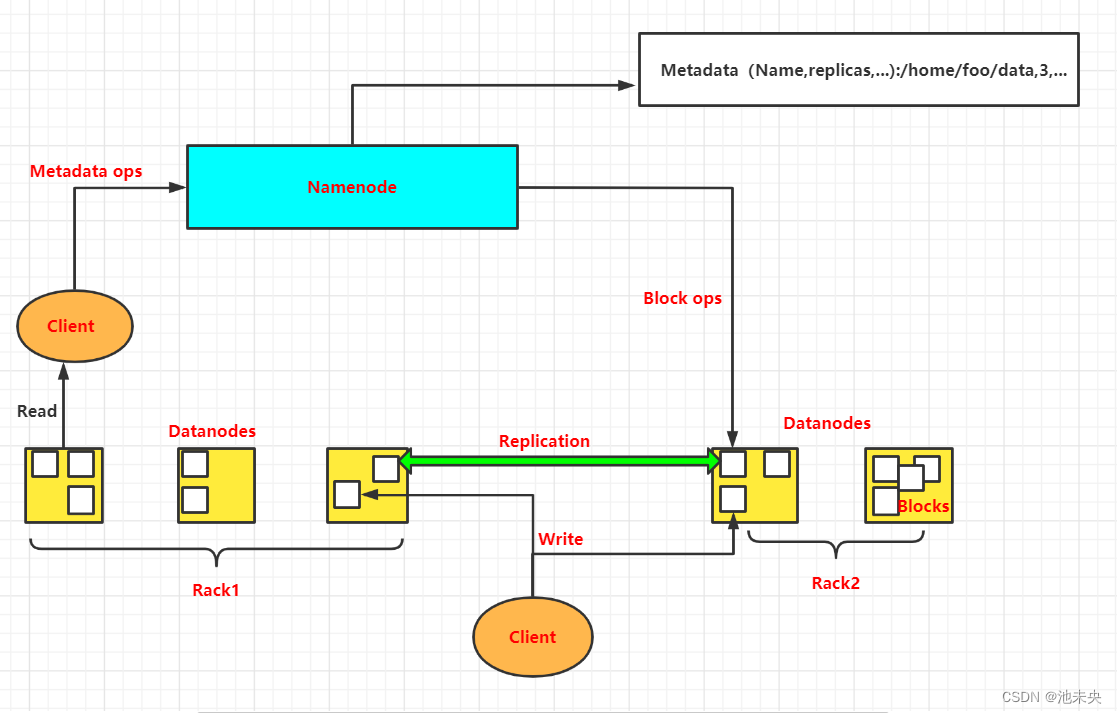
图1.1.1 HDFS的架构
1.1.5 HDFS文件的读取流程
客户端发起读取请求时,首先与 NameNode 进行连接。连接建立完成后,客户端会请求读取某个文件的某一个数据块。NameNode 在内存中进行检索,查看是否有对应的文件及文件块,若没有则通知客户端对应文件或数据块不存在,若有则通知客户端对应的数据块存在哪些服务器之上。客户端接收到信息之后,与对应的 DataNode 连接,并开始进行数据传输。客户端会选择离它最近的一个副本数据进行读操作。
读取文件的具体过程如下。
(1)客户端调用 DistributedFileSystem 的 Open() 方法打开文件。
(2)DistributedFileSystem 用 RPC 连接到 NameNode,请求获取文件的数据块的信息;NameNode 返回文件的部分或者全部数据块列表;对于每个数据块,NameNode 都会返回该数据块副本的 DataNode 地址;DistributedFileSystem 返回 FSDataInputStream 给客户端,用来读取数据。
(3)客户端调用 FSDataInputStream 的 Read() 方法开始读取数据。
(4)FSInputStream 连接保存此文件第一个数据块的最近的 DataNode,并以数据流的形式读取数据;客户端多次调用 Read(),直到到达数据块结束位置。
(5)FSInputStream连接保存此文件下一个数据块的最近的 DataNode,并读取数据。
(6)当客户端读取完所有数据块的数据后,调用 FSDataInputStream 的 Close() 方法。

图1.1.2 HDFS文件的读取流程
1.1.6 HDFS文件的写入流程
(1)客户端调用 DistribuedFileSystem 的 Create() 方法来创建文件。
(2)DistributedFileSystem 用 RPC 连接 NameNode,请求在文件系统的命名空间中创建一个新的文件;NameNode 首先确定文件原来不存在,并且客户端有创建文件的权限,然后创建新文件;DistributedFileSystem 返回 FSOutputStream 给客户端用于写数据。
(3)客户端调用 FSOutputStream 的 Write() 函数,向对应的文件写入数据。
(4)当客户端开始写入文件时,FSOutputStream 会将文件切分成多个分包(Packet),并写入其內部的数据队列。FSOutputStream 向 NameNode 申请用来保存文件和副本数据块的若干个 DataNode,这些 DataNode 形成一个数据流管道。队列中的分包被打包成数据包,发往数据流管道中的第一个 DataNode。第一个 DataNode 将数据包发送给第二个 DataNode,第二个 DataNode 将数据包发送到第三个 DataNode。这样,数据包会流经管道上的各个 DataNode。
(5)为了保证所有 DataNode 的数据都是准确的,接收到数据的 DataNode 要向发送者发送确认包(ACK Packet)。确认包沿着数据流管道反向而上,从数据流管道依次经过各个 DataNode,并最终发往客户端。当客户端收到应答时,它将对应的分包从内部队列中移除。
(7)不断执行第 (3)~(5)步,直到数据全部写完。
(8)调用 FSOutputStream 的 Close() 方法,将所有的数据块写入数据流管道中的数据结点,并等待确认返回成功。最后通过 NameNode 完成写入。
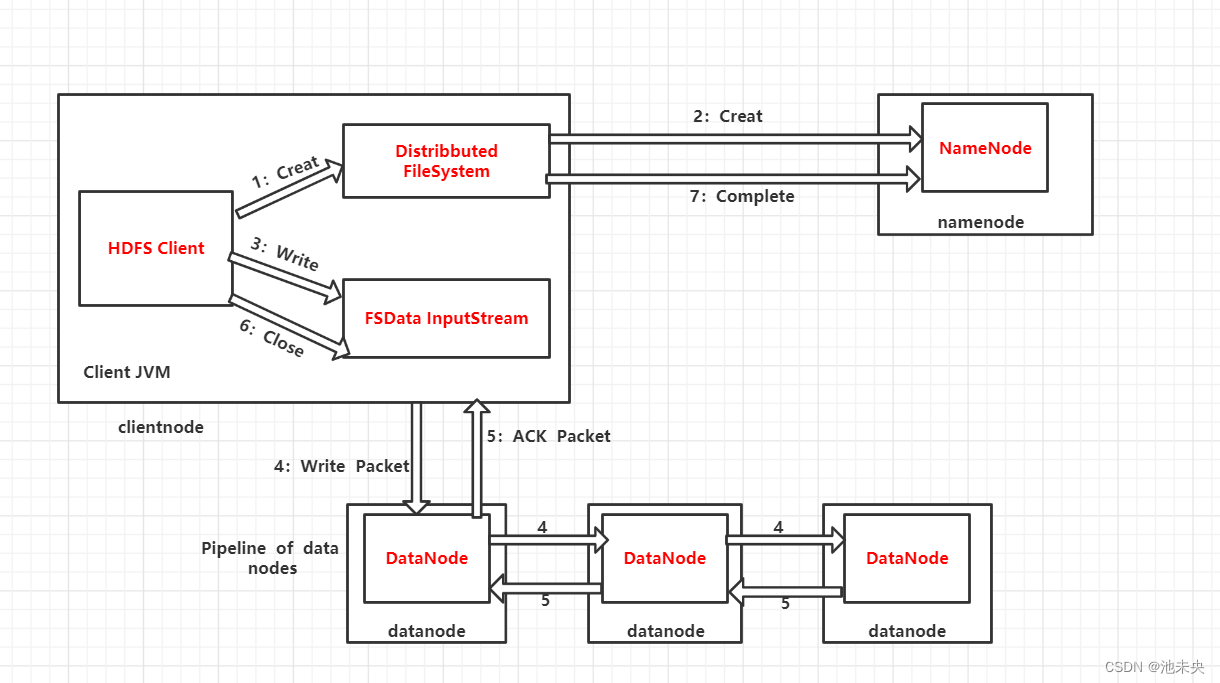
图1.1.3 HDFS文件的写入流程
1.1.7 HDFS的核心概念
关于HDFS有以下核心概念,理解这些概念对于更好地了解HDFS的原理有很大帮助。
1.数据块(block)
每个磁盘都有默认的数据块大小,这是磁盘进行数据读/写的最小单位。HDFS也有块的概念,在HDFS 1.x 中默认数据块大小为 64MB,在HDFS 2.x中默认数据块大小为128MB。
与单一磁盘上的文件系统相似,HDFS上的文件也被划分成块大小的多个分块(chunk),作为独立的存储单元。但与面向单一的文件磁盘系统不同的是,HDFS中小于一个块大小的文件不会占据整个块的空间(例如一个1MB的文件存储在一个128MB的块中时,文件只会使用1MB的磁盘空间,而不是128MB)。
2. NameNode
NameNode为HDFS集群的管理节点,一个集群通常只有一台活动的NameNode,它存放了HDFS的元数据且一个集群只有一份元数据。NameNode的主要功能是接受客户端的读写服务,NameNode保存的Metadata信息包括文件 ownership、文件的permissions,以及文件包括哪些Block、Block保存在哪个DataNode等信息。这些信息在启动后会加载到内存中。
3. DataNode
DataNode中文件的储存方式是按大小分成若干个Block,存储到不同的节点上,Block大小和副本数通过Client端上传文件时设置,文件上传成功后副本数可以变更,BlockSize不可变更。默认情况下每个Block都有3个副本。
4. SecondaryNameNode
SecondaryNameNode(简称SNN),它的主要工作是帮助NameNode合并edits,减少NameNode启动时间。SNN执行合并时机如下:
根据配置文件设置的时间间隔fs.checkpoint.period,默认3600秒。
根据配置文件设置edits log大小 fs.checkpoint.size,规定edits文件的最大值默认是64MB,如图下图所示。
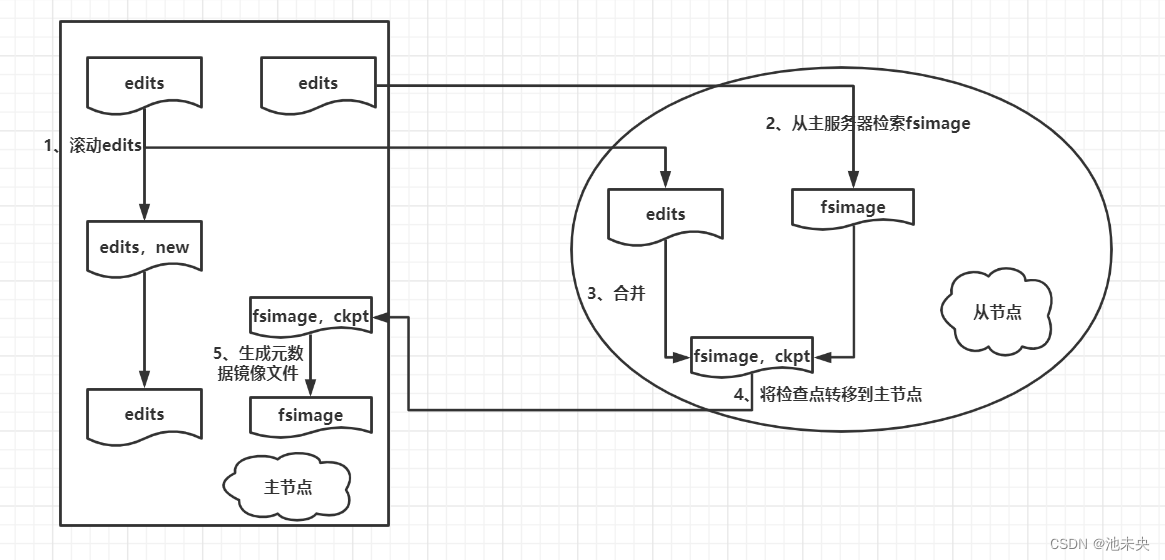
图1.1.4 配置文件设置
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









