







CSAPP Final Exam Preparation: reading & solution records
天灵灵地灵灵,保佑我考试上95 orz
Chapter1 Introduction/Preface
skip (read offline /doge)
Chapter2 Representation and processing of information
page33 旁注
man ascii在linux中可以生成ASCII表
注:
Oct - Octal - 八进制(O/Q)
Dec - decimal - 十进制
Hex - hexadecimal - 十六进制
Bin - binary - 二进制

page33 2.5
铺垫:定义了show_bytes函数
其中涉及知识:
- size_t类型:“它是一种“整型”类型,里面保存的是一个整数,就像int, long那样。这种整数用来记录一个大小(size)。size_t 的全称应该是size type,就是说“一种用来记录大小的数据类型”。通常我们用sizeof(XXX)操作,这个操作所得到的结果就是size_t类型。因为size_t类型的数据其实是保存了一个整数,所以它也可以做加减乘除,也可以转化为int并赋值给int类型的变量。”
——摘自NickWei的博客 - show_type函数
#include <stdio.h>
typedef unsigned char *byte_pointer; //定义字节指针(也就是指向某个字节的指针)
void show_types(byte_pointer start, size_t len)
{
size_t i;
for(i = 0; i < len; i++)
printf("%.2x", start[i]); //打印16进制数字,并且默认是两位
printf("\n");
}
void show_int(int x) //通过这种形式将int使用16进制字节形式打印出来
{
show_bytes((byte_pointer) &x, sizeof(int));
}
书上32页的实验证明了
Linux32、Linux64、Windows都是小端机(最高位为权值较小的十六进制数字),而Sun是大端机。
值得一提的是,这个函数的字节输出检验大端OR小端方法并不适用于Pointer类型,原因是不同的机器/操作系统配置使用了不同的存储方式。
另外,由poinetr的字节表示可以看出的是Linux32、Sun、Windows使用的是4字节地址,而Linux64使用的是8字节地址。
结果是这道题的答案是显然的
page34 2.6
naive
page34 2.7
naive
需要注意的几点:
- ‘a’ ~ 'z’的ASCII码为 0x61 ~ 0x7A
- 二进制代码在不同的机器之间是不兼容的
page35 2.8
naive
需要注意:将bool运算扩展到位向量的运算上[a1, a2, a3, …]
网络旁注: boolean ring
对于任何值a来说,a ^ a = 0,并且重新排列顺序仍然成立
例如:(a ^ b) ^ a = b
page37 2.9
naive
page38 2.10
exchange *x and *y by exclusive-or options
*x = *x ^ *y;
*y = *x ^ *y;
*x = *x ^ *y;
so interesting~
page39 2.11
不要进入思维误区,考虑的重点是 中间的两个元素的地址都是相等的 ,所以说一旦第一次运算得到的*x = 0之后,无论进行多少次运算,得到的都是0。
page38 掩码
作用就是将想要的位体现出来,不想要的位变成0
方式例如一个掩码时0xFF,一个数是x,那么就可以通过x & 0xFF将x的后八位(Bin)留下,其他位变成0。
page39 2.12
B: x ^ ~0xFF(最低有效字节不变,其他字节取补)
应用性质: 0 ^ x 不变,1 ^ x 取补
A&C:naive
*page39 2.13
很有意思的一道题,给了我一些对于异或的思考:
集合的对称差运算实际上也叫做异或运算,异或运算(a ^ b)等价于
(
¬
a
∩
b
)
∪
(
¬
b
∩
a
)
(\neg a\cap b)\cup (\neg b\cap a)
(¬a∩b)∪(¬b∩a)
这就是这道题第二个空的思路来源
annotation
C语言中的位级运算 &, |, ~,以及逻辑运算 &&, ||, ~
page40 2.14
naive
让机器做

page40 2.15
思路就是使用异或思想(( ~ a & b)|( ~ b & a),得到两个数的异或,如果结果为0,就输出,否则两次!得到1
my_code:
#include <stdio.h>
int main()
{
int a, b, c;
scanf("%d%d", &a, &b);
c = !!((~a&b)|(~b&a));
printf("%d", c);
}
annotation
for shifting
- 左移只有一种,就是舍弃最高位,右边补0
- 右移有两种,逻辑右移(左端补k个0),算术右移(左端补k个符号位)
- 移位从左至右是可结合的即a>>b>>c,亦即(a>>b)>>c
- 无符号数的右移都是逻辑右移
- C语言中没有明确说明有符号数是哪种右移,而绝大多数机器的有符号数都是算术右移
- Java中a>>>b是逻辑右移,a>>b是算术右移
- 加减法的优先级高于移位,因此1<<2+3<<4 <=> 1<<5<<4
笑死
当移动位数大于实际最大位数的时候C语言标准很小心地规避了说明在这种情况下如何做,实际上位移量k是通过k mod w得到的,其中w是最大位数。
几个数字
2
15
=
32768
2^{15}=32768
215=32768
2
16
=
65536
2^{16}=65536
216=65536
2
31
=
2147483648
2^{31}=2147483648
231=2147483648
C/C++/Java的有/无符号数
C和cpp两种都有,Java只有有符号数
page45 2.17
A2B实际上就是用B的方式来解读A这个数,二者之间传递关系是位级表示不变
T denotes Two’s Implement (补码)
W denotes number of the bits of the data presentation (位数)
That’s all you need to pay attention to…
annotation
- 不同机器的补码表示范围不同,为了提高可移植性,可以使用C语言的<limit.h>库文件,其中定义了INT_MAX, INT_MIN, UINT_MAX的宏
- ISO C99中给出了<stdint.h>文件,其中含有intN_t, uintN_t类型,其中N一般为8、16、32、64
- C语言中几乎所有机器都使用补码,也就是将数字当作有符号数,只有当数字后面有U时才认为这是无符号数输入时可用%u.
- C语言中有符号数和无符号数进行运算默认会将有符号数看成无符号数进行运算
page53 2.21
| 表达式 | 类型 | 求值 |
|---|---|---|
| -2147483647-1 == 2147483648U | 无符号 | 1 |
| … | … | … |
| 其余以此类推 |
annotation
short转换成unsigned,转换顺序,先改变大小(也就是长短),再进行有符号到无符号的转换
page56 2.23/2.24
naive
page58
2.25
将unsigned改成int
因为length(unsigned)与-1(ffffffff)相加时,-1会被当成65535(
2
32
−
1
2^{32}-1
232−1),相加得到一个很大的数,达不到停止程序循环的目的。
或者改成i < length,避免了有符号和无符号的混合计算
2.26
不能说naive,相反给出了我们一些编写程序的时候的注意事项,就像size_t这个数据类型表示的是无符号数
annotation
如何检验unsigned是否溢出,可以通过相加得到的数与加数(两个都行)进行比较,如果得到和小于加数,就说明发生了溢出。
page62 2.27
if(x + y < x)
printf("Overflow!");
else printf("In normal condition.")
annotation
- 无符号加法逆元:注意是 2 w 2^w 2w减去无符号数(正常减法),两个无符号相加等于 2 w 2^w 2w也就是相当于等于0,因为溢出舍去了。
- 有符号数加法逆元:实际上都是取反加一,但是在将补码转换为数值表示的时候,会发现除了 T M i n T_{Min} TMin等于本身之外其余都等于自己的相反数。
- 补码加法中,如果向上溢出(
x
+
y
≥
2
w
−
1
x+y \ge 2^{w-1}
x+y≥2w−1),就减去
2
w
2^w
2w,如果向下溢出(
x
+
y
<
−
2
w
−
1
x+y < -2^{w-1}
x+y<−2w−1),就加上
2
w
2^w
2w。
实际上就是做了截断,最后的结果显现出来的就是这样。 - 如何判断是否出现补码(有符号数)加法的溢出?如果两个正数得到负数,或者两个负数得到正数就是溢出了。
*page65 2.31
x, y的补码加法运算形成了阿贝尔群!仔细品味这个性质。
**page65 2.32
很好的题,指出了1000…000(
T
M
i
n
T_{Min}
TMin)的特殊性,因为这个补码没有对相应的相反数,他的相反数正是他自己,与之相呼应的是,
T
M
i
n
+
T
M
i
n
=
0
T_{Min}+T_{Min}=0
TMin+TMin=0。(因为上一位的0无法体现,因此在补码表示中就无法改变自己的符号)
这提醒我们,函数的任何测试中,
T
M
i
n
T_{Min}
TMin都应该成为一种测试情况。
***page68 2.35
看着脑袋疼,我承认是我不耐烦了,先留个坑
page69 2.36
本来想得到乘积,判断是不是在范围里面,但是答案的也挺好
但是有个问题

就是这样得到的(int64_t)x*y 是用64位的x与32位的y相乘吗,得到的是64位数吗?
Chapter3 Machine-level representation of the program
1. 微机的基本架构
都是一些概念问题…,先上图:

这是绪论中的那个图片,大概给出了整体的架构。
2. I32寄存器
下面给出一些概念(我爱混淆的):
- 既然说寄存器是最快的存储单元,那么寄存器是内存吗?
不是。解释参考Difference between Register and Memory - 寄存器只有一个吗?
不是。例如x86-64的寄存器有如下这么多:16个通用寄存器,每个寄存器为64位(包括2个索引寄存器和2个堆栈寄存器),16个 128位SSE寄存器6个16位段寄存器,指令指针状态寄存器。参考链接
另例:IA32(Intel Architecture, 32-bit)寄存器:
- 基本寄存器
- 8*32位通用寄存器
- 6*16位段寄存器
- 1*放置标志的寄存器(EFLAGS)
- 1*指令指针寄存器(EIP)
- 系统寄存器
- 浮点单元
其实我觉得 这个视频 讲的挺好的,但是就是对于寄存器和内存感觉分的不太明白,前面还register后面就memory了,还是说他们的内部结构是类似的?
老师推荐的体系结构寄存器的介绍以及我找的一个体系结构寄存器博文
基本寄存器:

通用寄存器的一般位级表示:


按照我的理解,
- 通用寄存器的功能在于执行各种基本的操作,例如进行算术逻辑运算、数据传送等。
- 段寄存器用于表示位置、地址,在实地址模式下用于存放段的基址,在保护模式下用于存放段描述符表的指针(索引)。
- 指令指针寄存器(EIP short for ‘Extended Instruction Pointer’)可以存放下一条被CPU执行的指令的地址。
- EFLAGS寄存器通过二进制位来反映当前状态(状态标志),或者用于控制CPU的操作(控制标志)。
几种EFLAGS:
- Adjust Flag:
8位操作数的位3到位4产生进位时被设置,BCD码运算时使用。
The flag bit is located at position 4 in the CPU flag register. It indicates when an arithmetic carry or borrow has been generated out of the four least significant bits, or lower nibble. It is primarily used to support binary-coded decimal (BCD) arithmetic [^1].
[^1] BCD中文翻译就是用二进制码表示十进制数字,下面图片(来源en.wikipedia.org)可以较好地帮助理解这个问题
-Parity Flag(奇偶标志):
结果的最低8位中,为1的总位数为偶数,则设置该标志;否则清除该标志。- Carry Flag(进位标志):
在 无符号算术运算 的结果,无法容纳目的操作数中时被设置。- Overflow Flag:
在 有符号算术运算 的结果位数太多,而无法容纳目的操作数中时被设置。- SF(sign flag)
- ZF(zero flag)

- 另外还有:
- 系统寄存器 [仅允许运行在最高特权级的程序(例如:操作系统内核)访问的寄存器,任何应用程序禁止访问]
- 浮点单元FPU(适合于高速浮点运算,从Intel 486开始集成到主处理器芯片中)
3. IA32内存管理
1. 实地址模式
8086CPU使用16位数据线,但是他的地址线是20位,怎么用16位表示20位呢?这里采用 内存分段(Memory segmentation) 的方法,也就是将内存分为多个64Kb( 2 16 2^{16} 216)的segment,将段地址存放在16位的段寄存器中
- CS用于存放16位的代码段基地址
- DS用于存放16位的数据段基地址
- SS用于存放16位的堆栈段基地址
段 : 偏移地址的计算方法:
a : b = a ∗ 10000 ( o r 10 H ) + b a:b = a*10000(or10H) + b a:b=a∗10000(or10H)+b
a: 段地址
b: 偏移地址
2. 保护模式
32位地址总线寻址,每个程序可寻址4GB(
2
32
2^{32}
232)内存
操作系统使用段描述符表定位程序使用的段的位置。
段寄存器指向相应的段描述符表项。
CS存放代码段描述符表项的地址
DS存放数据段描述符表项的地址
SS存放堆栈段描述符表项的地址
保护模式分为以下三种模式:平坦分段模式、多段模式、分页模式
2.1平坦分段模式
这是相对于之前实模式的重叠分段模式而言的。
2.2 分页模式
将内存分成4KB的页内存块,用界限值表示,若界限为a,则需要加上 a ∗ 2 12 a*2^{12} a∗212。
分页模式的基本思想:当任务运行时,当前活跃的执行代码保留在内存中,而程序中当前未使用的部分,将继续保存在磁盘上。当CPU需要执行的当前代码存储在磁盘上时,产生一个缺页错误,引起所需页面的换进(从磁盘载入内存)。
通过分页以及页面的换进、换出,一台内存有限的计算机上可以同时运行多个大程序,让人感觉这台机器的内存无限大,因此称为虚拟内存。
2.3 多段模式
在每一页里面还有段,用基址b表示, 要得到段地址(实际上是全局描述符表的一个值,表示了一个“段”),就用 a ∗ 2 12 + b a*2^{12}+b a∗212+b即可。
3. 指令周期与机器周期
单条机器指令的执行可以分解成一系列的独立操作,完成这些操作所需要的时间被称为 指令机器周期 。
程序在开始执行之前必须首先被装入内存。执行过程中,指令指针(IP) 包含着要执行的下一条指令的地址,指令队列中包含了一条或多条将要执行的指令。
机器指令的执行至少需要一个时针周期。
4. 计算机的启动
annotation: 8086中实际上CS:IP(code segment:instruciton pointer)就是实模式中的段:偏移量(segment:offset)
8086 PC的启动方式
在 8086CPU 加电启动或复位后( 即 CPU刚开始工作时)CS和IP被设置为CS=FFFFH,IP=0000H,即在8086PC机刚启动时,CPU从内存FFFF0H单元中读取指令执行,FFFF0H单元中的指令是8086PC机开机后执行的第一条指令。
F0000~FFFFFH:系统ROM,BIOS中断服务例程。
4. 正题 - 汇编语言
1. 计算机语言发展
- 机器语言
每一条语句都是二进制的代码
各个机器的指令系统各不相同
优点:
1.速度快
2.占存储空间小
缺点:
1.可移植性差
2.直观性差
3.调试困难 - 汇编语言
汇编语言 { 汇编指令(汇编语言的核心) 伪指令(由汇编器执行) 其他符号(由汇编器识别) 汇编语言\left\{\begin{matrix}汇编指令(汇编语言的核心) \\伪指令(由汇编器执行) \\其他符号(由汇编器识别) \end{matrix}\right. 汇编语言⎩ ⎨ ⎧汇编指令(汇编语言的核心)伪指令(由汇编器执行)其他符号(由汇编器识别)
汇编语言是机器指令便于记忆和阅读的书写格式——助记符,与人类语言接近,add、mov、sub和call等。
用助记符代替机器指令的操作码,用地址符号或标号代替指令或操作数的地址。也就是说,汇编指令和机器指令是一一对应的关系 - 高级语言
C++和Java等高级语言与汇编语言及机器语言之间是 一对多的关系 。
一条简单的C++语句会被扩展成多条汇编语言或者机器语言指令。 - 如何从高级语言转化为机器语言
(1) 解释方式
通过解释程序,逐行转化成机器语言,转换一行运行一行。
(2) 编译方式
通过编译程序(编译、链接)将程序转换成机器语言的形式 - 高级语言与汇编程序的可移植性比较
汇编语言总是和特定系列的处理器捆绑在一起。
当今有多种不同的汇编语言,每种都是基于特定系列的处理器或特定计算机的。
汇编语言没有可移植性。
高级语言的可移植性好。
2. 汇编语言
AT&T(reference site attached)
- intel以及AT&T两种汇编语言,有一个很大的差异在于操作数的顺序:
例如,英特尔语法中基本数据移动指令的一般格式是:
mnemonic destination, source
然而,在AT&T的情况下,一般格式是
mnemonic source, destination
这种方式相对于Intel汇编更加直观 - 寄存器指令
例如,IA-32架构的所有寄存器名称必须以"%"符号为前缀。%al,%bx, %ds, %cr0 等。
mov %ax, %bx
上面的示例是将值从 16 位寄存器 AX 移动到 16 位寄存器 BX 的 mov 指令。 - 文本值
所有文本值都必须以"$"符号为前缀。例如
mov $100, %bx
mov $A, %al
第一条指令将值 100 移动到寄存器 AX 中,第二条指令将 ascii A 的数值移动到 AL 寄存器中。为了使事情更清楚,请注意以下示例不是有效的指令,
mov %bx, $100
因为它只是尝试将寄存器 bx 中的值移动到文本值。这没有任何意义。 - 内存寻址
在AT&T语法中,内存以如下方式引用,
segment-override:signed-offset(base,index,scale)
部分内容可以根据所需的地址省略。
%es:100(%eax,%ebx,2)
下面的我其实没太看懂,感觉还有一些不会的没学的:
请注意,偏移量和比例不应以"$"为前缀。再举几个例子,用它们等效的NASM语法,应该会让事情更清楚,
GAS memory operand | NASM memory operand
-----------|------------
100 | [100]
%es:100 | [es:100]
(%eax) | [eax]
(%eax,%ebx) | [eax+ebx]
(%ecx,%ebx,2) | [ecx+ebx2]
(,%ebx,2) | [ebx2]
-10(%eax) | [eax-10]
%ds:-10(%ebp) | [ds:ebp-10]
示例说明,
mov %ax, 100
mov %eax, -100(%eax)
第一条指令将寄存器 AX 中的值移动到数据段寄存器的偏移量 100 中(默认情况下),第二条指令将 eax 寄存器中的值移动到 [eax-100]。
- 操作数大小
有时,尤其是在将文本值移动到内存时,有必要指定传输大小或操作数大小。例如指令mov $10, 100仅指定要将值 10 移动到内存偏移量 100,但不包括传输大小。
在 NASM 中,传输大小是通过将转换关键字byte/word/dword等添加到任何操作数来完成的。在 AT&T 语法中,这是通过向指令添加后缀b/w/l/q(对应1/2/4/8 bits)来完成的。
例如movb $10, %es:(%eax)将字节值 10 移动到内存位置 [ea:eax],
而movl $10, %es:(%eax)将长整型值(dword) 10移动到同一位置。
再举几个例子,
movl $100, %ebx
pushl %eax
popw %ax - 控制传输指令(分支寻址没学,这段也没太懂)
jmp,call,ret等指令将控制权从程序的一部分转移到另一部分。它们可以分为到同一代码段(近)或不同码段(远)的控制传输。分支寻址的可能类型包括 - 相对偏移量(标签)、寄存器、内存操作数和段偏移指针。
相对偏移量是使用标签指定的,如下所示。
label1:
.
.
jmp label1
使用寄存器或内存操作数的分支寻址必须以"*“为前缀。要指定"远"控件传输,必须以"l"为前缀,如"ljmp”、"lcall"等。例如
| GAS syntax | NASM syntax |
|---|---|
| jmp *100 | jmp near [100] |
| call *100 | call near [100] |
| jmp *%eax | jmp near eax |
| jmp *%ecx | call near ecx |
| jmp *(%eax) | jmp near [eax] |
| call *(%ebx) | call near [ebx] |
| ljmp *100 | jmp far [100] |
| lcall *100 | call far [100] |
| ljmp *(%eax) | jmp far [eax] |
| lcall *(%ebx) | call far [ebx] |
| ret | retn |
| lret | retf |
| lret $0x100 | retf 0x100 |
| 段偏移指针使用以下格式指定: | |
jmp $segment, $offset | |
| 例如: | |
jmp $0x10, $0x100000 |
Intel
3. Linux汇编程序 - 编译、链接
两种汇编格式: AT&T 汇编、Intel汇编
汇编器:
- GAS汇编器——AT&T汇编格式 Linux 的标准汇编器,GCC 的后台汇编工具
as -gstabs -o hello.o hello.s
-gstabs:生成的目标代码中包含符号表,便于调试。 - NASM——intel汇编格式
提供很好的宏指令功能,支持的目标代码格式多,包括 bin、a.out、coff、elf、rdf 等。
采用人工编写的语法分析器,执行速度要比 GAS 快
nasm -f elf hello.asm
连接器
ld 将目标文件链接成可执行程序:
ld -o hello hello.o
5. 书上内容阅读
(1) Page113
linux> gcc -Og -o p p1.c p2.c
这个命令的意思是使用GCC C编译器来编译文件p1.c, p2.c
GCC是Linux默认编译器;
-Og代表优化等级是符合原始C代码整体结构的机器代码,类似地有优化等级-o1, -o2;
gcc命令(而不是GCC C编译器)调用了一整套的程序,将源代码转化成可执行代码 (annotation: 可执行代码(Executable Code)是指将目标代码连接后形成的代码,简单来说是机器能够直接执行的代码,可执行代码当然也是二进制的。 源代码(也称源程序)是指未编译的按照一定的程序设计语言规范书写的文本文件,是一系列人类可读的计算机语言指令。 在计算机程序设计中,一般建议将源代码与可执行代码分离存储。);
gcc命令调用的一套程序:
- C预处理器 扩展源代码,插入
#include,#define命令的指定文件和扩展宏 - GCC编译器 产生源代码的汇编代码
p1.s, p2.s - 汇编器 将汇编代码转换成二进制 目标 代码
p1.o, p2.o - 链接器 将
p1.o, p2.o都将库函数引入并进行代码合并,将生成的可执行文件p生成(由命令行指示符-o p指定的)
- 区分源文件和源代码:源代码就是高级语言编写的代码,而源文件是.s(Source Code File: An S file is a generic source code file that contains the source for a computer program. It may be written in a number of different programming languages, but is commonly used for storing Assembly code.)是编译器产生的汇编代码文件。
x86-64中的一些处理器状态对于程序员来说是可见的:
如程序计数器PC,在x86-64中用%rip来表示,给出要执行的下一条指令在内存中的地址。
20220816
3.11 有关书上浮点数的内容
-
AVX浮点操作不能使用立即数作为操作数,所以会把需要的数放在内存中进行操作
-
有关212页的.long代码的解释:找到的一篇csdn博文,
解释:定义一个长整型,并为它分配空间,占四字节,0x12345678
如何将输入的两段.long转换为double类型呢?就是将两段long类型数字先用二进制表示成两个4字节数字,通过小端顺序连在一起,变成一个8字节的数字,然后使用 IEEE754 规则进行转换 -
浮点代码中使用位级操作:
xorpsvorpdvandpsandpd -
浮点数的比较操作:
ucomiss S1, S2
ucomisd S1, S2相当于计算 S2-S1 ,然后看条件码:ZF(零标志位), CF(进位标志位), PF(奇偶标志位)
第四章 处理器体系结构
4.1
ISA 全称:Instruction Set Architecture
是联系软件和硬件之间的部分
本教材中使用的Y86是仿照X86的指令集架构
- 条件码(CC, 全称 condition code):
包括ZF,SF,OF - 状态码(Stat, 在Y86中显示程序运行的状态):

4.2
听课笔记:
首先给出例子:

在这个例子中,我们需要通过链接将两个sum和array联系起来
使用gcc -Og -o prog main.c sum.c
在这个过程中产生的:
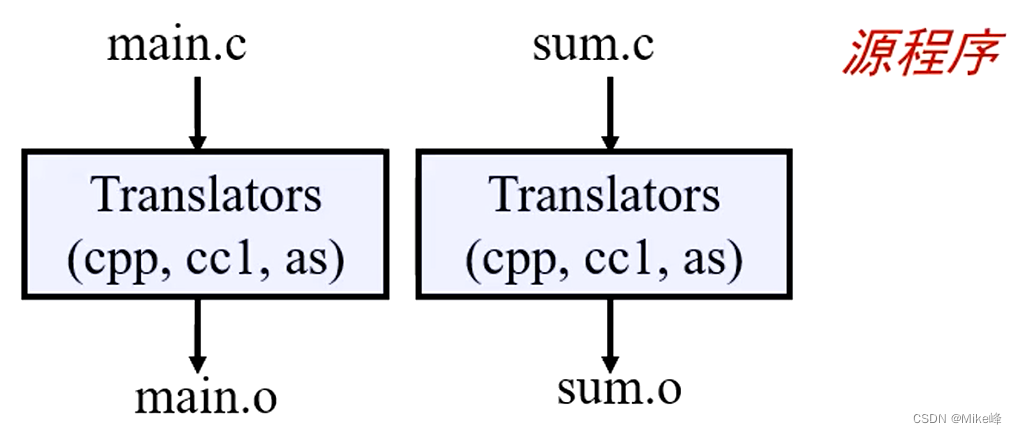
先是cpp进行预处理,将头文件的内容拷贝到main.c
然后经过cc1是一个编译程序,将高级语言程序变成汇编语言程序
使用as汇编器将汇编程序变成机器语言程序















 1620
1620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









