







全链路压测理论基础
什么是全链路压测
· 基于实际的生产业务场景、系统环境,基于真实数据模拟海量的用户请求对整个业务链进行压力测试,并持续调优的过程;
· 全链路的核心为:业务场景、数据链路、压力模型和环境拓扑;
· 全链路压测不仅仅是一种测试手段,更确切来说其是一种测试过程,该过程涉及自动化测试/性能测试/高可用测试技术以外,还覆盖性能分析调优以及扩缩容解决方案等等。
为什么做全链路压测
· 大流量请求业务,稳定性保障非常困难;
· 大型的分布式系统微服务众多,调用链错综复杂;
· 测试环境版本、数据不统一,测试环境配置与生产环境配置差异大,无法通过测试环境中单模块单接口性能预估生产环境真实性能评估;
哪些场景适合全链路压测
· 定时定期进行线上运营活动;
· 业务链路以及数据链路调用错综复杂,各子系统之间调用关系密切,均为业务核心调用链路;
· 真实业务流量与历史流量对比预估有量的增长;
· 业务需求频繁迭代,业务链路性能波动较大;
· 测试环境数据、系统版本等无法统一,且资源配置与线上差异较大;
现在我也找了很多测试的朋友,做了一个分享技术的交流群,共享了很多我们收集的技术文档和视频教程。
如果你不想再体验自学时找不到资源,没人解答问题,坚持几天便放弃的感受
可以加入我们一起交流。而且还有很多在自动化,性能,安全,测试开发等等方面有一定建树的技术大牛
分享他们的经验,还会分享很多直播讲座和技术沙龙
可以免费学习!划重点!开源的!!!
qq群号:110685036
全链路压测模型设计(DESP)

从全链路压测的四个核心点抽象出压测模型,对应模型的四个维度:数据仿真度(D)、环境仿真度(E)、场景仿真度(S)、压力仿真度(P),通过这四个维度的优化和调整来达到我们整个系统压测的最佳仿真,压测仿真度决定了整个压测的成败。
数据仿真度(D):
压测数据包括两部分:
一是被压测系统的背景数据,也就是系统的历史数据、存量数据;
历史数据对于查询类场景比较重要,保留历史数据也是为了最大可能的接近真实场景。比如查询接口,返回1万和返回10万条结果,性能是差很多的,我们的原则是背景数据规模尽量接近真实场景。
二是被压测请求的参数化数据,也就是接口参数的数据,这些数据可以来自线上脱敏数据,也可以根据参数规则和场景需求自己构造。
除了数据规模,数据复杂度也是很重要的一个指标,也是比较容易忽略的,数据复杂度对性能的影响可能还会超过数据规模。比如续班活动,我们通过大量压测得知每个学员报的班级数量对整个续班链路性能起了决定性影响。
比如100个学员:
场景1:90个学员报2个班,10个学员报10个班
场景2:10个学员报2个班,90个学员报10个班
压测得知场景2的性能大大低于场景1,因为场景2学员个人的报班量大于场景1。这就指导我们构造学员和班级数据时要考虑报班量的分布,例如90%的学员报班量不超过5个,5%的学员报班量不超过10个,还有5%的学员报班量不超过30个,这就是数据负责度对性能的影响,如果不这样构造数据,压不出性能瓶颈,无法接近真实场景;
数据复杂度的通用解释就是根据业务场景的流量比例,确定接口参数不同取值,比例越精确,参数取值就越多样化,也就越复杂,这些需要前期分析大量的调用日志获得。
数据仿真度因子包括:数据复杂度、数据规模
环境仿真度(E):
测试环境应该尽量接近真实环境,推荐直接在线上压测,需要建设压测通道,做到压测数据隔离,不要影响真实数据。如果没法在线上压测,那么线下环境尽量跟线上按等比例部署,服务器配置尽量跟线上一样,否则仿真度会大打折扣。
环境仿真度因子包括:是否线上压测、线下部署规模(跟线上集群等比例压缩)、线下服务器资源配置(跟线上保持一致)
场景仿真度(S):
压测场景就是压测的目标和范围,是我们压测的前提。需要充分了解业务,归纳抽象出一条或者多条核心业务链路,确定链路中的所有接口和调用请求,确定请求调用方式(同步或者异步,顺序或者并行)、参数等;
所谓业务链路就是用户的操作行为,核心链路就是分析所有用户操作的行为,确定的一条主链路,比如天猫双11,用户在淘宝的操作行为非常多,那么我们压测主要关注11号0点时最大的压力来自于哪些行为?通过分析就可以确定0点的主要行为就是:打开购物车->进行结算->打开收银台->选择优惠券、支付方式->支付->下单后置处理。这就是我们压测的核心链路,是通过日志和用户行为分析可以得出。
确定核心链路的一个关键就是不要贪多,觉得用户可能会操作这里,也可能操作那里,把一些低频的操作也加入链路,就会拖累核心链路。双11零点只保障核心链路,非核心的操作都会降级处理,比如0点打开订单页就会看到一行提示“只能查询最近三个月订单,其他订单20分钟以后再查”,这就是对订单进行了降级处理,避免查询数据太多占用过多资源,更多资源投入核心链路。
场景仿真度因子包括:核心链路的完整度、准确度、系统可测度
压力仿真度(P):
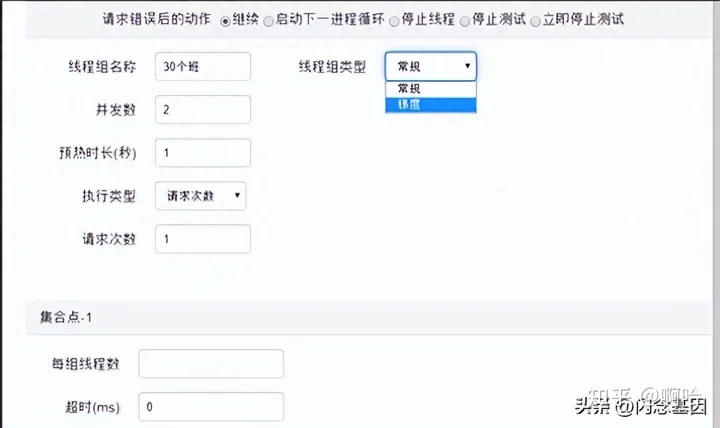
压力仿真度是指压测负载参数,包括压测模式(并发模式或者TPS/TPM目标模式)、并发数或者TPS目标数、集合点配置、thinktime设置、预热时长、压测时长等;
选择哪种压测模式是根据我们的压测目的决定的,这是我们整个压测能否达到目标的核心。
并发压测模式:适用于已知大概并发的压测场景,比如预计系统有10万用户访问,这10万就是极限并发,还需要进一步分析10万用户是集中访问,还是分散访问,
估算多长时间内会达到10万用户。如果10万用户会集中访问,比如秒杀、抢购类的场景,这样我们就需要设置10万并发,进行集合点压测。如果是1天内累计有10万用户访问,那么可以按照二八法则设置并发进行压测。
TPS目标压测模式:TPS即每秒钟请求量,也可以叫吞吐量。适用于后台接口类的场景,跟并发没关系,关注的是接口的吞吐量。比如接口设计最大TPS是10万,那么我们就可以直接用目标模式,设置TPS为10万,不需要设置并发,压测系统会根据目标TPS自动变化并发,如果压测系统检测到TPS到了10万,压力会保持不变,持续压测。如果目标TPS达不到,压测系统会提示系统不达标。
压力仿真度因子包括:并发数、TPS目标数、集合点并发数、thinktime
全链路压测案例分享
新东方续班体系全链路压测方案
一、续班体系介绍
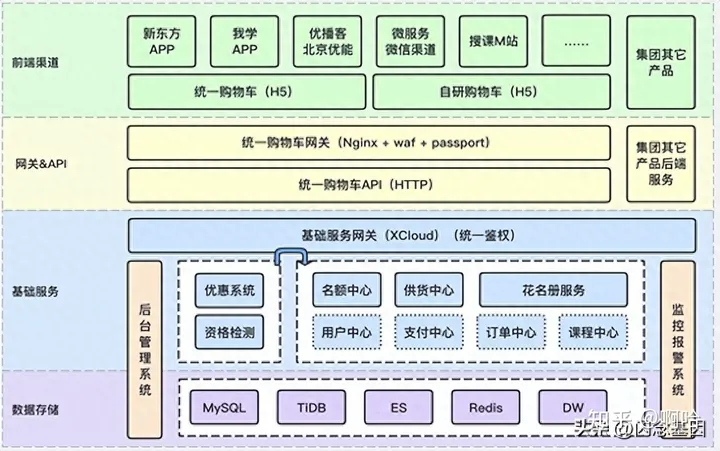
续班体系业务链路调用较复杂,同时业务逻辑校验相对较多,其不仅需要验证帐号和对应学员的有效性,同时需要校验班级各种属性,以及在当前时段内续班规则校验和实时计算报班的最优优惠,最终完成订单操作;
二、压测场景
· 确定压测链路
根据系统调用量和用户操作行为,梳理核心业务场景,确定相关的系统服务和接口
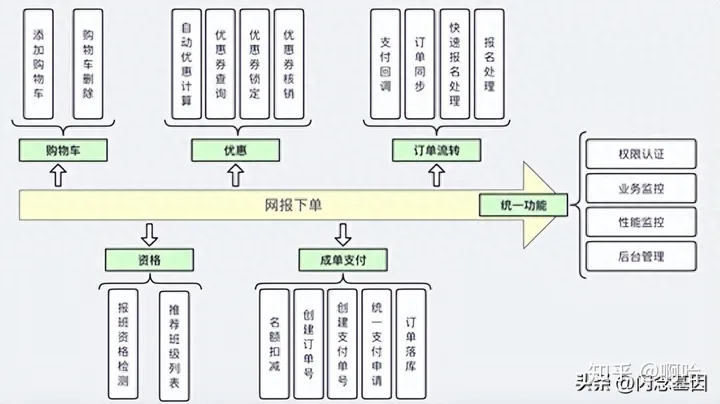
· 压测通道建设,解决压测流量和数据的隔离
续班链路压测场景基于生产真实环境实现,因此我们需要考虑进行真实数据和压测数据有效隔离,防止压测数据污染生产环境
实现方式:通过增加header标识进行压测流量标记,同时将压测标识透传关联业务系统并处理,通过压测标记过滤部分规则(如时间范围和名额等信息),保证压测数据业务正常流转且尽最大程度覆盖业务逻辑;根据标识区分压测流量和生产真实流量;
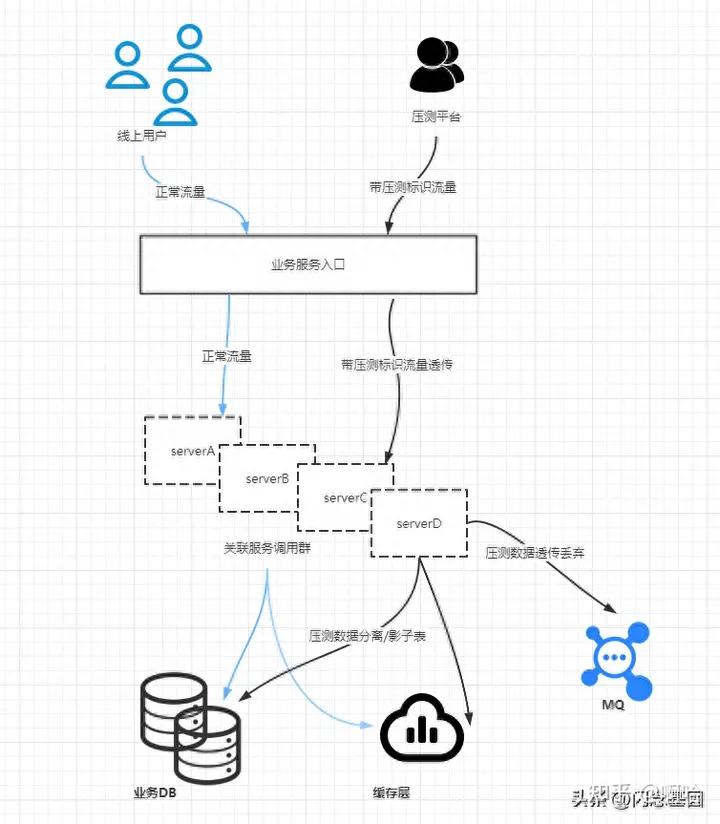
三、压测数据
压测场景主要覆盖两种压测数据:一类是通过测试帐号自动构造的数据(班级和规则均是直接使用生产真实数据);一类是通过数据抽取的方式获取真实用户流量数据进行真实流量回放;
链路相关数据主要涉及登录帐号、学员、班级,以及相应的业务规则和优惠规则;
· 对于常规续班体系性能验证,以及新服务上线,推荐使用历史数据,来压测指定的业务场景和服务;(规则为历史数据不是当前最新规则数据)
· 对于续班窗口期真实流量模拟性能能力验证,推荐使用真实流量,压测结果性能反馈更接近真实情况;(规则为当前有效数据数据业务仿真度较高)
· 针对业务链路压测覆盖不同的场景,需评估选择构造不同的压测数据
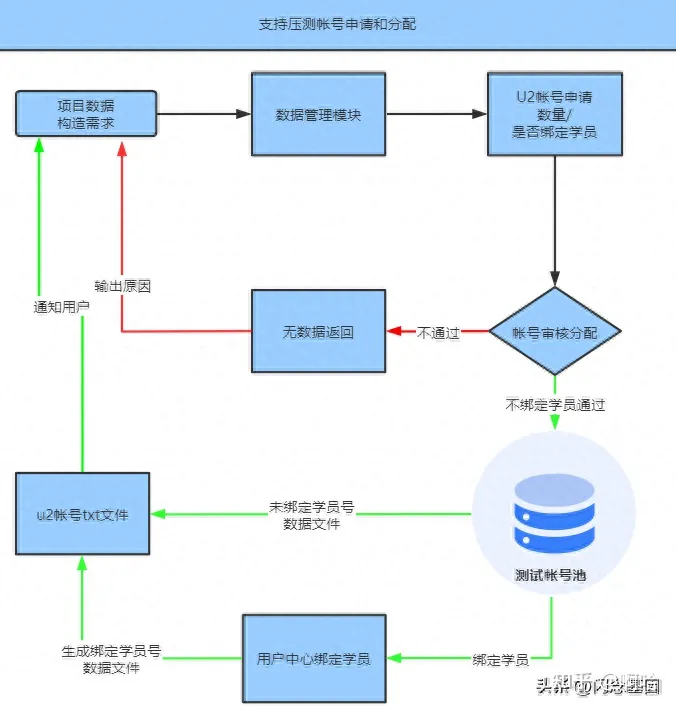
(1)基元数据
包括登录帐号、学员;
· 登录帐号:生产环境预留维护了约6万+测试帐号,供线上压测和其它业务测试使用;平台基于测试帐号可根据项目按需统一分配和回收;
· 学员:虚拟学员和真实学员;虚拟学员即为测试帐号对应的虚拟学员,通过姓名以及帐号绑定与真实学员数据隔离;真实学员:生产环境真实报班生成的学员信息;
实现方式:基于不同的压测场景以及业务链路,可自定义申请压测帐号;根据业务压测结果反馈,引导任务完成后实现测试数据清除以及帐号统一回收;
(2)业务型数据
· 班级:支持使用真实班级信息;基于业务链路实现数据一键构造完成;
· 业务规则:包括续班规则和优惠规则;通过压测标识实现续班压测链路自定义指定时间段内有效规则;
· 链路数据:通过基础数据和业务规则数据进行模拟业务操作,实现续班链路压测数据构造;支持任务调度中心一键/定时自动触发数据构造;
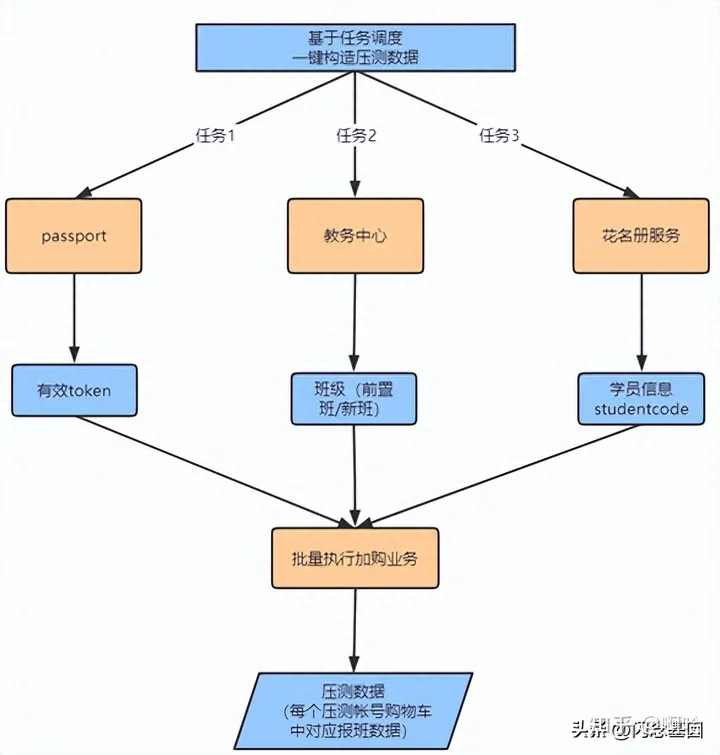
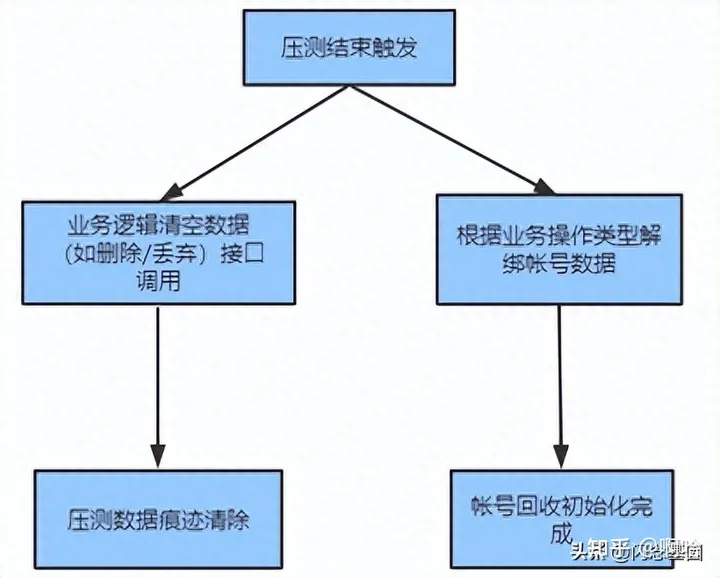
(3)压测数据清洗初始化
压测任务结束后,平台自定义清洗压测数据,基础数据初始化回收;
根据业务逻辑,对业务数据清洗(如:购物车数据);
基于用户服务业务针对分配的帐号是否解绑业务数据,最后回收并初始化帐号数据;
四、压测负载
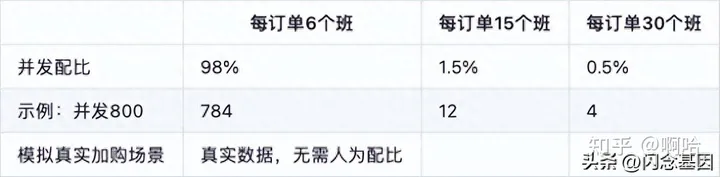
通过分析生产流量和系统性能表现,我们得出了续班链路压力模型和并发配比。
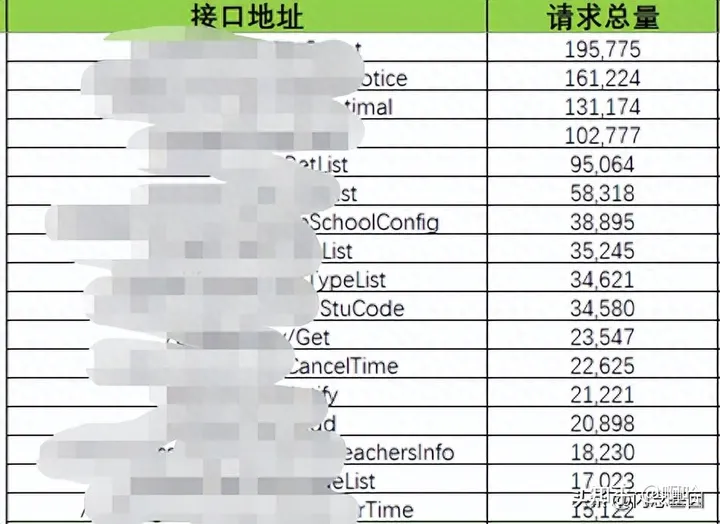
· 基于续班链路日志各业务调用峰值以及占比,定位续班链路压测覆盖范围,同时定位链路中业务并发点;
通过日志调用量以及业务实际抓包形式,确定续班链路业务调用以及业务上下游调用范围;
根据业务实现调用设计集中并发场景,实现模拟并发配比趋于真实流量请求;
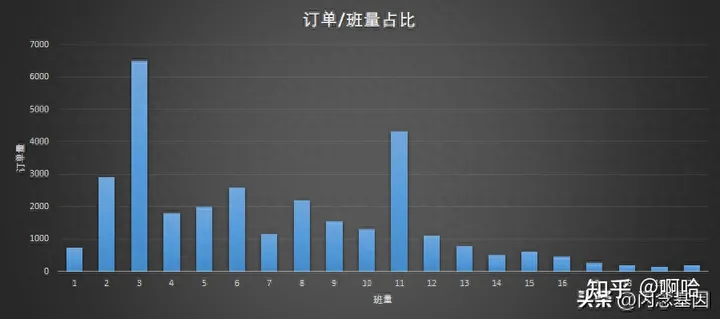
· 基于各续班窗口期订单数据详情,分析定位续班期订单数据占比;
通过订单详情统计分析订单中报班占比,构造并生成按统计汇总的实际占比的压测数据;
根据汇总统计订单占比结果,实现按该占比设计压测场景,实现模拟并发配比趋于真实流量请求;
· 真实加购数据全量模拟
为保证每次大流量续班业务性能,实现了全量拉取参与续班期的购物车数据;
根据真实加购数据设计压测场景,完成真实加购续班数据瞬时并发性能评估,同时为各节点扩容方案提供参考数据;
基于订单数据的压测场景并发配比表:
五、压测自动化
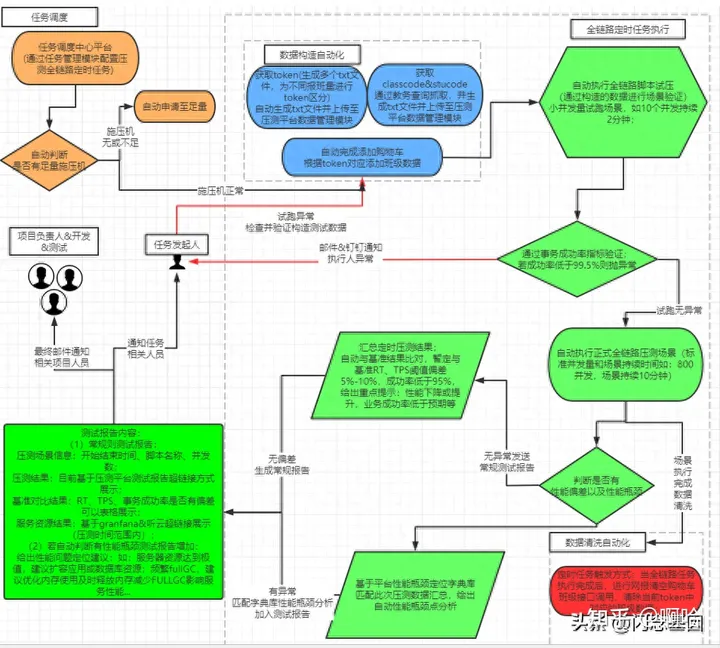
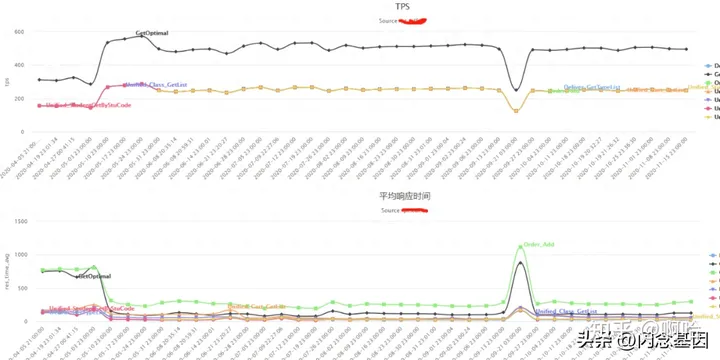
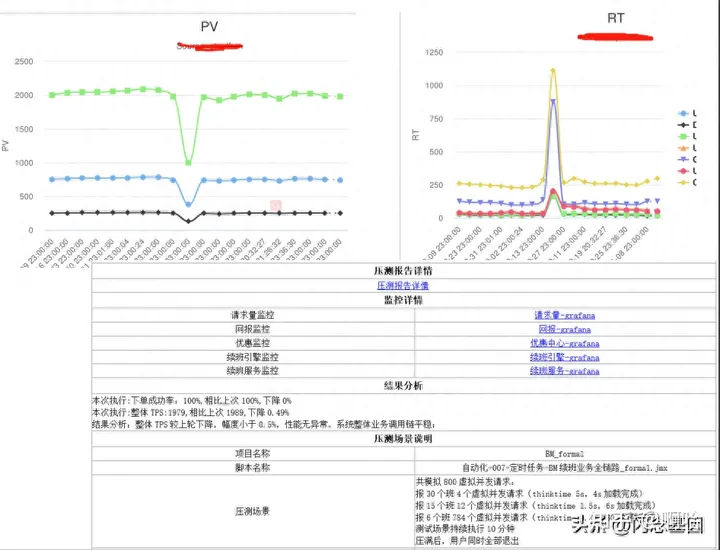
基于线上真实调用业务流量,设计基线压测场景,以任务调度的方式自动触发压测任务执行,并完成测试结果收集,同时对当前压测结果与上一轮压测结果进行对比,出现性能偏差则给出邮件或钉钉提示
整体性能基线建设基于任务调度中心触发任务的方式实现:
· 数据自动构造:通过任务方式在执行基线场景前,自动完成压测数据构造,并引用至压测场景中进行数据关联;
· 压测场景试运行:由于压测场景复杂性,因此完成数据构造后,自动实现压测场景试运行,目的验证场景业务链路调用是否正常,同时验证压测数据是否有效可用;
· 自定义任务:在建立基线过程中,根据业务调用需求,可自定义增加任务,如:压测场景中数据预热等;
· 基线任务执行:支持手动和定时两种方式完成基线压测场景执行;
· 压测结果对比评估当前系统性能可能存在的问题并消息通知相关负责人,目前支持邮件和钉钉通知两种方式;
全链路压测平台建设
一、系统架构
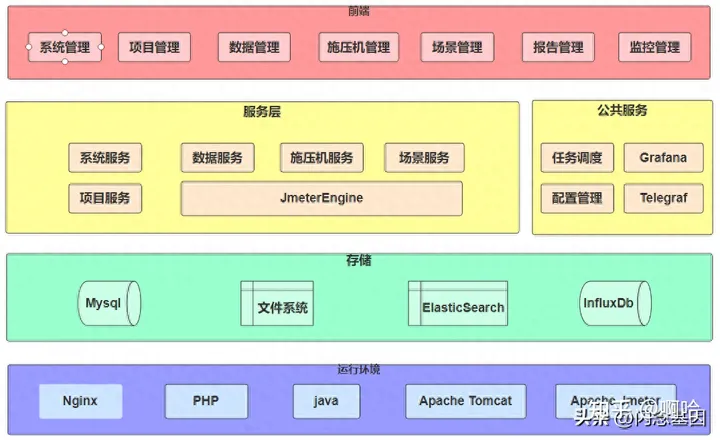
二、功能简介
· 实现功能
· 支持HTTP/HTTPS协议,支持在线创建脚本、调试脚本;
· 压测数据构造一键生成;
· 压测建模设计灵活;
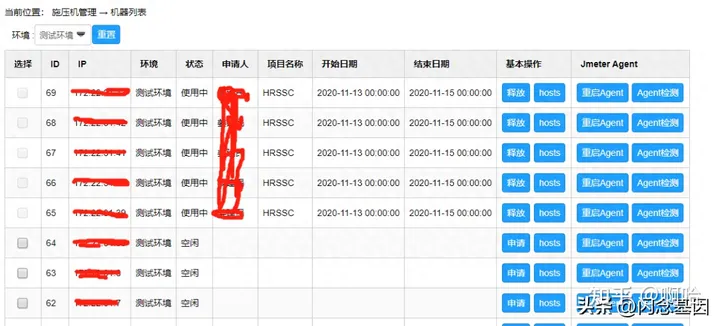
· 施压机统一管理维护;
· 测试过程实时监控及预警熔断;
· 测试结果报表聚合汇总归档支持建立性能基线库;
· 基于任务调度建立项目基线任务监控系统性能;
最后感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走!

软件测试面试文档
我们学习必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有字节大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


















 1092
1092

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









