






数据集介绍
本数据集涵盖了2000年到2019年全国各省的居民可支配收入、农村家庭可支配、城市家庭可支配、总人口数、
城镇化率、城镇总人口、农村总人口、城镇总收入、农村总收入、总收入,并且在此基础上计算了相应的泰尔
指数。在开始正式的分析之前,先对一些指标进行说明:城镇化率:城镇化是人口、地域、社会经济组织形式
和生产生活方式由传统落后的乡村型社会向现代城市社会转化的过程,是人类社会发展的客观趋势,是国家现
代化的重要标志,城镇化率是衡量城镇化发展水平的重要指标。泰尔指数是用来衡量个人之间或者地区间收入
差距(或者称不平等度)的指标。在本次实验中,主要选择了河南、山东、北京、广东四省的数据进行分析并
绘制了折线图、柱状图、饼图。
读取数据
import pandas as pd
pd_ = pd.read_excel("./data/data.xlsx")
检查数据缺失情况
pd_.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 620 entries, 0 to 619
Data columns (total 20 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 620 non-null int64
1 year 620 non-null int64
2 NAME 620 non-null object
3 居民可支配收入(元) 620 non-null float64
4 农村家庭可支配(元) 620 non-null float64
5 城市家庭可支配(元) 620 non-null float64
6 总人口数(万人) 620 non-null float64
7 城镇化率 620 non-null float64
8 城镇总人口(万人) 620 non-null float64
9 农村总人口(万人) 620 non-null float64
10 城镇总收入(元) 620 non-null float64
11 农村总收入(元) 620 non-null float64
12 总收入(元) 620 non-null float64
13 P1/P 620 non-null float64
14 Z1/Z 620 non-null float64
15 LN(N/O) 620 non-null float64
16 P2/P 620 non-null float64
17 Z2/Z 620 non-null float64
18 LN(Q/R) 620 non-null float64
19 泰尔指数 620 non-null float64
dtypes: float64(17), int64(2), object(1)
memory usage: 97.0+ KB
读取第二、三、四列数据
data = pd.read_excel("./data/data.xlsx",usecols=[1,2,3])
data
| year | NAME | 居民可支配收入(元) | |
|---|---|---|---|
| 0 | 2000 | 北 京 | 9065.07328 |
| 1 | 2000 | 天 津 | 6876.33562 |
| 2 | 2000 | 河 北 | 3313.29906 |
| 3 | 2000 | 山 西 | 2893.76610 |
| 4 | 2000 | 内蒙古 | 3361.72338 |
| ... | ... | ... | ... |
| 615 | 2019 | 陕 西 | 26453.69675 |
| 616 | 2019 | 甘 肃 | 20633.46305 |
| 617 | 2019 | 青 海 | 23897.51568 |
| 618 | 2019 | 宁 夏 | 25710.40186 |
| 619 | 2019 | 新 疆 | 24295.53540 |
620 rows × 3 columns
选取河南、北京、广东、山东四省的数据
sheet1 = data.loc[(data['NAME']==' 河 南 ') | (data['NAME']==' 北 京 ') | (data['NAME']==' 广 东 ') | (data['NAME']==' 山 东 ')]
将居民可支配收入数据类型转换成int
sheet1['居民可支配收入(元)'] = sheet1['居民可支配收入(元)'].astype(int)
C:\Users\Lenovo\AppData\Local\Temp\ipykernel_16580\1273220474.py:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
sheet1['居民可支配收入(元)'] = sheet1['居民可支配收入(元)'].astype(int)
将sheet1中的数据按省份分成四个数据集
sheet1_henan = sheet1.loc[(sheet1['NAME']==' 河 南 ')]
sheet1_beijing = sheet1.loc[(sheet1['NAME']==' 北 京 ')]
sheet1_guangdong = sheet1.loc[(sheet1['NAME']==' 广 东 ')]
sheet1_shandong = sheet1.loc[(sheet1['NAME']==' 山 东 ')]
绘制2000-2019年河南、北京、广东、山东四省居民可支配收入增长曲线
import matplotlib.pyplot as plt
import numpy as np
names=['河南','北京','广东','山东']
years=['2000','2001','2002','2003','2004','2005','2006','2007','2008','2009','2010',
'2011','2012','2013','2014','2015','2016','2017','2018','2019']
list = []
y=np.array(sheet1_henan['居民可支配收入(元)'])
y1=np.array(sheet1_beijing['居民可支配收入(元)'])
y2=np.array(sheet1_guangdong['居民可支配收入(元)'])
y3=np.array(sheet1_shandong['居民可支配收入(元)'])
list.append(y)
list.append(y1)
list.append(y2)
list.append(y3)
plt.figure(figsize=(15,7))
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.style.use('fivethirtyeight')
for i in range(4):
plt.plot(years,list[i],label=names[i],marker='o',markeredgecolor='b',markeredgewidth=1,linestyle='--',linewidth=1.5)
plt.xlabel('时间')
plt.ylabel('收入(元)')
plt.title('2000-2019年河南、北京、广东、山东四省居民可支配收入增长曲线')
plt.legend(prop = {'size':16})
plt.show()

读取数据选中第二、三、八、九、十列数据
data2 = pd.read_excel("./data/data.xlsx",usecols=[1,2,7,8,9])
data2
| year | NAME | 城镇化率 | 城镇总人口(万人) | 农村总人口(万人) | |
|---|---|---|---|---|---|
| 0 | 2000 | 北 京 | 0.7764 | 1059.009600 | 304.990400 |
| 1 | 2000 | 天 津 | 0.7202 | 720.920200 | 280.079800 |
| 2 | 2000 | 河 北 | 0.2622 | 1749.922800 | 4924.077200 |
| 3 | 2000 | 山 西 | 0.3506 | 1138.398200 | 2108.601800 |
| 4 | 2000 | 内蒙古 | 0.4282 | 1015.690400 | 1356.309600 |
| ... | ... | ... | ... | ... | ... |
| 615 | 2019 | 陕 西 | 0.5943 | 2303.631603 | 1572.578397 |
| 616 | 2019 | 甘 肃 | 0.4849 | 1283.738807 | 1363.691193 |
| 617 | 2019 | 青 海 | 0.5552 | 337.461664 | 270.358336 |
| 618 | 2019 | 宁 夏 | 0.5986 | 415.823476 | 278.836524 |
| 619 | 2019 | 新 疆 | 0.5187 | 1308.794214 | 1214.425786 |
620 rows × 5 columns
sheet2 = data2.loc[(data2['NAME']==' 河 南 ') | (data2['NAME']==' 北 京 ') | (data2['NAME']==' 广 东 ') | (data2['NAME']==' 山 东 ')]
sheet2_henan = sheet2.loc[(sheet1['NAME']==' 河 南 ')]
sheet2_beijing = sheet2.loc[(sheet1['NAME']==' 北 京 ')]
sheet2_guangdong = sheet2.loc[(sheet1['NAME']==' 广 东 ')]
sheet2_shandong = sheet2.loc[(sheet1['NAME']==' 山 东 ')]
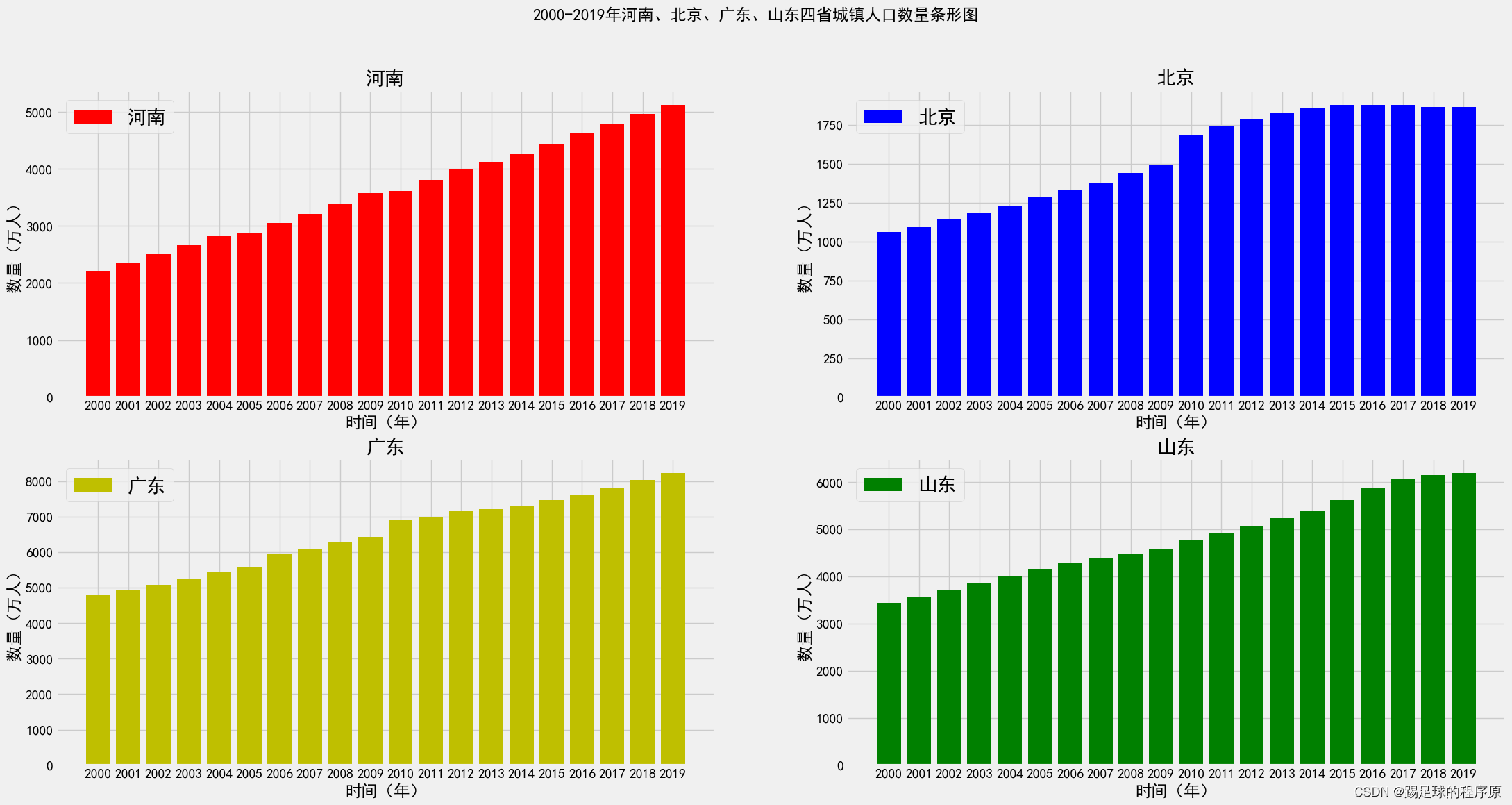
绘制2000-2019年河南、北京、广东、山东四省城镇总人口数量条形图
fig=plt.figure(figsize=(24,12),dpi=100)
plt.style.use('fivethirtyeight')
c=0
list=[]
y=sheet2_henan['城镇总人口(万人)']
y1=sheet2_beijing['城镇总人口(万人)']
y2=sheet2_guangdong['城镇总人口(万人)']
y3=sheet2_shandong['城镇总人口(万人)']
list.append(y)
list.append(y1)
list.append(y2)
list.append(y3)
color=['r','b','y','g']
for i in range(4):
c=c+1
ax=fig.add_subplot(2,2,c)
plt.bar(years,list[i],color=color[i],label=names[i])
fig.suptitle("2000-2019年河南、北京、广东、山东四省城镇人口数量条形图")
plt.xlabel('时间(年)')
plt.ylabel('数量(万人)')
plt.title(names[i])
plt.legend(prop = {'size':20})
plt.show()
绘制2000-2019年河南、北京、广东、山东四省农村总人口数量条形图
fig=plt.figure(figsize=(24,12),dpi=100)
num=0
list1=[]
Y=sheet2_henan['农村总人口(万人)']
Y1=sheet2_beijing['农村总人口(万人)']
Y2=sheet2_guangdong['农村总人口(万人)']
Y3=sheet2_shandong['农村总人口(万人)']
list1.append(Y)
list1.append(Y1)
list1.append(Y2)
list1.append(Y3)
for i in range(4):
num=num+1
ax=fig.add_subplot(2,2,num)
plt.bar(years,list1[i],color=color[i],label=names[i])
fig.suptitle("2000-2019年河南、北京、广东、山东四省农村人口数量")
plt.xlabel('时间(年)')
plt.ylabel('数量(万人)')
plt.title(names[i])
plt.legend(prop = {'size':20})
plt.show()

读取数据选中第二、三、四列数据
data3 = pd.read_excel("./data/data.xlsx",usecols=[1,2,6])
选取河南、北京、广东、山东四省
sheet3 = data3.loc[(data['NAME']==' 河 南 ') | (data['NAME']==' 北 京 ') | (data['NAME']==' 广 东 ') | (data['NAME']==' 山 东 ')]
sheet3_2000 = sheet3.loc[sheet3['year']==2000]
sheet3_2006 = sheet3.loc[sheet3['year']==2006]
sheet3_2012 = sheet3.loc[sheet3['year']==2012]
sheet3_2019 = sheet3.loc[sheet3['year']==2019]
sheet3_2000
| year | NAME | 总人口数(万人) | |
|---|---|---|---|
| 0 | 2000 | 北 京 | 1364.0 |
| 14 | 2000 | 山 东 | 8998.0 |
| 15 | 2000 | 河 南 | 9488.0 |
| 18 | 2000 | 广 东 | 8650.0 |
values=sheet3_2000['总人口数(万人)']
values1=sheet3_2006['总人口数(万人)']
values2=sheet3_2012['总人口数(万人)']
values3=sheet3_2019['总人口数(万人)']
list2=[]
list2.append(values)
list2.append(values1)
list2.append(values2)
list2.append(values3)
years=[2000,2006,2012,2019]
names=['北京','山东','河南','广东']
# 绘图
fig, axs = plt.subplots(2, 2, figsize=(16, 16), dpi=100)
axs = axs.ravel() #子图对象展平成一个一维的数组
for i in range(4):
plt.sca(axs[i])
plt.pie(list2[i],autopct='%1.1f%%',labels=names) #autopct在饼图上显示每个数据占比的百分比
plt.title(str(years[i])+'年')
plt.legend(prop={'size':12})
plt.style.use('fivethirtyeight')
# 添加数据表
data = {'省份': names, '总人口数(万人)': list2[i]}
df = pd.DataFrame(data)
# axs[i].axis('off')
axs[i].table(cellText=df.values,colLabels=df.columns,loc='bottom',rowLoc="center")
#cellText=df.values 用于传入数据,colLabels=df.columns 则添加表格列名。rowLoc="center" 参数用于设置行居中
fig.suptitle('2000、2006、2012、2019年河南、北京、广东、山东四省总人口比例', fontsize=14)
plt.show()
















 1766
1766











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









