






概念
反向传播(英语:Backpropagation,缩写为BP)是“误差反向传播”的简称,是一种与最优化方法(如梯度下降法)结合使用的,用来训练人工神经网络的常见方法。 该方法对网络中所有权重计算损失函数的梯度。 这个梯度会反馈给最优化方法,用来更新权值以最小化损失函数。(误差的反向传播)
算法的思路
多层神经网络的教学过程 反向传播 算法 为了说明这一点 使用如下图所示处理具有两个输入和一个输出的三层神经网络:
每个神经元由两个单元组成。 第一个单元将权重系数和输入信号的乘积相加。 第二单元实现非线性 函数,称为神经元激活函数。 信号 e 为加法器输出信号, y = f(e) 为非线性输出信号 元素。 信号 y 也是神经元的输出信号。
为了教授神经网络,我们需要训练数据集。 训练数据集由输入信号 ( x 1 和 x 2 ) 分配有相应的目标(期望的输出) z 。
网络训练是一个迭代过程。 每一个 使用来自训练数据集的新数据修改节点的迭代权重系数。 使用算法计算修改 如下面所描述的:
每个教学步骤都从强制训练集中的两个输入信号开始。 在这个阶段之后,我们可以确定输出信号值 每个网络层中的每个神经元。下图说明了信号如何通过网络传播,符号 w (xm)n 之间的连接权重 x m 和 n 输入层中 符号 y n 表示神经元 n
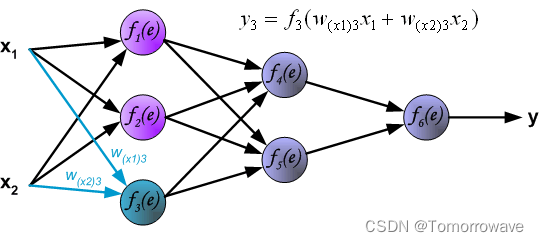
通过隐藏层传播信号。 符号 w mn 表示神经元输出之间的连接权重 m 和 n 下一层
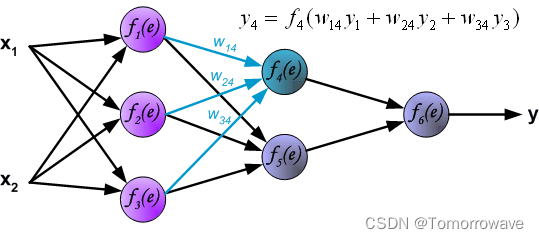
通过输出层传播信号。
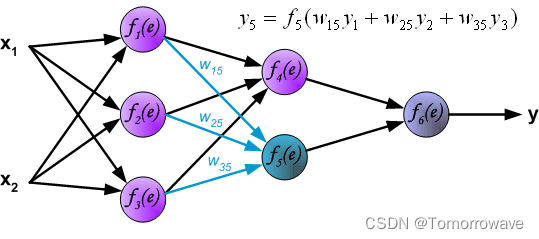
在下一个算法步骤中,将网络 y 与所需的输出值(目标)进行比较,找到 在训练数据集中。 差值称为误差信号 d的 输出层神经元。
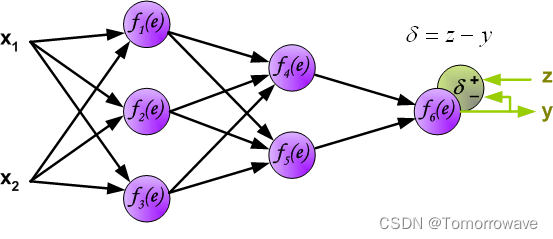
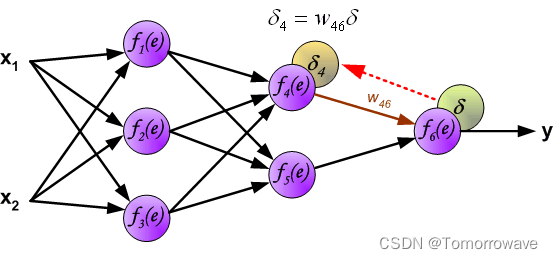
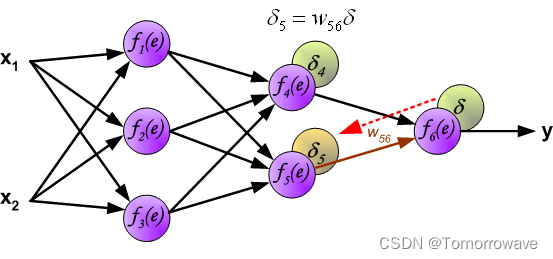
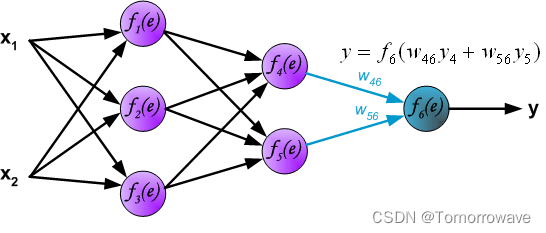
的权重系数 w mn 等于计算输出值期间使用的权重系数。 只有 数据流的方向发生了变化(信号从输出一个接一个地传播到输入)。 该技术用于所有网络 层。 如果传播的错误来自少数神经元,则添加它们。 图示如下:
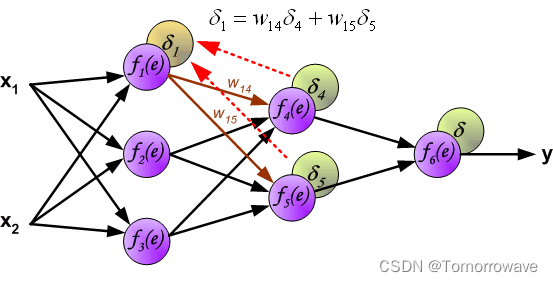
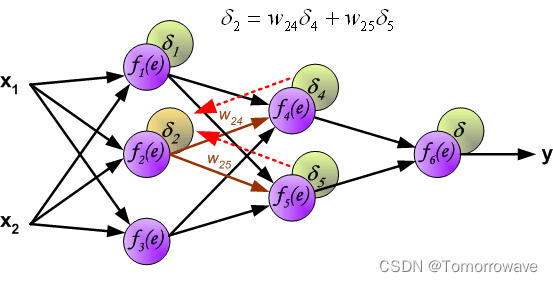
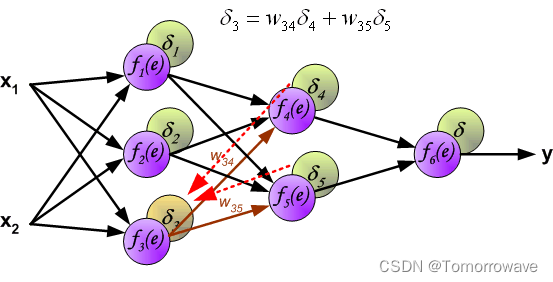
当计算每个神经元的误差信号时,可以修改每个神经元输入节点的权重系数。 在下面的公式中 df(e)/de 表示神经元激活函数的导数(权重被修改)。
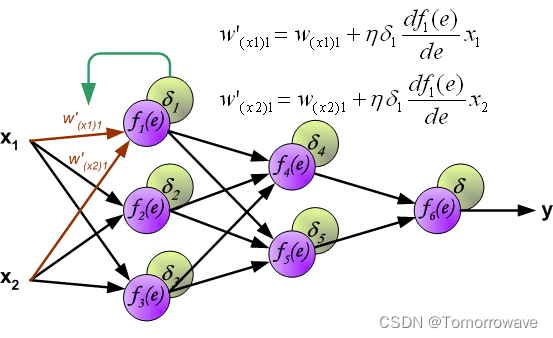
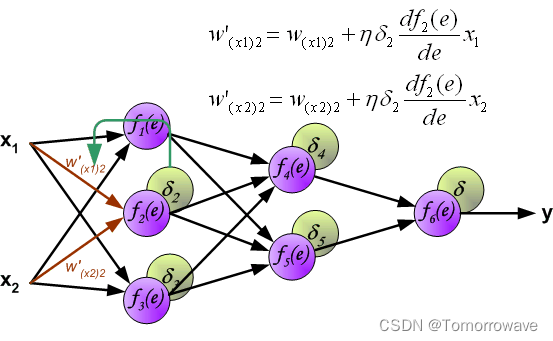
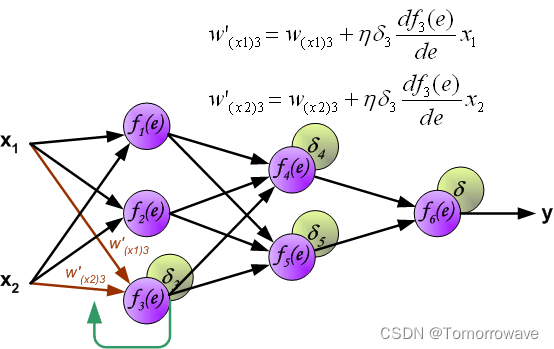
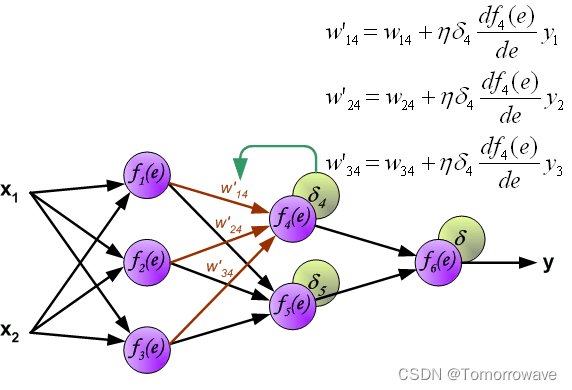
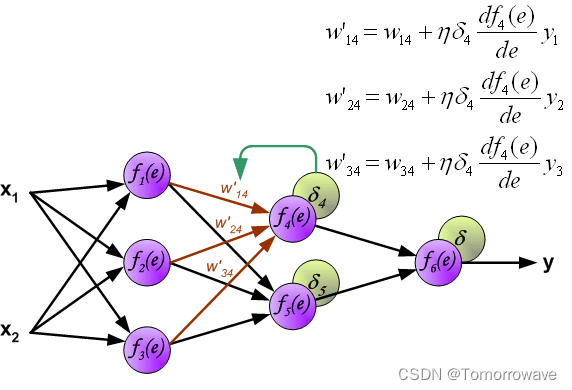
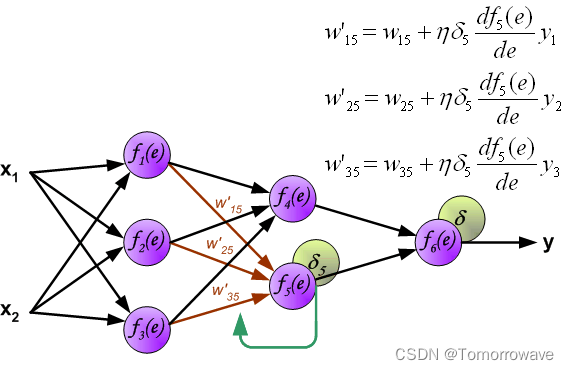
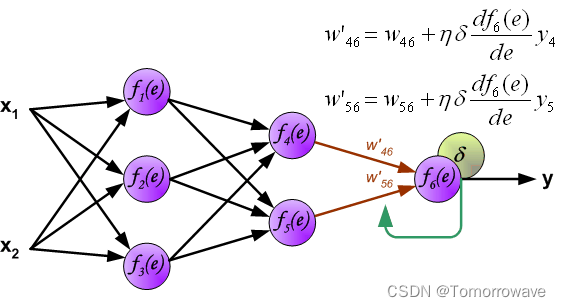
系数 H 影响网络教学速度。 有几个 技术来选择这个参数。 第一种方法是用较大的参数值开始示教过程。 虽然权重 系数正在建立,参数正在逐渐减小。 第二种更复杂的方法开始教学 小参数值。 在示教过程中,参数在示教前进时增大,然后在示教过程中再次减小。 最后阶段。 以低参数值开始教学过程可以确定权重系数符号。















 1986
1986











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









