






一、什么是Hadoop
Hadoop 是一个开源的 分布式计算框架,用于高效存储和处理 海量数据(TB/PB级)。它最初由 Apache 开发,灵感来自 Google 的 MapReduce 和 Google File System (GFS) 论文,旨在解决传统数据库无法处理的大规模数据问题。
二、Hadoop 的核心内容
| 组件 | 作用 |
|---|---|
| HDFS (Hadoop Distributed File System) | 分布式文件系统,负责 海量数据的存储。 |
| YARN (Yet Another Resource Negotiator) | 集群 资源管理和任务调度 框架,管理计算资源(CPU、内存)。 |
| MapReduce | 分布式计算模型,用于 并行处理大数据。 |
| Hadoop Common | 提供基础库和工具,支持其他模块运行。 |
三、HDFS 的核心内容
1、核心架构(主从模式)
| 组件 | 角色 |
|---|---|
| NameNode | 主节点,管理文件系统的 元数据(文件名、目录结构、数据块位置等)。 |
| DataNode | 从节点,存储 实际数据块,并定期向 NameNode 汇报状态。 |
| Secondary NameNode | 辅助 NameNode,定期合并元数据镜像和编辑日志(非热备)。 |
四、HDFS集群搭建
1、三台主机网络配置:
| 主机名 | IP |
| host181 | 192.168.1.181/24 |
| host182 | 192.168.1.182/24 |
| host183 | 192.168.1.183/24 |
2、关闭三台主机的防火墙
(三台都配置)
# 三台主机都执行以下命令关闭防火墙
su - root
systemctl stop firewalld
systemctl disable firewalld
# 查看防火墙状态
systemctl status firewalld3、永久关闭selinux
(三台都配置)
# 三台主机都执行以下命令永久关闭selinux(需要重启)
su - root
vi /etc/selinux/config
# 修改为如下内容
########
SELINUX=disabled
########
# 重启服务器
reboot
# 验证,输出应为 Disabled。
getenforce
4、配置主机名称和主机 hosts文件
主机名称配置(三台都配置)
su - root
hostnamectl set-hostname 新主机名
hosts文件配置(三台都配置)
su - root
vi /etc/hosts
# hosts文件末尾加入如下配置
####################
192.168.1.181 host181
192.168.1.182 host182
192.168.1.183 host183
####################5、创建hadoop账户
(三台主机都操作)
最好用专用的账户,避免以 root 用户启动
su - root
# 创建账户
useradd hadoop
# 配置密码
passwd hadoop6、检查主机间的网络通信
ping host181
ping host182
ping host183
ping www.baidu.com
7、配置三台主机之间hadoop账户的互信
三台主机都操作:
su - hadoop
# 生成密钥
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa仅host181主机操作:
su - hadoop
# 创建authorized_keys文件
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
ssh hadoop@host182 "cat ~/.ssh/id_rsa.pub" >> ~/.ssh/authorized_keys
ssh hadoop@host183 "cat ~/.ssh/id_rsa.pub" >> ~/.ssh/authorized_keys
# 分发authorized_keys文件
scp ~/.ssh/authorized_keys hadoop@host182:~/.ssh/
scp ~/.ssh/authorized_keys hadoop@host183:~/.ssh/
三台主机都操作
su - hadoop
# 设置正确权限
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys验证:(三台主机都操作)
# 如果都不用密码就能登录,即互信成功
su - hadoop
ssh hadoop@host181
ssh hadoop@host182
ssh hadoop@host183
8、jdk的安装
JDK1.8(三台都安装)
su - root
# 进入软件包所在目录
cd tool
# 解压软件包
tar -zxvf jdk-8u391-linux-x64.tar.gz
# 更改名称并移动位置
mv jdk1.8.0_391 /usr/local/jdk1.8
# 配置环境变量
vi /etc/profile
# /etc/profile文件末尾加入如下内容
#################
export JAVA_HOME=/usr/local/jdk1.8 # 这里设置解压的Java目录文件
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib
#################
# 使配置立即生效
source /etc/profile
# 验证
java -version

9、Hadoop安装
安装包获取:Hadoop1.3.1
将获取的安装包上传到虚拟机中,我这边上传到了 /home/hadoop 目录下
接下来进行Hadoop的安装
su - hadoop
# 解压安装包
tar -zxvf hadoop-3.1.3.tar.gz
# 重命名
mv hadoop-3.1.3 hadoop10、更改Hadoop相关配置
(1)workers文件配置(仅主节点修改)
vi /usr/local/hadoop/etc/hadoop/workers
# 填充一下内容,表示集群记录的节点
#####################
host181
host182
host183
#####################(2)配置hadoop-env.sh文件(三个节点都修改)
# 创建日志目录
mkdir -pv /home/hadoop/hadoop/logs
vi /home/hadoop/hadoop/etc/hadoop/hadoop-env.sh
# 填充以下内容
###############################
# JAVA_HOME 指明JDK的环境位置
export JAVA_HOME=/usr/local/jdk1.8
# HADOOP_HOME 指明hadoop的环境位置
export HADOOP_HOME=/home/hadoop/hadoop
# 关闭进程优先级调整
export HADOOP_NICENESS=0
# HADOOP_CONF_DIR 指明Hadoop的配置目录
export HADOOP_CONF_DIR=HADOOP_HOME/etc/hadoop
# 指明Hadoop运行日志的目录
export HADOOP_LOG_DIR=HADOOP_HOME/logs
###############################
(3)配置core-site.xml文件(三个节点都修改)
mkdir -pv /home/hadoop/hadoop/data/tmp
vi /home/hadoop/hadoop/etc/hadoop/core-site.xml
# 加入如下内容
# fs.defaultFS 指HDFS文件系统的网络通信路径。
# hdfs//host1:8020 表示整个HDFS内部的通讯地址,应用协议为hdfs//(Hadoop内部协议),表明DataNode将# 和host1的端口通讯,此配置固定了host1必须启动NameNode进程。
# io.file.buffer.size 表示io操作文件缓冲区大小(bit)。
######################
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://host181:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop/data/tmp</value>
</property>
</configuration>
######################(4)配置hdfs-site.xml文件(三个节点都修改)
mkdir -pv /home/hadoop/hadoop/data/namenode
mkdir -pv /home/hadoop/hadoop/data/datanode
vi /home/hadoop/hadoop/etc/hadoop/hdfs-site.xml
# 加入如下内容
# dfs.datanode.data.dir.perm 表示hdfs文件系统默认创建文件权限设置
# dfs.namenode.name.dir 表示NameNode元数据的存储位置
# dfs.datenode.name.dir 表示DataNode存放数据块的目录
# dfs.namenode.hosts 表示NameNode运行哪些节点的DataNode连接
# dfs.blocksize 表示hdfs默认大小256MB
# dfs.replication 表示副本数,根据从节点数调整
######################
<configuration>
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>700</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/hadoop/data/namenode</value>
</property>
<property>
<name>dfs.datenode.name.dir</name>
<value>/home/hadoop/hadoop/data/datanode</value>
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>host181,host182,host183</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
######################
(5)配置mapred-site.xml文件(三个节点都修改)
vi /home/hadoop/hadoop/etc/hadoop/mapred-site.xml
# 添加如下内容
# mapreduce.framework.name 指定运行MapReduce作业的执行框架
#####################
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
#####################(6)配置yarn-site.xml文件(三个节点都修改)
vi /home/hadoop/hadoop/etc/hadoop/yarn-site.xml
# 加入如下配置,其中 yarn.resourcemanager.hostname 仅需主节点配置
##########################
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>host181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 资源调度器 -->
<property>
<name>yarn.resourcemanager.scheduler.class</name
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
</configuration>
##########################11、启动Hadoop集群
(在主节点操作)
cd /home/hadoop/hadoop/bin
# 首次启动需要格式化 NameNode(仅第一次执行!)
./hdfs namenode -format
cd /home/hadoop/hadoop/sbin
# 启动 NameNode + DataNodes + SecondaryNameNode
./start-dfs.sh
# 查看集群节点状态
cd /home/hadoop/hadoop/bin/
./hdfs dfsadmin -report
# 检查进程,主节点启动了三个进程(DataNode,NameNode,SecondaryNameNode),从节点启动了一个进程(DataNode)
jps
# 启动资源调度
cd /home/hadoop/hadoop/sbin/
./start-yarn.sh
# 检查进程,主节点新增了(ResourceManager,NodeManager),从节点新增了(NodeManager)
jps
# 查看集群节点状态
cd /home/hadoop/hadoop/bin/
./yarn node -list
# 启动历史服务器(可选,用于查看作业日志)
./mapred --daemon start historyserver
# 检查进程,新增了进程(JobHistoryServer)
jps历史服务员界面,访问 http://<ResourceManager_IP>:19888 查看历史任务。
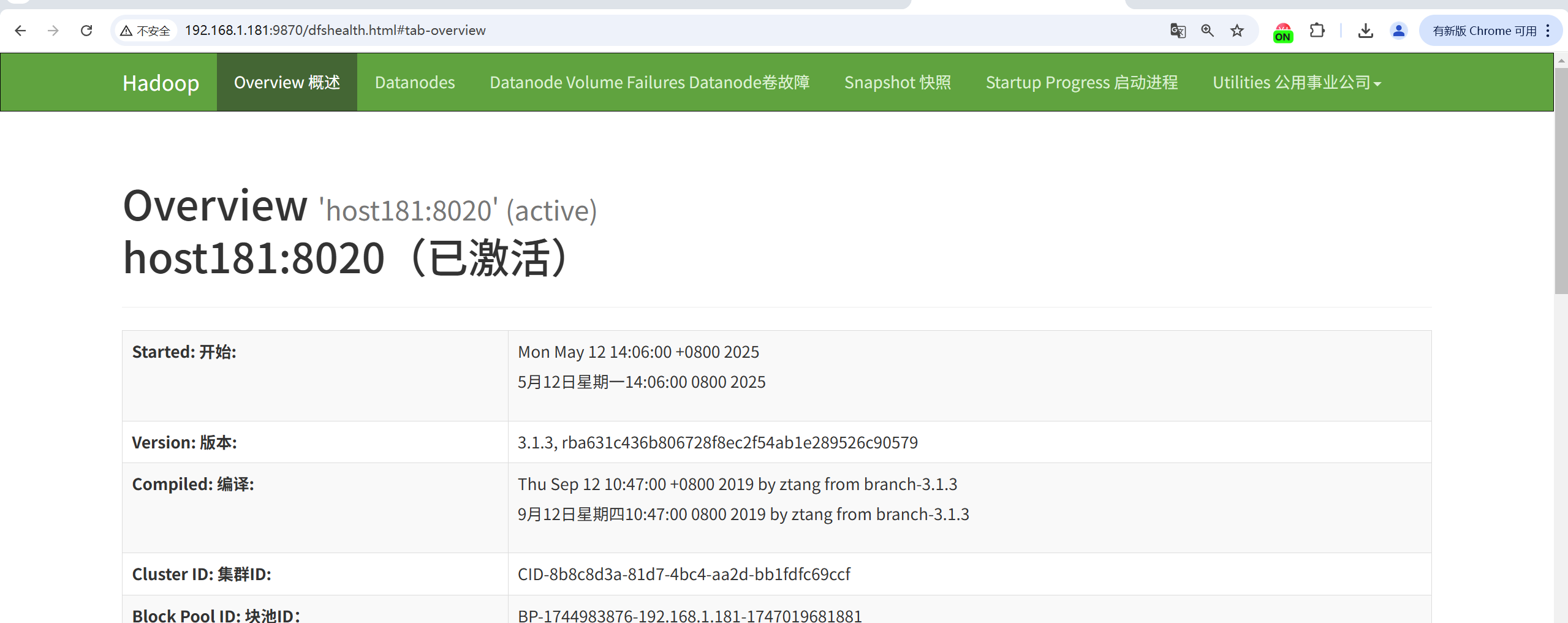
检查 DataNode 是否存活,存储空间等 http://<NameNode_IP>:9870
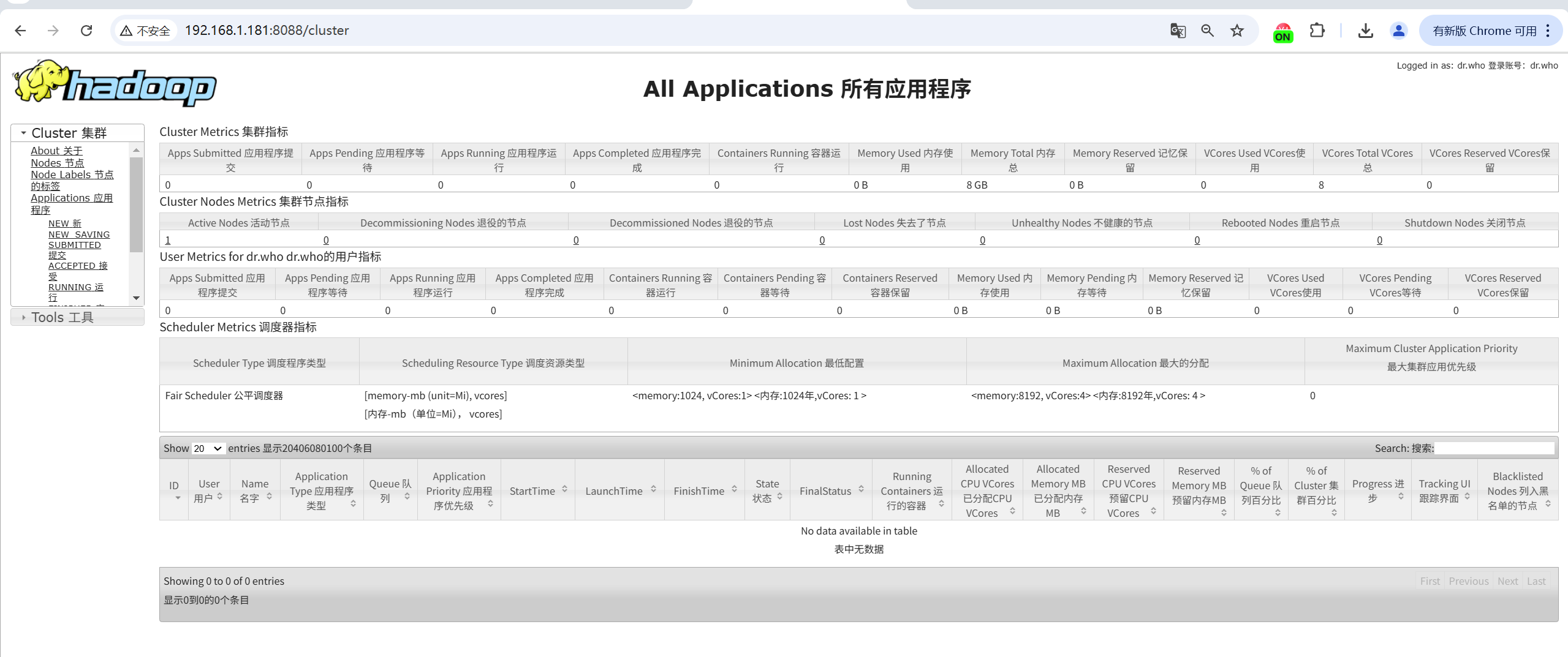
YARN ResourceManager(资源管理器)的 Web UI ,http://<ResourceManager_IP>:8088
12、停止hadoop集群
su - hadoop
cd /home/hadoop/hadoop/sbin
# 停止 YARN
./stop-yarn.sh
# 停止 HDFS
./stop-dfs.sh
# 停止所有服务
./stop-all.sh
# 停止历史服务器
cd /home/hadoop/hadoop/bin
./mapred --daemon stop historyserver
















 5166
5166

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









