






(一)代码解读
对于day1的代码进行分析:
首先,处理MIT-BIH数据库的数据,MIT-BIH的数据主要分为三个类型:.hea .dat .atr,首先要对这三种数据进行分析处理
def load_dataset():
"""加载并处理MIT-BIH数据集"""
all_beats = []
all_labels = []
valid_symbols = {'N', 'L', 'R', 'B', 'A', 'a', 'J', 'S', 'V',
'r', 'F', 'e', 'j', 'n', 'E', '/', 'f', 'Q', '?'}
for record in Config.RECORDS:
try:
# 读取数据
record_path = os.path.join(Config.BASE_PATH, str(record))
signal = wfdb.rdrecord(record_path, channels=[0]).p_signal.flatten()
annotation = wfdb.rdann(record_path, 'atr')
# 处理每个心拍
for i, (symbol, sample) in enumerate(zip(annotation.symbol, annotation.sample)):
if symbol not in valid_symbols:
continue
# 截取心拍
start = sample - Config.SAMPLE_LENGTH // 2
end = sample + Config.SAMPLE_LENGTH // 2
if start < 0 or end > len(signal):
continue
beat = signal[start:end]
beat = (beat - np.min(beat)) / (np.max(beat) - np.min(beat)) # 归一化
# 生成标签
label = 0 if symbol == 'N' else 1
all_beats.append(beat)
all_labels.append(label)
except Exception as e:
print(f"Error processing record {record}: {str(e)}")
continue
# 转换为numpy数组并添加通道维度
X = np.array(all_beats)[..., np.newaxis]
y = np.array(all_labels)
return X, y然后就是创建模型阶段,这里使用的是1D CNN(一维卷积神经网络)
-
输入层:接收形状为
input_shape的心电信号片段,表示每个心电信号片段的长度和通道数(这里是1个通道)。 -
卷积层1:
-
使用32个卷积核,每个卷积核的大小为5,用于提取局部特征。
-
使用ReLU激活函数,增加模型的非线性表达能力。
-
padding='same'确保输出的长度与输入相同,避免信息丢失。
-
-
批量归一化层:对卷积层的输出进行归一化处理,加速训练过程,提高模型的稳定性。
-
池化层1:使用最大池化,池化窗口大小为2,用于降低特征维度,减少计算量,同时保留重要特征。
-
卷积层2:
-
使用64个卷积核,每个卷积核的大小为5,进一步提取更高级的特征。
-
同样使用ReLU激活函数和
padding='same'。
-
-
批量归一化层:对第二个卷积层的输出进行归一化处理。
-
池化层2:再次使用最大池化,进一步降低特征维度。
-
Flatten层:将多维的特征图展平成一维向量,为全连接层做准备。
-
全连接层:包含64个神经元,使用ReLU激活函数,用于整合提取到的特征。
-
Dropout层:以0.5的概率随机丢弃神经元,防止过拟合,提高模型的泛化能力。
-
输出层:包含1个神经元,使用Sigmoid激活函数,输出一个介于0和1之间的概率值,表示样本属于正类的可能性。
def create_model(input_shape):
"""创建1D CNN模型"""
model = models.Sequential([
layers.Input(shape=input_shape),
layers.Conv1D(32, 5, activation='relu', padding='same'),
layers.BatchNormalization(),
layers.MaxPooling1D(2),
layers.Conv1D(64, 5, activation='relu', padding='same'),
layers.BatchNormalization(),
layers.MaxPooling1D(2),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dropout(0.5),
layers.Dense(1, activation='sigmoid')
])
model.compile(
optimizer=tf.keras.optimizers.Adam(Config.INIT_LR),
loss='binary_crossentropy',
metrics=[
'accuracy',
tf.keras.metrics.AUC(name='auc'),
tf.keras.metrics.Recall(name='recall'),
tf.keras.metrics.Precision(name='precision')
]
)
return model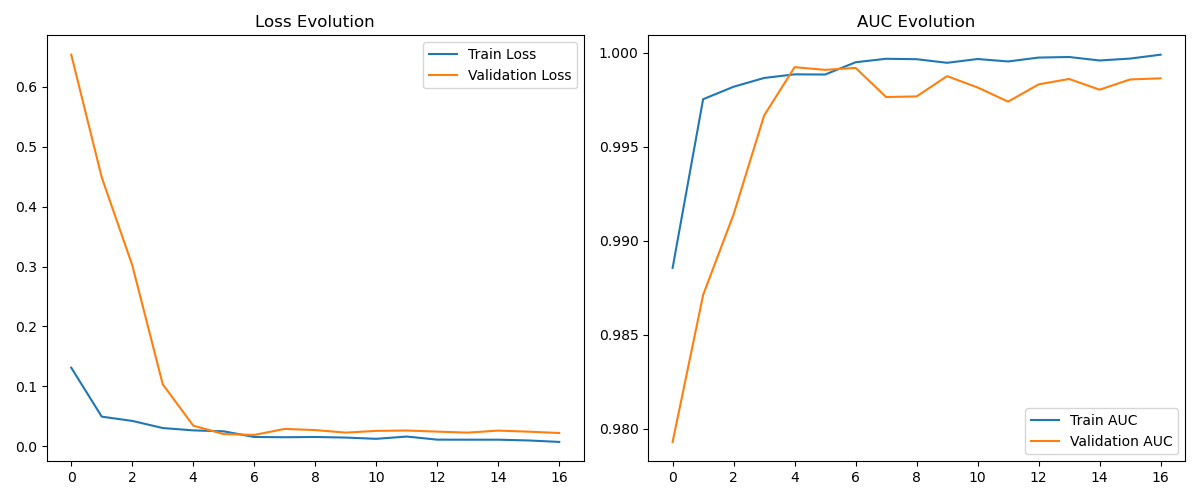

(二)数据预测
由于没有现成的数据,所以本文直接基于MITBIH作为要预测的数据,方便后续进行。
这里对数据的处理,我一开始希望用训练好的模型参数来进行预测,然后将患者的所有数据进行列出,但是只处理100-109的数据,花费了十分钟之久,导出的Excel数据有255列,2w行的数据...所以我改变了思路,直接将分类后的患者基本数据进行打印,并且对原始的hea数据增加一个标签:diagnosis(normal/abnormal),这样就可以减少因为列出数据而造成的时间浪费,提高代码的运行效率。运行结果如下:
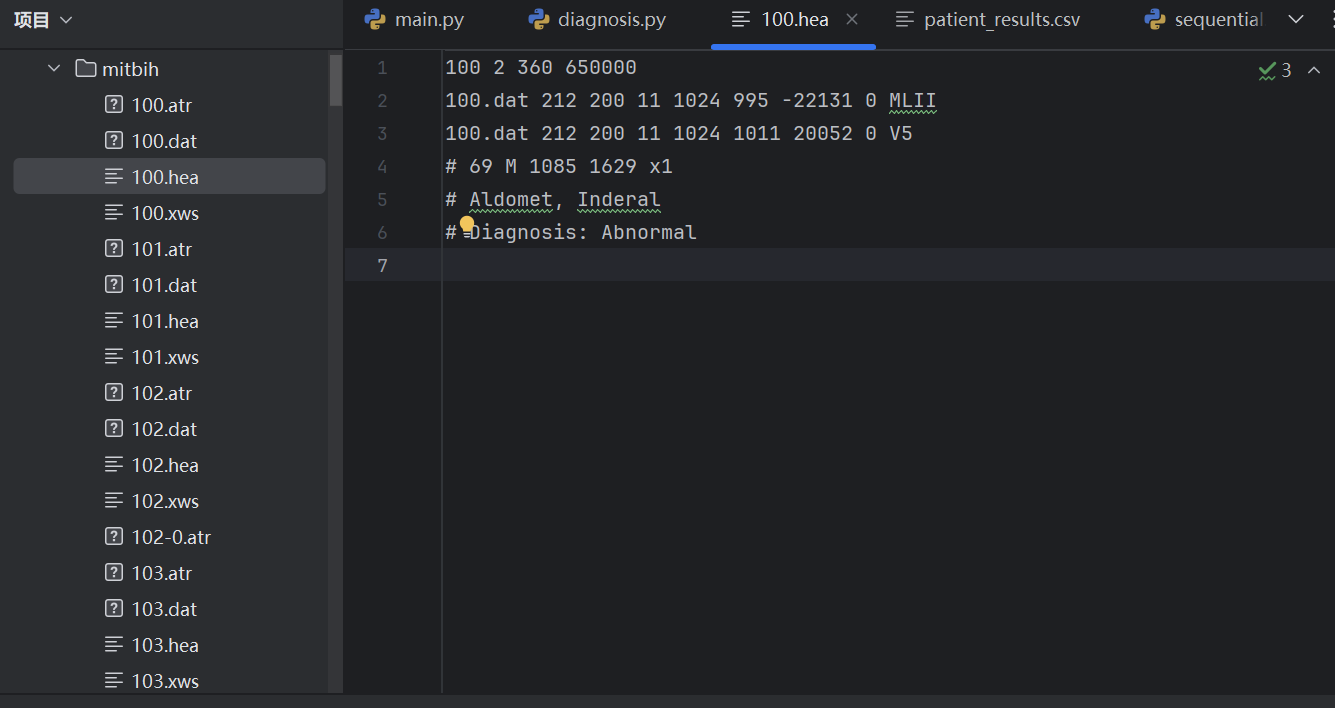
然后将再用一个csv文件将所有的患者的基本信息进行打印,方便进行初步筛选。
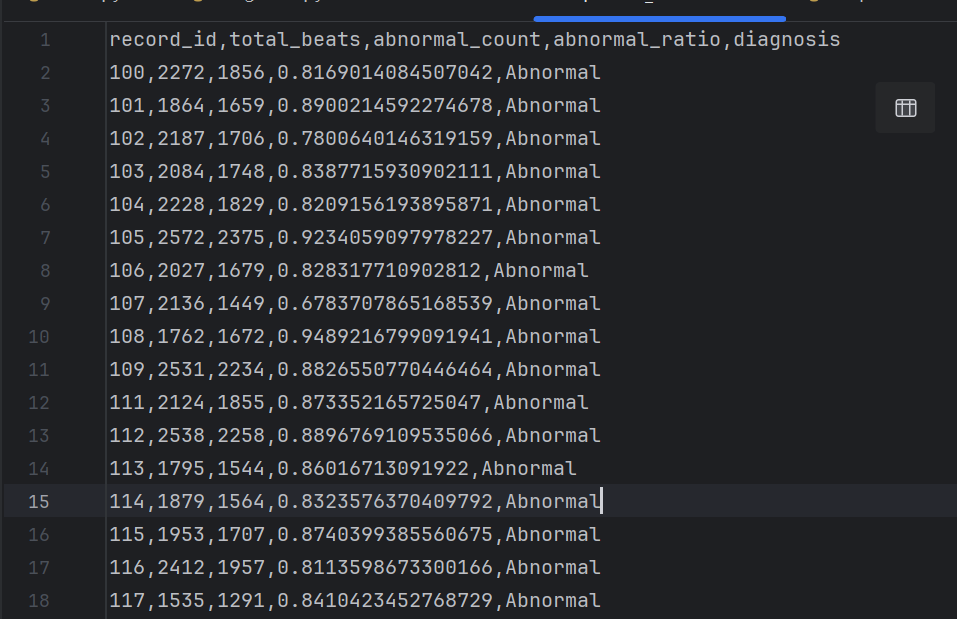
这样,我们就完成了对的是否患病实现了基本的分类,在后续使用大模型处理时,就可以先对csv中abnormal的患者编号记下来,然后在处理时,对原始的数据,根据编号进行上传处理。
(三)修改建议
这里的思路其实还可以进行优化,可以再一次使用二分类对患者的风险进行评估(也可以使用多分类一次对结果进行分析),结果分为高风险和一般风险,这样,在初步处理时就可以直接确定严重的患者,然后直接通知医生对其进行急救。
但是,由于时间缘故,暂时不能实现,这里仅仅提供一个思路。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









