






使用 AnimateDiff创建令人惊叹的 GIF 动画!
了解如何使用这个强大Stable Diffusion工具,释放你的创造力。
1. 下载所需文件
2. 安装 AnimateDiff扩展
3. 安装AnimateDiff模型
4. AnimateDiff 设置
5. Stable Diffusion设置
嗨,你发现了宝藏。
这是一个AnimateDiff介绍教程,这个工具可让您使用Stable Diffusion创建令人惊叹的 GIF 动画,这是目前为止最好的文本生成视频(Text-to-video)人工智能工具之一。

AnimateDiff GitHub:
https://github.com/guoyww/animatediff/ (复制到浏览器打开)
您可以用它创建逼真的视频,或者卡通风格,目前卡通风格的效果是最好的,所以在本教程中我会演示卡通风格如何使用,道理是一样的。
1. 下载所需文件
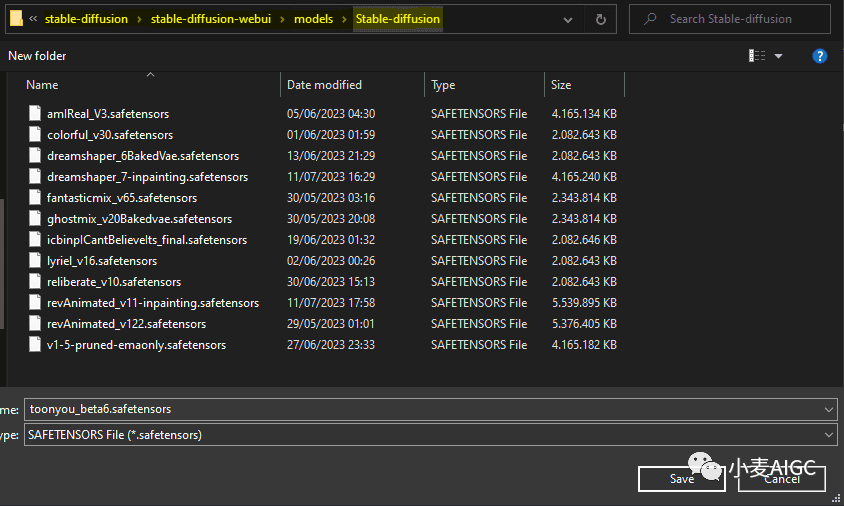
对于这种卡通风格,一个不错的checkpoint是 ToonYou,您可以从 CivitAI网站下载最新版本,并把它拖到您的Stable Diffusion模型文件夹中,如下所示。

下图:放到Stable Diffusion的模型文件夹中
2. 安装 AnimateDiff 扩展
要开始使用,不需要从 GitHub 页面下载任何东西。
直接转到Stable Diffusion扩展选项卡,点击“可用”,然后选择“从…加载”,在列表中搜索“AnimateDiff”,点击“安装”添加扩展。
如果在搜索中找不到它,请确保取消选中“隐藏带标签的扩展 -> 脚本”,它就出来啦。
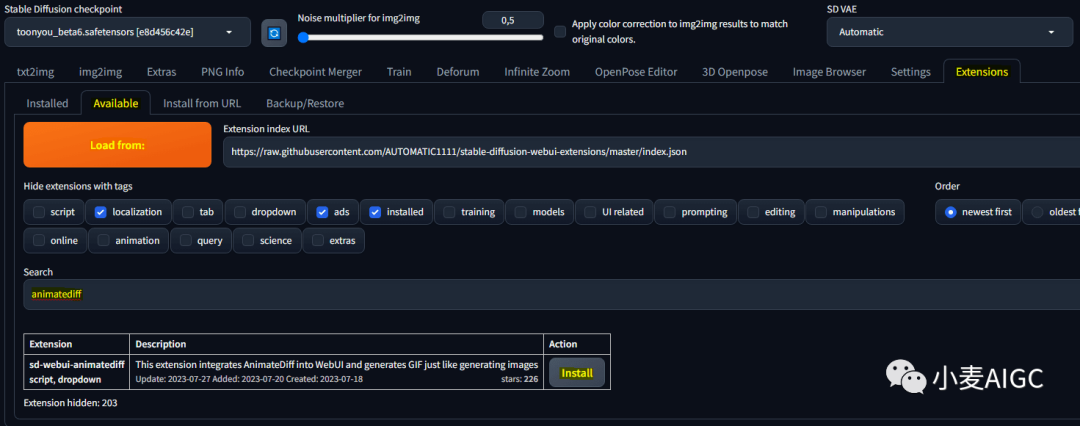
安装扩展后,转到“已安装”选项卡,然后单击“应用并重新启动 UI”。
建议你完全重启Stable Diffusion,以防止发生任何错误。

3. 下载AnimateDiff模型
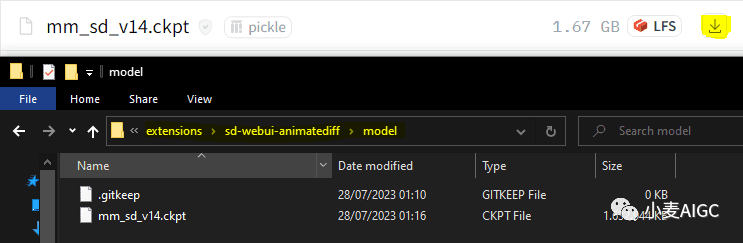
接下来我们需要 AnimateDiff 模型,这是使用扩展所必需的,您可以从 Hugging Face 网站下载该模型。目前有2种型号可供选择;“mm_sd_v14.ckpt”和“mm_sd_v15.ckpt”。我发现 v14 模型效果更好,但我建议这两个模型都下载下来,这样就可以自己尝试哪个更符合需求。
将这些文件放置在以下目录中:
“StableDiffusion”>“extensions”>“sd-webui-animatediff”>“models”。
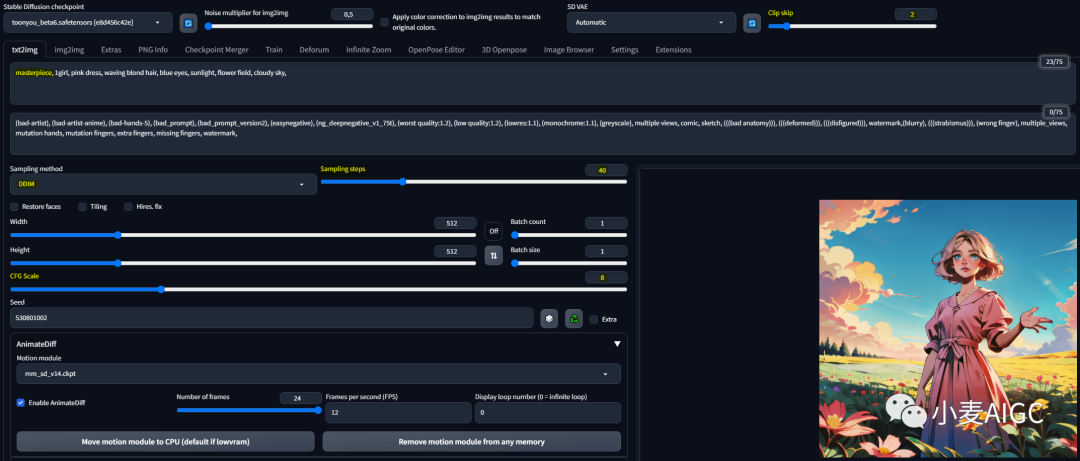
4. AnimateDiff 设置
安装 AnimateDiff 扩展后,它会出现在Stable Diffusion界面的底部。
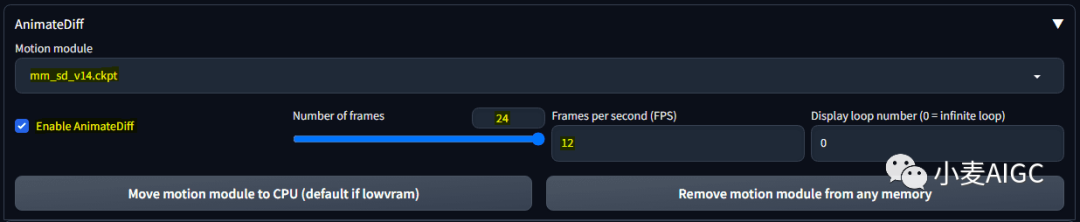
要使用它,单击“AnimatedDiff”选项,界面会展开。以下是您可以配置的一些设置,我列一下我推荐的设置。
运动模块(Motion module):mm_sd_v14.ckpt
帧数(Number of frames):我建议至少使用8帧以获得良好质量,如果使用较低的值,输出效果不会那么好。
每秒帧数(FPS):调整播放速度,我建议至少8到12。
不要忘记选中“启用”来使用该扩展。
故障排除
如果生成时间较长,请在生成前选择右边的“从内存中移除运动模块”。将负面提示控制在75个字符以下也很有帮助。最大帧数使用16帧。
5. Stable Diffusion设置
下面列出了使用 ToonYou checkpoint的推荐设置。
您可以尝试这些设置,找出最适合自己的。
checkpoint模型:ToonYou
clip跳过层:2(或更高)
正面提示词:包括 masterpiece,best quality等
负面提示词:包括 worst quality, low quality, letterboxed等
采样方法:DDIM(这是迄今为止最快的采样方法,会大大减少生成时间)。
采样步骤:最少 25 个,我建议 40 个。
宽高:512x512 或 768x768。请记住,您以后随时可以升级您的 GIF。
提示词相关性(CFG Scale):7.5 - 8
对于其余的配置,使用默认设置就行。
在生成 GIF 之前,我建议生成一些图像,使用你最喜欢的图像中的种子。
OK讲完了,接下来自己试试吧。
示例
以下是使用 AnimateDiff 和特定设置渲染的 GIF 动画的一些示例:
示例1
采样方法:DDIM
迭代步数:40
分辨率:768x512
提示词相关性(CFG Scale):8
模型:ToonYou(Beta 6)

示例2
采样方法:DDIM
迭代步数:40
分辨率:512x512
提示词相关性(CFG Scale):8
模型:ToonYou(Beta 6)

结论
虽然输出的质量可能有所差异,不过不影响AnimateDiff依然是目前最强的文生动图工具之一。
AI绘画的秘诀之一就是多尝试,试试不同的设置和模型,才能获得更满意的结果。
写在最后
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。

AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。


若有侵权,请联系删除

















 1926
1926

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









