







Python在数据科学中的作用
Python之所以能够成为大数据分析的主要工具,主要是因为他有很多现成的数据分析以及机器学习的工具包(Python中称为库),比如Numpy库、Pandas库、Scikit-Learn库等。这些库里写好了很多算法模型,我们在编程时可以直接调用;
Python环境部署
如果要学习Python这一编程语言,首先需要的是安装,建议直接安装Anaconda3,因为Anaconda3已经下载好了很多用于数据分析、机器学习的第三方库,不需要再去pip install package,而且在Anaconda3里面,我们还可以使用很多其他的IDE,比如Jupyter Notebook;
安装好Anaconda3之后一定要去配置环境变量,这一步非常重要但是却经常被忽视或者配置变量不完全,这一点可以去搜索需要配置哪些环境变量以及如何配置,如果这一步没有做好的话,在以后运行程序之时将会经常遇到错误,甚至没有办法开始;
Python使用常见问题
我们在Pycharm中新打开或者创建一个项目的时候,经常要看到最下面一排会出现未加载完全,显示<no interpreter>的现象,其实这是因为我们没有为当前窗口配置运行环境,这时候我们可以打开File->Other Settings->Python interpreter,进行添加我们anaconda3里面的python.exe文件,具体操作界面指示我放在下面,方便初次遇到问题的宝贝解决问题;
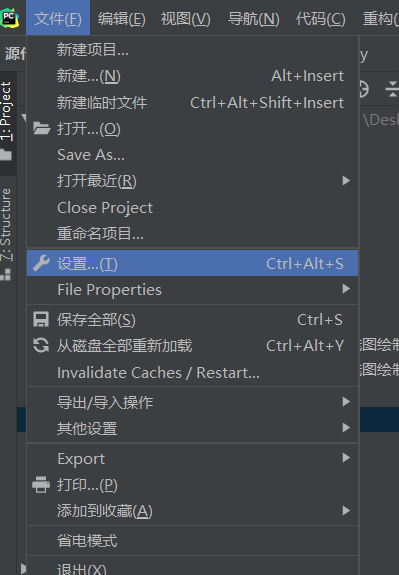
File->Settings
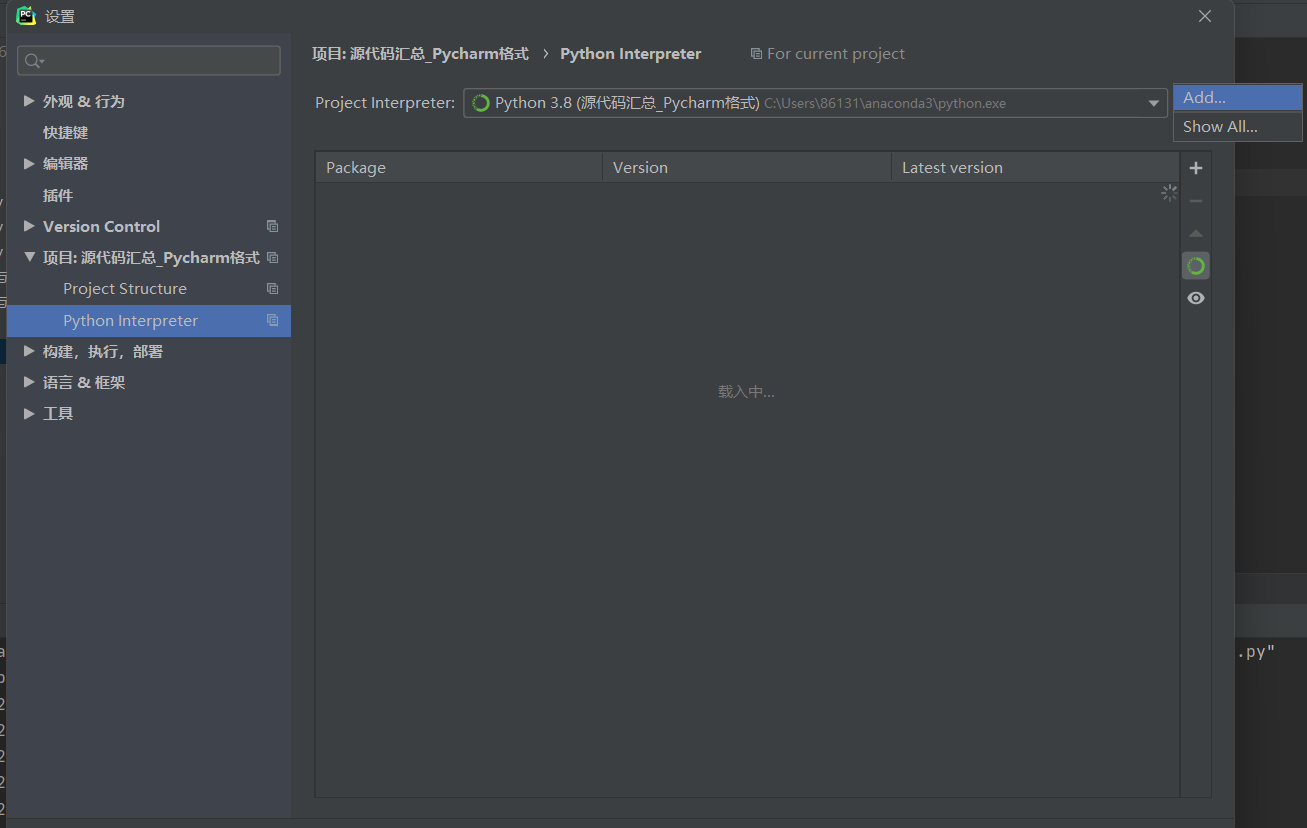
Python Interpreter->Add
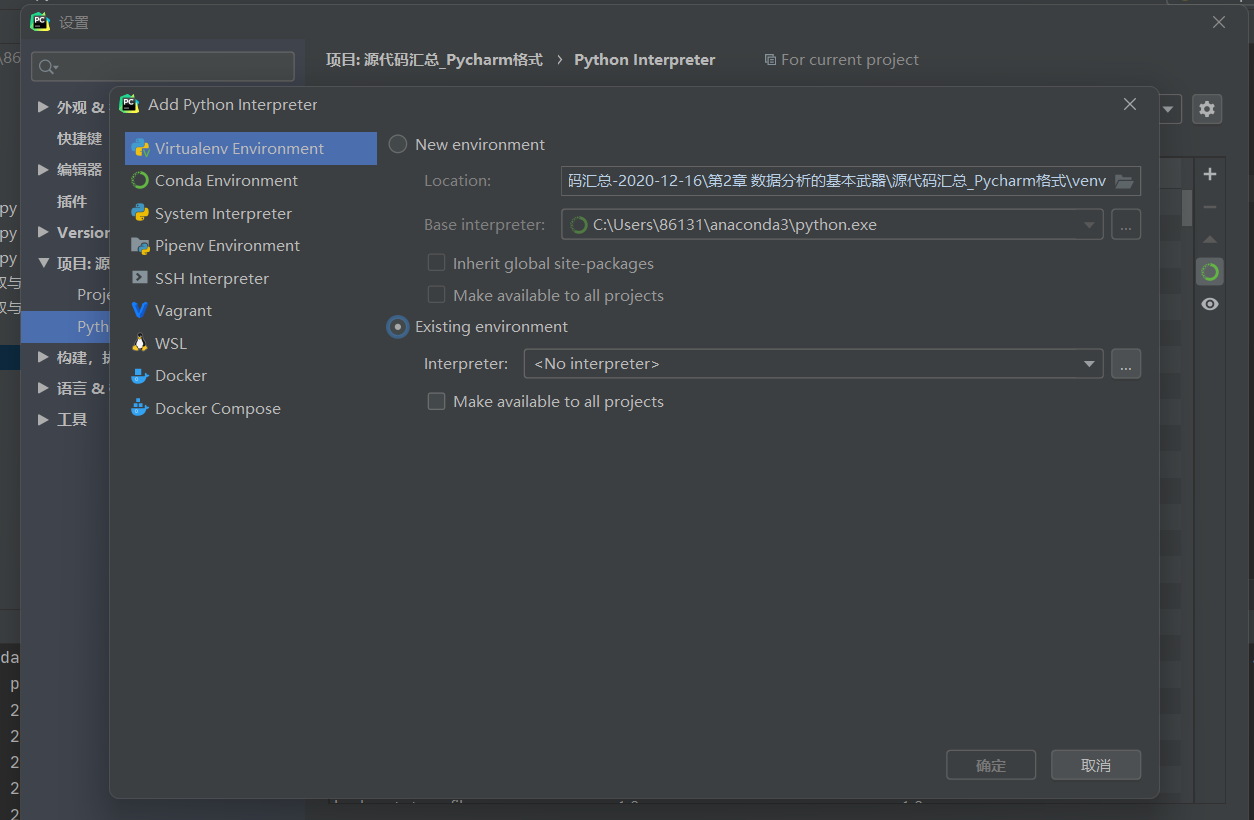
Virtual Environment->Existing environment
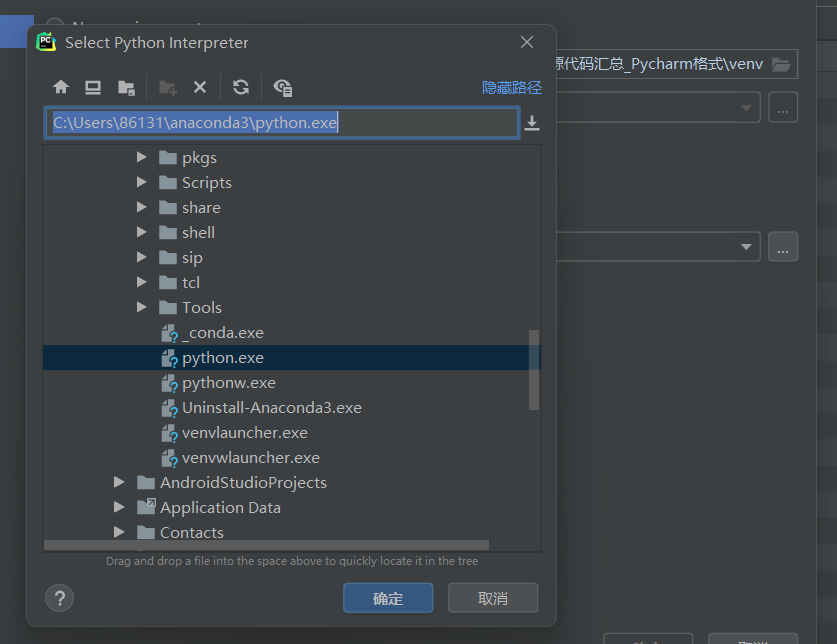
……->找到Anaconda3->选择Python.exe
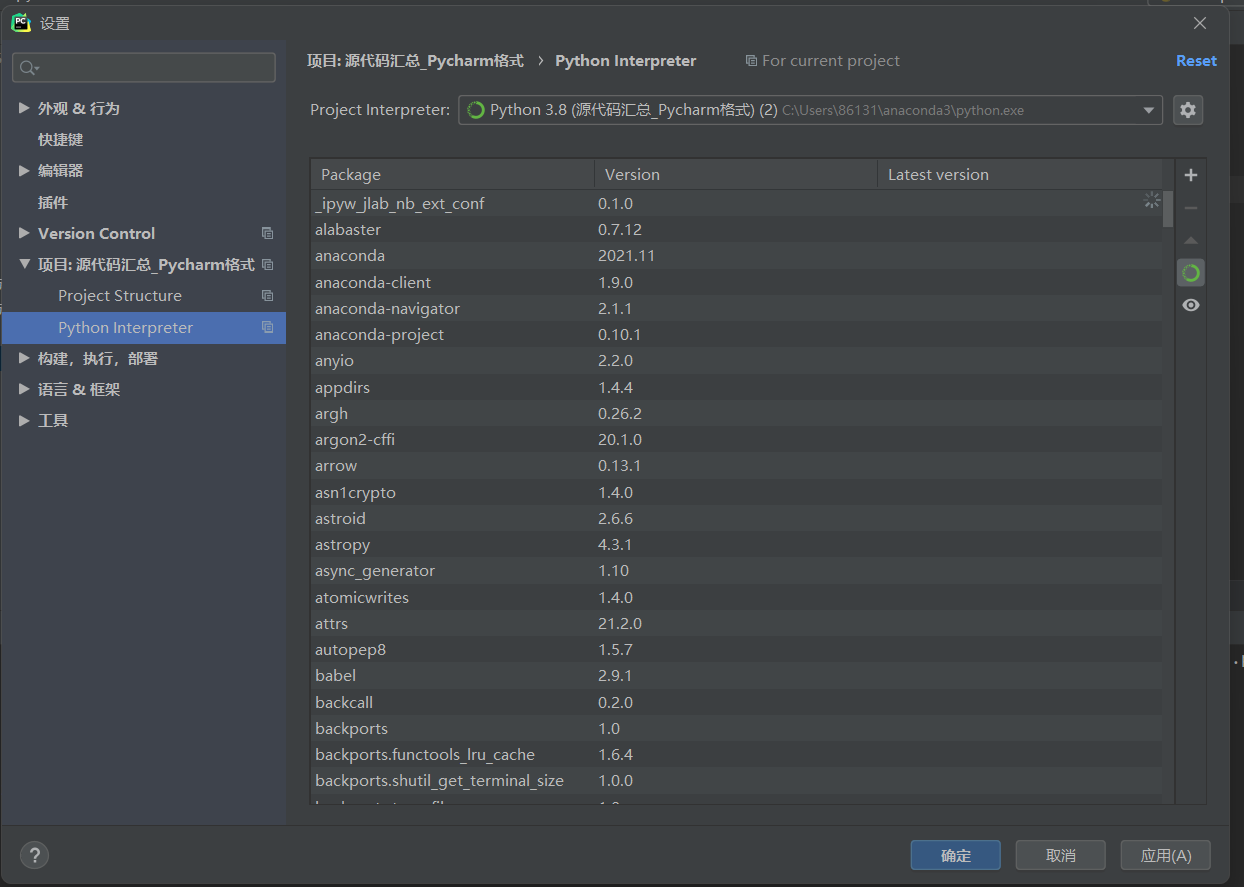
一直确定->应用->确定
Anaconda3会自带Jupyter Notebook进行编程,个人认为这个插件适合初学者使用,尤其是你还没学过Python基本语法结构的,因为他是一块一块执行代码,它与正常Pycharm创建的文件后缀名是不一样的,Jupyter Notebook创建的文件后缀为.ipynb,而正常python文件后缀为.py
Numpy基础
Numpy库的主要特点是引入了数组的概念,如果没学过Numpy也许你不知道Python也是可以有数组类型的数据的,这一点非常重要,因为这决定使用Python的Numpy库可以进行一些Matlab的矩阵运算功能,这也从另一个角度展示了Python作为编程语言的优越性;
利用Numpy创建数组
import numpy as np #import package as name可以起到一个简化库名的作用,方便后续引用
a=[1,2,3,4]
b=np.array([1,2,3,4])
print(a)
print(b)
print(type(a))
print(type(b))
print(a[1])
print(b[1])
print(a[0:2])
print(b[0:2])
c = a * 2
d = b * 2
print(c)
print(d)
e = [[1,2], [3,4], [5,6]]
f = np.array([[1,2], [3,4], [5,6]])
print(e)
print(f)利用以上代码可以清楚看到在Python中列表数据类型与数组数据类型的差异,主要可以概括为:列表类型各个元素之间用逗号作为分隔符,而数组类型各个元素之间以空格作为分隔符;列表无法数乘,而数组可以做到数乘;列表只能存储一维数据,而数组可以存储多维数据,而我们经常进行数据分析的数据结构经常就是二维表格的结构,所以数组这一数据类型非常重要;
下面再介绍几个创建数组的方式,也是要提前import numpy;具体函数如果不了解的话,可以搜索一下;
import numpy as np
b = np.array([1, 2, 3, 4])
f = np.array([[1,2], [3,4], [5,6]])
print(b)
print(f)
x = np.arange(5)
y = np.arange(5,10)
z = np.arange(5, 10, 0.5)
print(x)
print(y)
print(z)
a = np.random.randn(3)
print(a)
a = np.arange(12).reshape(3,4)
print(a)
a = np.random.randint(0, 10, (4, 4))
print(a)Pandas基础
Pandas主要是包含两个数据类型,一个是DataFrame类型,这是一个二维数组的类型,Pandas之所以作为数据分析利器很大原因是因为这样一个数据类型,因为我们在数据分析过程中是经常要用到二维表格的,还有一个数据类型是Series类型,它是一个一维数组的类型,但是他与Numpy中一维数组不一样的是Series类型是有索引的;
下面我的代码主要是通过不同的方式进行DataFrame数据类型的实例创建,包括通过列表进行创建、通过字典创建、通过二维数组创建;有一个需要注意的点,就是DataFrame()函数是可以通过index=[name1,name2,……],columns=[name11,name22,……]来自定义行索引和列索引的,然后默认索引是int类型,从零开始;具体可以通过仔细研究下方代码深入了解DataFrame数据类型;
import pandas as pd
s1 = pd.Series(['丁一', '王二', '张三'])
print(s1)
print(s1[1])
# **2.2.1 二维数据表格DataFrame的创建**
import pandas as pd
a = pd.DataFrame([[1, 2], [3, 4], [5, 6]])
print(a)
a = pd.DataFrame([[1, 2], [3, 4], [5, 6]], columns=['date', 'score'], index=['A', 'B', 'C'])
print(a)
a = pd.DataFrame()
date = [1, 3, 5]
score = [2, 4, 6]
a['date'] = date
a['score'] = score
print(a)
# (2) 通过字典创建DataFrame
b = pd.DataFrame({'a': [1, 3, 5], 'b': [2, 4, 6]}, index=['x', 'y', 'z'])
print(b)
c = pd.DataFrame.from_dict({'a': [1, 3, 5], 'b': [2, 4, 6]}, orient="index")
print(c)
# **补充知识点:通过.T来对表格进行转置**
b = pd.DataFrame({'a': [1, 3, 5], 'b': [2, 4, 6]})
print(b)
print(b.T)
# (3) 通过二维数组创建
import numpy as np
c=np.arange(12).reshape(3,4)
print(c)
import numpy as np
d = pd.DataFrame(np.arange(12).reshape(3,4), index=[1, 2, 3], columns=['A', 'B', 'C', 'D'])
print(d)
# **补充知识点:修改行索引或列索引名称**
a = pd.DataFrame([[1, 2], [3, 4]], columns=['date', 'score'], index=['A', 'B'])
print(a)
a = a.rename(index={'A':'阿里', 'B':'腾讯'}, columns={'date':'日期','score':'分数'})
print(a)
# 补充知识点:这里通过rename之后并没有改变原表格结构,需要重新赋值给a才能改变原表格;或者在rename()中设置inplace参数为True,也能实现真正替换,代码如下:
a = pd.DataFrame([[1, 2], [3, 4]], columns=['date', 'score'], index=['A', 'B'])
#a = a.rename(index={'A':'阿里', 'B':'腾讯'}, columns={'date':'日期','score':'分数'})
a.rename(index={'A':'阿里', 'B':'腾讯'}, columns={'date':'日期','score':'分数'}, inplace=True) # 另一种方法
print(a)
print(a.index.values)
a.index.name = '公司'
print(a)
a = a.set_index('日期')
print(a)
a = a.reset_index()
print(a)利用Pandas可以进行文件的读取与写入,这一功能有从另一个角度说明pandas的重要性;通常我们利用Pandas的read_excel()函数和read_csv()函数进行读取Excel文件和csv文件,其实刚开始遇到csv文件格式也是有点懵的,其实csv不是一种特定的文件格式,它是一种通用文件格式,是一种纯文本形式,分隔符默认为逗号,并且相同数据用csv文件格式存储可以减小文件大小;Excel文件现在通常我们看到的后缀为.xlsx,其实是因为2003年之后Excel进行一个升级,所以文件后缀名也相应更改,包括我们经常看到.docx作为word文件的后缀名格式;在进行文件的读取操作时,还需要注意一个点,你所传入的文件路径,文件路径作为参数传入函数时我们需要区别绝对路径和相对路径;
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
data = pd.read_excel('data.xlsx') # data为DataFrame结构
print(data.head())
#data.head()函数只是进行数据选择,并不能实现打印
# 其中read_excel还可以设定参数,使用方式如下:
data = pd.read_excel('data.xlsx', sheet_name=0)
#read_excel()函数中参数sheet_name是用来设置读取Excel表的哪一个工作表,可以通过数字设置,默认从零开始,也可以直接设置工作表的名称;参数encoding是来设置编码格式的,通常我们设置为utf-8或者gbk,是为了防止中文乱码的
data = pd.read_csv('data.csv')
data.head()
# read_csv也可以指定参数,使用方式如下:
data = pd.read_csv('data.csv', delimiter=',', encoding='utf-8')
#read_csv()函数的参数delimiter是用来设置csv文件中的分隔符的,默认为逗号
# (2) 文件写入
data = pd.DataFrame([[1, 2], [3, 4], [5, 6]], columns=['A列','B列'])
data.to_excel('data_new.xlsx')
data.to_excel('data_new.xlsx', sheet_name='Selina真好看', index=None, columns=['A列','B列'])
#to_excel()函数是用来把数据写入excel文件里面的,参数index是控制dataframe结构的数据的行索引是否写入Excel中的,默认是将行索引写入Excel中去的,但是可以设置为None取消行索引作为第一列;参数columns可以设置需要写入哪些列;参数sheet_name是用来设置工作表名称的,必须是字符串类型的,
data.to_csv('data_new.csv')
#如果写入csv文件出现中文乱码的现象,则需要更改encoding为utf_8_sig
data.to_csv('演示.csv', index=False, encoding="utf_8_sig")
# **补充知识点:文件相对路径与绝对路径**
data.to_excel('data.xlsx') # 绝对路径推荐写法1,此时E盘要有一个名为“大数据分析”的文件夹3.以下是进行数据获取的一些函数,其实我也记不全,但是我把它放在这里就可以随时查阅;其实通过这段代码对于数据进行一些排序、有条件获取的操作可以感受到Python数据处理能力的强大,因为之前确实从事过一段时间的利用Excel进行数据清洗的工作,非常重复繁琐无意义,要是早点会Python就好了;
import pandas as pd
data = pd.DataFrame([[1, 2, 3], [4, 5, 6], [7, 8, 9]], index=['r1', 'r2', 'r3'], columns=['c1', 'c2', 'c3'])
print(data)
# 1.按照行列进行数据筛选
# (1) 按照列来选取数据
a = data['c1']
print(a)
b = data[['c1']]
print(b)
c = data[['c1', 'c3']]
print(c)
# (2) 按照行来选取数据
a = data[1:3]
print(a)
b = data.iloc[1:3]
print(b)
c = data.iloc[-1]
print(c)
d = data.loc[['r2', 'r3']]
print(d)
e = data.head()
print(e)
# (3) 按照区块来选取
a = data[['c1', 'c3']][0:2] # 也可写成data[0:2][['c1', 'c3']]
print(a)
b = data.iloc[0:2][['c1', 'c3']]
print(b)
c = data.iloc[0]['c3']
print(c)
d = data.loc[['r1', 'r2'], ['c1', 'c3']]
e = data.iloc[0:2, [0, 2]]
print(d)
print(e)
f = data.ix[0:2, ['c1', 'c3']]
print(f)
a = data[data['c1'] > 1]
print(a)
b = data[(data['c1'] > 1) & (data['c2'] < 8)]
print(b)
# 3.数据整体情况查看
print(data.shape)
print(data.describe())
print(data['c1'].value_counts())
# 4.数据运算、排序与删除
# (1) 数据运算
data['c4'] = data['c3'] - data['c1']
print(data.head())
# (2) 数据排序
a = data.sort_values(by='c2', ascending=False)
print(a)
a = data.sort_values('c2', ascending=False)
print(a)
a = a.sort_index()
print(a)
# (3) 数据删除
a = data.drop(columns='c1')
print(a)
b = data.drop(columns=['c1', 'c3'])
print(b)
c = data.drop(index=['r1','r3'])
print(c)
data.drop(index=['r1','r3'], inplace=True)
print(data)
下面的代码主要是实现数据表的拼接,主要包括merge()、concat()、join()以及append()函数,具体的参数和实现效果如下:
import pandas as pd
df1 = pd.DataFrame({'公司': ['万科', '阿里', '百度'], '分数': [90, 95, 85]})
df2 = pd.DataFrame({'公司': ['万科', '阿里', '京东'], '股价': [20, 180, 30]})
print(df1)
print(df2)
# 公司 分数
# 0 万科 90
# 1 阿里 95
# 2 百度 85
# 公司 股价
# 0 万科 20
# 1 阿里 180
# 2 京东 30
# (1) merge()函数
df3 = pd.merge(df1, df2)
print(df3)
# 公司 分数 股价
# 0 万科 90 20
# 1 阿里 95 180
df3 = pd.merge(df1, df2, how='outer')
print(df3)
# 公司 分数 股价
# 0 万科 90.0 20.0
# 1 阿里 95.0 180.0
# 2 百度 85.0 NaN
# 3 京东 NaN 30.0
df3 = pd.merge(df1, df2, how='left')
print(df3)
# 公司 分数 股价
# 0 万科 90 20.0
# 1 阿里 95 180.0
# 2 百度 85 NaN
df3 = pd.merge(df1, df2, left_index=True, right_index=True)
print(df3)
# 公司_x 分数 公司_y 股价
# 0 万科 90 万科 20
# 1 阿里 95 阿里 180
# 2 百度 85 京东 30
# **补充知识点:根据行索引合并的join()函数**
df3 = df1.join(df2, lsuffix='_x', rsuffix='_y')
print(df3)
# 公司_x 分数 公司_y 股价
# 0 万科 90 万科 20
# 1 阿里 95 阿里 180
# 2 百度 85 京东 30
# (2) concat()函数
df3 = pd.concat([df1,df2], axis=0)
print(df3)
# 公司 分数 股价
# 0 万科 90.0 NaN
# 1 阿里 95.0 NaN
# 2 百度 85.0 NaN
# 0 万科 NaN 20.0
# 1 阿里 NaN 180.0
# 2 京东 NaN 30.0
df3 = pd.concat([df1,df2],axis=1)
print(df3)
# 公司 分数 公司 股价
# 0 万科 90 万科 20
# 1 阿里 95 阿里 180
# 2 百度 85 京东 30
# (3) append()函数
df3 = df1.append(df2)
print(df3)
# 公司 分数 股价
# 0 万科 90.0 NaN
# 1 阿里 95.0 NaN
# 2 百度 85.0 NaN
# 0 万科 NaN 20.0
# 1 阿里 NaN 180.0
# 2 京东 NaN 30.0
df3 = df1.append({'公司': '腾讯', '分数': '90'}, ignore_index=True)
print(df3)
# 公司 分数
# 0 万科 90
# 1 阿里 95
# 2 百度 85
# 3 腾讯 90Matplotlib库基础
这一部分主要适用利用Python进行数据可视化,其实数据可视化对于一些行业是比较重要的,比如Data Analysis或者Data Marketing,在与一些品牌方客户进行数据分析的结果展示之时,数据可视化是一项非常重要的技术指标,因为你的目的已经摆在那里了,你是需要让一个没有参与过数据分析过程甚至对于你数据分析的逻辑完全不了解的人听懂看懂你的结论;然后利用Python的Matplotlib库可以实现柱状图、饼图、散点图、折线图的绘制等,大致构图思路都是先利用numpy进行一个数组的创建,然后再进行函数表达式的定义,再进行一个画图的命令,这个过程就包括设置图线的像素、颜色、虚线还是实线、添加图例、双坐标轴等等,需要记忆的参数也是比较多的,但是其实没有必要记,还是需要使用的时候过来查一下资料就可以,然后经常使用的话一定会熟练;具体效果放在Pycharm里面跑一下就知道了;有一个问题是如果电脑里安装多个python,那么你的画图功能会出现紊乱,就是运行的时候你可能发现明明已经可以画图了但是却没有显示,这个时候只要再结尾加一句plt.show()就可以了;
# # 2.3 Matplotlib数据可视化基础
# **2.3.1 基本图形绘制**
#(1) 折线图
import matplotlib.pyplot as plt
x = [1, 2, 3]
y = [2, 4, 6]
plt.plot(x, y)
import pylab as pl
pl.xticks(rotation=45)
plt.show()
#
import numpy as np
import matplotlib.pyplot as plt
x1 = np.array([1, 2, 3])
# # 第一条线:y = x + 1
y1 = x1 + 1
plt.plot(x1, y1)
# # 第二条线:y = x*2
y2 = x1*2
plt.plot(x1, y2, color='red', linewidth=3, linestyle='--')
plt.show()
# # (2) 柱状图
import matplotlib.pyplot as plt
x = [1, 2, 3, 4, 5]
y = [5, 4, 3, 2, 1]
plt.bar(x, y)
plt.show()
# (3) 散点图
import matplotlib.pyplot as plt
import numpy as np
x = np.random.rand(10)
y = np.random.rand(10)
plt.scatter(x, y)
plt.show()
(4) 直方图
import matplotlib.pyplot as plt
import numpy as np
data = np.random.randn(10000)
plt.hist(data, bins=40, edgecolor='black')
plt.show()
# # **补充知识点:在pandas库中的快捷绘图技巧**
import pandas as pd
df = pd.DataFrame(data)
df.hist(bins=40, edgecolor='black')
df.plot(kind='hist')
import pandas as pd
df = pd.DataFrame([[8000, 6000], [7000, 5000], [6500, 4000]], columns=['人均收入', '人均支出'], index=['北京', '上海', '广州'])
print(df)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
df['人均收入'].plot(kind='line')
df['人均收入'].plot(kind='bar')
plt.show()# (1) 添加文字说明
import matplotlib.pyplot as plt
x = [1, 2, 3]
y = [2, 4, 6]
plt.plot(x, y)
plt.title('TITLE')
plt.xlabel('X')
plt.ylabel('Y')
plt.show()
# (2) 添加图例
import numpy as np
import matplotlib.pyplot as plt
# 第一条线, 设定标签lable为y = x + 1
x1 = np.array([1, 2, 3])
y1 = x1 + 1
plt.plot(x1, y1, label='y = x + 1')
# 第二条线, 设定标签lable为y = x*2
y2 = x1*2
plt.plot(x1, y2, color='red', linestyle='--', label='y = x*2')
plt.legend(loc='upper left')
plt.show()
# (3) 设置双坐标轴
import numpy as np
import matplotlib.pyplot as plt
# 第一条线, 设定标签lable为y = x
x1 = np.array([10, 20, 30])
y1 = x1
plt.plot(x1, y1, color='red', linestyle='--', label='y = x')
plt.legend(loc='upper left')
plt.twinx()#这个用来设置双坐标轴
# 第二条线, 设定标签lable为y = x^2
y2 = x1*x1
plt.plot(x1, y2, label='y = x^2')
plt.legend(loc='upper right')#这个可以用来调整图例的位置
plt.show()
# (4) 设置图片大小
plt.rcParams['figure.figsize'] = (8, 6)
x = [1, 2, 3]
y = [2, 4, 6]
plt.plot(x, y)
plt.show()
# (4) 设置X轴角度,这个设置x角度我也没搞清楚到底干嘛用,解释说是为了防止x轴刻度太密导致看不清楚,所以可以适当调整x轴角度来让图表刻度更清楚;
import matplotlib.pyplot as plt
x = [1, 2, 3]
y = [2, 4, 6]
plt.plot(x, y)
import pylab as pl
pl.xticks(rotation=0)
plt.show()有一个问题就是使用Matplotlib画图时总是会出现重复的现象,然后就找不到你现在运行的程序,看到一个说法是Matplotlib画图进行for循环之前的图片也是会保存的,所以需要加一个plt.clf(),但是我用了不咋好用,如果有知道的也可以告诉我!感恩!















 395
395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









