






正则表达式
暂时先略
Xpath
。。。。。。
豆瓣250爬取实例
1.导入库,发起网络请求
网站地址:豆瓣电影 Top 250 (douban.com)
import requests
from lxml import etree
url = "https://movie.douban.com/top250"
headers = {
'User-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0'
}
res = requests.get(url=url, headers=headers)
print(res.status_code)打印结果200,说明请求成功
2.解析数据
在网页中定位
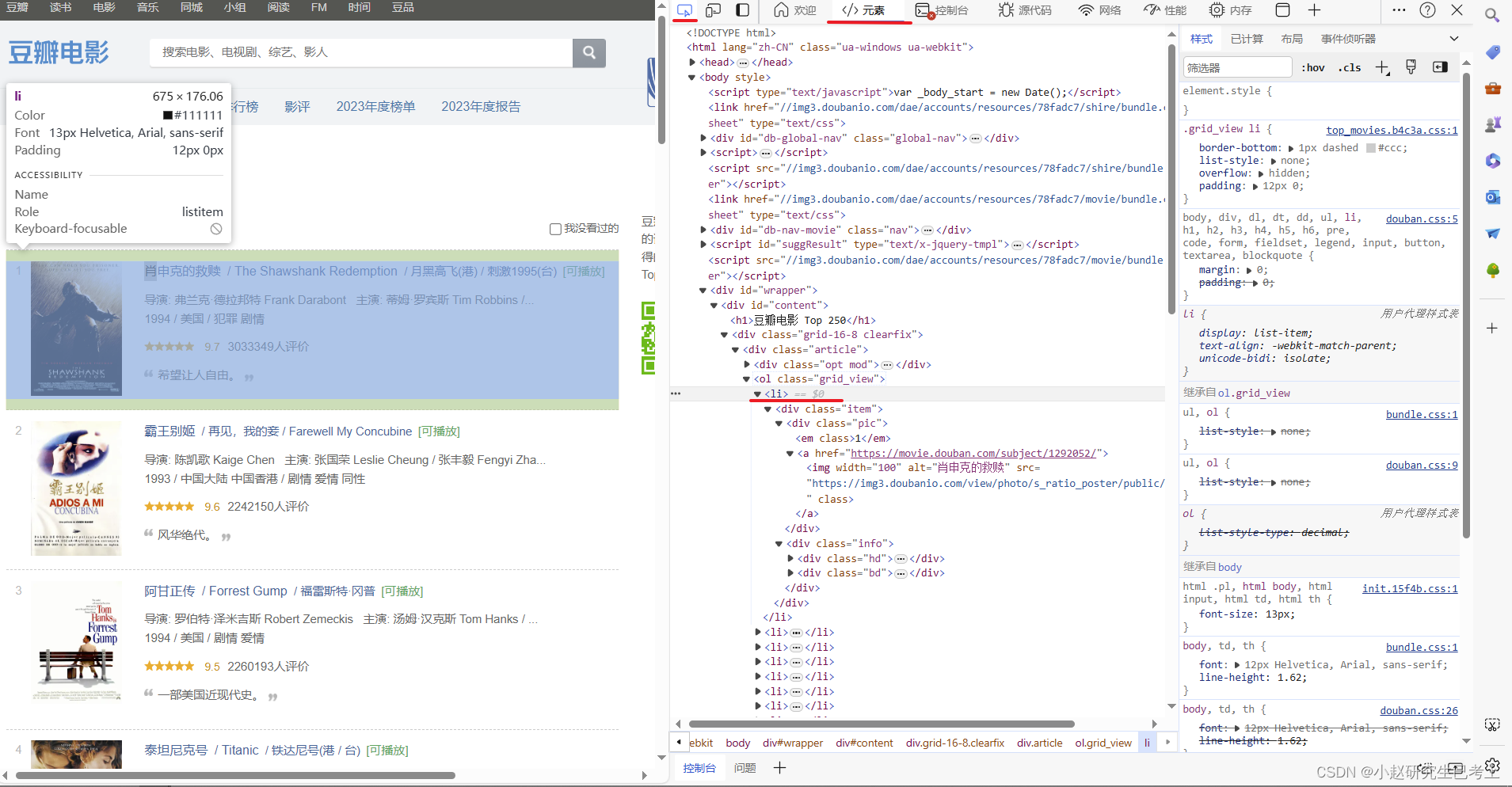
每页有25个电影,用列表lis,存储Xpath。我们如果要爬取这一页,打印lis长度的话应为25
html = etree.HTML(res.text)#在这解析
lis = html.xpath('//*[@id="content"]/div/div[1]/ol/li')
print(len(lis))#观察长度

解析
for li in lis:
# .表示当前位置,
title = li.xpath('./div/div[2]/div[1]/a/span[1]/text()')#电影名称
src = li.xpath('./div/div[2]/div[1]/a/@href')#详情连接
director = li.xpath('./div/div[2]/div[2]/p[1]/text()')[0].strip()#删去字符串两边的空格,/导演/
score = li.xpath('./div/div[2]/div[2]/div/span[2]/text()')#评分
comment = li.xpath('./div/div[2]/div[2]/div/span[4]/text()') # 评价人数
summary = li.xpath('./div/div[2]/div[2]/p[2]/span/text()') # 一句话评价
print(title[0],src[0],director,score[0],comment[0],summary[0])
3.爬取豆瓣top250
(1)分析url特点
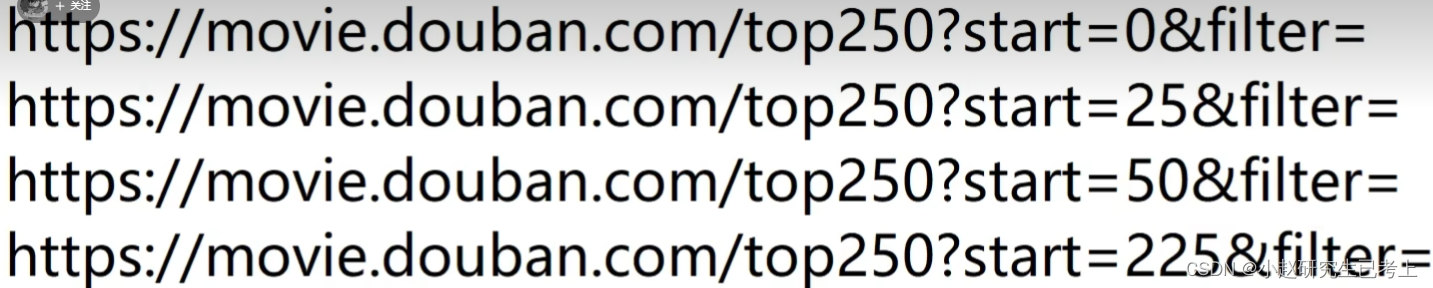
可以看到,只有后面0/25/50/225是不同的,用一个列表,将十个不同的url保存到列表中
urls = urls = ['https://movie.douban.com/top250?start={}&filter='.format(str(i * 25)) for i in range(10)]
for url in urls:
print(url)#验证,是否能得到url地址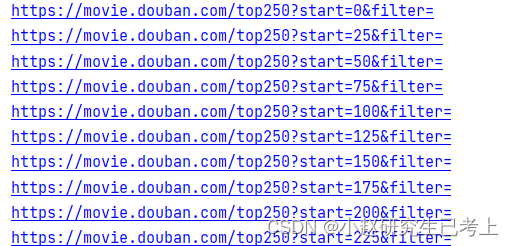
循环爬取十页信息
urls = urls = ['https://movie.douban.com/top250?start={}&filter='.format(str(i * 25)) for i in range(10)]
i = 0#用于计数
for url in urls:
# print(url)#验证,是否能得到url地址
html = etree.HTML(res.text) # 在这解析
lis = html.xpath('//*[@id="content"]/div/div[1]/ol/li')
for li in lis:
# .表示当前位置,
title = li.xpath('./div/div[2]/div[1]/a/span[1]/text()') # 电影名称
src = li.xpath('./div/div[2]/div[1]/a/@href') # 详情连接
director = li.xpath('./div/div[2]/div[2]/p[1]/text()')[0].strip() # 删去字符串两边的空格,/导演/
score = li.xpath('./div/div[2]/div[2]/div/span[2]/text()') # 评分
comment = li.xpath('./div/div[2]/div[2]/div/span[4]/text()') # 评价人数
summary = li.xpath('./div/div[2]/div[2]/p[2]/span/text()') # 一句话评价
print(title[0], src[0], director, score[0], comment[0], summary[0])
i+=1
print(i)#观察是否爬取了250个电影4.将爬取信息导入Excel,并附上完整代码
import requests
from lxml import etree
import pandas as pd
url = "https://movie.douban.com/top250"
headers = {
'User-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0'
}
res = requests.get(url=url, headers=headers)
print(res.status_code)#观察是否请求成功
urls = urls = ['https://movie.douban.com/top250?start={}&filter='.format(str(i * 25)) for i in range(10)]
df=pd.DataFrame(columns=["序号","标题","链接","导演","主演","上映时间","制片国家","电影类型","评分","评价人数","简介"])#创建标题
i = 0#用于计数
for url in urls:
# print(url)#验证,是否能得到url地址
html = etree.HTML(res.text) # 在这解析
lis = html.xpath('//*[@id="content"]/div/div[1]/ol/li')
for li in lis:
# .表示当前位置,
title = li.xpath('./div/div[2]/div[1]/a/span[1]/text()') # 电影名称
src = li.xpath('./div/div[2]/div[1]/a/@href') # 详情连接
director = li.xpath('./div/div[2]/div[2]/p[1]/text()')[0].split(" ")[0].strip("'\n ").strip("导演: ") # 删去字符串两边的空格,/导演/
actor = li.xpath('./div/div[2]/div[2]/p[1]/text()')[0].split(" ")[1].strip("主演: ") # 主演,一人
time = li.xpath('./div/div[2]/div[2]/p[1]/text()[2]')[0].strip("\n ").split("\xa0/\xa0")[0]#上映时间
country = li.xpath('./div/div[2]/div[2]/p[1]/text()[2]')[0].strip("\n ").split("\xa0/\xa0")[1]#制片国家
movie_genres = li.xpath('./div/div[2]/div[2]/p[1]/text()[2]')[0].strip("\n ").split("\xa0/\xa0")[2]#电影类型
score = li.xpath('./div/div[2]/div[2]/div/span[2]/text()') # 评分
comment = li.xpath('./div/div[2]/div[2]/div/span[4]/text()') # 评价人数
summary = li.xpath('./div/div[2]/div[2]/p[2]/span/text()') # 一句话评价
df.loc[len(df.index)]=[i,title[0], src[0], director,actor,time,country,movie_genres,score[0], comment[0], summary[0]]
i+=1
df.to_excel("movies.xlsx")
print(i)#观察是否爬取了250个电影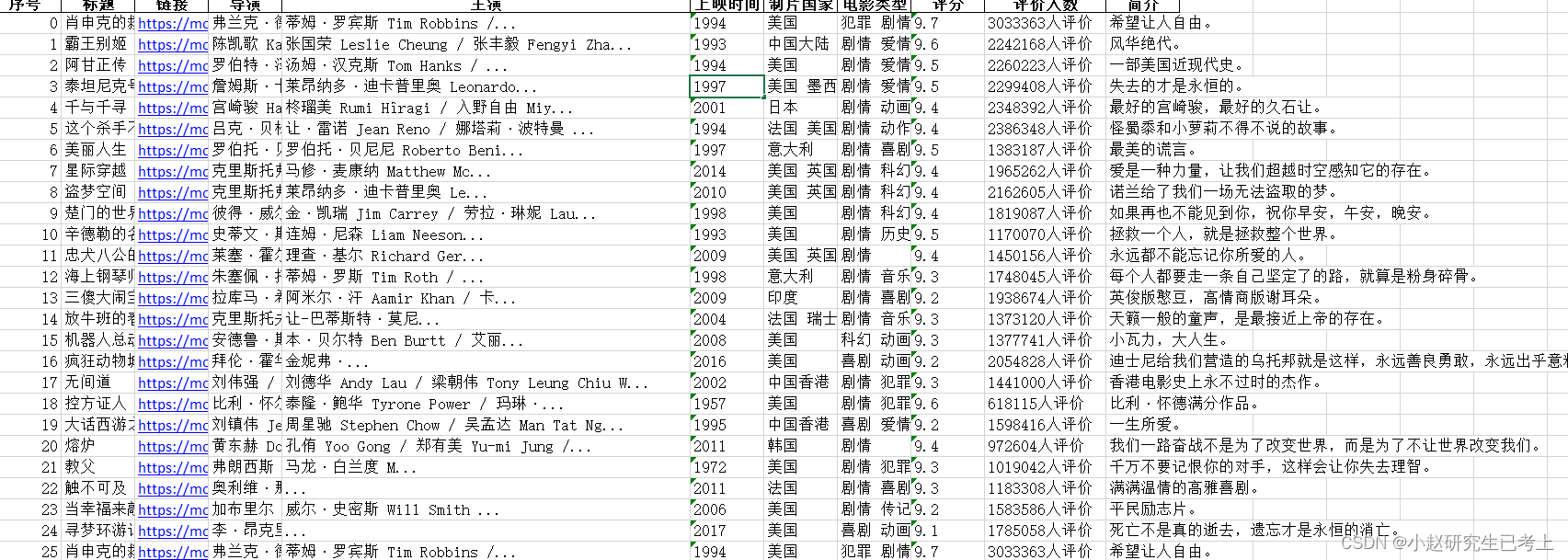
注意代码中的返回类型
python爬虫实战代码(一)_df.loc[len(df.index)]=[count,title,src,dictor,scor-CSDN博客















 2648
2648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









