






需求描述:
现在有两张表,分别是test01和test02。其中表test01的数据内容示例如下:
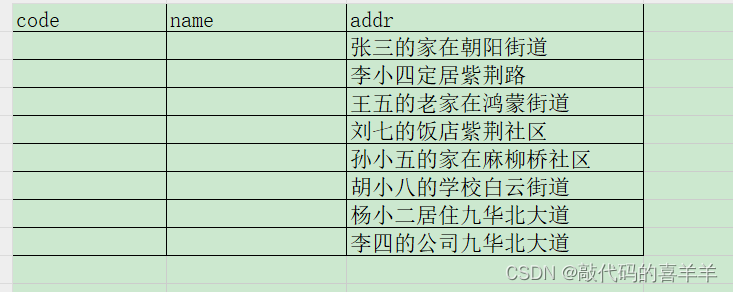
该表一共有三列数据,第一列为地址代码,第二列为地址名称,第三列为详细地址。
表test02的数据内容示例如下:
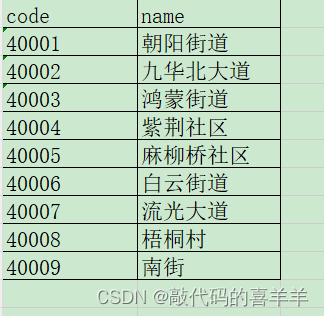
该表一共有两列,第一列为地址代码,第二列为地址名称。
现在,我要根据表test02的地址名称(name)列,和表test01的详细地址列(addr)进行匹配,将表test02的地址代码和地址名称填充/覆盖到表test01相应的code和name列。最终表test01的结果如下:
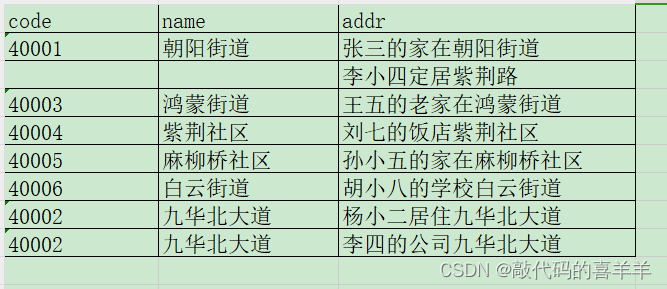
具体实现:
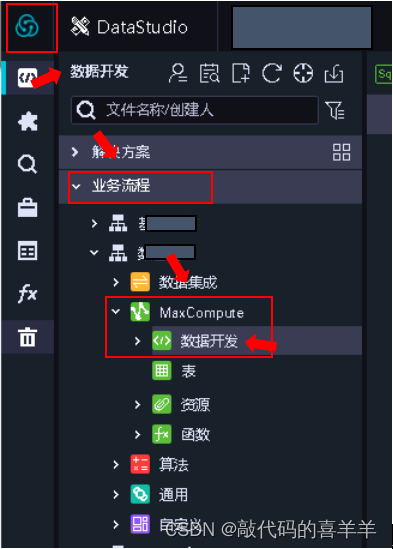
一般来说,我们可以使用sql关联两张表来进行数据匹配填充,关联条件可以借助正则匹配或者like,但是这样不够精准,因为存在数据不完善的情况。因此我们借助python脚本实现。首先打开阿里云平台的数据开发,右键新建一个pyodps结点:
假设odps上test01和test02这两张表已经存在,如果不存在,你可以借助sql脚本建表和插入数据。并且确保你已经安装了PyODPS库。如果你的阿里云平台配置过连接信息,则可以忽略下面这段代码,如果没有,那么你需要建立一个odps连接。
from odps import ODPS
# 配置ODPS连接信息
access_id = '您的AccessKey ID'
access_key = '您的AccessKey Secret'
project_name = '您的项目名称'
end_point = 'http://service.odps.aliyun.com/api'
# 创建ODPS连接
odps = ODPS(access_id=access_id, access_key=access_key, project=project_name, endpoint=end_point)
如果你已经建立好连接,那么逻辑处理代码如下:
from odps import ODPS
import pandas as pd
def main():
for index, row in df1.iterrows():
addr = row['addr']
for index2, row2 in df2.iterrows():
code = row2['code ']
name = row2['name']
if addr is not None:
if name in addr:
df1.at[index, 'code'] = code
df1.at[index, 'name'] = name
if __name__ == "__main__":
# 读取数据
table = odps.get_table('test01')
# 如果你的表格是分区表,那么使用get_partition获取相应分区;反之,则直接读取
# df1 = table.get_partition('dt=20231210').to_df()
df1 = table.to_df()
df2 = odps.get_table('test02').to_df()
# 查看数据读取后的条数
ct = df1.size().execute()
print(ct)
# 由于在odps中dataframe类型不支持遍历,因此需要转换为pandas对象
df1 = df1.to_pandas()
df2 = df2.to_pandas()
# 逻辑处理
main()
# 写入ODPS
# 写入方式可以是覆盖原表数据写入,还可以是写入到新的一张表中,如果需要覆盖原表数据写入,则需要在write_table里面加入一个overwrite=True的参数
# 在这里,我是新建了一张和test01表结构一样的空表来存放逻辑处理后的结果
odps.write_table('result', df1.values.tolist() , partition='dt=20231210',create_partition=True)
print('已完成')小结:
本文只是一个简单示例,实现如何编写一个pyodps脚本来处理无法直接用sql关联的表的逻辑处理问题。大家可以根据自己项目具体的需求来对逻辑处理模块进行完善。此外,odps中的一些函数也会因为maxcompute版本问题出现不适用的问题,具体大家可以在阿里云平台官网搜索解决方案。
https://www.aliyun.com/product/bigdata/apsarabigdata
















 3303
3303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









