






在使用Stable Diffusion创作的时候,经常会遇到一个问题:角色的身体并不是创作者想要的姿势。
比如想让她做出挥手的动作,输入对应的提示词,效果不明显,甚至AI对此不为所动(AI经常对一些提示词不敏感)。

ControlNet插件提供了一个约束身体姿势的功能,叫openpose。
这个功能有两个用法,分别是标准用法和高阶用法,我逐个介绍一下。
ControlNet插件内置了openpose模型,如果未能自动安装,可以到官方地址下载(文末扫码也可直接获取模型,无需自己查找),然后拷贝至\extensions\sd-
webui-controlnet\models
下载地址:
https://huggingface.co/lllyasviel/ControlNet/blob/main/models/control_sd15_openpose.pth
同时为了方便使用,还要安装openpose编辑器插件:
https://github.com/fkunn1326/openpose-editor.git
安装成功后,可以在webui界面看到该选项卡:
一、标准用法
我看到一张造型非常棒的照片,想画出同样姿势但是完全不同场景的图片。

那就可以使用openpose来实现。
首先上传姿态比较完美的照片,
然后选择“启用”,否则无效。
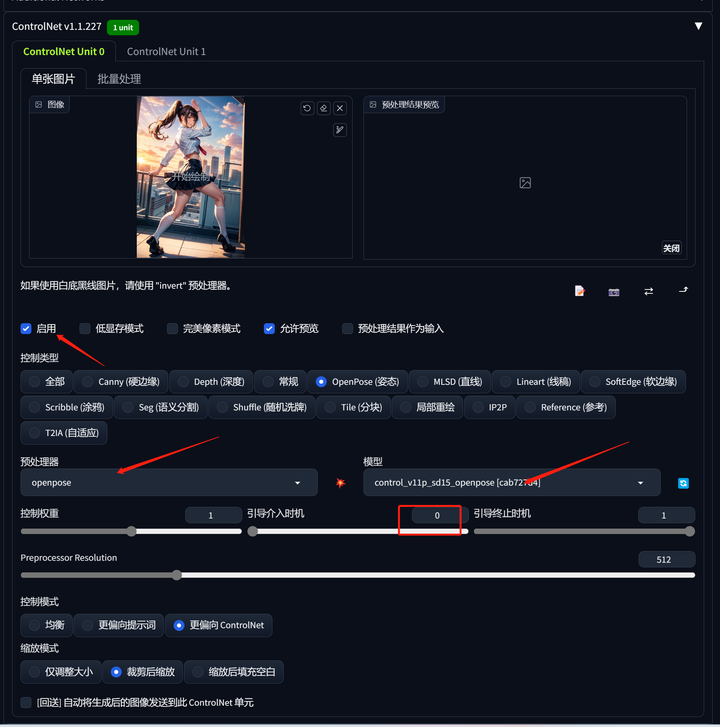
预处理器选择openpose,模型选择control_v11p_sd15_openpose。
引导介入时机选择0,意味着从一开始生成图片就介入引导。
控制模式选择更偏向controlNet。
点击一下预览,会提取出当前图片的骨架。
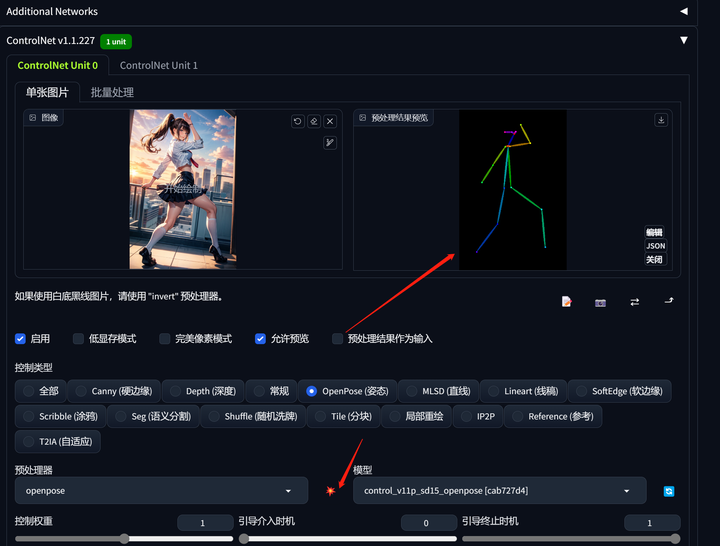
在文生图里输入想要的内容,选择合适的模型,生成的图片人物就会是这个造型了。
比如:

模型:breakdomainrealistic_R2333
提示词:
bestquality,1girl,babyface,smile,cute,lora:baby_face_v1:0.7 lora:add_detail:1

二、高阶用法
如果我对图片提取的姿势不满意怎么办?
openpose编辑器提供了一个调整姿势的方法。
先选择“从图片中提取”,把想要调整姿态的图片上传,
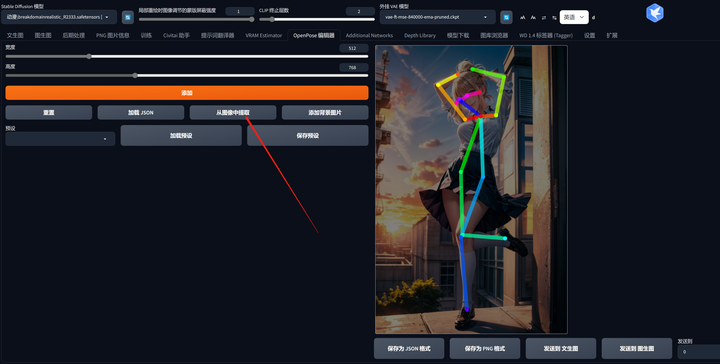
然后编辑器会自动读取该图片的姿势信息,生成一个骨架图,注意,这个图是可以拖动的。
图里每个小亮点,都可以用鼠标拖动,这样可以根据自己的想法,来控制身体骨架的姿态变化。
调整完毕后,点击“发送到文生图”,就会回传到ControlNet界面,后面的就和标准用法一致了。
想象力不足怎么办?
那就不要去想象,我从C站下载了362个参考姿势,你直接拿来用就好了。
这个姿势使用起来非常简单,除了姿势外,还有效果预览图,先从预览图里找到想要的姿势图片,再找到对应的姿势图,扔给ControlNet就好了!
每个姿势都有对应的编号。
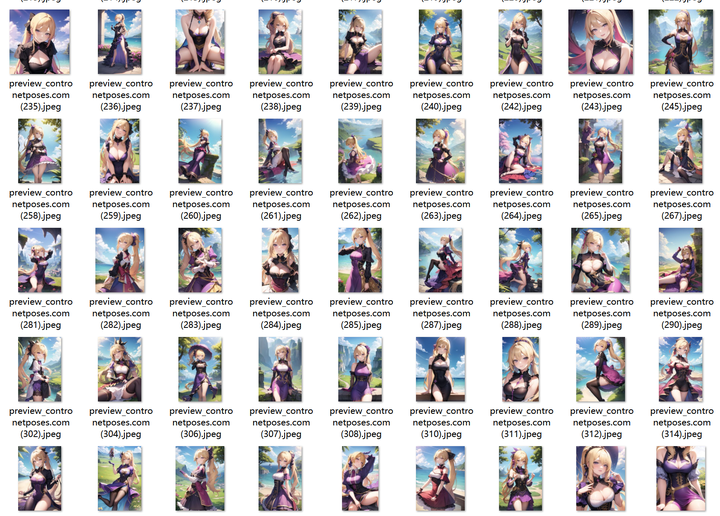
看中该姿势后再到姿势图里寻找到对应编号的姿势图。

再在ControlNet里上传该姿势图。和标准玩法略有不同的是,预处理器选择none,模型不变,然后上传姿势图片,再点击文生图就可以了!
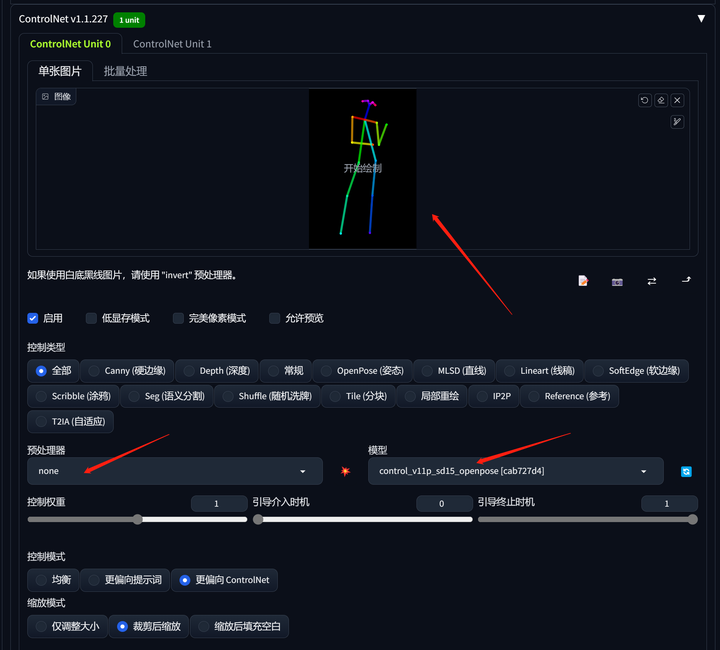
模型:meinamix_meinaV10
提示词:
absurdres, highres, ultra detailed, (1girl:1.3), BREAK , Sun Knight, solar
magic, light manipulation, radiant power, sunbeam attacks, aura of warmth,
shining armor BREAK , photo manipulation, altered realities, fantastical
scenes, digital artistry, creative editing, evocative narratives, striking
visuals BREAK , kinetic art, moving sculptures, mechanical creations,
interactive installations, dynamic motion, engineering ingenuity, captivating
visuals.
<lyco:GPTS8 Elusive World_493473:0.3>
负面提示词:
illustration, 3d, sepia, painting, cartoons, sketch, (worst quality:2), (low
quality:2), (normal quality:2), monochrome, (grayscale:1.2), (backlight:1.2),
analog, analogphoto, , RAW photo, (open mouth), (((text, signature, watermark,
username, artist name, stamp, title, subtitle, date, footer, header))), nsfw,
nipples, pubic hair, EasyNegativeV2, bad anatomy, long_neck, long_body,
longbody, deformed mutated disfigured, missing arms, extra_arms, mutated
hands, extra_legs, bad hands, poorly_drawn_hands, malformed_hands,
missing_limb, floating_limbs, disconnected_limbs, extra_fingers, bad fingers,
liquid fingers, poorly drawn fingers, missing fingers, extra digit, fewer
digits, ugly face, deformed eyes, partial face, partial head, bad face,
inaccurate limb, cropped, multipul angle, split view, grid view

需要注意的是,openpose成功率非常高,但也不是100%,有些比较复杂的姿势,有可能出现引导错误。
openpose模型、362个姿势预览图和姿势都已经打包好了,需要的小伙伴下方扫码找我拿~
这里直接将该软件分享出来给大家吧~
1.stable diffusion安装包
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.SD从0到落地实战演练

如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名SD大神的正确特征了。
这份完整版的stable diffusion资料我已经打包好,需要的点击下方插件,即可前往免费领取!


















 883
883

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









