







1、 创建一个值为1,3,5,7,9的整型数据类型的Series对象,其索引下标为0,1,2,3,4,请输出该Series对象的数据类型、维度形状大小、以及值的总和。
import pandas as pd
yi = pd.Series([0, 1, 2, 3, 4])
print(yi)
print(yi.ndim)
print(yi.shape)
print(sum(yi))
2、请使用键盘输入的方式对以下数据生成Series对象(字典创建Series),其中第一列为索引名字,第二列为值,并打印该对象的数据类型、维度形状大小以及值的平均值。
import pandas as pd
er=pd.Series({'a':1,'b':2,'c':3,'d':4,'a':5,})
print(er)
print(type(er))
print(er.ndim)
print(er.shape)
print(sum(er))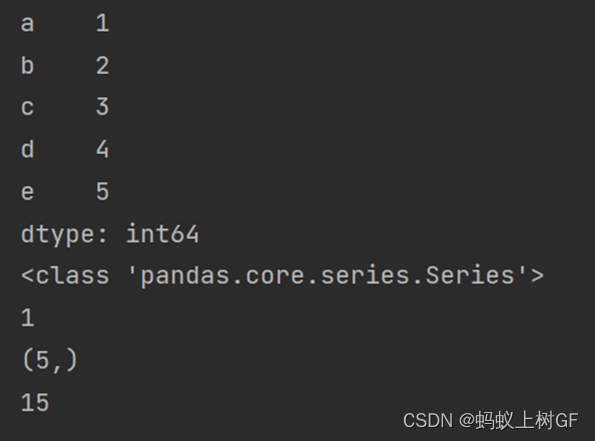
3、使用numpy创建5个1-10范围内的随机值序列,并转为Series类型,索引值为a,b,c,d,e。完成以下问题:
(1)访问第一个元素的两种方式
(2)访问前两行数据的两种方式
(3)访问第一行和最后行的两种方式
(4)求出随机值中小于5的子序列。
import numpy as np
import pandas as pd
pd.Series(np.random.randint(1,11,size=5,),index=['a','b','c','d','e'])
print(san)
print(san['a'])
print(san[0])
print("------")
print(san[['a','b']])
print(san[0:2])
print("------")
print(san['e'])
print(san[-1])
print(“------“)
print(san[san<5])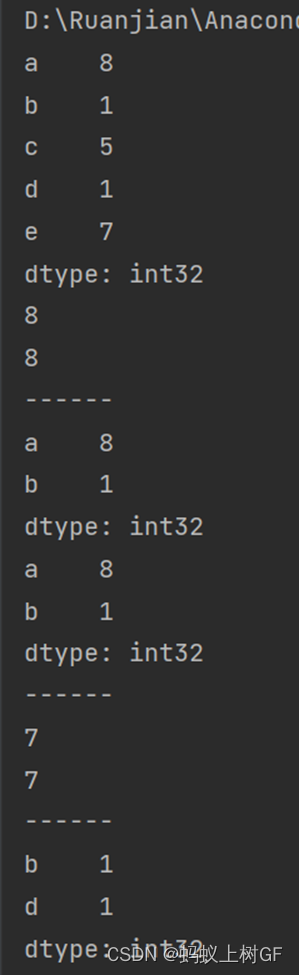
4、创建一个形状为6x4的DataFrame对象,其中当前日期的等差序列作为索引(如当前日期为:2022-11-03),值为6行4列的正态分布数组,列名为‘A’,’B’,’C’,’D’。 完成下列问题:
提示:创建等差时间序列:pandas.date_range(),创建二维正态分布数组:numpy.random.randn()
比如:
import pandas as pd
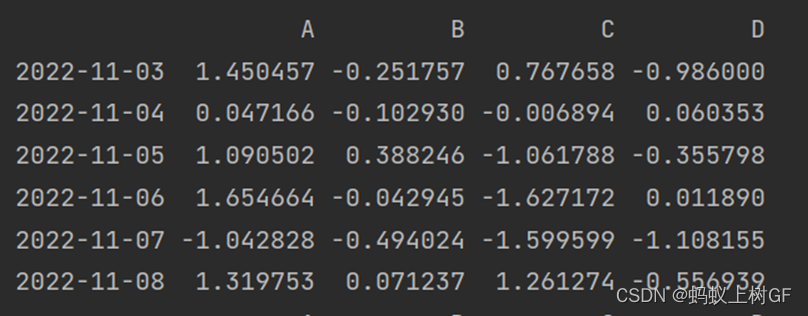
si = pd.DataFrame(np.random.randn(6,4), index=pd.date_range(start="2022/11/3",period=6),columns=list('ABCD'))
print(si)
#loc方法是针对DataFrame索引名称的切片方法
#DataFrame.loc[行索引名称或条件, 列索引名称]
print(si.loc['2022-11-03':'2022-11-05'])
#iloc和loc区别是iloc接收的必须是行索引和列索引的位置
#DataFrame.iloc[行索引位置, 列索引位置]
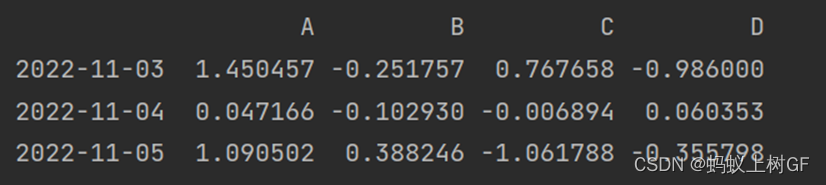
print(si.iloc[0:3])
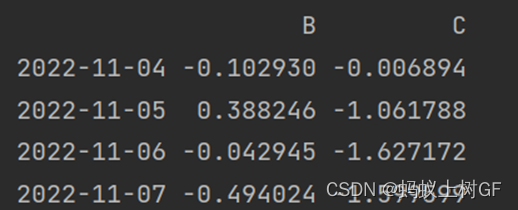
print(si.loc[['2022-11-04','2022-11-05','2022-11-06','2022-11-07'],['B','C']])
print(si.iloc[1:5,1:3])(1) 打印出你所创建的DataFrame对象。
(2) 分别使用DataFrame的iloc()和loc()方法获取前三行的数据。
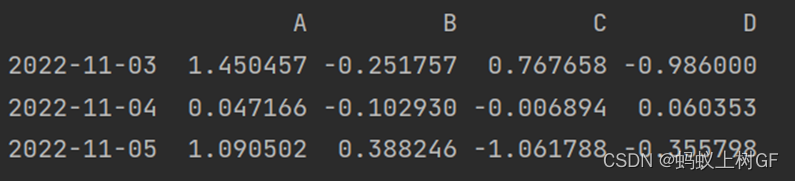
(3) 分别使用DataFrame的iloc()和loc()方法获取第二行第二列到第五行第三列的数据。

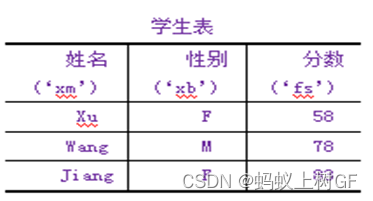
5、将以下二维数据表创建为DataFrame对象,其中列名为“姓名”,“性别”,“分数”,索引名为’a’,’b’,’c’。其次对三行三列的数据值进行格式化打印,并对分数大于60分的所有行进行打印,再对c行的性别列改为“M”并打印性别为M的行,最后求出三条数据分数列的平均分。
三行三列的数据遍历的格式要求:

Import pandas ad pd
wu = pd.DataFrame({'xm': ['xu', 'wang', 'jiang'], 'xb': ['F', 'M', 'F'], 'fs': [58, 78, 83]}, index=['a', 'b', 'c'])
print(wu)
print(wu[wu['fs'] > 60])
wu.loc['c','xb']='M'
print(wu)
6、使用以下字典数据创建一个DataFrame对象,其索引值为'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j'。请完成以下要去的操作。
字典数据为:{'animal': ['cat', 'cat', 'snake', 'dog', 'dog', 'cat', 'snake', 'cat', 'dog', 'dog'], 'age': [2.5, 3, 0.5, np.nan, 5, 2, 4.5, np.nan, 7, 3],'visits': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],'priority': ['yes', 'yes', 'no', 'yes', 'no', 'no', 'no', 'yes', 'no', 'no']}
Import pandas ad pd
wu = pd.DataFrame({'xm': ['xu', 'wang', 'jiang'], 'xb': ['F', 'M', 'F'], 'fs': [58, 78, 83]}, index=['a', 'b', 'c'])
print(wu)
print(wu[wu['fs'] > 60])
wu.loc['c','xb']='M'
print(wu)(1) 请取出该DataFrame对象中的animal和age列
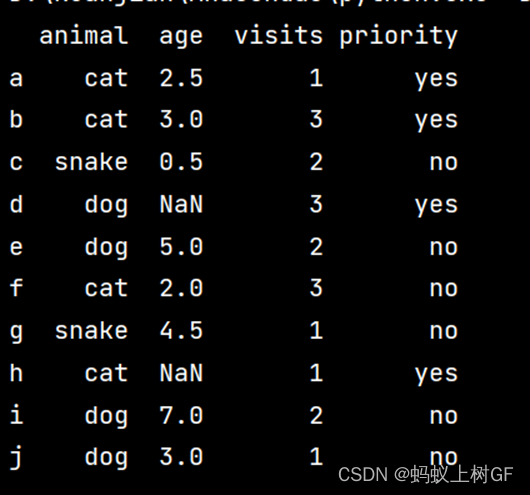
(2) 取出索引为[3, 4, 8]行的animal和age列
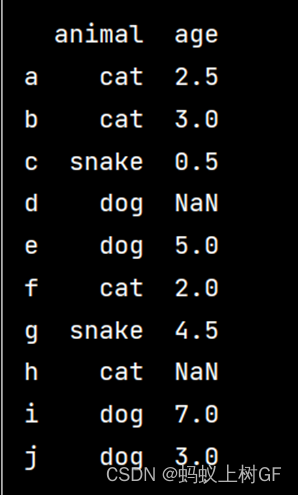
(3)取出age值大于3的行
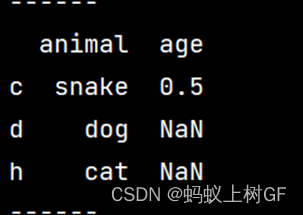
(4)取出age值缺失的行
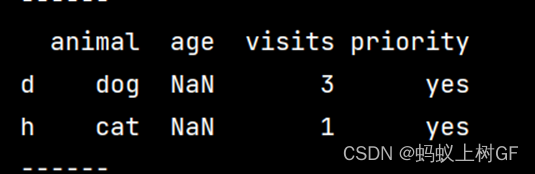
(5)统计数据中有缺失值的行数

(6)将f行的age改为1.5

(7)计算visits的总和

(8)在df中插入新行k,然后删除该行
#插入
df.loc['k'] = [5.5, 'dog', 'no', 2]
# 删除
df = df.drop('k')
请指正
















 2883
2883











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









